
基于DIBR 视点合成的空洞填充方法
2019-03-04 08:31李晗
现代计算机 2019年1期
李晗
(四川大学计算机学院,成都610065)
0 引言
基于深度图像的渲染(DIBR)技术是生成多视点视频的一种实用方法,可以减少存储空间,节省传输带宽。然而由于前景参照物会遮挡到后景区域从而产生空洞,使得合成视频较原景象出现较大的偏差。
解决空洞问题一直是当前主流的研究方向,一般来说,有两种填充空洞的方法。一种是通过低通滤波器对深度图进行预处理,从而减小空洞区域。对称高斯低通滤波器和非对称滤波器来平滑整个深度图,使用着这种方法生成的虚拟图像会产生一定的几何失真。另一种类型的方法是使用视频的空间或时间相关性来填充空洞。在空间域中,视图混合方法可以通过使用多个视图可以填充大多数空洞区域,但是它们需要更多的拍摄设备并且会增加传输带宽的压力。因此,采用单个视图将更加具有优势。分层空洞填充方法对虚拟视图进行下采样然后逐渐上采样,其中不产生几何失真,但可以引入大孔周围的模糊区域。时间填充方法能够通过使用更多帧来获取被遮挡域中的纹理。在时间域中,当前景对象移开时,当前帧中的被遮挡的背景可能在其他帧中变得可见。背景重建可以利用2D 视频及其对应的深度图中的时间相关性信息来生成背景视频,该背景视频可以用于消除合成视频中的空洞。因此,采用一些背景模型来恢复被遮挡的背景。高斯混合模型(GMM)和前景深度相关(FDC)从几个连续的视频帧和深度图离线构建稳定的背景。如果前景对象缓慢移动或旋转,则GMM 可以将该前景对象视为稳定背景的一部分,因为真实背景在大多数帧中被前景对象遮挡。如果深度图不完美,则FDC 可能会产生一些尾。大多数基于背景模型的方法可能在构造的背景中带来一些前景纹理或者不适合于移动相机场景。本文提出了一种基于背景重建的填孔方法,其中去除前景物体,然后运动补偿应用于移动摄像机场景,最后通过改进的GMM 生成干净的背景视频。我们的方法适用于运动场景,可以防止模糊效果,或者在移除前景对象时从前景纹理中带来伪影。
1 前景提取
为了生成不含尾影的背景视频,需要从参考视图中的2D 视频及其深度图中移除前景对象。如何自动提取视频中的前景仍然是一个具有挑战性的问题。在我们提出的方法中,通过随机游走分割算法在参考视图中自动提取前景对象。为了将前景和背景的分离,构造了无向图G=(V,E)用于随机游走公式,其中V 是深度图中所有点的集合,E 是加权边集。定义vi 代表深度图中的第i 个点,v∈V。并使用典型的高斯加权函数定义节点之间的权重来解决标记问题。
其中gi表示像素i 处的深度值,β是平衡深度相似性成本的灵敏度的加权因子(例如,在此次的实验中β=90)。将顶点分为两组,标记节点VM和未标记节点VU,L 可以分解为:
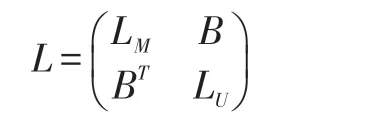
其中LM是标记节点的权重,LU是非标记节点的权重。求解标签的未知概率等价于求解矩阵方程:

其中xM和xU分别对应于标记和非标记节点的概率。另外,用表示节点xi属于标签s 的概率。将标记点的标签集定义为函数,其中s ∈S,S={s1,s2}。定义 | VM|×1为矢量,每个标签s 在节点vj∈VM为:

因此,求解Dirichlet 问题可以转换为:

利用初始标记节点,可以通过求解上述公式获得前景标签和背景标签的随机游走概率图,其结果如图1所示。

图1
2 动态背景重建
删除前景对象后,视频的剩余部分可用于重建清晰的背景。考虑到传统的背景重建方法不适合移动摄像机场景,采用了运动补偿和混合高斯模型(GMM)两个模块进行背景重建,从而实现动态场景中依旧可以获取清晰的背景。
2.1 运动补偿
运动补偿(MC)在视频滤波中非常有用,可消除噪声并增强信号。它允许滤波器或编码器基于构成图像序列在近似最大相关的路径上处理视频。运动补偿也用于所有分布质量的视频编码格式,因为它能够实现最小的预测误差,然后更容易编码。运动可以用速度矢量v 或位移矢量d 来表示,并用于将参考帧转换到目标帧上。运动估计可以目标帧中的每个像素,用于获得这些位移。
光流是从所谓的约束方程中设置,得到的视位移矢量场为d=( d1,d2)。

所有方法都从这个基本方程开始,这实际上只是一种理想化。理想的偏离是由于在所观察的场景中覆盖和揭露物体,在时间和场景中的物体之间的光变化,朝向或远离相机的运动,以及围绕轴的旋转。通常,约束方程仅在最小二乘意义上解决。此外,预期位移不是上式中假设的整数,通常需要使用某种类型的插值。
不能在逐个像素的基础上确定运动,因为每个像素有两个运动分量,因此未知数是方程的两倍。一种常见的方法是假设运动在称为孔径的小区域上是恒定的。如果光圈太大,那么我们将错过详细的运动,并且只能获得场景中物体运动的平均测量值。如果光圈太小,则运动估计可能很差到非常错误。事实上,所谓的孔径问题涉及图中所示的方形区域中的运动估计如图2 所示。

图2
如果均匀暗区的运动与其边缘平行,则无法检测到该运动。由于这种情况通常仅适用于自然图像中的小区域,因此孔径效应使我们选择不太小的孔径尺寸。因此,找到正确的孔径尺寸是取决于视频内容的重要问题。
另一个问题是覆盖和揭露,如图3 所示,显示了两个连续帧n 和n-1 的一维描述,一个物体向右移动。我们假设一个简单的对象在固定的背景上在前景中进行转换,而不是视频帧的不合理的局部近似。我们看到目标帧n 中的背景区域的一部分未被覆盖,而参考帧n-1 中的部分背景区域被覆盖。试图匹配两个帧中的区域的运动估计将无法在覆盖或未覆盖区域中找到良好匹配。但是,在其他背景区域内,匹配应该是好的,并且在纹理对象内匹配也应该是好的,至少如果它可以按跟踪的方式移动,并且像素样本足够密集。相对较小的覆盖/未覆盖区域中的问题是存在两个运动。
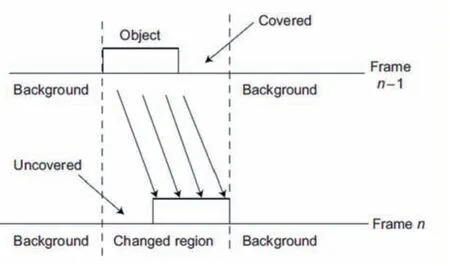
图3
2.2 混合高斯模型
混合高斯模型(GMM)属于背景建模法中的一种,本文使用的GMM 在整个过程不断的更新和学习因此对背景图具有一定鲁棒性,并且非常适用于动态场景。以下为建造GMM 的具体步骤:
(1)为矩阵的模型进行参数初始化。首先对模型进行训练,使用视频中的T 帧用来训练GMM 模型。为每一个像素建立其模型个数最大高斯的GMM 模型。单独为第一个像素在程序中设置好其固定的初始值。
(2)非第一帧训练过程中,当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3 倍的方差内,则任务属于该高斯。此时用如下方程进行更新:

(3)当到达训练的帧数T 后,进行不同像素点GMM 个数自适应的选择。首先用权值除以方差对各个高斯进行从大到小排序,然后选取最前面B 个高斯,使其满足:
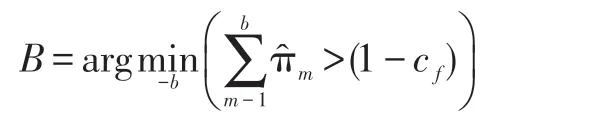
(4)在测试阶段,对新来像素点的值与B 个高斯中的每一个均值进行比较,如果其差值在2 倍的方差之间的话,则认为是背景,否则认为是前景。
3 实验结果
使用多视点MVD 序列(Ballet)来测试我们在实验中提出的方法的性能,并与Criminisi 提出的基于样本的修复方法进行比较,比较结果如表1 所示。
在我们的实验中,PSNR 用于测量合成和参考图像像素的平方强度差异,并且SSIM(结构相似性)用于测量合成图像和参考图像之间的结构相似性。所提出的方法和测试序列的Criminisi 方法的平均PSNR 和SSIM 值显示在表1 中,其中'测试序列'表示数据集和投影信息。结果表明,所提出的方法产生了较好的整体结果。与Criminisi 方法相比,本文所提出的方法有一定的提升。

表1
4 结语
本文通过提取并去除二维视频中的前景对象和参考视图中的深度图,并使用运动补偿构造稳定的背景。我们的研究表明,利用所提出的背景模型可以生成不带前景物体伪影的纯净背景,从而可以消除遮挡区域中的模糊效应或伪影,并且消除前景边界上的尖锐边缘。
猜你喜欢
今日农业(2021年7期)2021-07-28
建材发展导向(2021年6期)2021-06-09
建材发展导向(2021年24期)2021-02-12
小天使·二年级语数英综合(2019年4期)2019-10-06
中国外汇(2019年11期)2019-08-27
小学生学习指导(低年级)(2019年6期)2019-07-22
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
电脑知识与技术(2016年13期)2016-06-29
