
基于卷积神经网络的藏文手写数字识别
2019-03-12 08:13夏吾吉色差甲扎西吉贡保才让华却才让
现代电子技术 2019年5期
关键词:自动识别
夏吾吉 色差甲 扎西吉 贡保才让 华却才让


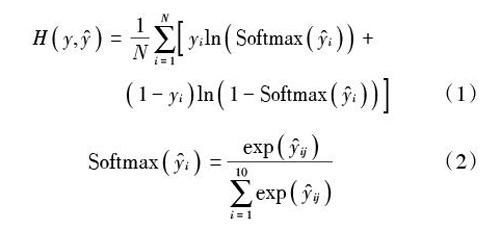
关键词: 藏文手写数字; 数字识别; CNN; 数据预处理; 样本训练; 自动识别
中图分类号: TN711?34 文献标识码: A 文章编号: 1004?373X(2019)05?0079?04
Tibetan handwritten numeral recognition based on convolutional neural network
XIA Wuji1, 2, SE Chajia1, ZHAXI Ji1, GONGBAO Cairang1, HUAQUE Cairang1
(1. Key Laboratory of Tibetan Information Processing of Ministry of Education, Qinghai Normal University, Xining 810008, China;
2. Normal College for Nationalities, Qinghai Normal University, Xining 810008, China)
Abstract: The Tibetan information processing technology is potentially needed for Tibetan processing and Tibetan numeral automatic recognition increasingly, and has become one of the important research topics in Tibet. Tibetan handwritten numeral data is collected and constructed, which is 15 000 samples in total, in which 13 000 samples are taken as the training data, and 2 000 samples are taken as the test data and preprocessed. The convolutional neural network (CNN) model is used to train the Tibetan handwritten numeral samples. The experimental results show that the recognition correct rate of test set can reach up to 97.85%.
Keywords: Tibetan handwritten numeral; numeral recognition; convolutional neural network; data preprocessing; sample training; automatic recognition
0 引 言
藏文作為我国藏族地区、不丹、尼泊尔和其他藏传佛教传播地区广泛使用的语言文字,属于世界上公认的复杂拼音文字之一[1]。经过1 400多年的演变和发展,藏文形成了严格而完整的拼写规则体系,是由4个元音字母和30个辅音字母从上到下、从左到右叠加而形成的二维结构。
藏文中的数字通常有两种表达方式[2]:第一种是阿拉伯数字,比如“0,1,2,…,9”;第二种是藏文数字,比如“?、?…?”。其中,阿拉伯数字是全世界公用的数字,其手写识别是多年来的研究热点,并且手写阿拉伯数字技术在各个行业领域得到了广泛的应用,包括支票数据处理、自动识别邮政编码、税务智能系统和商贸往来等。经过数十年的研究和发展,研究者提出了很多有效的手写阿拉伯数字识别方法[3?9],并得到了较好的效果。以计算机科学技术为核心的网络信息化时代,随着藏区的网络信息化和藏文信息量的急剧增长,对藏文字处理和藏文数字识别等藏文信息处理技术的潜在需求也越来越高,目前已经成为藏区重要的研究课题之一。同样藏文手写数字也广泛应用于藏文信息化的各个行业领域,比如,藏文邮政编码系统和藏文支票数据处理等,这些应用场合对藏文手写数字识别的精确度有很高的要求,并且其识别直接关系到藏区经济、藏区信息化建设和民族交流等问题。由于不同手写者和手写数字的随意性,会加大识别的难度,导致影响识别效果。因此,藏文手写数字识别问题是藏文信息处理和藏区信息化建设等领域的关键问题。目前,在信息界的相关研究者未对藏文手写数字自动识别进行研究和讨论。因此,本文将手写阿拉伯数字识别研究作为参考,采用卷积神经网络(CNN)模型对藏文手写数字识别进行研究。
1 数据采集与预处理
手写数据样本采集和构建是数字识别中最重要的工作之一,为此,随机选择了50位懂藏文的人,采集每个人“?”至“?”的藏文手写数字样本,每个人将每一个藏文数字均手写30次,共得到15 000个样本。由于不同样本图像的字体、字号和所在区域是有差别的,所以为了确保数字图像输入到卷积神经网络的形式具有一致性,对所有样本数据做了如下预处理:
1) 绘制像素为2 480×3 508、行数为15、列数为10的表格,共有150个格子,为便于图像的切割处理,每个格子的像素固定为200×200。然后用A4纸张打印,每人均手写两张(300个样本),50人共得到15 000个样本。
2) 将所有样本用扫描仪进行扫描,得到藏文手写数字图像。
3) 将得到的每张藏文手写数字图像,通过像素计算切割成像素为200×200的150个小图片。
4) 将得到的藏文数字图像用最大类间方差法(OTSU)进行二值化,获得藏文手写数字二值化图像,在二值化过程中,把藏文数字图像各像素点的值由(0,255)灰度图像处理成二值(0,1)。
5) 为了便于后续识别,将所有的样本归一化为相同的像素点阵图,本文选择的形式为28×28。
数据处理见图1。
2 模型及框架
2.1 模 型
卷积神经网络(Convolutional Neural Network,CNN)通过局部感受野、下采样和权值共享三个特性来实现位移识别、缩放和扭曲等不变性[10]。设计一个CNN时,单层CNN由卷积层(Convolutional)、下采样层(Pooling)、Relu(Rectified Linear Units)层、全连接层等四个层构成。其中,卷积是图像识别中一种常用算法,通过卷积运算可以使样本信息的特征增强,并降低噪声数据[11]。同一个特征图片中的所有神经元都用一个卷积核来共享,其卷积核被认为是训练参数或者权重。用卷积核计算得出的值可以代表一个特征,从图片中局部感受野能够发现一些局部特征。一般卷积核的大小、数目以及滑动步长等设置不同将会影响局部的特征学习效果。下采样也称之为二次采样(Subsampling),使用图片局部信息的相关性对图片进行子抽样,其目的就是降低数据的计算量,同时存留特征明显的信息。在CNN中这种操作称为池化(Pooling)操作,常见的有最大池化(Max Pooling)和平均池化(Mean Pooling)。池化层具有将特征进行聚合和防止模型过拟合等作用。Relu是一个常见的激活函数,其具有卷积层提取特征进行非线性转换的作用。目前其他常见的激活函数还有Sigmoid,Softmax,tanh等。Relu在训练梯度下降时可获得更快的收敛速度[12],这也是CNN中使用Relu的原因之一。全连接层使用卷积层和池化层等多层学习后将结果映射到一个固定大小的向量,为了处理后续待解决的任务(比如分类任务等),一般在全连接层中也会使用激活函数,针对解决问题的不同,使用的激活函数也不同,比如多类分类时使用Softmax函数,而二类分类时一般使用Sigmoid函数。
图2中每个卷积操作和池化操作过程中使用的[Wi(i=1,2,3)]和[Mj(j=1,2,4)]都是固定的权重以及固定的窗口,其窗口大小与输入的大小和窗口移动步长等有關。同时,在模型训练过程中,必须确定一个目标函数和参数更新方法。其中,常见的目标函数有交叉熵、互信息和对比估计噪声法(Noise?Contrastive Estimation,NCE)[13]等,本实验中目标函数将使用交叉熵(Cross Entropy With Softmax)。由于藏文数字识别是多类问题,所以目标函数中应用Softmax函数。其公式如下:
[Hy,y=1Ni=1NyilnSoftmaxyi+1-yiln1-Softmaxyi] (1)
[Softmaxyi=expyiji=110expyij] (2)
式中:[Hy,y]为目标函数,即用交叉熵计算损失函数;[yi]是第[i]个数据的真实标签;[yi]是第[i]个数据模型得出的标签;[N]是训练样本个数;[yij]是第[i]个样本向量的第[j]个位置上的值。参数更新法主要用于梯度下降法,而常见的梯度下降法有随机梯度下降法(Stochastic Gradient Descent,SGD)、批量梯度下降法(Batch Gradient Descent,BGD)和自适应矩估计法(Adaptive Moment Estimation,Adam)等。本文使用Adam法,其主要优点有动态调整学习率,对偏值进行校对后,每次迭代时学习率控制在一定的范围内,使得参数比较平稳。
2.2 基本框架
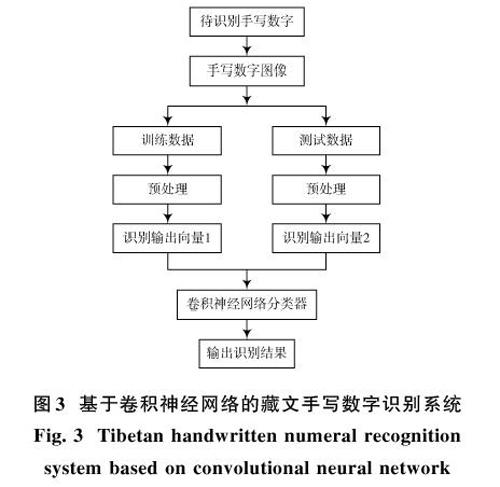
基于卷积神经网络的藏文手写数字识别系统主要利用三层卷积层、三层池化层以及一层全连接层的卷积神经网络,在手写数字识别领域有良好的识别性能。整个识别系统包括从采集手写图像到得出识别结果的过程。具体框架如图3所示。
3 实 验
实验采用藏文手写数字共15 000个样本,训练集规模为13 000个样本,测试集规模为2 000个样本。为了客观评价本文所提基于卷积神经网络模型藏文手写数字识别方法的有效性,通过正确率指标对藏文手写数字识别的结果进行评价。经测试,十种藏文手写数字的平均自动识别准确率达到97.85%,“?”至“?”每一种藏文手写数字具体识别结果如表1所示。
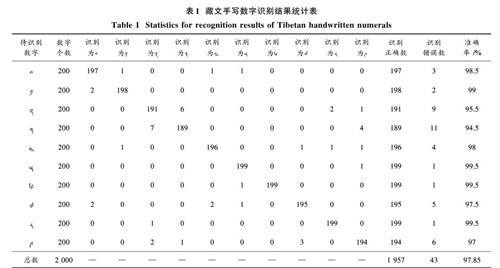
通过实验结果得出,由于50个人的书写方式不同,写出的藏文数字也各不相同。因此,本文对每一个数字进行了分析,分析数字的范围是“?” 到“?”这十类数据,每类提取200个,每个数字与其他数字进行对比分析后得出数字“?”,“ ?”和“ ?”的识别率最高均为99.5%,错误数仅为1;数字“?”和“?”的识别率相对较低,分别为95.5%和94.5%。由表1可知,“?”和“?”相互出错率最高,原因是在藏文数字中“?”和“?”的字形相近,且手写时由于手写者和手写数字随意性的不同,导致“?”和“?”容易混淆,加大了识别难度。其余数字因手写时超出规定表格,切分时将数字图像的一些细节信息丢失,从而导致少数识别错误。
4 结 语
随着深度学习理论和技术在各个研究领域中获得突破性成绩,在图像识别和理解领域,深度学习同样取得了不错的效果,其识别正确率甚至超过了人工的识别结果,然而藏文手写识别的研究工作相对空缺。为此,本文初步完成了基于神经网络的藏文手写数字识别工作,在构建的数据样本集上取得了97.85%的平均正确率。
由于藏文手写数字样本数据较为匮乏,加之采集到的数据中手写字体的格式(粗细、大小)、手写方式等存在差异,导致实验结果相对于阿拉伯手写数字的识别准确率较低。在后续的工作中,将继续扩大手写数据规模,提高准确率,并在此基础上尝试藏文手写字符的识别工作。
注:本文通讯作者为华却才让。
参考文献
[1] 华却才让.基于树到串藏语机器翻译若干关键技术研究[D].西安:陕西师范大学,2014.
HUAQUE Cairang. Research on some key techniques of Tibet machine translation based on tree to string [D]. Xian: Shaanxi Normal University, 2014.
[2] 孙萌,华却才让,刘凯,等.藏文数词识别与翻译[J].北京大学学报(自然科学版),2013,49(1):75?80.
SUN Meng, HUAQUE Cairang, LIU Kai, et al. Tibetan number identification and translation [J]. Journal of Peking University (natural science edition), 2013, 49(1): 75?80.
[3] 李文趋.SVM在手写数字识别中的应用[J].泉州师范学院学报(自然科学),2010,28(4):18?21.
LI Wenqu. Application of SVM in handwritten numeral recognition [J]. Journal of Quanzhou Normal University (natural science), 2010, 28(4): 18?21.
[4] 张黎,刘争鸣,唐军.基于BP神经网络的手写数字识别方法的实现[J].自动化与仪器仪表,2015(6):169?170.
ZHANG Li, LIU Zhengming, TANG Jun. Realization of handwritten numeral recognition based on BP neural network [J]. Automation and instrumentation, 2015(6): 169?170.
[5] 焦微微,巴力登,闫斌.手写数字识别方法研究[J].软件导刊,2012,11(12):172?174.
JIAO Weiwei, BA Lideng, YAN Bin. Handwritten digital re?cognition method [J]. Software guide, 2012, 11(12): 172?174.
[6] 杜梅,赵怀慈.手写数字识别的研究[J].计算机工程与设计,2010,31(15):3464?3467.
DU Mei, ZHAO Huaici. Research on handwritten digit character recognition [J]. Computer engineering and design, 2010, 31(15): 3464?3467.
[7] 付庆玲,韩力群.基于人工神经网络的手写数字识别[J].北京工商大学学报(自然科学版),2004,22(3):43?45.
FU Qingling, HAN Liqun. Recognition for handwritten numbers based on Artificial neuron network [J]. Journal of Beijing Technology and Business University (natural science edition), 2004, 22(3): 43?45.
[8] 刘东泽,蔡建立.基于神经网络的手写数字识别[J].福建电脑,2009(11):83?84.
LIU Dongze, CAI Jianli. Handwritten numeral recognition based on neural network [J]. Fujian computer, 2009(11): 83?84.
[9] 王璇,薛瑞.基于BP神经网络的手写数字识别的算法[J].自动化技术与应用,2014,33(5):5?10.
WANG Xuan, XUE Rui. The algorithm of handwritten digit recognition based on BP neural network [J]. Automation technology and applications, 2014, 33(5): 5?10.
[10] 高学,王有旺.基于CNN和随机弹性形变的相似手写汉字识别[J].华南理工大学学报(自然科学版),2012,32(5):538?544.
GAO Xue, WANG Youwang. Recognition of similar handwritten Chinese characters based on CNN and random elastic deformation [J]. Journal of South China University of Technology (natural science edition), 2012, 32(5): 538?544.
[11] 匡青.基于卷积神经网络的商品图像分类研究[J].软件导刊,2017,16(2):178?182.
KUANG Qing. Commodity image classification based on convolutional neural network [J]. Software guide, 2017, 16(2): 178?182.
[12] NAIR V, HINTON G E. Rectified linear units improve restricted boltzmann machines [C]// Proceedings of the 27th International Conference on Machine Learning. Haifa: ACM, 2010: 807?814.
[13] MNIH A, KAVUKCUOGLU K. Learning word embeddings efficiently with noise?contrastive estimation [C]// Proceedings of the 26th International Conference on Neural Information Proces?sing Systems. Lake Tahoe: ACM, 2013: 2265?2273.
猜你喜欢
中国自动识别技术(2023年6期)2024-01-12
水上消防(2019年3期)2019-08-20
特别健康(2018年3期)2018-07-04
发明与创新(2016年26期)2016-08-22
电测与仪表(2016年6期)2016-04-11
计测技术(2014年6期)2014-03-11
