
面向兵棋演习的问答系统问句分类模型研究∗
2019-02-27 08:31:22孙泽健司光亚
计算机与数字工程 2019年2期
孙泽健 司光亚 刘 洋
(国防大学信息作战与指挥训练教研部 北京 100091)
1 引言
随着战争形态的演变和发展,计算机兵棋推演作为重要的仿真手段在军事训练中的作用和地位越来越突出,各类专业的兵棋训练系统应运而生[1~2]。但相较于一般的游戏软件或军事训练系统,大型“人在回路”兵棋系统的数据和规则更加复杂,使用和操作存在一定难度,给使用者设置了不低的门槛。而近年来,自然语言处理技术的最新进展,为构建面向兵棋演习的智能问答系统创造了条件,其可以辅助参加兵棋演习的人员更好地操作使用兵棋系统,解决使用人员产生的各种疑问,快速准确地反馈演习数据,减轻服务人员工作量,提高兵棋演习的质量。
2 需求和技术思路
2.1 兵棋演习对智能问答的需求
通过参加某兵棋演习,搜集兵棋系统使用人员常问的问题,组成一个小样本的兵棋问题集来进行需求分析。发现所涉及的问题种类多样,大致可以分为五类,主要依据和典型例句参见以下示例(表1)。
根据数据统计和某一兵棋系统现有条件进行分析,可知用户输入的问题大多是带疑问词的简单句,提供的句子特征并不多,部分甚至是几个关键词的组合;而不同类别的问句需要访问不同的知识库,其系统实现的方法完全不同。故面向兵棋演习的问答系统必是一个组合了不同实现方式的组合问答系统,而问句分类可以实现系统的调度功能,让组合问答系统可以集成多个系统模块。
2.2 技术思路
问句分类是问答系统的一个常见模块,其能够决定答案选择策略,或减少候选答案[3]。问句分类也是除自然语言预处理模块外,兵棋问答系统处理问句的第一步、首要环节,直接影响后续流程的实现以及问答系统的性能,且尤以对系统召回率的影响极大。
当前问句分类的主要方法主要集中在两方面:基于规则的方法和基于统计的机器学习的方法[4]。但对于一个开放的问答系统,基于统计的方法对于问句特征的提取和选择更能排除人的主观干扰,抓住容易忽视的细节。
本文基于向量空间模型,通过生成词向量和词权重来完成问句表征,综合考虑算法复杂度以及匹配精确度,通过KNN算法将两个不同的问句相似度模型结合,最终完成问句分类。
同时考虑FAQ类问答模块的实现同样需要建立问句匹配模型,需要完成特定的语义表征,进行问句匹配,相当于完成大数量级别的问句分类。问句分类和问句相似度模型的构建,可以为后续实现FAQ类问答模块提供参考。

图1 问句分类模型框架
3 问句相似度模型
问句分类模块分类器的主要部分是完成新输入问句和知识库中存储的、已完成标记的历史问句的比较,而这离不开在问句表征基础上的问句相似度计算[5~6]。
本文根据技术条件、已有数据情况、问答系统需要,选择用词向量和词权重计算来完成问句表征,利用空间向量模型完成问句相似度计算,并利用改进KNN算法统筹了两个不同的问句相似度模型一和二。其中模型一,通过计算单个的词条相似度来完成问句相似度计算,算法复杂度低同时计算精确度也有限;模型二通过源自运筹学运输优化问题的WMD算法,来完成问句相似度计算,算法复杂度较高,但计算精确度高于模型一。
3.1 词向量
传统的词语表示方式是通过词典将词条编码为01向量(One-hot Representation),容易造成数据稀疏和“维数灾难”的问题。随着自然语言处理技术中神经网络算法的发展,出现了分布式词向量[4~5]。通过搜寻大规模领域文本,以及Word2vec工具,可以较快地实现词条的分布式空间表示。
3.1.1 Word2vec算法
Word2vec最早是Tomas Mikolov在2013年由NNLM模型基础上引出[7~8],同时Google也在同年开源的一款生成词向量的高效工具。其利用一个浅度的神经网络和训练文本中上下文的相关性,通过无监督学习将原始的N-gram模型中的高维one-hot向量转化为低维度的分布式词向量,从而降低了空间维度,避免了“维数灾难”。生成的词向量各维度上的数值虽然并无显示含义,但向量之间的差异代表了词语的语义间隔。故一方面,借助词向量可实现词语的知识表示,另一方面,利用词向量的余弦距离可表示词的语义相似度。分布式词向量的出现未计算文本的语义相似度提供了新的选择,但词向量的质量取决于训练语料的规模、质量、覆盖面和模型参数的设置。
3.1.2 问句矩阵
搜集整理和兵棋演习、战争模拟、军事武器相关的文本资料,兼顾其数量和内容相关度,作为本模型词向量的训练语料。对训练语料进行数据归一化和清洗,包括中文分词、去除停止词和部分低频词(频度小于5)等,通过Word2vec生成词向量,每一个词条(Term)可以表示成一个N维词向量,而每一个问句可以由其句中的词向量按词序生成问句矩阵。

图2 词向量在空间中的示例
定义1 问句矩阵

其中V为问句包含词条的词向量。
3.2 词权重
词权重对于区分不同词条的重要程度,具有重要作用。由于搜集到的兵棋演习过程中所涉及的问题(表1),基本为不超过5个词条的短文本,单个词条的词频一般不会超过1(不会重复),故通过计算TF值来得到词权重几乎没有意义,而TextRank算法[6]考虑了语料中词条的语义关系及上下文特点,其生成的词条排序反映了词条在全文本中的重要程度,可以有效替代TF统计的作用,故本文通过结合词条的TextRank排序和其IDF值来计算词权重。
3.2.1 TextRank算法
TextRank算法最早由Mihalcea和Tarau于2004年在研究自动摘要过程中提出,主要借鉴了Google著名的网页排名算法PageRank的思路[9]。通过把文本分割成若干文本单元并视其为节点,以单元之间的共现关系赋边和边权,从而构建图模型,仿照PageRank算法迭代至收敛,进而完成某一特定任务。其详细步骤如下:
1)根据不同的NLP任务,选定特定的文本单元(可以是词条、实体或者句子)作为节点,初始时为所有的节点赋同一分数;
2)根据文本单元特点定义一种共现关系,如词条可以是某一文本窗口(窗口大小可以是2到10)里的共现关系,共现一次边权加1,而句子可以是相互间的句子相似度,实体则可以是其在句法树上的距离;
3)得到图的邻接矩阵,根据PageRank算法,迭代至收敛;
4)对各节点最终的得分进行排序。
海湾战争前,美国曾组织力量运用这款兵棋对海湾战争进行了推演,并得出诸多结论。后来海湾战争的实践证明,这些预测性结论是十分正确的。美国通过兵棋得出了一条重要结论:海湾战争如果实施集中式大规模空袭,容易得速战速决的战略性胜利。
3.2.2 TextRank+IDF求词重

图3 TextRank生成的图模型
以兵棋问题集作为词权重模型的训练语料,进行以下处理:
1)对兵棋问题集进行预处理,包括分词和去除停止词;
2)以词条为图模型节点,设定共现窗口值为N,窗口不得跨越问句边界;
3)统计共现窗口里的词条共现情况,两词条共现一次,其图模型中的边权加1;
4)根据式(2)和式(3)计算词权重Wi。
根据TextRank算法的迭代公式(和PageRank算法迭代公式形式一样):

其中d为阻尼系数,TR(Vi)为Vi节点得分(TR值),wij为任两点间边权。同时根据逆文档频度公式

其中di为包含词条ti的问句数,D为兵棋问题集问句总数。可得词条ti的词权重Wi为

经归一化处理后,词权重为
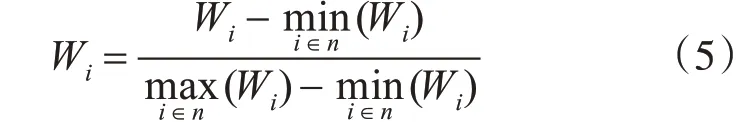
3.3 问句相似度模型一
两个问句的相似度取决于多个因素,如问句的句长和句法结构,词条的语义、词序以及上下文语境等。限于句法结构计算实现的难度较大,而问答系统问句的上下文语境建模较为困难,模型一以词向量和词权重的计算结果为基础,根据孔胜、王丽月等的研究[7],综合词条语义、句长、词序来计算问句相似度。
模型一首先完成问句包含词条之间相似度的计算,并认为问句A和B的相似度,由问句的单向(问句A对B或B对A)相似度加权求和得来。首先定义以下概念:
定义2 词条相似度
计算词条相似度,优先通过字符串匹配的方法,相同的词条其相似度为1;否则,计算词向量的余弦距离。而据实验证明,当词向量间余弦距离小于1时,词语之间几乎没有语义相似度,也不存在反面语义现象,故对词条相似度作非负处理,以保证问句相似度不为负值。

其中V1、V2为词条t1、t2的词向量。
定义3 词条和问句相似度
词条t与问句A的相似度为其与问句A中最相似词条的相似度:

定义4 单向问句相似度
问句A对B的相似度定义为A中词条对问句B相似度的加权和:
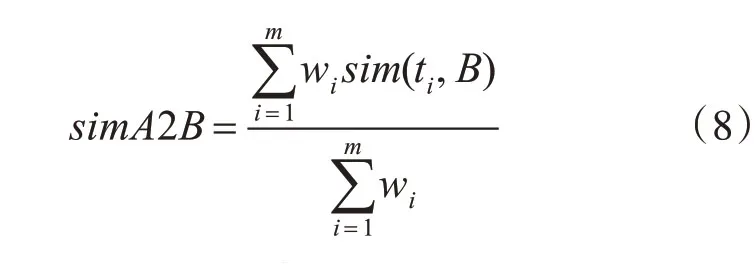
其中wi为词条ti的词权重。
定义5 句长调整因子
问句A对B的句长调整因子定义为

同理B对A的句长调整因子为

定义6 问句相似度
问句A和B的相似度为其单向相似度的加权和,其权值为各句长调整因子,故其定义为

此外由于采用词条相似度加权和的计算方法,词序的相关信息未被考虑,故增加词序调整因子,使相似度计算更加精确合理。定义7 词序相似度
问句A分词后,词条t按词序存于序列sequA中。同理,B中词条词序存于sequB中,寻找A中词条ti在B中最相似词t′i,将t′i在sequB中的下标组合成A对B的词序列orderA2B,同理可得B对A的词序列orderB2A。
通过计算order A2B和order B2A逆序对的均值,可得问句A和B的词序相似度:

综上所述,模型一的问句相似度计算公式为

其中λ1+λ2=1。
3.4 问句相似度模型二
模型一综合考虑了问句的多种特征,但由于兵棋演习情景中输入问句一般都为较短的单句,问句提供的相关信息有限,其对问句的区分度有限。以图4所示情况为例,问句B为输入问句,但在计算其和问句A、C的词条相似度的过程中,可以发现其明显和句A的词条相似度更高,从而导致后续计算问句相似度时,和A句的相似度更高。但我们明显知道,问句A和问句B明显是不同属方关心的不同问题,问句B在语义上明显和问句C更接近。虽然模型一在个别问句相似度计算上存在部分不合理之处,并不一定导致后续问句分类出错,但为了提高模型的准确度,根据WMD算法,提出了问句相似度模型二。

图4 三个句子间最相似词条情况
3.4.1 WMD算法
WMD(Word Mover's Distance)算法[8]是Matt J.Kusner和Yu Sun等[11]于2015年在Word2vec生成词向量的基础上,将求问句相似度的问题转化为线性规划中运输优化问题(Option Transport Problem),由于将词语间的语意给考虑进来再进行计算句子的相似性,在测试中取得了良好的效果。图5为WMD算法的一个空间示例。

图5 WMD算法语义解释
3.4.2 WMD算法求解问句相似度
将待匹配句子中的词条视为OT问题中的工厂(源地),词条的词权重视为OT中的货物,而候选句子中的词条视为仓库(目的地),将词向量间的空间距离视为工厂到仓库的路途或运费(Travel Cost),而词条间语意的映射则可视为OT问题中唯一的变量(货物的单线运输量Tij)。而两句子的相似度也可视为产销平衡条件下OT问题总路途的最小值。故模型二求解问句相似度的公式为

其中wi、wj分别表示不同问句中第i和第j个词条的词权重,dist(i,j)为词条i和j的空间距离,在此选用词向量的余弦距离。
3.5 改进KNN问句分类模型
模型一的算法复杂度为O(n2),而基于WMD算法的模型二计算任意两个问句的相似度都相当于在求解一个运输优化问题,其算法复杂度O(n3log n),虽然问答系统实际应用过程中所涉及的问句多为短文本,模型二计算带来计算成本的提高并不明显。但考虑随着问答系统的使用,兵棋问题集中保存的历史问句数量会不断增加,使模型计算量成倍增加,本文设计了一个综合考虑算法复杂度和计算精确度的改进KNN算法完成最终的问句分类[9]。
KNN算法是经典的有监督分类算法,特别适合多分类问题,易于理解。但往往存在以下缺点:
1)基于全局的空间距离计算,当数据集规模较大时,计算代价不容忽视。
2)当不同类别的数据集数量不均时,KNN算法偏向数据集数量多的类别。
随着问答系统的使用,兵棋问题集规模越来越大,不同类别的问句难免会有数量不均的情况产生,故本文根据问句相似度模型一和模型二两种问句相似度计算方法,结合优先队列(Priority Queue)思想,再使用KNN算法完成问句分类。具体步骤详述如下:
1)对兵棋问题集中所有的问句完成类别标记,分成M类(对应M种查询策略);
2)利用问句相似度计算模型一计算输入问句和兵棋问题集中全部问句的相似度,筛选出各类相似度最高的Τop N个问句,共组成M×N个参考问句集;
3)利用问句相似度计算模型二计算输入问句和参考问题集中M×N个问句的相似度,找出K个最相似的问句;
4)选K个问句中数量最多的类别作为输入问句的类别。
据此,可以有效降低问句分类的计算难度,使计算复杂度较高的模型二方法使用不超过M×N次。同时,利用模型一去粗取精,统一不同类别问句数量,规避了经典KNN算法的缺点,使分类模型兼顾效率和准确率[10]。
4 实验
为了测试本文模型的有效性,在相同训练集和测试集和不同候选类数量的条件下,对不同模型进行了评测。共搜集到876个问句实例,用其中的700个作为训练实例,176个作为测试实例。实验平台计算机CPU为Intel Xeon E5-2687w,主频3.10GHz,内存64GB,系统为64为Windows 7,实验基于Python 3.5语言和Pycharm开发环境。
选用的对比模型有三个,本文模型为方法一,领域文本的大小为276MB,但内容较为混杂。
方法二不采用TextRank算法,只通过计算IDF值来求取词权重。
方法三不采用WMD算法,只采用问句相似度模型一来进行分类。
方法四采用一个小规模的领域文本(约15MB)来生成词向量,但其领域相关性更高。
由实验结果可知,随着候选类别的增加,对于不同方法来说,分类精确度都有所下降。但在确定的候选类别情况下,WMD算法对系统性能的影响最大,在不采用WMD算法的方法三中,准确率有明显下降。其次是生成词向量的领域文本质量,以及TextRank算法的使用。

图6 不同候选类别情况下不同方法的分类效果
5 结语
当前,以各大科技巨头研发的多种聊天机器人或虚拟个人助理,正成为智能问答系统发展新的里程碑,展示了诸多可能性[14]。但万丈高楼平地起,先进的功能、复杂的架构都离不开自然语言处理基础理论和基本技术的发展。问句表征、问句相似度计算以及在此基础上的问句分类就是问答系统实现的重要基础[15]。不管是问答系统选用何种技术完成知识库访问和答案抽取,一个好的问句分类模块都可以减少候选答案的空间,明确答案选择的策略。
兵棋演习情景中设计系统操作和运行规则的大量问题固然可以依靠信息抽取技术从大规模自由文本中直接抽取,但短期来说,依靠人工编辑好的FAQ问答对来回答此类问题效果更加明显。但从大规模的候选问题集中找到合适的问答对来回答用户新提出的问题,精确的问句相似度计算仍是不可缺少的。在此基础上,问句分类模块和FAQ查询模块是技术共通的。
但同时我们也应看到,Word2vec算法和TextRank算法虽是较为前沿的统计方法,但由词向量和词权重组成的问句表征的合理性仍难以评估,其效果直接受限于训练数据的规模和质量,对未登录词、近同义词没有好的处理方式。另外,问句相似度计算也是自然语言处理领域的主要难题之一,句子相似度很难统一定义,只能根据具体任务来具体构建,在本文中就直接影响了问句分类效果。而如何确定问句相似度计算的合理性,没有明确的思路。
由于数据规模的限制,在实验中统计方法并没有取得预期中的效果,下一步,将聚焦于问答数据的收集和统计方法与规则方法的结合,在使用和实验的基础上来改善问句分类的效果。
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18
军事文摘(2020年19期)2020-10-13 12:29:28
军事运筹与系统工程(2019年3期)2019-08-13 06:53:52
人大建设(2018年5期)2018-08-16 07:09:00
军事运筹与系统工程(2018年4期)2018-03-26 06:37:46
军事运筹与系统工程(2018年2期)2018-02-16 07:39:00
电信科学(2017年6期)2017-07-01 15:44:57
知识经济·中国直销(2016年5期)2016-11-07 09:35:07
知识经济·中国直销(2016年4期)2016-11-07 09:34:04
知识经济·中国直销(2016年10期)2016-02-27 16:16:54
