
基于华为大数据平台的电商网站建设优化
2019-03-14 07:17:54刘磊黄嘉浩许锐强蔡欣桦
现代计算机 2019年4期
刘磊,黄嘉浩,许锐强,蔡欣桦
(广东开放大学,广东理工职业学院,广州 510000)
0 引言
电商网站是当今人们使用最多的Web应用,大量用户每日访问网页浏览商品、搜索喜欢的商品、查看商品详情、收藏添加购物车、登录购买商品等操作,在电商网站留下了海量的使用数据,堆积起来达到一定规模,就构成大数据,大数据分析就是利用特定平台对规模巨大的数据进行分析挖掘,找到相关因素之间的关系。本文以某电商网站的Web日志、用户维表、商品维表、销售事实表为源数据,通过源数据分析、数据清洗、HQL分析、数据可视化等步骤,从用户浏览量、销售量、点击量、商品好评等角度,分析每个用户对不同类型商品的喜好程度,从而为电商网站在相应页面推荐合适商品给不同用户,优化网站建设,提升用户体验并促进用户消费。
1 华为大数据平台
华为大数据平台FusionInsight HD是华为企业级大数据存储、查询、分析的统一平台,通过分布式部署,对外提供大容量的数据存储、查询和分析能力,能够快速构建海量数据信息处理系统,对海量信息数据实时与非实时的分析挖掘,FusionInsight HD兼容开源Ha⁃doop框架及众多组件,是完全开放的大数据平台,可运行在开放的x86架构服务器上[1]。FusionInsight HD对开源组件进行封装和增强,包含了管理系统Manager和众多组件,常用功能包括:①Manager,运维管理系统;②Loader,实现FusionInsight HD与关系型数据库、文件系统之间交换数据和文件的加载工具,Loader支持关系型数据库和HDFS、HBase、Hive表等之间的互相导入导出;③Hive:建立在Hadoop基础上的开源的数据仓库,提供类似SQL的Hive Query Language语言(HQL)操作结构化数据存储服务和基本的数据分析服务。④MapReduce:提供快速并行处理大量数据的能力,是一种分布式数据处理模式和执行环境[2]。本文采用Java编写MapReduce程序对数据进行清洗。
2 分析方案设计
基于大数据平台对海量数据分析展示一般分步进行,本文对电商网站数据分析设计的方案如图1所示。步骤如下:
(1)获取源数据:本文电商网站数据来源于互联网,可以通过大数据交易、API接口、网络爬虫、统计图表等方式获取源数据。
(2)分析源数据:源数据拿到后,根据定下的分析角度,分析源数据字段是否全部满足分析角度的需求,是否有脏数据,是否需要数据清洗,本文从三个角度分析:分析每个商品的好评度、分析用户粘度、分析用户最喜欢购买的商品。
(3)加载源数据:使用ETL工具将源数据导入HDFS,这里采用Loader组件将数据从关系型数据库导入Hive表。
(4)数据预处理:源数据通常包含脏数据,不能直接用来分析,需要根据需求进行预处理,包括数据清洗,缺省值填充,数据选择,数据变换,数据集成等。
(5)HQL分析:对预处理后的数据,使用HQL语言进行分析,HQL可以查询和分析存储在Hadoop中的大规模数据,使用HQL可以快速方便的进行MapReduce统计。
(6)Java分析:使用Java编写MapReduce程序进行数据清洗和可视化呈现分析结果。
(7)导出分析结果:使用Loader工具将分析结果从HDFS导出到关系型数据库,为Web系统应用提供大数据分析结果。

图1 分析方案示意图
3 源数据分析
本文收集到的电商网站数据,包含Web日志数据、用户维表、商品维表和销售事实表,Web日志数据存储在HDFS文件系统,数据量为1949878条,记录用户浏览网站的痕迹,源数据包含了一些错误字段和脏数据,需要先进行数据清洗,再导入Hive进行分析。用户维表、商品维表和销售事实表都存储在MySQL关系型数据库中,用户维表记录用户的基本信息,数据量为100000条,定义表名为user;商品维表记录商品的标签和价格,数据量为54条,定义表名为shop;销售事实表存储销售记录,数据量为1000001条,定义表名为sale。这三表存在主外键关系,销售事实表里有两个外键,用户名字段来自用户维表,商品ID字段来自商品维表。这三张表不需要数据清洗,直接使用Loader工具导入Hive数据仓库。
4 数据预处理
高质量的大数据分析要基于高质量的数据,但是源数据通常存在部分脏数据,例如数据不完整、数据存在错误或异常、数据内容不一致等。这时要根据分析需求预先进行数据清洗。
电商网站Web日志源数据以文件形式存储在HDFS文件系统中,使用命令查看,通过分析电商网站Web日志源数据,数据格式是每行为一条记录,行之间通过换行符分开,每行数据用空格符分隔成9个不同字段数据,除这些正确数据格式外,发现源数据还存在字段错误、冗余数据,影响后面的数据分析,因此对脏数据进行过滤。编写MapReduce程序进行数据清洗,清洗过程由Mapper负责,Reducer则负责把清洗后的数据输出,使用Java编写代码。Mapper代码获取输入流,按规则进行清洗,首先对每一行按空格拆分成数组,判断若数组长度为9则符合要求,继续清洗,使用Parselogs类将每行数据解析成9个字段,分别对应用户IP地址、用户名、时间、商品一级标签、商品二级标签、商品ID、用户访问来源url地址、响应码、用户访问页面所用的工具,将正确的数据交给Reducer[3-5]。
清洗完之后Web日志数据相对干净和有规律,保留的结构如表1所示。
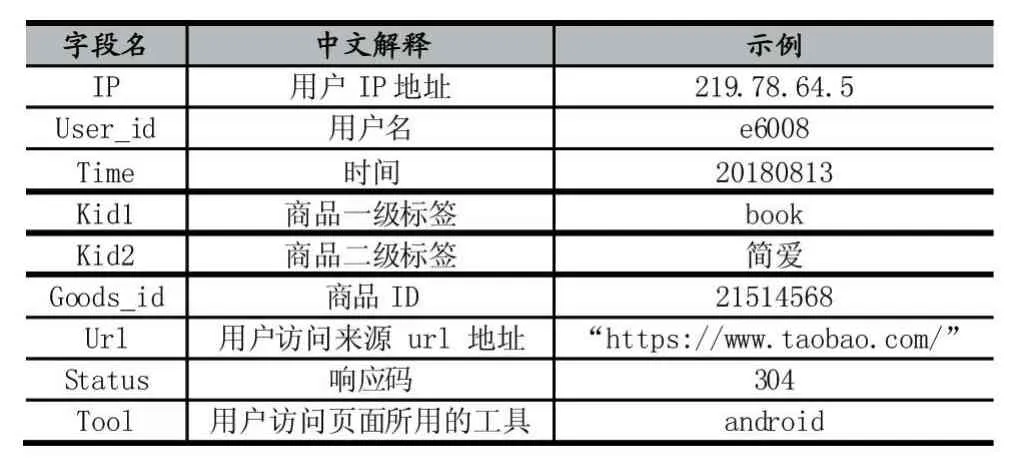
表1 清洗后的Web日志数据(Web)结构
5 HQL分析及可视化
Hive是基于Hadoop的数据仓库基础构架,可以将结构化的数据文件映射为一张数据库表,提供了一种存储、查询和分析Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据,可以将HQL语句转换为MapReduce任务进行运行[6]。
Hive中所有的数据都存储在HDFS中,支持text⁃file、Sequencefile、Rcfile等数据格式。使用Hive创建表的时候,需要设定数据中的列分隔符和行分隔符,这样才能将数据正确导入Hive表。
下面使用HQL从三个角度分析电商网站数据:
(1)分析每个商品的好评度
计算每个商品的好评度,对商品做出合理评价,给予用户更好质量的推荐,提高用户体验度。设定好评度计算规则为:好评度=(5分次数+4分次数*0.8+3分次数*0.5)/评价总次数,如果评价字段空缺,则用5分填充。本条分析数据来自销售事实表(sale),根据商品ID分组统计,计算每个商品的好评度,分析语句如下:
select goods_id as`商品 ID`,round(count(case when evalu⁃ates=4 then'4'end)+count(case when evaluates=3 then'3'end)+count(case when evaluates=5 and evaluates=''then'5'end)/count(evaluates),2)as`好评度`from sale group by goods_id order by`好评度`;
运行结果如图2所示。
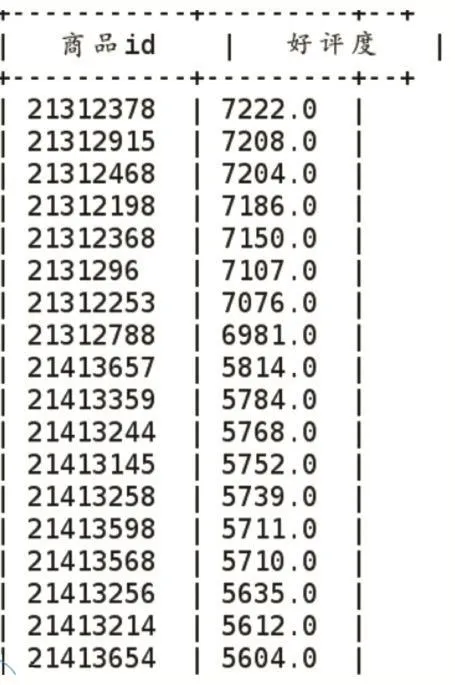
图2 统计商品的好评度
对数据结果进行可视化展示,使用Java编写代码展示好评度排名前10的商品,效果如图3所示。
(2)分析用户粘度
从网页URL被访问的访客数量和访问总次数两个角度分析网站的访问粘性,分析访问量最大的页面,优化其他页面,衡量页面更新前后受欢迎程度,从而优化整体网站建设。本条分析数据来自用户浏览网站的Web日志记录(web),根据网页URL分组统计,计算不重复的访客数量,页面访问总次数,并按降序排列,分析语句如下:
select url as`网页 URL`,count(distinct user_id)as`访客数量`,count(url)as`访问总次数`from web group by url;
运行结果如图4所示。
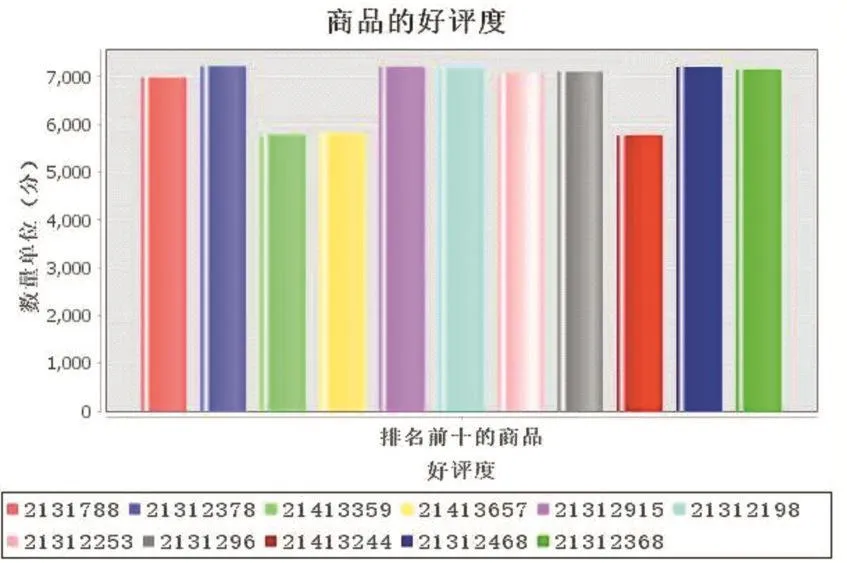
图3 统计商品的好评度可视化效果

图4 统计用户粘度
对数据结果进行可视化展示,使用Java编写代码展示访问量前5的网页,效果如图5所示。
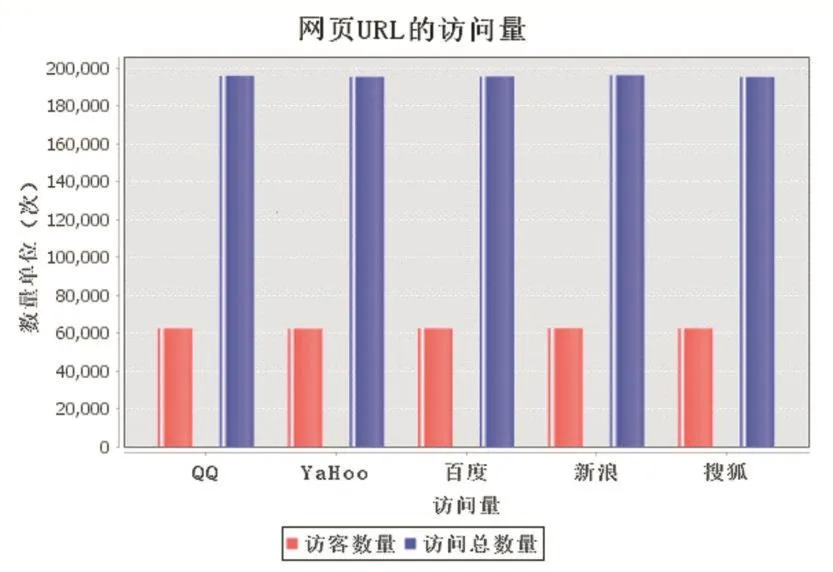
图5 统计用户粘度可视化效果
(3)分析用户最喜欢购买的商品
对于已经登录的用户,根据用户的基本信息如年龄段、性别、职业等,分析出用户最喜欢购买的商品,从而将这些商品有目标的推送给不同用户展示,提高交易成功率,优化网站建设。本条分析统计不同年龄段不同性别消费金额最多的商品种类,年龄和性别来自用户维表(user),消费金额来自销售事实表(sale),商品种类来自商品维表(shop),用户维表和销售事实表根据用户ID关联,销售事实表和商品维表根据商品ID关联,根据年龄段和性别分组,统计出消费金额最多的商品种类,分析语句如下:
select t.sex as`性别`,t.age as`年龄段`,y.kid2 as`商品类别`from(select elect*,row_number()over(partition by c.sex,c.age order by c.money desc)as rank from(select a.sex,a.age,b.goods_id,b.money from(select s.age,s.sex,s.id from(select case when range_age<=30 then'<=30'when range_age>30 and range_age<=50 then'30-50'when range_age>=50 then'>=50'end as age,sex,userid as id from user)s group by s.age,s.sex,s.id)a join(select sum(money*num)as money,goods_id,us⁃er_id from sale group by goods_id,user_id)b on a.id=b.user_id group by a.sex,a.age,b.goods_id,b.money)c)z where z.rank<=1)t join shop y on t.goods_id=y.goods_id;
运行结果如图6所示。
由结果可知,不同年龄段不同性别的用户最喜欢购买的商品种类,基于大数据分析结果,再将同类目下的商品推荐给顾客,就可以达到优化网站建设,提高用户体验度的效果。

图6 不同年龄段不同性别用户喜欢购买的商品
6 结语
电商网站每日产生的用户数据正呈指数性增长,如何从这么大规模的数据量中分析挖掘出有价值的信息,反馈网站建设优化,给用户带来更好的使用体验,这给技术带来了挑战。随着大数据平台的日渐成熟和普及,能够轻松实现TB级数据的存储、PB级数据的查询分析,为海量数据的分析预测提供了技术手段。本文基于业界流行的华为大数据平台,对电商网站数据进行了三个角度的分析,先进行数据清洗,再使用HQL语言做统计分析,最后使用Java呈现可视化分析结果,为Web网站建设优化提供了数据支持,本文下一步将继续研究更复杂的分析角度,采用编写MapReduce程序实现复杂分析。
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
传媒评论(2019年4期)2019-07-13 05:49:14
现代企业文化(2018年13期)2018-06-09 08:22:23
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
机电信息(2015年28期)2015-02-27 15:57:42
