
物联网异常流量检测算法研究
2019-03-08 10:26:12邓海勤
网络安全与数据管理 2019年2期
鲍 捷,牛 颉,张 勇,邓海勤
(1.北京邮电大学 电子工程学院,北京 100876;2.爱动超越人工智能科技(北京)有限责任公司,北京 100007)
0 引言
随着当前物联网在全球各领域的广泛应用与快速发展,作为一种信息承载工具,物联网已经成为人们生活中不可缺少的一部分。物联网网络安全问题越来越成为广受关注的焦点。出于不良目的所产生的异常流量影响着物联网的正常运转,用户主机面临新的安全隐患,进一步影响了广大人民群众的日常工作与生活。
传统的通过静态规则匹配的网络异常检测方法在动态、复杂的网络环境中难以检测出未知异常和攻击类型,不能满足网络安全检测的要求。机器学习具有自学习、自演化的特性,可以适应复杂多变的网络环境,能够检测出未知异常,满足实时准确检测的需求。因此,使用机器学习的方法检测网络中海量的流量,对于物联网领域的发展具有重要的意义。本文借鉴传统网络中异常流量检测技术加以改进,从而识别物联网中异常流量。因为在实时网络流量异常检测中无法得到大量带标记的样本记录,所以从机器学习的无监督学习算法中选取One-class SVM、Isolation Forest、K-means等方法进行网络异常流量检测,对相关技术进行分析和比较。
1 网络异常流量检测技术
传统的预防网络安全的技术主要有防火墙、病毒的查杀软件等,这些措施只能够发现一些简单的网络入侵,对于一些设计较为严密的入侵则较难判断。新形势下的互联网异常流量已经变得比以往更加复杂多变,因此传统的预防网络安全的技术只是在特定的范围中或是一定的程度上起到作用。文献[1]主要是从分类、聚类、统计、信息理论四个角度来总结异常流量检测技术。文献[2]介绍利用数据挖掘的异常流量检测技术,主要从分类和结合数据挖掘、聚类、关联分析的多种算法来归纳。张楠等在文献[3]总结了当前有哪些主流的异常流量检测技术和检测过程中的技术和关键问题。文献[4]从入侵检测方法中的三个方面入手,介绍了异常检测的方法和技术类型等。文献[5]从动态网络的异常检测出发,归纳了动态网络中的四种异常类型。虽然有很多机器学习的算法被应用到异常流量检测中,但是都没有从机器学习的角度全面地介绍网络异常流量检测。
基于监督机器学习的方法是利用标记的数据集将分类器输出的结果与实际结果进行连续比较,然后调整参数直至训练出最优模型。早在2005年,朴素贝叶斯被摩尔等人引入并进行流量的识别与分类,之后贝叶斯网络再一次被奥尔德等人应用,并在性能上加以提高,使用效率优于从前。另一种较为常见的监督算法是C4.5决策树,应用于K-Nearest Neighbor(KNN)以及流量的识别。但是,这些方法整体倾向于局部优化。支持向量机是有监督的算法,可以避免局部优化,在识别流量方面显示出高度的准确性,并检测异常流量。文献[6]使用KNN算法来实现异常行为的检测,文献[7]把KNN和K-means融合在一起形成一个新的方法,文献[8]针对冗余特征和样本数据高维度等问题,使用KNN和改进的人工鱼群算法来选择特征向量,提高异常检测的效率和正确率。文献[9]是采用的决策树来实现网络异常流量检测。
无监督的算法旨在聚类,即根据统计特征来聚合相似的流量,分离不相似的流量并建立群集和网络应用之间的映射。在2004年,期望最大化(Expectancy Maximum,EM)被McGregor应用于流量分类。但是,它只能识别未知流量,不能识别出流量的具体应用。然后,Zander st.通过利用EM构建无监督贝叶斯分类器提出了AutoClass。尽管AutoClass可以识别某种类型的流量,但仍然很难识别其他类型的流量。通常,非监督方法比识别特定类型更适合在动态环境中查找新的应用程序类型。文献[10]提出了一种改进的K-means的方法,将多次划分的数据集相交直至结果收敛,减少迭代次数、加快了算法的速度。
2 无监督机器学习算法
无监督学习相比较于监督学习是在数据不知道任何标签的情况下,按照偏好所训练出的算法,这种方法将所有的数据与不同的标签映射。
2.1 One-class SVM算法
One-class SVM指的是训练数据只有一类的数据,学习到这类数据的边界,然后导入测试集,在此范围内的数据标签为1,之外的标签为-1。例如:假如对工厂的产品进行检查,往往知道的大多数数据都是合格产品的参数,这个时候可以通过合格产品的参数训练一个一类分类器,超出这个边界的便可标记为不合格产品。
它的求解模型如下:
(1)
subject to (w·Φ(xi))≥ρ-ξi,ξi≥0
(2)
2.2 K-means算法
K-means是一种聚类算法,聚类是针对大量未知标签的数据集,按照数据内部存在的数据特征划分为不同的类别,使类别内的数据比较相似,类别之间的数据相似度比较大,属于无监督学习算法。输入的是样本集,聚类的簇数是l,最大迭代次数N的输出是簇划分。
算法流程:

1.选择K个点作为初始质心;2.将每个点对应到最近的质心,形成K个簇;3.重新计算每个簇的质心;4.重复上述步骤;5.直到达到最大迭代次数或者是簇不发生变化。
寻找使误差准则函数最小的簇是K-means算法的目的。簇与簇之间的区别在潜在的簇形状为凸面的时候比较明显,而且当簇的大小差不多时,通常情况下会产生比较理想的聚类结果。时间复杂度为O(tKmn)的该算法是与样本数量呈线性相关的,所以在处理大数据集合的时候效率非常高,并且在处理时也具有很好的伸缩性。除了对初始聚类中心较为敏感以及需要事先确定簇数K之外,算法的结束通常是采取局部最优的方法,并且对孤立点和“噪声”比较敏感,该方法实际上不适于寻找凸面形状的簇或者大小差别很小的簇。
2.3 Isolation Forest算法
Isolation Forest是随机采样一部分数据构造每一颗iTree,保证不同树之间的差异性,iTree的构造需要首先随机选择一个属性,然后随机选择这个属性的一个值,把小于这个值的作为左孩子,大于等于的作为右孩子,一般直到传入的数据集的树的高度达到了限定高度,iForest具有线性时间复杂度,对全局稀疏点敏感。
算法流程:

1.选择一个属性Attr;2.选择该属性的一个值Value;3.Attr对每条记录进行分类,把Attr小于Value的记录归为左孩子,把大于等于Value的记录归为右孩子;4.递归的构造左孩子和右孩子,直至满足以下的两个条件之一:(1)传入的数据集只有一条记录或者有多条一样的记录;(2)树的高度达到了限定高度。
把iTree构建好之后就可以预测数据了,预测的过程如下:先在iTree上运行一下训练数据集,看通过测试之后得到的记录落在哪个叶子节点。iTree能有效检测异常的假设是:网络流量异常点一般来说都是十分稀少的,所以在iTree中会很快找到这样的叶子节点,叶子节点到根节点的路径用h(x)来表示,可以用这个参数的长度判断一条记录x是否是异常点。对于一个包含n条记录的数据集,其构造的树的高度最小值为log(n),最大值为n-1,归一化公式如下:
(3)
c(n)=2H(n-1)-(2(n-1)/n)
(4)
其中H(k)=ln(k)+ξ,ξ=0.577 215 664 9 为欧拉常数。
s(x,n)是记录x在由n个样本的训练数据构成的iTree的异常指数,s(x,n)取值范围为[0,1]异常情况的判断分以下几种情况:
(1)越接近1表示是异常点的可能性高;
(2)越接近0表示是正常点的可能性比较高;
(3)如果大部分的训练样本的s(x,n)都接近于0.5, 说明整个数据集都没有明显的异常值。
iForest和Random Forest的方法有些类似,都是随机采样一部分数据集去构造每一棵树,保证不同树之间的差异性,不过iForest与RF不同,采样的数据量Psi不需要等于n,可以远远小于n。
算法流程如下:

输入:输入数据X,iTree的数量,样本大小ψ 输出:iForest1.初始化Forest;2.设置限制高度;3.对于每个分支构造iTree并赋给Forest;4.返回iForest。
Isolation Forest算法主要有两个参数:一个是二叉树的个数;另一个是训练单棵iTree时候抽取样本的数目。实验表明,当设定为100棵树,抽样样本数为256条时,IF在大多数情况下已经可以取得不错的效果,体现了算法的简单、高效。
Isolation Forest是无监督的异常检测算法,在实际应用时,并不需要黑白标签。需要注意的是:(1)如果训练样本中异常样本的比例比较高,违背了先前提到的异常检测的基本假设,可能最终的效果会受影响;(2)异常检测与具体的应用场景紧密相关,算法检测出的“异常”不一定符合场景实际。比如,在识别虚假交易时,异常的交易未必就是虚假的交易。所以,在特征选择时,可能需要过滤不相关的特征,以免识别出一些不相关的“异常”。
3 实验与分析
本文中pcap流量包使用开源数据集CICIDS2017[11],CICIDS2017数据集包含良性和最新的常见攻击,类似于真实的真实数据(PCAP)。还包括使用CICFlowMeter进行网络流量分析的结果,该流量分析具有基于时间戳、源和目标IP、源和目标端口、协议和攻击(CSV文件)的标记流。使用wireshark对pcap流量包进行解析、预处理操作,最后得到41维的.csv文件作为本文使用的数据集。对三种结果数据整理、计算,可得到正确率、误报率、漏报率、效率,如表1所示。
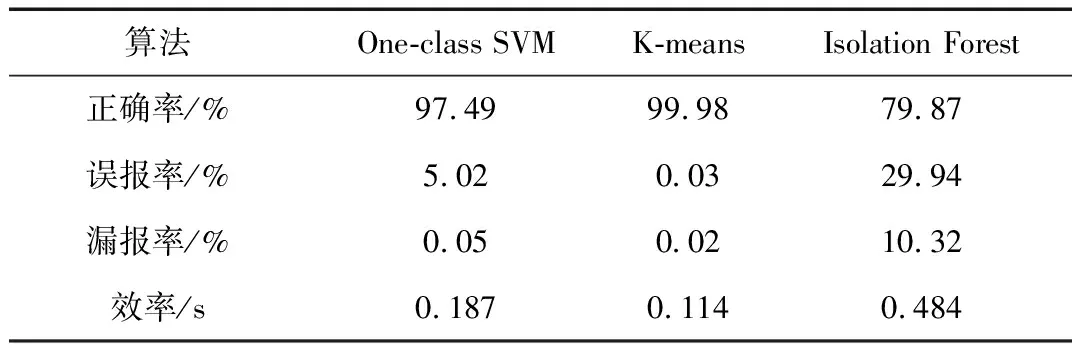
表1 实验结果分析
从表中可以看出,K-means在正确率、误报率、漏报率、效率方面要优于Isolation Forest和One-class SVM。综合来看,K-means表现要优于其他两种无监督机器学习算法。
4 结论
使用三种不同的无监督机器学习算法对物联网异常流量进行检测,通过结果对比可以得到K-means算法要优于其他两种算法,Isolation Forest算法表现最差。希望为无监督机器学习算法检测物联网流量研究提供借鉴。
猜你喜欢
玩具世界(2022年2期)2022-06-15 07:35:36
房地产导刊(2021年8期)2021-10-13 07:35:16
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
出版人(2020年4期)2020-11-14 08:34:26
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2017年15期)2017-12-18 07:19:27
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
