
上市公司信息披露的文字主观叙述与盈余操纵
——基于机器学习法提取主观模式的研究
2019-03-01 07:55毛怡欣
商业研究 2019年1期
毛怡欣
(厦门大学 管理学院,福建 厦门 361005)
内容提要:选取2006-2016年沪深A股上市公司样本,研究上市公司是否会操纵文字信息披露,以更主观的方式叙述来配合上市公司的盈余操纵行为。利用机器学习法提取2-POS主观模式,构建了可量化的文字叙述的主观性指标,通过实证检验发现,处于财务重述前,即在盈余操纵隐藏期间,上市公司年报中使用的主观句比例更高、整体主观性分数也更高;进一步的研究发现,良好的外部市场环境和内部治理环境会抑制上市公司利用主观色彩更浓的信息叙述来配合其盈余操纵的行为。本文的研究既为上市公司操纵文字信息披露的动机提供了新的证据,补充了财务数据与文字信息披露关系的相关研究,也为监管部门加强信息披露监管以及外部信息使用者判断信息质量提供了新的实证依据。
一、引言
公司年报中有大量的文字叙述,对财务状况和其他重要的非财务状况进行说明和解释,这些文字叙述是非常重要的展示上市公司的方式(Li,2010)。虽然监管部门要求上市公司进行信息披露时必须保证其内容客观真实,但是上市公司在进行相关事实的文字叙述时,叙事者是难以跳脱出自身的认知模式、完全不带任何自身的态度和感情色彩的(沈家煊,2001),并且由于语言的复杂性,相关监管部门也难以制定出系统的、可量化的标准来对上市公司的相关文字叙述进行统一的规范。因此,上市公司年报的文字叙述很难达到完全客观、不带任何上市公司自身的立场和感情色彩(Baginski等,2016)。尽管上市公司在年报的文字叙述难以摆脱主观性印记,主观性在各上市公司年报中普遍存在,但是各公司年报主观性程度是不同的。有的上市公司在叙事时尽量的还原事实,使文字叙述成为向外部人员传递信息的重要渠道,从而使外部投资者掌握更多有效信息做出更准确的决策;但是有的上市公司会利用更主观的叙述来模糊或转移焦点,故意夸大对上市公司有利的事实以及故意削弱对上市公司不利的事实,误导外部信息使用者。上市公司的财务数据与文字信息是相辅相成的,上市公司披露的相关财务数据需要利用文字进行进一步说明和解释,管理状况、发展前景等其他重要的非财务状况的文字叙述又是财务信息的重要支撑,所以,文字信息和财务数据不是相互独立的(Loughran和Mcdonald,2016)。那么上市公司若进行了盈余操纵,就会有强烈的动机操纵文字叙述,对相关事实进行更主观的叙述,运用词汇和句法等方式削弱某些事实的真实性,以此来配合盈余操纵,以避免相关操纵行为被外部信息使用者发现。因此,构建一套可量化的指标衡量上市公司年报文字的主观程度,对上市公司信息披露进行实证检验是有必要的。本文通过机器学习法对年报语料进行训练提取2-POS主观模式对年报文字叙述的主观性特征进行度量后,对上市公司文字叙述是否配合盈余操纵进行的实证检验。
二、文献回顾和研究假设
(一)文本挖掘方法的使用及研究
近年来,随着机器学习、自然语言处理技术的发展,文本挖掘方法越来越多地被应用到对上市公司会计文本的定量分析中。其中关于对文本主观性的研究起始于对英文语料的研究,早期的研究认为形容词的使用是判断主观性的重要特征,因此利用标识形容词来计算文本的主观性(Hatzivassiloglou和Wiebe,2000),这也激发了学者对其他词性与主观性关系的研究。Riloff等(2003)发现名词也与语句的主观性存在很强的相关性,通过Bootstraping算法得出1052个主观性的名词,然后将这些主观性名词作为判断语句主观性的特征。随后,有学者在前人的基础上又突破了仅以单个的词语作为标识语句主观性的依据,叶强等(2007)基于中文的语料提出了利用连续双词词类模式(2-POS模式)作为判断语句主观性的依据。目前国内已经有较多学者将2-POS模式进一步应用到对中文的主观性判断中,并且验证了利用2-POS模式判断中文主观性的可行性。张文文和王挺(2013)在比较了6种不同的主客观分类方法后,发现基于2-POS模式的方法效果是最好的。虽然大多关于文本主观性研究的语料是基于互联网的评论、微博和新闻等,这些语料与上市公司披露的会计文本的语料有一定的差异。但段钊等(2017)也将2-POS模式应用到上市公司的社会责任报告的文本分析中,发现利用2-POS主观模式对主观句的查全率和查准率可以达到90%以上,这表明了利用2-POS模式对上市公司披露的会计文本进行主观性分析是可行的。
(二)文字主观性与盈余操纵
许多研究显示上市公司对文字信息披露进行的策略性管理更多的是为了转移外部信息使用人员对不利消息的关注或模糊上市公司的不利消息,即出于信息模糊动机而进行文字信息披露的操纵。例如,Bonsall等(2013)发现当上市公司面临的不确定越高,就会披露更多与盈余无关的前瞻性信息;Merkley(2014)也发现当上市公司的业绩较差时会披露更多关于研发的信息,并且当公司绩效较差时,上市公司年报的可读性也会越差。上市公司年报中的财务数据和文字信息之间并不是相互独立的,财务数据由准确的数字构成可以提供更为客观的公司状况,年报中的文字叙述可以反映结构化的财务数据无法反映的更多细节信息,例如财务数据相关的会计准则和管理者动机,外部信息使用者在了解了相关会计准则后,可以更准确地理解财务数据的含义,上市公司对外公告的财务数据与文字叙述之间是相互联系和相互印证的。相关的研究也显示了上市公司的会计文本信息对财务数据起到补充作用而不是替代作用,例如Bochkay和Levine(2013)发现结合财务数据和管理层讨论与分析的文本信息才可以做出更准确的盈余预测,上市公司的文本信息也会影响财务数据与市场反应之间的关系。因此,为了隐藏上市公司的盈余操纵行为,上市公司就会有强烈的动机采取对文字信息也进行操纵的手段,提供更模糊的相关事实的信息以避免相关盈余操纵行为被外部人员发现。虽然利用文字对相关事实进行叙述时难以避免叙述者所带的立场和感情从而难以达到绝对客观(沈家煊,2001),上市公司年报中的文字叙述可能普遍存在着一定程度上的主观性,但是各上市公司的文字叙述所带的主观色彩程度并不是完全一致的,其中也大量存在有主观目的性的。
对前期财务报告中的财务数据进行更正的财务报告重述(即“财务重述”)行为经常性地在一定程度上隐藏了上市公司的盈余操纵行为(Richardson等,2002;Lev,2003;周晓苏和周琦,2011)。通过以我国上市公司为研究样本的实证检验发现,我国上市公司财务重述泛滥的主要原因就在于上市公司为了掩盖其不良经营状况进行的盈余操纵(于鹏,2007);上市公司及其管理层盈余操纵行为一旦实施,财务重述就会随即发生 (Lo等,2017)。魏志华等(2009)通过梳理我国上市公司年报重述情况后也认为监管部门需要重点关注上市公司的财务重述中可能存在的盈余操纵。许多学者也在实证研究中把财务重述作为上市公司进行盈余操纵的表征,例如,程新生等(2015)利用财务重述作为上市公司盈余操纵的表征,实证检验盈余操纵与MD&A中的非财务信息披露之间的配合;张璇等(2016)也把财务重述作为上市公司盈余质量的代理变量。因此,本文选择在财务信息披露以后进行过财务重述,但该年报还未被重述,公司进行了盈余操纵但还处于隐藏期间的年报作为样本,来研究上市公司是否会在该财务报告中以更主观的文字叙述来配合其盈余操纵行为。若上市公司的年报处于财务重述前的状态,这时上市公司处于盈余操纵隐藏期间,上市公司是具有为了隐藏和配合其盈余操纵行为,策略性披露更主观的文字叙述的动机的。因此,本文提出了以下假设。
假设1:相较于其他没有进行过财务重述的上市公司,进行过财务重述的上市公司在财务重述公告前,即在隐藏期间,其尚未被更正的年报中会使用更多的主观句式。
假设2:相较于其他没有进行过财务重述的上市公司,进行过财务重述的上市公司在财务重述公告前,即在隐藏期间,其尚未被更正的年报文字部分的整体主观性更高。
三、研究设计
(一)样本选择和数据来源
本文选取2006-2016年沪深两市的A股上市公司作为研究样本,剔除了金融行业样本、上市时间不超过两年的样本以及相关变量缺失的样本后,一共得到了11715个样本数据,其中在年报披露后进行过财务重述但当前处于还未被重述的状态的年报样本共有655个。由于在进行进一步分析时涉及了不同变量,导致变量缺失情况不同,因此样本数略有不同。上市公司的年报数据来自于Wind数据库,财务重述公告数据来自于国泰安数据库,内部控制指数数据来自于迪博数据库,其他相关变量数据来自于锐思数据库。为了消除极端异常值的影响,本文对所有连续变量都进行了1%和99%水平下的Winsorize缩尾处理。本文的行业分类标准为证监会门类行业。
(二)变量度量
1.被解释变量。本文的被解释变量为主观句占比(Sub_1)和主观性分数(Sub_2)。本文采用2-POS模式(将句子按照词性进行分词,2个连续词的顺序组合就构成1个2-POS模式)来对语句主观性进行度量。提取2-POS主观模式以及计算主观句占比(Sub_1)、主观性分数(Sub_2)这两个变量的具体步骤如下所示:
第一步,在上市公司年报中的文本中随机抽取2000个句子,请3位志愿者分别对这2000个句子属于主观句还是客观句进行标注,若有两位志愿者以上将语句标注为主观句,那么将该句划分为主观句,否则划分为客观句,一共得到744句主观句和1256句客观句,再随机抽取500句主观句和500句客观句,构建训练年报语料的样本。
第二步,利用LTP(Language Technology Platform)分词系统对训练样本进行分词和词性的标注,将所有主观句和客观句中的按顺序组合的连续双词模式(2-POS模式)提取出来,计算所有主观句中的2-POS模式的χ2值并排序,选取前20个2-POS模式作为2-POS主观模式。χ2值的计算公式如下:
(1)
其中,N表示主观句和客观句总数,A表示主观句中包含该2-POS模式的句数,B表示客观句中包含该2-POS模式的句数,C表示主观句中不包含该2-POS模式的句数,D表示客观句中不包含该2-POS模式的句数。
第三步,计算前20个2-POS主观模式的查准率和查全率,即按照利用该2-POS模式判断出的主观句的准确率和比例作为该2-POS模式的查准率和查全率,具体计算公式为:

(2)

(3)
将2-POS主观模式的查准率作为主观性分数的权重。表1报告了提取的20个2-POS主观模式的查准率和查全率。

表1 2-POS主观模式
第四步,利用LTP(Language Technology Platform)分词系统将所有样本的年报进行分词和词性标注后,提取每一份年报中每句话中包含的2-POS模式,然后标识年报中包含的2-POS主观模式,再加总每句话中各自包含的2-POS主观模式与其主观权重乘积。当按主观和客观进行分类设置阈值时,发现将阈值设置为0时,主客观分类的查准率和查全率都达到90%以上,因此本文将判断主客观句的阈值设置为0,即加总该句话中包含的2-POS主观模式与其主观权重乘积大于0,那么将该句分类为主观句,否则将该句分类为客观句。因此可计算出年报中的主观句占比(Sub_1)和主观性分数(Sub_2),Sub_1和Sub_2的具体计算公式分别如下所示:
(4)
(5)
公式(4)中的sub_count表示年报中包含的主观句数,ob_count表示年报中包含的客观句数;公式(5)中的ni表示年报中包含的第i个2-POS主观模式的频数,weihgti表示第i个2-POS主观模式的主观权重,2-POS_count表示包含的所有2-POS模式个数。
2.解释变量。本文的解释变量为财务重述前(Restate_pre),若上市公司在披露年报之后对该年报进行了财务重述,那么在该年报还未进行财务重述之时,变量取值为1,否则取值为0。在经过处理后,一共得到了655个财务重述前的样本。
3.控制变量。本文选取了公司规模(Size)、资产负债率(Lev)、总资产报酬率(ROA)、公司成长性(Growth)、分析师关注度(Follow)、机构持股比(Ins)、董事会规模(BDS)、独董比例(Indep)、是否国有控股(State)这些对上市公司信息披露可能会有显著影响的因素作为控制变量。除此以外,为了控制上市公司年报披露在不同年份和不同行业之间的差异,还控制了行业虚拟变量(Industry)和年份虚拟变量(Year)。表2报告了本文涉及的主要变量的定义和计算方法。

表2 变量定义以及计算方法
(三)模型设定
为了检验假设1和假设2,构建了如下回归模型:
Sub_1i,t=α0+β1Restate_prei,t+β2Sizei,t+β3Levi,t+β4ROAi,t+β5Growthi,t+β6Followi,t+β7Insi,t+β8BDSi,t+β9Indepi,t+β10Statei,t+∑Industry+∑Year+εi,t
(I)
Sub_2=α0+β1Restate_prei,t+β2Sizei,t+β3Levi,t+β4ROAi,t+β5Growthi,t+β6Followi,t+β7Insi,t+β8BDSi,t+β9Indepi,t+β10Statei,t+∑Industry+∑Year+εi,t
(II)
分别以Sub_1和Sub_2作为回归模型(I)和回归模型(II)的被解释变量;回归模型(I)和回归模型(II)的被解释变量为Restate_pre,控制变量为Size、Lev、ROA、Growth、Follow、Ins、BDS、Indep、State;采用行业和年份固定效应模型;回归模型中各变量的具体定义和计算方法如表2所示。若回归模型(I)和回归模型(II)中解释变量Restate_pre的回归系数β1显著为正,那么假设1和假设2成立。为了解决内生性问题以及进行稳健性检验,本文进一步采用倾向性评分匹配(PSM)方法为处于财务重述前的样本进行1:1匹配选取控制组样本,利用匹配后的样本再次对回归模型(I)和回归模型(II)进行回归,以及构建双重差分模型进行检验,除此以外还采用修正Jones模型计算上市公司的盈余管理作为盈余操纵代理变量重新进行回归。
四、实证结果分析
(一)主要变量描述性统计和相关性分析
表3报告了本文涉及的主要变量的描述性统计结果。其中:上市公司年报中的主观句占比的平均值为0.3444,表示年报中的语句中平均有大约34%比例的为主观句;年报的整体得分平均为0.1157,而主观性分数最低为0.088,最高得分为0.1831。从主观句占比和主观性分数的描述性统计结果来看,最小值都大于0并且都没有趋近于0,这表明上市公司在年报中的文字叙述中普遍都带有主观性色彩,但是不同上市公司的年报主观性程度是有差异的;财务重述前的平均值为0.0559,这表示约有5.6%的上市公司年报处于盈余操纵隐藏期间。根据是否国有的平均值来看,样本中国有控股公司的比例接近30%。其他公司特征在不同上市公司之间也存在着一定的差异,资产负债率、总资产报酬率、公司成长性、分析师关注都有较大的差异;资产负债率最小值仅有4.78%,而最大值达到了107.44%;总资产报酬率最低为-7.87%,最高为19.85%;公司成长性最小值为-0.616,而成长性最高的公司的营业总收入增长近2倍;有的上市公司没有分析师关注,而有的上市公司多达36位分析师对其进行跟踪;上市公司最低机构持股比例为0,最高机构持股比例达84.25%。
表4报告了本文涉及的主要变量之间的Pearson相关系数。其中:年报的主观句比例与主观性分数之间的相关系数为0.7407,在1%水平下显著,主观句比例和主观性分数有较强的正相关关系;财务重述前与主观句比例、主观性分数的相关系数分别为0.0905和0.0836,并且在1%水平下显著,解释变量与被解释变量之间都有显著的正相关关系。支持假设1和假设2。解释变量与其他控制变量之间的相关系数都不超过0.3,虽然在控制变量中,公司规模与分析师关注度、公司规模与机构持股比、分析师关注度与机构持股比、董事会规模与独董比例的相关系数超过了0.3,但在进行回归检验时进行了多重共线性检验,方差膨胀因子(vif值)都小于5,因此,本文的回归模型不存在多重共线性问题。

表3 主要变量描述性统计结果
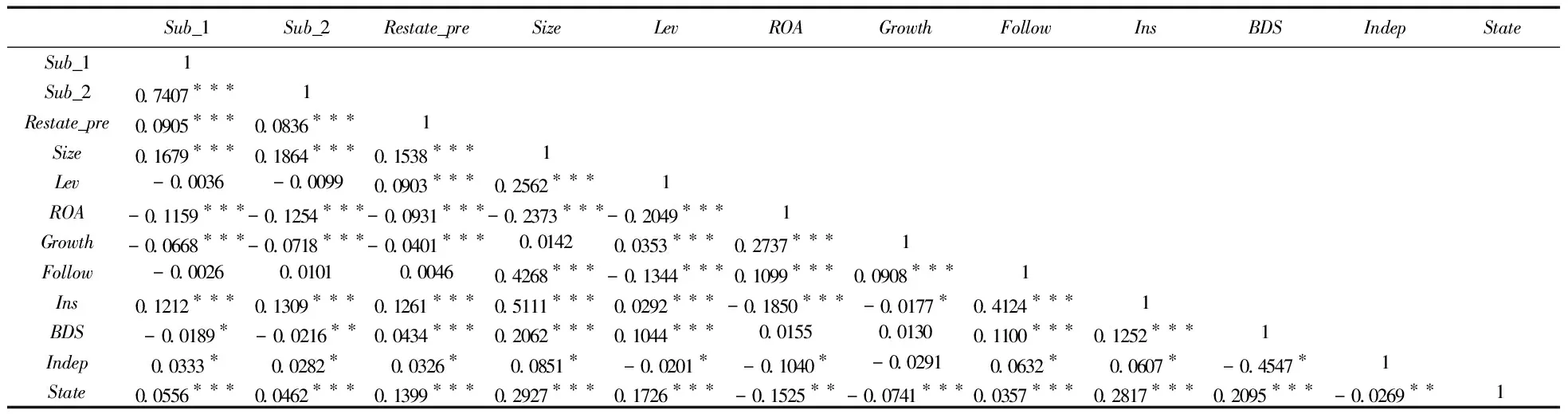
表4 主要变量Pearson相关系数
注:*表示在10%水平下显著,**表示在5%水平下显著,***表示在 1%水平下显著(下同)。

表5 主要变量是否处于财务重述前的差异
本文进一步以上市公司年报是否处于财务重述前为划分标准将样本划分为两组子样本进行了描述性统计,表5报告了两组子样本主要变量的样本数和平均值、两组子样本主要变量之间的均值差以及对两组子样本主要变量之间的平均值是否有显著差异进行的t检验结果。根据表5报告的数据,除了分析师关注度以外,其他主要变量的平均值在两组样本之间都有显著的差异。其中,没有处于财务重述前的年报的主观句比例平均为34.36%,处于财务重述前的年报的主观句比例平均为35.87%,经过t检验,没有处于财务重述前的年报的主观句比例显著低于处于财务重述前的年报。没有处于财务重述前的年报的主观性分数平均为0.1154,而处于财务重述前的年报的主观性分数平均为0.1205,根据t检验结果,没有处于财务重述前的年报的主观性分数也显著低于处于财务重述前的年报。从分组描述性统计结果来看,处于财务重述前的年报的文字叙述的主观性程度更高。

表6 财务重述前与年报主观句比例、主观性分数
(二)财务重述前与年报主观性
表6报告了回归模型(I)和回归模型(II)的回归结果。其中:第2列报告了以年报主观句比例(Sub_1)作为被解释变量的回归结果,控制了相关影响因素后,解释变量财务重述前(Restate_pre)的回归系数为0.0059,在1%水平下显著,财务重述前与主观句占比显著正相关;第3列报告了以年报主观性分数(Sub_2)为被解释变量的回归结果,加入控制变量后,解释变量财务重述前(Restate_pre)的回归系数为0.0014,也在1%的水平下显著,财务重述前与主观性分数显著正相关;回归结果表明处于财务重述前状态的年报中使用的主观句的比例更高、年报的整体主观性分数也更高,上市公司在盈余操纵隐藏期间,会使用更主观的文字叙述配合其盈余操纵行为,与本文提出的假设1和假设2的预期是一致的。
(三)上市公司外部市场环境的影响
不同地区的上市公司所面临的外部市场化环境是不同的。在市场化程度较高的地区,上市公司面临更为有效的外部治理机制,上市公司与外部人员之间的信息传递效率可能会更高,这可能会使上市公司操纵年报文字信息披露隐藏盈余操纵行为的动机减弱,因此上市公司面临的外部市场环境可能会影响上市公司年报中的主观文字叙述与盈余操纵之间的关系。为了进一步检验上市公司所处的外部市场环境是否影响盈余操纵对主观文字叙述的影响,本文根据王小鲁等(2016)编制的中国分省份市场化指数,将样本划分为市场化程度较低(MKT-L)和市场化程度较高(MKT-H)两组,进行分组回归检验。计算各地区的市场化指数中位数,上市公司所在地区的市场化程度低于中位数,那么将其划分为市场化程度较低组,反之则将样本划分为市场化程度较高组。除了利用王小鲁等(2016)编制的市场化指数进行分组以外,东部和中西部地区之间的市场化发展程度有显著差异,因此本文还将样本以上市公司所在省份属于东部还是中西部划分为东部和中西部两组,进行分组回归检验。
表7报告了外部市场环境影响的检验结果,其中,第2列至第5列报告了市场化程度较高组和市场化程度较低组的分组回归结果,第6列至第9列报告了东部组和中西部组的分组回归结果。从第2列和第4列的回归结果来看,在市场化程度较高的情况下,是否处于财务重述前(Restate_pre)对主观句比例(Sub_1)和主观性分数(Sub_2)没有显著的影响;而第3列和第5列的回归结果显示在市场化程度较低的情况下,财务重述前(Restate_pre)对主观句比例(Sub_1)和主观性分数(Sub_2)的影响显著为正。第6列和第8列显示,在东部地区,财务重述前(Restate_pre)对年报中的主观句比例(Sub_1)和年报的主观性分数(Sub_2)没有显著的影响;而第7列和第9列的回归结果显示,在中西部地区,财务重述前(Restate_pre)与主观句比例(Sub_1)、年报的主观性分数(Sub_2)都是在1%水平下显著正相关。综合表7的分组回归结果,上市公司的外部市场环境发展程度越好,上市公司操纵年报文字叙述以掩盖盈余操纵的动机就会减弱,高程度的市场化环境可以抑制上市公司在年报中采用较多的主观叙述进行策略性的披露;而上市公司在面临较差的市场化环境时,更容易利用主观叙述配合其盈余操纵,在外部市场化程度发展较低时,盈余操纵与主观叙述之间的关系更为显著。
(四)上市公司内部治理环境的影响
除了外部市场环境会影响上市公司的信息披露行为以外,前人的研究也显示了公司内部的治理环境也会影响上市公司信息披露行为(李慧云等,2013)。若上市公司内部治理环境良好,可能会约束管理层对信息披露的操纵,因此内部治理环境更好的上市公司利用主观性叙述掩盖盈余操纵的可能性会降低。本文选取了是否两职合一、董事会规模、独董比例、监事会规模、前十大股东持股比例、机构持股比例这些公司治理指标,利用主成分分析法构建了上市公司的公司治理指数,将公司治理指数高于中位数的上市公司划分为公司治理环境较好的一组(GI_H),低于中位数的上市公司划分为公司治理环境较差的一组(GI_L),分别对两组样本进行回归检验。本文还利用了迪博数据库的内部控制指数将上市公司划分为内部控制环境较好(IC_H)和内部控制环境较差(IC_L)两组样本,内部控制指数高于中位数则划分为内部控制环境较好一组,低于中位数,则划分为内部控制环境较差一组,然后也对两组样本进行分组回归检验。
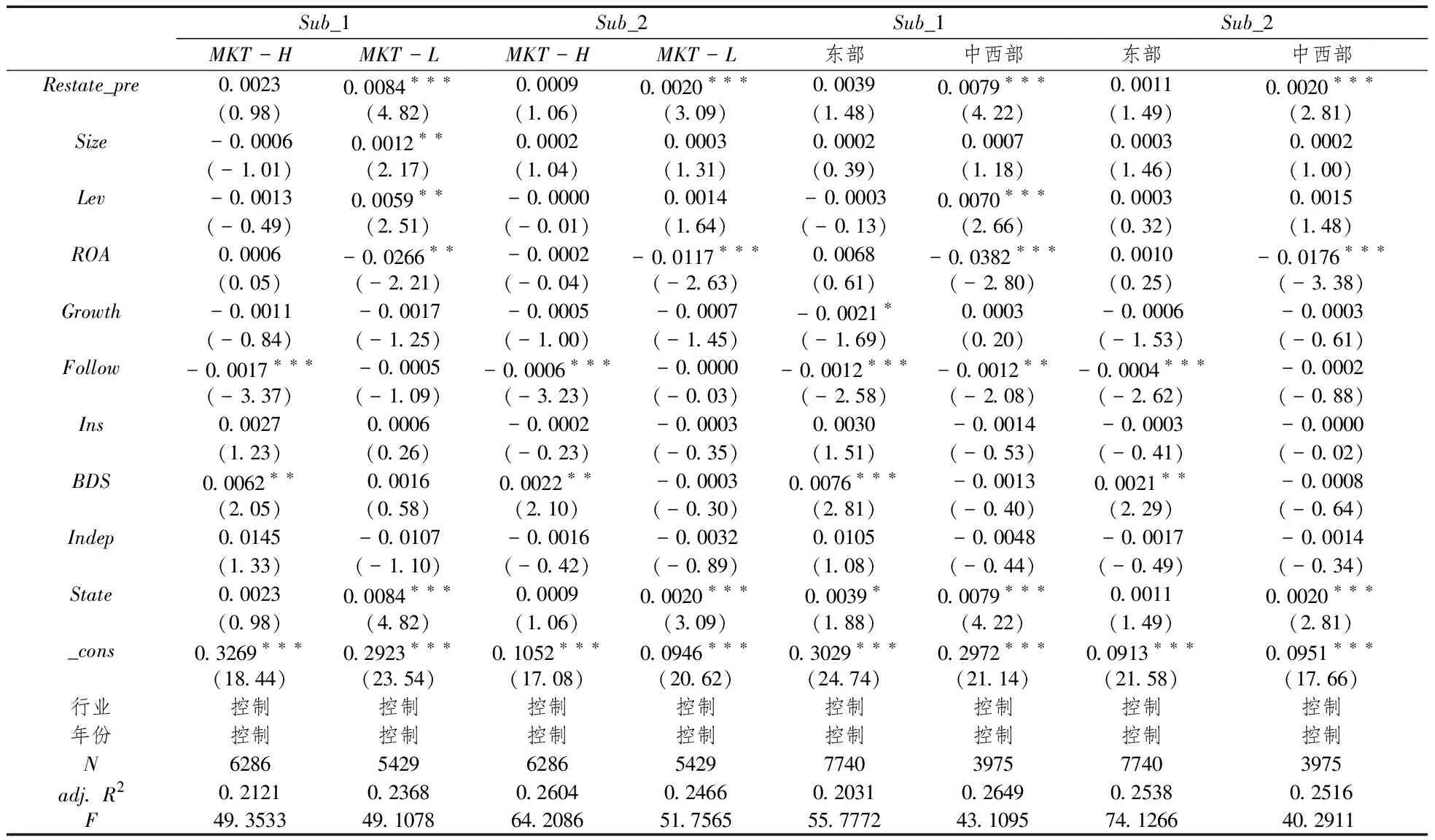
表7 外部市场环境影响

表8 内部治理环境的影响
表8报告了上市公司内部治理环境对年报主观叙述的影响。其中:第2列至第5列报告了以公司治理指数分组的回归结果,回归结果显示只有在公司治理环境较差的情况下(GI_L),财务重述前(Restate_pre)的回归系数显著为正,在公司治理环境较好的情况下(GI-H),财务重述前(Restate_pre)的回归系数并不显著。第6列至第9列中报告了以内部控制指数分组的回归结果,只有在内部控制环境较差的情况下(IC_L),财务重述前(Restate_pre)的回归系数显著为正,当上市公司的内部控制较好时,财务重述前(Restate_pre)对年报的主观句比例(Sub_1)和主观性分数(Sub_2)没有显著影响。因此根据表8报告的分组回归结果,上市公司良好的内部治理环境会抑制操纵文字信息披露配合盈余操纵的行为,而较差的内部治理环境会使上市公司操纵文字叙述,以带有更多主观色彩的描述与盈余操纵相配合。

表9 PSM匹配样本和DID模型回归结果
(五)稳健性检验
1.倾向性评分匹配(PSM)。在前文的回归检验中,采用了整体混合样本进行检验,本文在稳健性检验中进一步采用倾向性评分匹配方法进行1:1匹配,为发生过财务重述的上市公司在没有发生过财务重述的上市公司中寻找配对样本,以配对后得到的实验组和控制组的样本重新对回归模型(I)和回归模型(II)进行回归。首先将进行过财务重述的上市公司的公司年标记为实验组(treat=1),没有发生过财务重述的上市公司的公司年标记为控制组(treat=0);选取的匹配变量为:行业(Industry)、上市年份(Age)、公司规模(Size)、资产负债率(Lev)、总资产报酬率(ROA)和营业总收入增长率(Growth),然后进行Logit回归;根据倾向性评分对每一个财务重述前的样本进行最近邻一对一匹配,最终得到632组(1264个)配对样本。表9中的第2列和第3列报告了PSM匹配样本的回归结果,财务重述前(Restate_pre)的回归系数仍然显著为正,利用PSM方法得到匹配样本进行的稳健性检验得到的回归结果与前文的回归结果是一致的,仍然支持本文提出的假设1和假设2,上市公司会在年报中采用更主观的叙述配合盈余操纵行为。
2.双重差分模型。本文进一步设计了双重差分模型(DID)对内生性问题进行检验,双重差分模型如下所示:
Sub_1i,t=α0+β1Resi,t+β2Prei,t+β3Resi,t×Prei,t+β4Sizei,t+β5Levi,t+β6ROAi,t+β7Growthi,t+β8Followi,t+β9Insi,t+β10BDSi,t+β11Indepi,t+β12Statei,t+∑Industry+∑Year+εi,t
(III)
Sub_2=α0+β1Resi,t+β2Prei,t+β3Resi,t×Prei,t+β4Sizei,t+β5Levi,t+β6ROAi,t+β7Growthi,t+β8Followi,t+β9Insi,t+β10BDSi,t+β11Indepi,t+β12Statei,t+∑Industry+∑Year+εi,t
(IV)
在回归模型(III)和回归模型(IV)中,Res定义为是否发生过财务重述的虚拟变量,若上市公司发生过财务重述,那么取值为1,否则取值为0。Pre定义为财务重述隐藏期间的虚拟变量(隐藏期可能大于一年),在上市公司还未发布财务重述公告,取值1,发布了财务重述公告后,取值0;若是PSM配对样本,若处于其配对样本还未进行财务重述公告前的期间,Pre取值1;若处于其配对样本进行财务重述公告后的期间,Pre则取值0。回归模型(III)和回归模型(IV)中的Res和Pre的交乘项的回归系数β3是本文关注的双重差分的估计量,表示盈余操纵对主观句比例和主观性分数的净影响。表9的第5列和第6列报告了DID模型的回归结果,根据表中报告的数据,交乘项的回归系数都显著为正,这表明相较于没有进行过财务重述的上市公司,进行过财务重述的上市公司在进行财务重述公告前披露的年报的主观句比例更高、主观性分数也更高,这与前文的结论也是一致的。
3.其他稳健性检验。本文还选取了盈余管理(|DA|)作为盈余操纵的代理变量再次进行回归检验,本文采用修正Jones模型计算上市公司的盈余管理,首先估计回归模型:
TAi,t/Ai,t-1=α1*1/Ai,t-1+α2*(ΔREVi,t-ΔRECi,t)/Ai,t-1+α3*PPEi,t/Ai,t-1+εi,t
(Ⅴ)
其中,TAi,t为第t年净利润与经营活动净现金流之差,Ai,t-1为第t-1年年末的资产总额,ΔREVi,t为第t年与第t-1年营业收入之差,ΔRECi,t为第t年与第t-1年应收账款之差,PPEi,t为第t年年末固定资产。将模型(Ⅴ)分别按行业和年份进行回归,回归模型的残差就是上市公司的盈余管理DAi,t。由于本文不考虑盈余管理方向,因此采用绝对值|DAi,t|作为盈余管理指标。表10中的第2列和第3列报告了以|DA|为解释变量的回归结果,从回归系数来看,|DA|的回归系数都显著为正。除此以外本文还构建了高盈余管理(|DA|_H)虚拟变量,若上市公司的盈余管理高于中位数,|DA|_H取值1,否则取值0,表9中的第4列和第5列报告了以|DA|_H作为解释变量的回归结果,结果显示高盈余管理与主观句比例和主观性分数显著正相关。选取上市公司的盈余管理作为代理变量进行稳健性检验结果仍然显示上市公司会利用主观性叙述配合上市公司的盈余操纵行为。
五、结论与启示
本文利用机器学习方法对上市公司年报语料进行训练,通过提取2-POS主观模式,构建了度量年报文字叙述主观程度的指标,即年报的主观句比例(Sub_1)和整体主观性分数(Sub_2)。对上市公司年报的主观性指标进行分组描述性统计后,发现处于进行财务重述前状态的上市公司年报的主观句比例、主观性分数都显著高于不处于财务重述前的上市公司年报。通过回归检验发现,年报中的主观句比例、主观性分数与年报处于财务重述前的状态是显著正相关的。经过进一步的分组回归检验发现,在较差的外部市场环境和内部治理环境下,主观句比例、主观性分数与年报处于财务重述前的状态显著正相关;而在较好的外部市场环境和内部治理环境下,主观句比例、主观性分数与年报是否处于财务重述前之间并不显著相关。本文的实证结果显示,我国上市公司进行盈余操纵的同时,会采取主观的文字叙述策略模糊其盈余操纵行为,但是外部的高市场化环境和内部的良好治理环境会抑制上市公司利用主观文字叙述隐藏盈余操纵行为的问题。

表10 盈余管理与年报主观句比例、主观性分数
针对我国上市公司披露的主观叙述问题,由于中文语言的复杂性以及监管部门目前对上市公司文字信息披露的监管力度仍然较弱,为上市公司对文字信息披露进行操纵提供了可乘之机。我国监管部门应该加强对上市公司文字信息披露的监管力度,进一步规范上市公司会计文本的用语。美国证监会(SEC)在1998年制定了“Plain English”的规则,并且发布了指导上市公司如何使用简洁和规范用语的相关手册,我国监管部门也可以借鉴国外相关成功经验制定相关会计文本披露规范对我国上市公司的文字信息披露问题进行监管。对于外部信息使用者而言,应该注意上市公司文字叙述所带的主观色彩,当文字叙述的主观色彩较浓时,应该仔细辨别相关文字信息的质量,考虑上市公司是否具有信息披露的操纵行为,以避免被低质量的信息误导,从而做出错误的决策。
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
西北林学院学报(2022年4期)2022-08-02
西北林学院学报(2022年3期)2022-06-10
中国注册会计师(2021年9期)2021-10-14
中华养生保健(2020年8期)2021-01-14
中国外汇(2019年10期)2019-08-27
影视与戏剧评论(2016年0期)2016-11-23
股市动态分析(2016年16期)2016-10-18
中国现当代社会文化访谈录(2016年0期)2016-09-26
语言与翻译(2015年4期)2015-07-18
