
基于缓解HoL堵塞的单组播混合调度算法
2019-03-05 03:37袁龙熊庆旭萧翰
北京航空航天大学学报 2019年2期
袁龙, 熊庆旭, 萧翰
(北京航空航天大学 电子信息工程学院, 北京 100083)
随着网络应用的发展,网络所承载的业务类型从单一类型逐渐向多元化发展,交换机不仅需要支持纯单播业务或纯组播业务分组转发,还需要有效调度单组播混合业务。
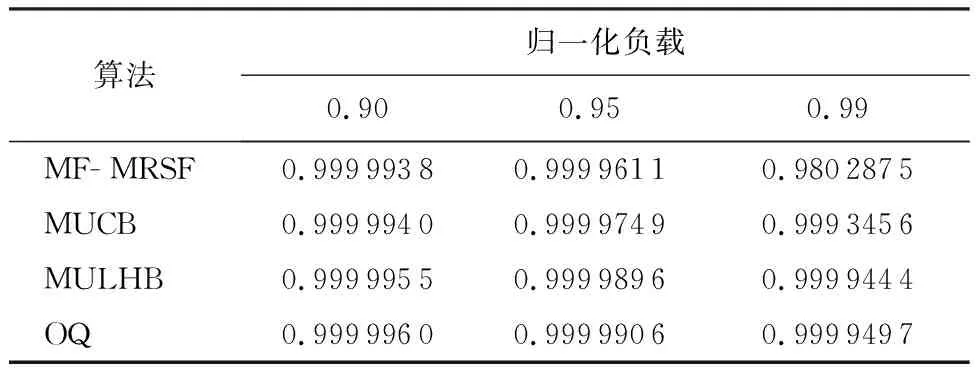
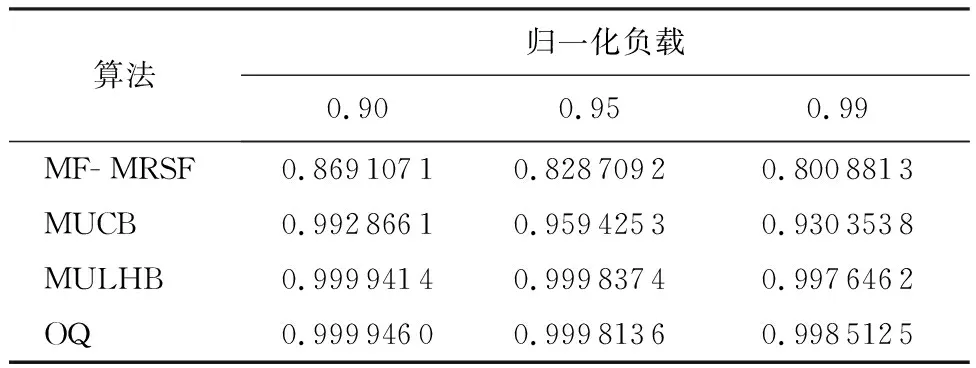
输出排队(Output Queued,OQ)结构的通过率为100%,可提供QoS确保功能,但存在N倍加速比,不易于扩展[1]。输入排队(Input Queued,IQ)结构加速比为1,可扩展性强,但需采用虚拟输出排队(Virtual Output Queuing,VOQ)[2]结构克服头分组(Head of Line,HoL)堵塞[3]问题。对于单播业务只需在每个输入端口配置N个虚拟队列,但组播业务分组扇出类型多达2N-1种,则需要在每个输入端口放置2N-1个队列[4],难以在大规模交换机中实用化。目前的研究通常配置k(1 随着集成电路技术的发展,联合输入交叉排队(Combined Input and Crossbar Queued,CICQ)被普遍认为最值得期待的高性能分组交换结构,但 CICQ结构单组播混合业务调度算法研究不多。早期主要以单播调度或组播调度为主,在单播调度中[5-7],文献[7]提出的交叉缓存队列均衡(Crossbuffer Queue Balance,CQB)算法从定量的角度出发,以交换机实现work-conserving状态为追求目标,使交换机的性能得到显著提升。在组播调度中,Mhamdi和Hamdi提出了组播交叉结点轮询(Multicast Cross-Points Round Robin,MXRR)算法[8],由于输入端口中仅采用单FIFO(First In First Out)队列,存在严重的HoL堵塞问题。文献[9]提出了轮询(Round Robin,RR)、最小扇出优先(Minimum Residue First,MRF)、最大服务优先(Maximum Service First,MSF)以及最大服务率优先(Maximum Ratio of Service First,MRSF)等调度算法,并在输入端口采用多个组播队列,从结构上缓解了组播HoL堵塞,提高了交换机的通过率降低了平均分组时延。为了满足单播组播混合业务调度的需求,Mhamdi和Vassiliadis提出了单组播轮询调度(Multicast and Unicast Round robin Scheduling,MURS)算法[10],采用不同的优先级轮询调度单组播业务。虽然算法复杂度低,但整体性能欠佳。Yi等提出的低代价组播调度(Low-Cost Multicast Scheduling,LCMS)算法[11],考虑了单组播业务之间的差异性,基于权重裁决单组播之间的竞争,算法的性能有一定提升,但输入端口仅采用一个组播队列,导致了较严重的HoL堵塞。梁佳诚等提出的均衡交叉节点缓存单组播调度(Multicast and Unicast Crossbuffer Balance,MUCB)算法[12],与以往基于轮询或者基于权重的调度算法不同,而是采用了均衡交叉节点缓存占用的思路,使交换机最大程度地逼近work-conserving状态。虽然MUCB算法使交换机的性能有了较好的改善,但没有采取有效机制以缓解HoL堵塞。 为了缓解组播HoL堵塞问题,通常在输入端口配置k个组播队列。因此,新到达分组需要按照一定的入队策略选择合适的队列入队。在已有研究中,多数基于三大准则[9]提出相应的入队策略,主要分为2类: 1) 静态入队策略,如文献[13]提出Module入队策略,利用分组扇出数取余的方法选择队列,即:i=Fmodk;实现简单,但扇出数目相同却不相关的分组会进入同一缓存队列,且对于小扇出分组均衡性差。文献[14]提出加权取模(Weighted Module,WM)入队策略改善了Module中小扇出组播均衡效果差的问题。文献[15]提出特征向量法(vector)选择分组扇出与队列特征向量距离最小的队列入队,增加了头分组扇出差异性,但负载均衡的效果一般。 2) 动态入队策略,如文献[9]提出的面向分组轮询分配(Cell oriented Round-Robin Assignment,CRRA)、面向突发轮询分配(Burst oriented Round-Robin Assignment,BRRA)、面向最短队列分组优先(Cell oriented Shortest Queue First,CSQF)和面向最短突发队列优先(Burst oriented Shortest Queue First,BSQF)等入队策略,存在分组失序问题。 本文通过研究HoL堵塞与work-conserving之间的关系,基于CICQ结构提出一种新的单组播混合调度算法, 即单组播低HoL堵塞(Multicast and Unicast with Low HoL Blocking,MULHB)算法,其基本思想就是以缓解HoL堵塞为目标,使交换机逼近work-conserving状态。同时,为了进一步缓解HoL堵塞,本文提出一种新的组播分组入队策略, 即动态组播分组入队(Dynamic Muticast Queuing,DMQ) 策略,使新到达分组根据缓存队列的状态可以动态选择合适的队列入队。 本文首先对CICQ结构单组播混合调度中的主要问题进行了分析;然后,具体说明了DMQ策略以及MULHB算法;最后,给出了本文提出算法的仿真结果,并和当前主流的单组播混合调度算法进行比较和分析。 本文讨论的CICQ交换结构如图1所示。每个输入端口分别配置N个单播队列和k(1 CICQ结构work-conserving状态是指,任一时隙中若交换机中存在去往某个输出端口的分组,则该时隙必有分组离开该输出端口。由于输入端口中组播队列的数目受到限制,因此,在调度过程中,属于同一组播队列的分组扇出去向不完全一致。此时,若组播队列的后续分组中存在使交换机满足work-conserving状态的扇出去向,而头分组中不存在,则发生了由HoL堵塞引起的非work-conserving问题。由于考虑整个组播队列中全部后续分组的扇出过于复杂,本文算法中仅考虑头分组对次分组的堵塞造成的影响。 为了尽量解决由HoL堵塞引起的非work-conserving状态,在每一时隙中,分组入队后、输入调度前,应使所有输入端口中存在若干不属于同一端口的头分组的扇出去向可以完全覆盖所有传输需求但对应节点缓存列为空的输出端口。为了达到上述条件,首先,可以通过入队策略动态调整新到达分组在队列排队状态。已有实用的静态入队策略由于选择队列的方式固定,分组入队后,相同扇出类型的分组不能根据调度的需求重新选择合适的队列入队。同时,仿真统计发现在调度过程中,输入端口内的缓存队列出现大量为空的状态。因此,入队策略应当使新到达分组根据当前缓存队列的状态动态选择合适的队列入队,尤其存在可选的空队列时,应充分选择空队列入队,使输入端口中头分组的扇出差异性增大。其次,为了使交换机达到高通过率及低时延的目标,应尽可能使交换机处于work-conserving状态。从文献[7]中给出交换机实现work-conserving的条件可知,在输入调度之后,所有的有传输需求的输出端口对应节点缓存列均不为空,从而使得输出端口总有分组离开。在此基础上,输入调度后,应使有助于交换机逼近work-conserving状态的次分组尽快成为头分组。最后,输出调度应尽快调度节点缓存中可能导致发生HoL堵塞的分组离开交换机。 图1 CICQ交换结构Fig.1 CICQ switch architecture 此外,在输入端口中采用的缓存配置方式对单播和组播分组进行隔离处理。由于2种业务之间存在一定的差异性,当输入调度在选择分组进入节点缓存内时,需要采用一定的裁决机制解决单、组播分组之间的竞争问题,以避免“饿死”现象发生。 由第1节分析可知,为使交换机避免发生由HoL堵塞引起的非work-conserving状态,本文采用新的入队策略控制分组入队,同时结合相应的输入输出调度算法使交换机尽可能在分组入队后、输入调度前,所有输入端口中存在若干不属于同一端口的头分组的扇出去向可以完全覆盖有传输需求但对应节点缓存列为空的输出端口。本节将从入队策略、输入调度和输出调度等环节详细分析DMQ-MULHB调度算法的设计。 当输入端口i有组播分组到达时,选择入队队列的具体步骤如下: 1) 分组到达时,若H[p]≠0,选择队列号等于F[p]值的队列入队,入队结束;否则进入步骤2)。 2) 若存在空队列,选择分组扇出与队列特征向量差异最小的队列,进入步骤5);否则进入步骤3)。 3) 若存在队长为1的队列,选择分组与头分组扇出差异最小的队列,进入步骤5);否则进入步骤4)。 4) 选择分组与队尾分组扇出差异最小的队列;若存在多个,则选择最短队列。 5)F[p]更新为所选队列序号,H[p]加1,选择F[p]对应队列入队,入队结束。当索引值为p的头分组在输入端口完全扇出时,H[p]减1。 由上述步骤可知,首先,步骤1)限定了新到达分组重新选择队列入队的条件,只有当该输入端口中相同扇出类型的分组缓存数目为零时,才能重新选择队列入队,该机制避免发生乱序;其次,步骤2)允许可重新选择队列的新到达组播分组进入空队列增加端口中头分组扇出差异,使队列头分组获得更多调度机会,以缓解了HoL堵塞,使交换机尽量逼近work-conserving状态。最后,步骤3)~步骤5)对于缓存分组具有均衡作用,同时尽量减少相邻分组间的扇出差异,当前一分组成为头分组时,可以缓解头分组对次分组造成的HoL堵塞。 本文提出MULHB算法,在输入调度过程中,首先,找出有传输需求且对应节点缓存列为空的输出端口;其次,找出扇出去向包含上述输出端口且头分组扇出去向类型数最少的输入端口;再次,从上述输入端口中找出满足工作保持状态的头分组;最后,从中优先选择可以完全扇出且对应次分组有助于交换机逼近work-conserving状态的头分组进行传输。在输入调度中尽量使交换机既在当前时隙实现work-conserving状态,又使输入端口中头分组扇出在后续时隙尽可能覆盖所有有传输需求的输出端口,从而避免交换机发生由HoL堵塞引起的非work-conserving状态。另外,在裁决单、组播分组之间的竞争时,组播分组的权重以头、次分组扇出、节点缓存状态以及头分组等待时间作为权重因子,单播分组的权重以等待时间作为权重因子。基于权重比较完成,避免“饿死”现象发生。在输出调度过程中,输出调度优先选择其次分组有助于交换机在后续时隙逼近work-conserving状态的头分组对应的节点缓存中的分组进行输出。 输入调度算法: 1) 初始化集合O包含所有输出端口,集合I包含所有输入端口。 2) 若集合O为空,则结束该时隙输入调度。 3) 从集合O的第1个元素开始,找出max{yj}对应输出端口j,若max{yj}=0,进入步骤11)。 4) 若集合J为空,从集合O中剔除输出端口j,回到步骤2)。 5) 从J的第1个元素开始,选择其中min{Di}对应输入端口i;找出输入端口i中存在扇出去向包含输出端口j且可完全扇出的组播头分组,进入下一步;否则,进入步骤8)。 6) 若步骤5)找出的头分组中存在次分组满足Sik>0,则选择max{Sik}对应的组播队列,进入步骤9);否则,进入步骤7)。 10) 从集合I中剔除输入端口i,更新U、J、Y,回到步骤3)。 11) 若集合I为空,该时隙输入调度结束。 12) 从集合I的第1个元素开始,若Mi中存在可完全扇出的头分组,进入步骤13),否则,进入步骤15)。 13) 若Mi中存在次分组满足Sik>0,则选择max{Sik}对应的组播队列,进入步骤16);否则,进入步骤14)。 输出调度算法: 1) 初始化集合O包含全部输出端口,集合I包含全部输入端口。 2)若集合O为空,则结束该时隙输出调度。 3) 从O的第1个元素开始,从输入端口中找出所有包含输出端口j扇出去向且状态不为空的Xij对应的队列;若存在,进入下一步;否则进入步骤7)。 4) 若步骤3)中找出的队列中存在次分组满足Sik>0,则选择max{Sik}对应的组播队列;否则,进入步骤6)。 6) 输出Xij中分组,从集合O中剔除输出端口j,回到步骤2)。 本节将基于CICQ交换结构对DMQ-MULHB算法进行仿真并对其性能进行评估。仿真采用Bernoulli和ON-OFF两种业务作为业务源模型。交换结构的端口规模为16×16,仿真时间为100万个时隙,每个输入端口设有8个组播队列。其中ON-OFF业务的平均突发长度为16。为了方便对性能进行分析,同时给出了最大扇出优先和最大服务比率优先(Maxfanout First and Maximum Ratio of Service First,MF-MRSF)算法、MUCB算法以及OQ调度的仿真结果进行对比,其中MF-MRSF算法、MUCB算法均采用Module入队策略。 在本次仿真中,假设单播业务占比fu,组播业务占比fm,组播分组平均扇出为|φ|,输入负载为λ,输出负载为μ,仿真结果中的负载均为输出负载,在单组播混合调度中,输入与输出负载之间的关系满足μ=λ(fu+|φ|fm)。 仿真中的非均匀业务为弱对角业务,对于输入端口i,其到达分组去向分布为 其中:uij为输入端口i的分组到达时,去往输出端口j的概率;ui为输入负载;ω为非均匀因子,仿真中将ω设为0.5。 低负载情况下,不同算法的性能差异性相对较小,本文给出高负载情况下的通过率及平均时延对比。 表1、表2给出了均匀业务下,fm=0.8时,各算法在归一化负载为0.90、0.95、0.99的通过率。可以看出,不同负载下,MULHB算法的通过率高于MF-MRSF及MUCB算法。 图2给出了均匀业务下平均时延的对比结果。从图中可以看出,MULHB算法的时延性能优于MF-MRSF及MUCB算法。 表1 均匀Bernoulli业务通过率Table 1 Throughput under uniform Bernoulli traffic 表2 均匀ON-OFF业务通过率Table 2 Throughput under uniform ON-OFF traffic 表3、表4给出了非均匀业务下,fm=0.8时,不同算法的通过率。MULHB算法的通过率要高于MF-MRSF及MUCB算法。 图3给出了非均匀业务下平均时延的对比结果。从图中可以看出,MULHB算法的时延性能显著优于MF-MRSF及MUCB算法,并且接近OQ调度。 通过仿真结果对比可以看出,无论是在均匀业务下还是非均匀业务下,DMQ-MULHB算法的性能相对于MUCB算法、MF-MRSF算法,都有了明显的提升。尤其在非均匀业务下,DMQ-MULHB算法的性能接近OQ调度。 图2 均匀Bernoulli和ON-OFF业务平均时延Fig.2 Average delay under uniform Bernoulli and ON-OFF traffic 表3 非均匀Bernoulli业务通过率Table 3 Throughput under non-uniform Bernoulli traffic 表4 非均匀ON-OFF业务通过率Table 4 Throughput under non-uniform ON-OFF traffic 图3 非均匀Bernoulli和ON-OFF业务平均时延Fig.3 Average delay under non-uniform Bernoulli amd ON-OFF traffic 1) 本文基于CICQ交换结构分析了单组播混合调度中HoL堵塞、节点缓存状态以及使交换机逼近work-conserving状态之间的关系。 2) 与已有研究中基于轮询机制或者基于最大权重匹配的调度算法不同,本文以缓解HoL堵塞问题为目标,尽量使交换机逼近work-conserving状态。 在上述分析的基础之上,本文提出了DMQ入队策略以及MULHB算法,通过仿真与现有性能较好的MUCB算法以及MF-MRSF算法进行对比,在均匀业务下,DMQ-MULHB算法的性能更好。尤其在非均匀业务下,DMQ-MULHB算法性能的表现有了显著的提升,并且接近OQ调度。1 问题分析
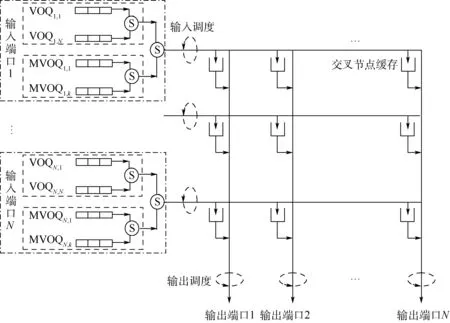
2 DMQ-MULHB调度算法
2.1 入队策略

2.2 MULHB调度算法
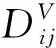
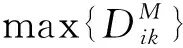
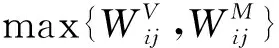

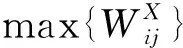
3 仿真及对比分析
3.1 流量模型
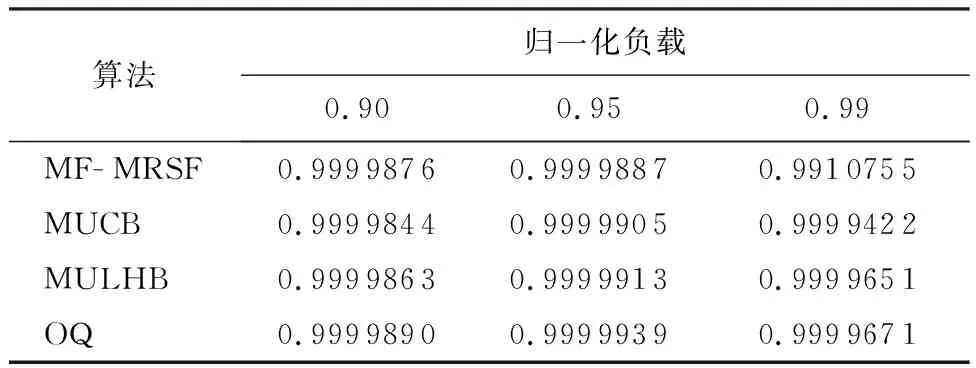
3.2 均匀业务
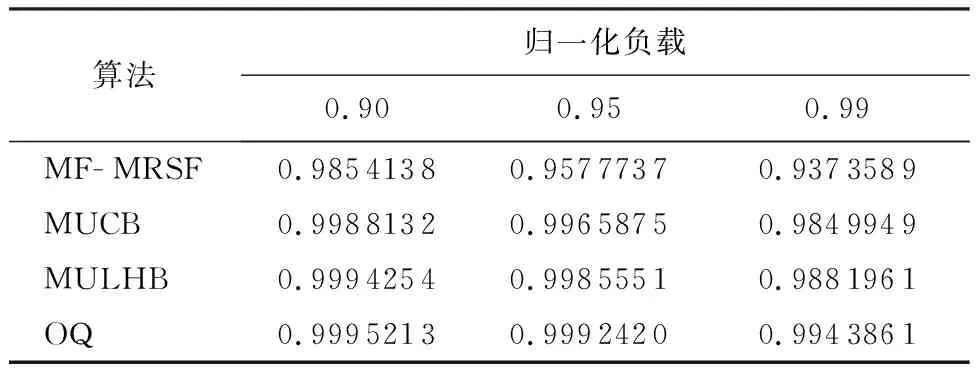
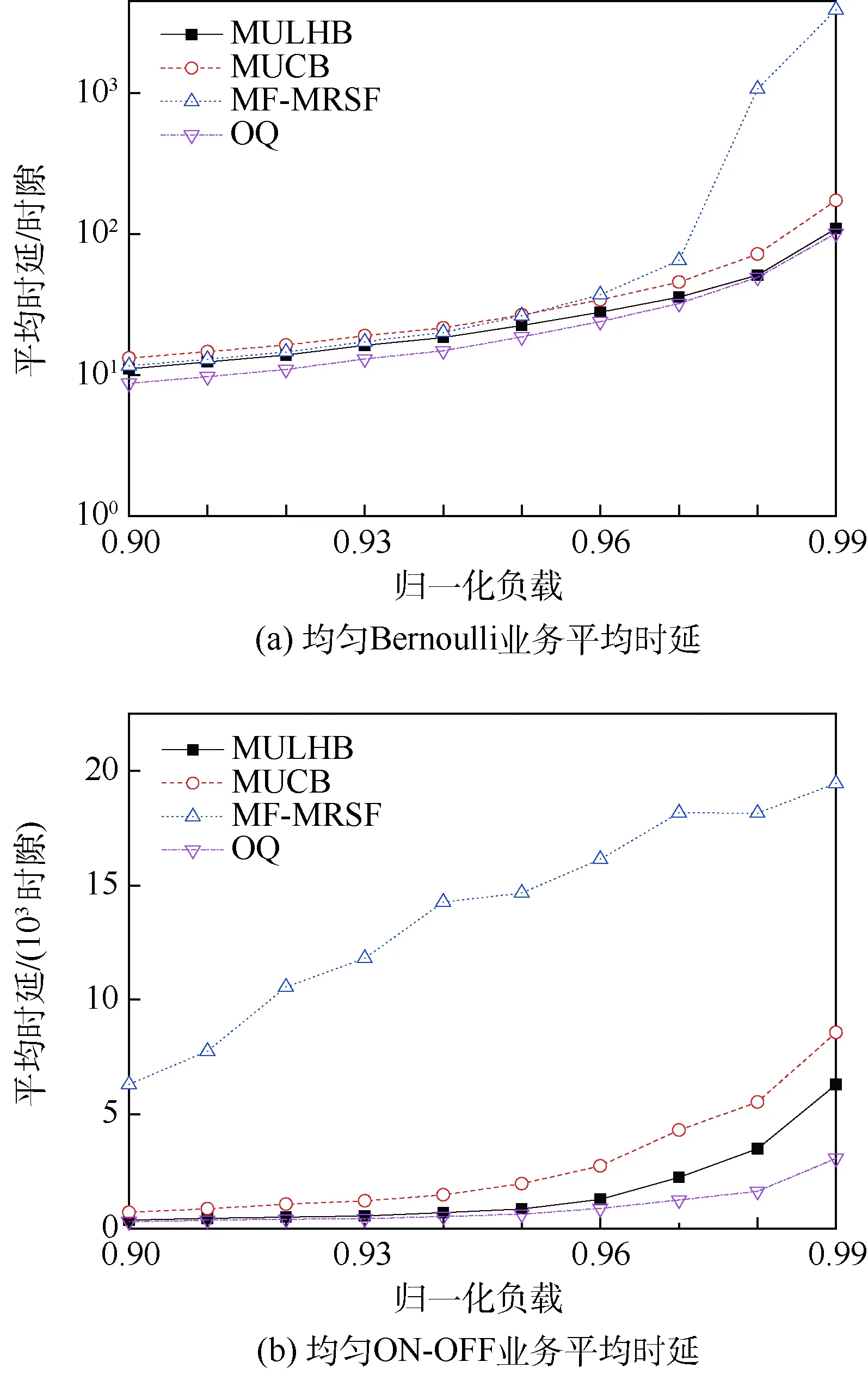
3.3 非均匀业务

4 结 论
猜你喜欢
少先队活动(2022年5期)2022-06-06课堂内外·创新作文小学版(2022年3期)2022-03-31汽车工程(2021年12期)2021-03-08科学导报·学术(2020年26期)2020-10-21小学生学习指导(低年级)(2020年4期)2020-06-02阅读与作文(小学低年级版)(2019年10期)2019-11-27小学生学习指导(低年级)(2018年10期)2018-10-13科学与财富(2016年24期)2017-03-29青年文学家(2016年32期)2016-12-23智能制造(2015年10期)2015-11-04
