
基于规则和N?Gram算法的新词识别研究
2019-02-20 02:07姜如霞黄水源段隆振罗丽娟
现代电子技术 2019年4期
姜如霞 黄水源 段隆振 罗丽娟


关键词: 新词识别; N?Gram算法; 构词规则; 中文分词; 碎片库; 召回率
中图分类号: TN911?34; TP391 文献标识码: A 文章编号: 1004?373X(2019)04?0166?05
Research on new word recognition based on rules and N?Gram algorithm
JIANG Ruxia, HUANG Shuiyuan, DUAN Longzhen, LUO Lijuan
(School of Information Engineering, Nanchang University, Nanchang 330031, China)
Abstract: A lot of word fragments can be produced and the meanings after word segmentation are very different from original meanings after word segmentation using the current word segmentation tool, and the formation rules of new words have the characteristic of high freedom degree. As a result, the current word segmentation method cannot effectively identify new words in network. The fragment library is constructed combining the formation rules of new word structures on the basis of the ICTCLAS2016 word segmentation system. The Bi?gram and Tri?gram modes are adopted to extract the candidate word strings in the fragment library. The left and right adjacent entropies are used for expansion and filtering of the candidate word strings. A new word recognition method based on rules and N?Gram algorithm is proposed. The results show that the word segmentation accuracy, recall rate and F values of the method are improved. The experimental results show that the new word recognition method can effectively construct the candidate new word sets and improve the effect of Chinese word segmentation.
Keywords: new word recognition; N?Gram algorithm; word formation rule; Chinese word segmentation; fragment library; recall rate
0 引 言
新词是一个最近铸造的发明词或者词的重新组合,来源于新事物的产生、方言的引言吸收,简略词汇、网络新词汇、外来语、旧词新用等,如“蓝瘦”“一带一路”。 随着网络的发达及网络用户的增多,新詞在网络上传播较快,使用频率也越来越广,但对新词的处理也带来许多挑战。目前,很多分词工具不能识别或是有效识别出这些新词,对这些新词分词后形成字碎片,没有表现它完整的语义甚至语义完全相反。
目前有的新词发现[1]方法可大致分为基于语言规则的方法和基于统计学习的方法。鉴于上述两种方法各自的不足,现在大多数学者都采用统计与规则相结合的方法,从而改进新词发现结果。
霍帅等提出基于统计的词关联性信息与统计特征与词法特征相结合的新词发现方法[1]。林自芳等首先进行重复串查询,之后结合词内部模式的特征对位置成词的概率和首尾单字成词改进方法,最后进行统计[2]。周超等首先对微博语料进行分词,将在两停用词间的相邻字串两两组合,根据组合后的字串频率统计取得新词候选串,再通过组合成词规则进行筛选获得候选新词,最后通过词的邻接域变化特性去除垃圾串获得新词[3]。
1 相关技术分析
1.1 候选字串结构制定规则
根据词语模式可知词语的长度大多介于2~4之间,因此本文提取的新词候选字串为二元组、三元组、四元组这三种类型。在碎片词中根据新词候选字串组成形式,二元组新词候选字串只有一种组合形式:“单字”+“单字”;三元组新词候选字串,有三种组合形式:“二字词+单字”“单字+二字词”“单字+单字+单字”;四元组新词候选字串,有五种组合形式:“单字+单字+单字+单字”“单字+单字+二字词”“单字+三字词”“二字词+单字+单字”“三字词+单字”。形成碎片库序列MC的获取规则如下:
1.1.1 单 字
1) 当连续单字碎片为n=1,若该单字碎片下一个编号的词是一个二字词或者三字词,则将它们加入到碎片库MC中;
2) 当连续单字碎片为n=2,若该单字碎片下一个编号的词是一个二字词,则将它们加入到碎片库MC中;
3) 当连续单字碎片为n>2,则该连续单字碎片加入到碎片库MC中;
4) 当与其连续的上一个编号的詞是一个单字且与其连续的下一个编号的词是一个二字词,则将它们加到碎片库MC中;
5) 当与其连续的上一个编号的词是一个二字词且与其连续的下一个编号的词是一个单字,则将它们加到碎片库MC中。
1.1.2 二字词
若与其连续的上两个编号的词是两个单字或其连续的下两个编号的词也是单字,则将它们加到碎片库MC中。
1.1.3 三字词
当与其连续的上一个编号的词是一个单字或者与其连续的下一个编号的词也是一个单字,则将它们加到碎片库MC中。
当遇到的是单字、二字词或者三字词,不存在与其连续编号的词,则跳到下一个编号的词开始判断。
1.2 N?Gram统计模型
N元统计模型[4]的主要思想是:一个单词的出现与N?Gram模型建立在一种假设前提下,即假设第n个词的出现只与前面n-1个词相关,并且与其他任何词都不相关,得到的各个词出现的概率的乘积就是整句的概率。
这种方法随着i的增大,其存在两个致命的缺陷:一个缺陷是wi的历史基元增多,不可能实用化;二是数据稀疏严重。
为了解决wi的历史基元增多,不可能实用化引入了马尔科夫[5]假设:一个词的出现仅仅依赖于它前面出现的一个或者有限的几个词。
如果一个词的出现仅仅与它前面出现的一个词有关称之为二元Bi?Gram。如果一个词的出现仅仅与它前面出现的两个词有关称之为三元Tri?Gram。
为了得到[Pwiw1,w2,…,wi-1],采用一种简单的估计方法:最大似然估计。即可得到: [Pwiw1,w2,…,wi-1=C(w1,w2,…,wi)C(w1,w2,…,wi-1)] (1)
式中,[Cw1,w2,…,wi]是统计序列[w1],[w2],…,[wi-1]出现在语料库中的次数。
而对于数据稀疏这个问题,需要进行数据平滑(Data Smoothing)处理。数据平滑的目的有两个:一个是使所有的N?Gram概率之和为1;二是使所有的N?Gram概率都不为0。
较为常用的平滑技术主要包括:Jelinek?Mercer的方法、Katz的方法、Church?Gale的方法。本识别方法使用的平滑技术是Katz[6]平滑模型:Back?off Model,该技术优点是参数较少可以通过计算得出,结果也更接近实际概率分布。该技术的思想是当一个N元Gram模型对[(wi-n+1,w2,…,wi)]词序列出现的概率为0时,将按照一个折扣估计退回到低元模型,并按照[Pwiwi-n+1,w2,…,wi]的比例分配为出现的N元模型对。
[Pwiwi-n+1,…,wi-1=discounted*Cwi-n+1,…,wiCwi-n+1,…,wi-1] (2)
[βwiwi-n+1,…,wi-1= 1-Cwi-n+1,…,wi-1>0Pwiwi-n+1,…,wi-11-Cwi-n+2,…,wi-1>0Pwiwi-n+2,…,wi-1] (3)
1) 当[Cwi-n+1,…,wi>0]时,则:
[Pwiwi-n+1,w2,…,wi-1=P(wi)Pwiwi-n+1,…,wi-1] (4)
2) 当[Cwi-n+1,…,wi=0]时,则:
[Pwiwi-n+1,w2,…,wi-1=βwiwi-n+1,…,wi-1Pwiwi-n+2,…,wi-1] (5)
结合式(2)~式(5)可以得到基于N?Gram模型分词算法的最佳切分输出方式。将[s=(wi-n+1,w2,…,wi)]词序列的最佳切分输出方式代入到式(1),推导可得如下公式:
[Ps=argmaxMi=1mPwiwi-n+1,…,wi-1] (6)
在实际计算中,为防止机器误差将很小的概率值当作零来处理,通常采用负对数处理的方式将问题转化为求极小值问题,具体公式为:
[P′s=-ln Ps=argminMi=1mlnC(wi-1,wi)C(wi-1)] (7)
1.3 新邻接熵
邻接熵一般用于统计方法的新词发现。使用邻接熵计算一对词之间的左熵和右熵,熵越大,字符串成词概率越大,越有可能是一个新词。
左邻接熵:
[HLx=-p(ax)log p(ax)] (8)
右邻接熵:
[HRx=-p(bx)log p(bx)] (9)
式中: [p(ax)]表示a为候选词x的左邻接字符的概率;[p(bx)]表示b为候选词x的右邻接字符的概率。
2 词识别
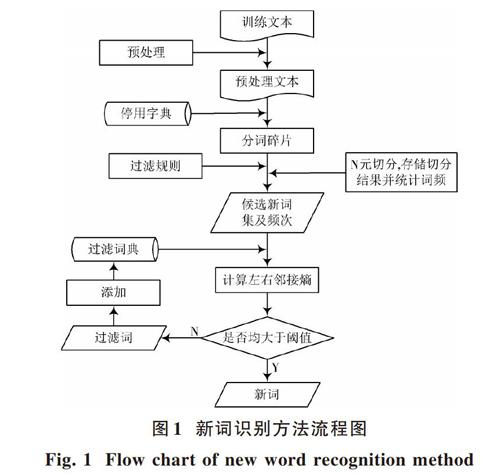
新词不同于普通词的构成结构,词语组成比较自由,并没有严谨的遵循传统语法结构。因为单纯的基于规则的方法,制定规则非常耗时,而且可移植性差,而单一的N?Gram模型移植性好,但是在大规模的数据中计算量大,所以本文提出了基于新词结构制定规则和N?Gram方法的新词识别方法。主要步骤如下:
步骤1:通过对预处理文本中的分词碎片进行处理,得到候选新词集合。
在加入碎片库MC过程中把每个文本中连续编号组成一个碎片子集序列FS,根据上述规则可知,FS是大于2个词的词序列。
例如:“第一/遍/可能/还/一知半解/不明/觉/厉”。根据规则可以得到2个FS :“第一遍可能”和“不明觉厉”。
基于N?Gram模型碎片库MC提取FS的候选字串算法如下:
算法:候选新词提取算法。
輸入:MC//碎片库序列;FS//碎片子集序列;
输出:CS//候选新词集合。
过程:
1) 在碎片库序列MC中,根据关键词候选串制定规则提取FS作为二元的Bi?Gram和三元的Tri?Gram模式的处理对象;
2) 先统计每个FS中每个词的频数,之后做归一化处理,最后利用Bi?Gram模式根据式(6)分别计算每个FS的二元组、三元组和四元组字符串的概率。把字符串和概率保存到数据库中;
3) 根据式(2)计算每一种分词结果的概率,选择最优结果,即利用式(6)求出概率P(s)的极大值,若是很小概率则使用式(7)计算概率。把所有字符串的概率按由大到小排序,选取排在前面一半的字符串作为候选字串CS1;
4) 利用Tri?Gram模式,重复过程2)、过程3),得到候选字串CS2,最后选取同时存在与CS1和CS2中的字符串作为候选新词集合CS。
步骤2:采用邻接熵对候选新词集合进行外部成词概率的筛选。
候选新词为二元组或四元组,计算左右邻接熵均大于阈值[7],加入新词集合。
候选新词为三元组,首先计算左邻接熵,是否大于阈值;若大于阈值,再对右邻接熵进行计算,把左右邻接熵均大于阈值的候选新词加入新词集合,否则向右扩展一个字符,再次计算右邻接熵;否则向左扩展一个字符,再次计算左邻接熵。
本文提出的新词识别方法具体流程如图1所示。
3 实验设计与结果
3.1 数据采集与预处理
以新浪微博为实验平台,主要以新浪微博的API接口,并结合网络爬虫技术,对2016年8月15日—9月5日期间关注的9个热点话题相关的微博数据进行采集。关注的7个热点话题包括:王宝强离婚、里约奥运、傅园慧洪荒之力、大学生徐玉玉电信诈骗案、王健林的目标、三星Note 7、杭州G20。
对采集到各个话题相关的微博信息进行预处理,通过数据分析发现微博数据中包含各式各样的垃圾数据,这些垃圾数据对话题发现的准确度产生负面影响。把筛选后的数据保存到数据库中,主要包括微博用户名、用户的关注人数、用户的粉丝数、微博发布时间、微博文本、微博评论等。oracle数据库中,微博条数共102 104,用户人数96 803,部分微博数据。把每条微博评论的内容放到每个TXT文档中,文档命名为微博编号。
对所有微博文本进行预处理:微博数据用ICTCLAS2016分词系统分词后,结合哈尔滨工业大学和百度停用词库,去除停用词,如“不管”“了”“吗”等后,把留下的词语保存到词语分词表中的同时进行词频统计,为提取候选新词做准备。文本预处理后保存,对前三个微博文本处理结果如表1所示(加位置编号)。
3.2 实验过程与结果分析
评价中文分词效果时,对评价指标召回率和精确度的具体定义如下:TP为正确切分的词语数;TP+FP为切分出来的词语总数;TP+FN为参考结果中的词语总数。引入准确率P和召回率R的概念和综合评价指标F1?Measure,有:
[P=TPTP+FP] (10)
[R=TPTP+FN] (11)
[F1?Measure=2×P×RP+R] (12)
式中:TP预测为正,实现为正;FP预测为正,实现为负;FN预测为负,实现为正;TN预测为负,实现为负。
本次实验抽取9 000条微博文本分三组作为输入,分别使用本文算法和中文ICTCLAS2016分词系统对其做分词处理,根据评价指标得到的结果如表2所示。
分析表2可知,本文分词算法在查准率、召回率和F1?Measure值上都要比使用中文ICTCLAS2016分词系统分词更好。
下面是对一条微博两种方法的不同结果对比:
1领导叫你和另外两位同志一起负责一个项目,他们两个人有冲突,请问你怎么协调落开展工作?
2傅园慧里约奥运会走红微博粉丝涨700万洪荒之力,表情包疯转请问你怎么看?
3小赵出差在外还要一周才能回来,他母亲生病,组织上特意派你去探望,请问你见到他母亲会怎么说。
ICTCLAS2016分词系统:
1/领导/叫/你/和/另外/两/位/同志/一起/负责/一个/项目/,/他们/两/个/人/有/冲突/,/请问/你/怎么/协调/落/开展/工作/?
2/傅/园/慧/里/约/奥运会/走红/微/博/粉丝/涨/700万/洪荒/之/力/,/表情/包/疯/转/请问/你/ 怎么/看/?
3/小/赵/出差/在/外/还/要/一/周/才/能/回来/,/他/母亲/生病/,/组织/上/特意/派/你/去/ 探望/,/请问/你/见到/他/母亲/会/怎么/说/?
本文算法:
1/领导/叫/你/和/另外/两位/同志/一起/负责/一个/项目/,/他们/两个人/有/冲突/,/请问/你怎么/协调/落/开展/工作/?
2/傅园慧/里约/奥运会/走红/微博/粉丝/涨/700万/洪荒之力/,/表情包/疯/转/请问/你怎么/看/?
3/小/赵/出差/在外/还要/一周/才能/回来/,/他/母亲/生病/,/组织/上/特意/派你去/ 探望/,/请问/你/见到/他/母亲/会/怎么/说/?
通过分析可知,使用本文第2节中的新词识别方法处理“表情/包”“洪荒/之/力”“两/个/人”“傅/园/慧”“里/约”,可以把候选新词“表情包”“洪荒之力”“两个人”“傅园慧”“里约”抽取出来。
4 结 语
本文利用规则和统计相结合的方法识别候选新词,给出候选子串结构制定规则,采用邻接熵选取新词。对于新词和人名ICTCLAS2016分词系统没有识别出来,而本文算法识别出来了,但是会把不同的字组合在一起形成错误的词语。整体而言,本文分词算法性能较高,新词发现结果较好。
参考文献
[1] 霍帅,张敏,刘奕群,等.基于微博内容的新词发现方法[J].模式识别与人工智能,2014,27(2):141?145.
HUO Shuai, ZHANG Min, LIU Yiqun, et al. New words discovery in microblog content [J]. Pattern recognition and artificial intelligence, 2014, 27(2): 141?145.
[2] 林自芳,蒋秀凤.基于词内部模式的新词识别[J].计算机与现代化,2010(11):162?164.
LIN Zifang, JIANG Xiufeng. A new method for Chinese new word identification based on inner pattern of word [J]. Computer and modernization, 2010(11): 162?164.
[3] 周超,严馨,余正涛,等.融合词频特性及邻接变化数的微博新词识别[J].山东大学学报(理学版),2015,50(3):6?10.
ZHOU Chao, YAN Xin, YU Zhengtao, et al. Weibo new word recognition combining frequency characteristic and accessor variety [J]. Journal of Shandong University (Natural science), 2015, 50(3): 6?10.
[4] MILLER D R H, LEEK T, SCHWARTZ R M. BBN at TREC7: using hidden Markov models for information retrieval [C]// Proceedings of the 7th Text Retrieval Conference. [S.l.: s.n.], 2008: 80?89.
[5] MANNING C D, SCHUTZEH H.统计自然语言处理基础[M].苑春法,李庆中,王昀,等译.北京:电子工业出版社,2005.
MANNING C D, SCHUTZEH H. Foundations of statistical natural language processing [M]. YUAN Chunfa, LI Qingzhong, WANG Jun, et al, translation. Beijing: Publishing House of Electronics Industry, 2005.
[6] HARB B, CHELBA C, DEAN J, et al. Back?off language model compression [C]// Proceedings of 10th Annual Conference of the International Speech Communication Association. Brighton: [s.n.], 2014: 352?355.
[7] 兰冲.基于统计规则的中文分词研究[D].西安:西安电子科技大学,2011.
LAN Chong. Research on Chinese word segmentation based on statistical rules [D]. Xian: Xidian University, 2011.
[8] 夭荣朋,许国艳,宋健.基于改进互信息和邻接熵的微博新词发现方法[J].计算机应用,2016,36(10):2772?2776.
YAO Rongpeng, XU Guoyan, SONG Jian. Micro?blog new word discovery method based on improved mutual information and branch entropy [J]. Journal of computer applications, 2016, 36(10): 2772?2776.
[9] 周霜霜,徐金安,陈钰枫,等.融合规则与统计的微博新词发现方法[J].计算机应用,2017,37(4):1044?1050.
ZHOU Shuangshuang, XU Jinan, CHEN Yufeng, et al. New words detection method for microblog text based on integrating of rules and statistics [J]. Journal of computer applications, 2017, 37(4): 1044?1050.
[10] 张海军,李勇,闫琪琪.一种基于海量语料的网络热点新词识别方法[J].计算机工程与应用,2015,51(5):208?213.
ZHANG Haijun, LI Yong, YAN Qiqi. Method of new Chinese words identification from large scale network corpora [J]. Computer engineering and applications, 2015, 51(5): 208?213.
[11] 杜丽萍,李晓戈,于根,等.基于互信息改进算法的新词发现对中文分词系统改进[J].北京大学学报(自然科学版),2016,52(1):35?40.
DU Liping, LI Xiaoge, YU Gen, et al. New word detection based on an improved PMI algorithm for enhancing segmentation system [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2016, 52(1): 35?40.
[12] 邢恩军,赵富强.基于上下文词频词汇量指标的新词发现方法[J].计算机应用与软件,2016,33(6):64?67.
XING Enjun, ZHAO Fuqiang. A novel approach for Chinese new word identification based on contextual word frequency?contextual word count [J]. Computer applications and software, 2016, 33(6): 64?67.
[13] 黄轩,李熔烽.博客语料的新词发现方法[J].现代电子技术,2013,36(2):144?146.
HUANG Xuan, LI Rongfeng. Discovery method of new words in blog contents [J]. Modern electronics technique, 2013, 36(2): 144?146.
