
基于模糊判别成分分析法的高光谱作物信息提取与分类
2019-02-21 14:26董丽芳赵海士常志勇
农业工程学报 2019年21期
杨 晨,董丽芳,赵海士,常志勇
(1.吉林大学地球科学学院,长春 130061;2.吉林大学计算机科学与技术学院,长春 130021 3.吉林大学生物与农业工程学院,工程仿生教育部重点实验室,长春 130022; 4.吉林大学油页岩地下原位转化与钻采技术国家地方联合工程实验室,长春 130021)
0 引 言
高光谱遥感是20 世纪80 年代兴起的一种新型对地观测技术,它能够获取上百个非常窄的连续谱段信息,得到“图谱合一”的曲线,提供丰富的光谱信息来增强对地物的区分能力[1-2]。成像光谱仪是高光谱遥感技术的核心,分为机载成像光谱仪和星载成像光谱仪2种。1983年,美国研制出第一个航空成像光谱仪AIS-1。之后,国内外学者相继研制成像光谱仪应用到不同领域[3-4]。机载可见光/红外成像光谱仪(airborne visible infrared imaging spectrometer,AVIRIS)作为应用最为广泛的机载成像光谱仪,在农作物分类[5-7]方面有着广泛应用。但是,由于高光谱遥感影像的典型特征,即高维性与波段间相关性强的特点,在分类过程中易引起所谓的“Hughes 现象”(维数灾难)[8],降低分类精度,影响作物长势监测、作物估产[9]及作物种植[10-11]。
应用高光谱遥感影像进行作物分类之前,在不损失有用信息的前提下,利用数据降维技术将高维影像压缩到低维空间是很有必要的。高光谱影像常用的数 据降维技术包括特征选择与特征提取。特征选择方法从原始特征集中选择出适合于分类的特征子集,从而改善分类性能。张卫正等[12]运用连续投影算法对甘蔗高光谱影像进行特征选择,寻找含有最低限度冗余的甘蔗茎节波段,用于高光谱遥感甘蔗茎节识别分类。但是,现有多数特征选择算法通常具有次优化性;另外,选择合适的特征及特征数目非常耗时、耗力,最优特征子集的选择往往无法保证。特征提取通过映射或变换,将原始处于高维空间的数据转换到低维特征空间,减轻高光谱数据的复杂相关性和冗余度。常用的高光谱影像特征提取方法有主成分分析(principal component analysis, PCA)[13]、最大噪声分离(maximum noise fraction, MNF)等。本文主要针对高光谱遥感影像作物特征提取方法进行研究。
随着高光谱遥感空间分辨率的提高,同类地物内光谱差异增大,类间差异性减小,决定了高光谱遥感影像中存在着光谱变异性[14]。传统基于单一光谱特征方法,无法考虑高光谱遥感影像光谱变异性问题。近年来,国内外学者研究将光谱信息和空间特征相结合,已成为当前研究热点。杨思睿等[15]针对高光谱影像无法区分物质组分相同的对象问题,融合LiDAR 数据,利用主成分分析与形态学属性剖面进行光谱特征和纹理特征提取,用于农业区精细作物分类。然而,高光 谱遥感影像地物覆盖本质上具有区域相似性和同质性,即高空间相关性。采用形态学空-谱结合方式,无法同时考虑光谱变异性和高空间相关性。近年来,一种新的机器学习方法——调节学习(adjustment learning)[16]逐渐受到关注。调节学习引入了全新的先验知识形式,即块(chunklet)。基于调节学习的度量学习方法相继提出,如相关成分分析[17]、判别成分分析(discriminative component analysis,DCA)[18]、核判别成分分析。本人利用正约束和负约束结合调节学习,提出了基于特征度量[19]和判别特征度量[17]的高光谱遥感影像波段选择方法;将核判别成分分析引入高光谱特征提取[20],通过构建判别约束同时解决光谱变异性和高空间相关性问题。
同时,不同地物光谱存在的固有不确定性与作物类型的复杂性,决定了作物混合像元的存在和混合光谱引起的相邻像元之间自相关现象,产生光谱混淆,严重影响了作物的分类精度[21-24]。随着高光谱遥感图像处理研究的深入,其不确定性问题也越来越得到重视。由于遥感影像集中体现了地表现象在某个瞬间的波段特性,成像过程受多方面随机变化因素的影响,导致获得的影像数据具有一定随机性,也即具有统计性。一些研究者将模糊集理论与统计分析方法相结合,提出了模糊统计学[25]。模糊统计学在处理灰度空间不确定性和和变异性方面已显示出优势[26-27]。
面对高光谱遥感影像的高维性、光谱变异性、不确定性,本文基于调节学习与模糊统计学相关理论,提出模糊判别成分分析(fuzzy-statistics-based DCA, FS-DCA)用于作物特征提取。通过定义模糊统计数字特征解决光谱变异性和高空间相关性与抑制噪声像元造成的不确定性,使得学习的特征空间具有更好的类间分离性和类内紧凑性,以期为作物分类提供可分性更强的空-谱特征空间,有效提高作物分类精度。
1 基于模糊判别成分分析的高光谱影像作物特征提取模型
针对高光谱遥感影像数据,首先由正约束关系生成若干个作物像元块与非作物像元块,并通过负约束关系形成每个像元块的判别集合。然后,引入模糊统计学相关理论,定义两两像元块之间的总方差和每个像元块内部的总方差,从而构建模糊判别特征子空间。
令 X = {x1, x2, …, xL} ⊂L×N为一个高光谱遥感数据集,L 为光谱波段的数目,N 为每个波段的像元数目,xi= {xi1, xi2, …, xiL}表示第i 个光谱向量,如图1 所示。在高光谱遥感影像集中,如果2 个像元属于同一作物或非作物类别(无类别标记),将它们定义为正约束关系,如图1 中标注C1和C2像元块为大豆幼苗;如果2 个作物或非作物像元不属于同一类别,则为负约束关系,如图1 中标注C3像元块的为干草,C4像元块为森林。令P 与N 分别表示正与负约束信息:
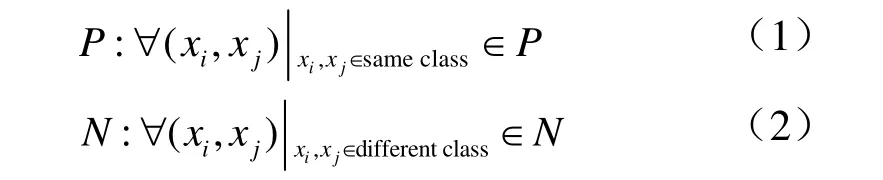
像元块集合C、相关集合R 与判别集合D 定义如下:
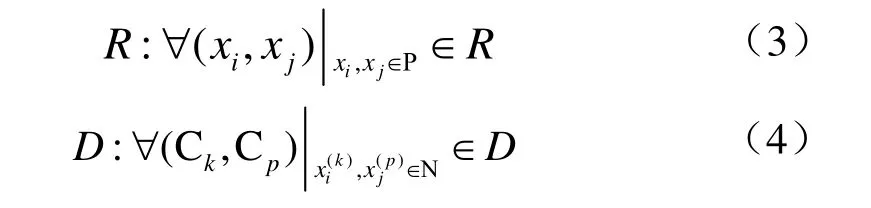
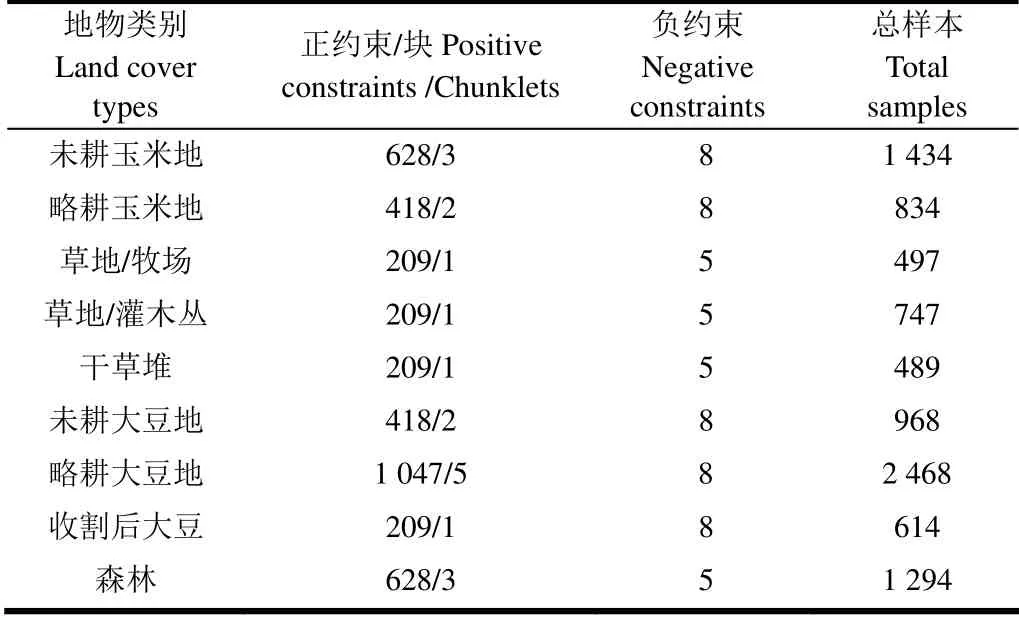
根据给定的约束,一组具有正约束的像元可以聚集在一起组成块集合,具有负约束的像元形成一个描述块的判别集合。 令作物与非作物像元块为第k 个块为第k 个块中的第i 个像元,nk为第k 个块中所包含像元点的数目。判别块集合中的元素表示K 个块之间的正与负约束关系。判别块定义为2 个块中至少有1 个负约束关系。特征表示的目的是寻找一个特征子空间Y=ATX∈l×N(l < 图1 高光谱影像数据集 Fig.1 Hyperspectral image data set 基于模糊统计学定义高光谱影像统计特征,包括模糊集、模糊均值和模糊散布矩阵。 在定义的模糊集中,作物与非作物像元块中像元是由像元对应的向量x 和隶属度μ 共同描述。像元块内像元的模糊均值定义如下: 对于给定的高光谱遥感数据集X,像元块集合C和判别集合D,模糊散布矩阵定义如下: 式(6)~(7)中,FMk与FMp分别为第k 与第p 个作物或非作物像元块的模糊均值,为判别集合D 各个像元块中作物或非作物像元个数,为第p 个像元块的第i 个像元。式(6)表示判别集合中不同作物之间及与非作物的模糊总方差,即模糊判别像元块散布矩阵,用于描述判别集合分散度;式(7)为模糊像元散布矩阵,用于描述同一作物与非作物块的紧凑度。 通过学习最优转换矩阵,使得学习的特征空间最大化模糊判别像元块散布矩阵,最小化模糊像元块散布矩阵,即: 利用学习的最优转换矩阵,获得模糊最优农作物特征子空间如下: 基于模糊统计学的高光谱遥感影像作物特征提取方法具体步骤如下: 1)初始化参数。根据已知正约束信息P 和负约束信息N,定义作物与非作物像元块集合C,判别集合D。 2)计算模糊散布矩阵。根据式(6)与式(7),计算模糊判别像元块散布矩阵和模糊像元散布矩阵。 4)根据公式(9)构建基于模糊统计学的高光谱遥感影像作物特征空间。 由模糊判别成分构建的作物特征空间FS 被用于后续作物分类。 本文采用广泛使用的Indian Pines 92AV3C[28]高光谱数据集。该数据由机载可见光/红外成像光谱仪(AVIRIS)获取,图像大小为145×145,光谱覆盖范围为400~2 500 nm,光谱分辨率为10 nm,共224 个波段,空间分辨率为20 m,获取时间为1992 年6 月,拍摄地点为美国印第安纳州西北部。该数据集地物种类较为复杂,混合了种植作物、林地、草地等。地物种类分布不均匀,存在样本稀少类别。原始影像包含16 类地物。考虑到统计验证的可靠性[29],试验中保留9 个类别,舍弃样本稀少的7 个类别。保留的9 类地物中主要包含不同类型玉米与大豆及植被覆盖区。由于该区域农作物尚处于生长阶段,裸露的土壤与农作物残渣增加了作物提取与分类的难度。鉴于以上特点,本文选取Indian Pines 92AV3C 高光谱数据集进行作物信息提取与分类。图2 为AVIRIS 影像假彩色合成图与真实地物图。通过去除低信号噪声(signal-to-noise, SN)波段(104~108、150~163 和220 nm),选取其中的200 个波段为测试集。试验中,随机选取13 个作物像元块与6 个非作物像元块,每个像元块中包含210 个像元(见表1)。 为了评估本文提出的FS-DCA方法在作物分类方面的性能,分别选取经典特征提取方法PCA和DCA,以及原始AVIRIS高光谱影像全部波段进行对比。采用峰值信噪比(peak signal-to-noise ratio,PSNR)来评估所提取特征图像质量。利用支持向量机(support vector machine, SVM)分类方法进行验证[30]。AVIRIS数据集包含9,345个样本,其中训练样本按照每类5%选取,共500个,测试样本共有8 845个。为了更客观地验证算法有效性,试验中训练和测试样本随机选取3次,每次无重复。选取生产者精度(producer’s accuracy,PA)、用户精度(user’s accuracy,UA)、总体分类精度(overall accuracy,OA)、平均总体分类精度(average overall accuracy,AOA)、标准偏差(standard deviation,SD)作为评价准则。 图2 AVIRIS影像假彩色合成图与真实地物图 Fig.2 False color composite image and available ground truth map of the AVIRIS image 表1 AVIRIS数据集正约束/块、负约束及总样本数目 Table 1 Number of positive/chunklets and negative constraints and total samples for AVIRIS data set 图3 为应用PCA、DCA 和FS-DCA 分别提取的主 成分、判别成分与模糊判别成分,表2 为主成分、判别成分以及模糊判别成分的峰值信噪比(peak signal-to-noise ratio,PSNR)。结合图3 和表2 可以看出,第六、第七主成分和第七判别成分的峰值信噪比分别是16.87、12.97 和15.51,所含信息量较少,地物区分性不好;第一、二、六和七模糊判别成分的峰值信噪比(25.41、21.21、20.50、17.59)均大于对应的主成分与判别成分。可见,模糊判别成分分析为后续作物分类提供了区分性更好的特征图像。 运用Matlab 在PC 工作站(Intel(R) Core(TM) i7-3720QM CPU 2.60 GHz, 2.60 GHz 16 GB,RAM)上运行PCA、DCA 和FS-DCA,所用计算时间分别为1.26、1.35 和224.37 s,FS-DCA 耗时高于PCA 与DCA。这是由于在FS-DCA 中,需要通过迭代方法不断修正隶属度,以获得最优模糊均值。 图3 基于主成分分析、判别成分分析和模糊判别成分分析的AVIRIS高光谱遥感影像特征表示 Fig.3 AVIRIS hyperspectral imagery features representation based on PCA, DCA and FS-DCA 为了验证提取特征的有效性,将PCA、DCA、FS-DCA 所提取的7 个特征和原始200 个波段分别应用于AVIRIS Indian Pines 92AV3C 高光谱遥感影像中进行作物分类。影像分类精度(OA、AOA 和SD)结果如表3。最佳分类结果如图4 所示。 表2 主成分、判别成分和模糊判别成分的峰值信噪比 Table 2 Peak signal-to-noise ratio (PSNR) of PC(principal component), DC(discriminative component) and FDC(fuzzy discriminative component) 表3 PCA、DCA 和FS-DCA 的分类精度 Table 3 Classification accuracy of PCA, DCA and FS-DCA 图4 运用全部原始波段、主成分、判别成分和模糊判别成分的AVIRIS高光谱遥感影像分类图 Fig.4 AVIRIS hyperspectral imagery classification map of all channels, PC, DC and FDC 从表3 可以看出,应用PCA、DCA 和FS-DCA 选取的7 个特征获取的平均总体分类精度分别高于原始200 个波段3.6、6.38、6.88 个百分点。对于不同特征提取方法,基于FS-DCA 提取的特征获得的平均总体分类精度高于PCA 和DCA 3.28 和0.5 个百分点。同时,所提出的FS-DCA 展现出了最低的标准偏差,证明了 FS-DCA 具有更好的稳定性。 结合表3 与图4 可以看出,原始200 个波段的分类图中各类之间界线模糊,随机选取3 次训练和测试样本的总体分类精度为65.03%,各类间均有混淆现象,且标准偏差为0.77,随机选取3 次训练和测试样本的分类结果相近。已整理大豆地的生产者精度和用户精度分别为36.06%和33.93%,其对应的漏分误差和错分误差较大,分别为63.94%和66.07%。 从运用主成分获得的分类图中可以看出,各类之间界线较运用200 个波段清晰,但存在很多错分情况。随机选取3 次训练和测试样本的总体分类精度为71.19%,标准偏差为1.97,未耕玉米地的用户精度为51.52%,对应的错分误差为48.48%,在未耕玉米地中有被错分的略耕玉米地和收割后大豆。略耕玉米地的生产者精度为39.29%,用户精度为57.89%,略耕玉米地与未耕玉米地出现了错分情况。略耕大豆地的生产者精度为67.5%,用户精度为65.99%,未耕玉米地被错分为略耕大豆地。 在运用DCA 分类图中,各类之间展现了很好的区分度。但仍存在大量错分现象,收割后大豆的生产者精度和用户精度分别为50.00%和43.88%,收割后大豆中出现了被错分的略耕玉米地。略耕大豆地的生产者精度和用户精度分别为73.72%和65.87%,其中出现了略耕玉米地和略耕大豆地的错分情况。 从基于FS-DCA 分类图中可以看出,类别之间错分情况较PCA 与DCA 少。略耕大豆地的生产者精度和用户精度分别为71.89%和67.36%,其中只有少量的略耕玉米地错分情况。未耕大豆地的生产者精度和用户精度分别为64.71%和76.26%,同样只有少量的未耕玉米地错分情况。收割后大豆的生产者精度和用户精度分别为68.47%和50.84%;与DCA 相比,基于FS-DCA 分类图中收割后大豆的分类效果更好,未耕大豆地和略耕大豆地等类别展现出了更好的区分。总体上看,种植作物的生产者精度与用户精度比PCA 与DCA 提高1.37~18.47 个百分点。 同时,从图4 可以看出,虽然基于FS-DCA 分类图中空间相邻作物间出现的混淆错分现象比PCA、DCA 与运用原始200 个波段明显减少。但是,3 种方法中,一些面积较小的相邻作物混淆不同地物类别现象相对严重。 现有高光谱遥感影像特征提取方法在固有特性方面与作物光谱变异性方面考虑不充分,直接影响后续作物分类效果。本文针对此问题,将模糊统计学理论与判别成分分析相结合,提出模糊判别成分分析(FS-DCA),通过模糊统计特征及变换,扩大特征空间不同作物及非作物间分离性和相同作物的类内紧凑性;由判别变换获取特征子空间,保留作物可分光谱与空间信息;有效地降低波谱数目。试验结果表明,利用SVM基于FS-DCA对AVIRIS Indian Pines 92AV3C高光谱遥感影像9种种植作物进行分类的平均总体精度比采用全部波段、PCA和DCA分别高出6.88、3.28、0.5个百分点,种植作物的生产者精度与用户精度比传统方法提高1.37~18.47个百分点。与传统方法相比,基于模糊统计学建立的高光谱影像特征提取方法,大大减少后续分类维度的同时,为作物分类提供了可分性更强的特征空间。 今后对高光谱作物分类进行研究中可将超像素技术引入到光谱维特征提取,以进一步研究提高作物(特别是相邻作物)分类精度的有效方法。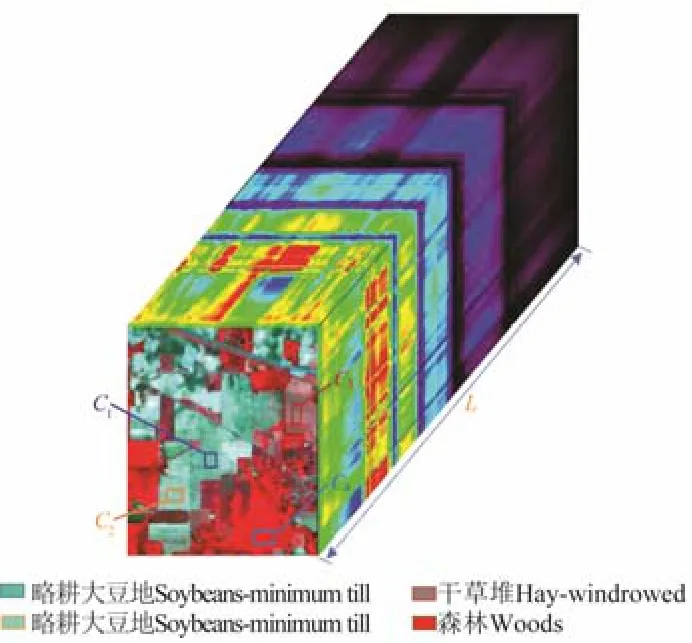
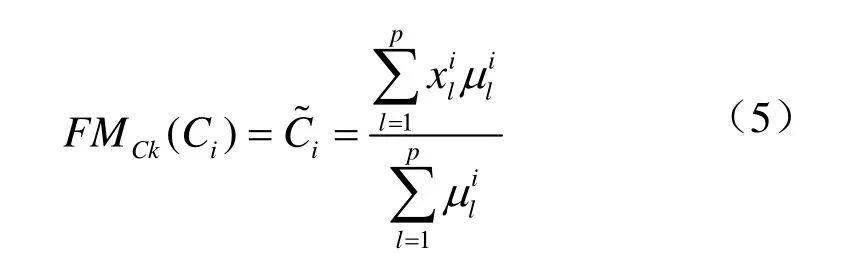
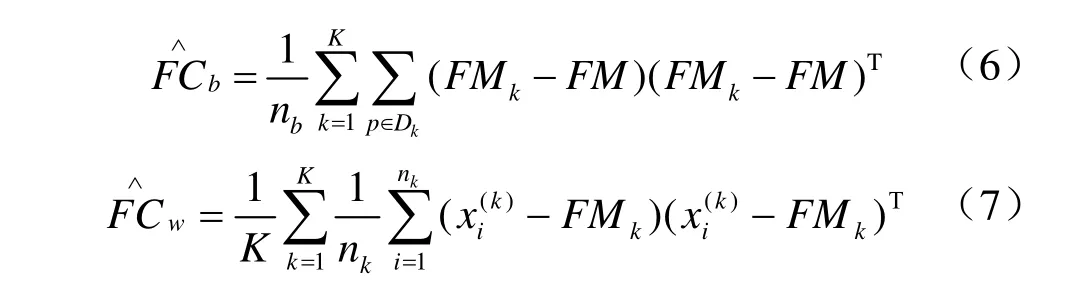


2 试验设计
2.1 试验数据
2.2 对比方法与评价指标

3 结果与分析
3.1 高光谱影像特征提取结果

3.2 作物分类精度评价



4 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
航天返回与遥感(2022年2期)2022-05-12
黑龙江大学自然科学学报(2022年1期)2022-03-29
空间科学学报(2021年1期)2021-05-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
