
大数据环境下多源异构数据的访问控制模型1
2019-02-20 07:49:22苏秋月陈兴蜀罗永刚
网络与信息安全学报 2019年1期
苏秋月,陈兴蜀,罗永刚
(1. 四川大学计算机学院,四川 成都 610065;2. 四川大学网络空间安全学院,四川 成都 610065;3. 四川大学网络空间安全研究院,四川 成都 610065)
1 引言
大数据平台不仅是分布式、高度可扩展的平台,还支持多源异构数据源的集成。随着大数据、云计算的不断发展,越来越多的企业将其内部数据存放在公共大数据平台中,以降低公司的运行成本。与此同时,如何保障平台中的数据不被其他租户非法访问,确保数据的安全性成为企业用户关心的问题。因此,如何实现云存储中多租户的数据安全隔离一直是业界研究的重点。
访问控制是实现数据受控访问、保护数据安全的有效手段之一。在存储海量多源异构数据的大数据开放平台上,为了实现租户之间数据的隔离访问,应实施高效、细粒度且灵活的访问控制。但在大数据平台中对多源异构数据的访问控制面临如下问题:首先大数据平台上汇聚了来自不同租户的异构数据,虽然基于Hadoop的大数据平台提供了不同的组件来存储这些多源异构的数据,但大多只能依赖访问控制列表(ACL, access control list)[1]实现粗粒度的访问控制,在使用过程中权限不易管控,存在用户可以擅自提权的风险;其次平台中用户、数据以及访问上下文环境在时刻变化,访问权限也需要随之变化,否则容易出现授权不足或过度授权的问题。
近年来,国内外企业和学者对 Hadoop平台的访问控制问题进行了深入研究。Hortonworks公司和Cloudera公司相继推出了Hadoop平台上集中访问控制的开源框架,分别是 Apache Ranger[2]和 Apache Sentry[3]。其中,Ranger采用基于策略的访问控制模型,通过设置策略为用户或用户组授予对数据的访问权限。Sentry采用基于角色的访问控制(RBAC,role-based access control)模型[4]。RBAC模型通过分配给用户的角色来授予用户访问的权限,并且可以通过构建角色层次结构来减少用户-角色分配,实现了对访问控制系统的简单管理。但在多租户环境下,用户-角色关系和角色-权限关系经常变化,安全管理员难以考虑所有的数据访问权限,使权限分配难度增加。
Gupta 等[5-6]总结 Ranger、Sentry 以及 Hadoop原生基于ACL这3种访问控制机制的特点,提出了Hadoop生态系统的多层授权框架和Hadoop生态系统授权模型。陈垚坤等[7]和Gupta等[8]将基于属性的访问控制(ABAC,attribute-based access control)[9]模型应用到Hadoop平台中,根据用户、数据、环境以及操作的属性制定访问控制策略,其中,相应属性可以包含实体的任何描述符,如标签、安全级别等。与RBAC模型相比,ABAC模型利用基于属性的访问控制策略直接定义了用户权限关系,实现了更加灵活的访问控制,在一定程度上避免了RBAC中权限分配困难的问题。但正是由于ABAC模型灵活的授权管理,目前属性的定义没有一个较好的格式标准,导致属性管理难度较大。另外,访问权限判定的时间消耗也取决于属性选择的复杂性。
文献[10-12]将 RBAC模型与主客体标签结合,提出了一种面向多租户云存储平台的访问控制策略。该策略通过比较主客体标签是否相符,确保了租户之间数据的强隔离性,但随着用户和数据不断变化,这种强制访问控制机制下的访问权限难以灵活地随之改变。Bhatt等[13]将角色作为属性之一添加到ABAC模型中,提出在多租户云环境下的一种属性角色结合的访问控制机制。王于丁等[14]进一步提出了一种基于角色和属性的云计算数据访问控制模型。最近,Gupta等[15]在Hadoop生态系统中讨论了角色与属性结合的方法,将对象标签作为对象属性添加到RBAC模型中,提出基于对象标签的角色访问控制模型。上述研究将属性与RBAC结合使用,实现了简单的授权管理和动态的权限分配,但均未解决属性管理复杂的问题。
针对上述问题,本文提出了大数据平台下多源异构数据的访问控制模型(MT-MHAC,access control model for multi-source heterogeneous data in big data platform)。该模型通过构建数据组层次结构扩展RBAC模型,避免了冗余的角色权限分配;采用基于属性的策略定义角色权限关系,细粒度、灵活地分配角色的权限;另外,将相同数据属性的数据分配到同一数据组,数据可以通过数据组的层次结构继承数据属性,避免为数据设置重复属性,简化了数据属性的管理。最后,本文将MT-MHAC模型实现在Hadoop平台中。通过实验验证,该模型可以满足多租户环境下,对多源异构数据细粒度、动态授权的访问控制需求,保障租户之间数据的安全隔离。
2 MT-MHAC模型
2.1 模型元素
RBAC模型为每个用户分配一个或多个角色,并通过定义角色层次结构减少了用户角色的分配工作。随着大数据向更多应用领域扩展,越来越多的数据涌入大数据平台中,RBAC模型下的角色-权限分配成为一项重大挑战。本文旨在Hadoop平台中多租户场景下,对多源异构数据实施灵活、细粒度的访问控制。本文使用数据治理工具 Apache Atlas[2]对平台中的多源异构数据进行集中管理,并在此前提下提出了MT-MHAC模型,如图1所示。

图1 MT-MHAC模型
在基于Hadoop的大数据平台中,很多组件中数据具有天然的层次结构。例如,分布式文件系统(HDFS)中的文件存在于目录树下;数据仓库工具Hive中数据有数据库、表、行或列这几种类型,也存在层次结构。MT-MHAC模型利用了平台中这些数据的特点,构建了数据组的层次结构,与 RBAC模型的角色层次结构相结合,简化了角色-权限的分配,可以将平台中具有相同属性的数据分配到同一数据组中,为该组分配适当的属性和属性值,而不用为每个数据分配属性。如果数据组之间还存在层次结构,可以间接通过其他数据组继承数据属性,通过这种数据组层次结构简化了数据属性的管理。另外,采用基于属性的权限策略,实现对多源异构数据灵活简单的访问控制,确保了租户间数据安全灵活的隔离。
为了保证MT-MHAC模型的正常运行,假设访问 Hadoop平台的用户均已通过身份认证。本文所提出的模型中实体包括用户(U)、角色(R)、会话(S)、数据(D)、数据组(G)、操作(OP)。属性集合包括数据属性(DATT)、环境属性(EATT)和操作属性(OPATT)。具体定义描述如表1所示。
2.2 实体间的关系
除了实体之外,模型中还包含实体间的关系,通过关系集合将各个实体集联系起来,实现实体中元素之间的操作。下面对这些关系进行定义。
定义1角色层次结构RH⊆R×R,表示在角色集合R上存在的偏序关系。角色的继承从低到高,即父角色继承其所有的子角色。若存在ri≻rj,其中ri,rj⊆R,则ri是rj的父角色。这里ri不仅具有其自身角色,还继承了rj的角色。
例如,用户 Gary被分配角色为developer,用户 Bard被分配角色为direct,其中,direct是developer的父角色。因此用户 Bard所拥有的角色除了被直接分配的direct之外,还有通过继承得到的developer。由此可知,角色层次结构可以方便地为单个用户分配和删除多个角色,简化了用户-角色关联关系的管理。
定义2数据-数据组分配DGA⊆D×G,等价于directG(d):D→ 2G,表示数据与数据组之间多对多的映射关系。可以将数据分配给多个数据组,通过函数directG获取数据并返回该数据所属的数据组集合。
定义3数据组层次结构GH⊆G×G,表示在数据组集合G上的偏序关系。若gi≻gj,其中gi,gj⊆G,意味着分配了数据组gi的角色将获得该组和来自低级数据组gj这2个组中所有数据的访问权限。
大数据环境下,租户将数据源源不断地从各种系统聚集到 Hadoop平台中,同时用户访问数据的上下文在不断变化,导致用户的访问权限需要及时更新。但在RBAC模型中,用户权限的更新只能通过修改或增加为用户所分配的角色,而角色的权限更新需要修改原有的角色权限关系,导致授权管理难度增加。为了解决上述问题,本文定义数据属性、环境属性和操作属性,根据属性策略进行角色权限分配,动态地建立角色与权限之间的关系。

表1 实体和属性定义
定义4属性是对实体特征的具体描述,记为ATT::=(att_nameopatt_value)。其中,att_name是指属性名称;op指属性运算符,包括<、=、>、≤、≠、≥等;att_value指属性的取值,可由有限的原子值或集合表示。例如, ∃datt⊆DATT,datt::= (type= {file、database、table})表示数据属性集中有一个属性为type,其属性值等于一个包含file、database和table的集合。
定义5数据组的有效属性effectiveGdatt,包含直接分配给用户组的数据属性和来自子数据组所继承的属性。对于∀datt∈DATT,∀g∈G,有
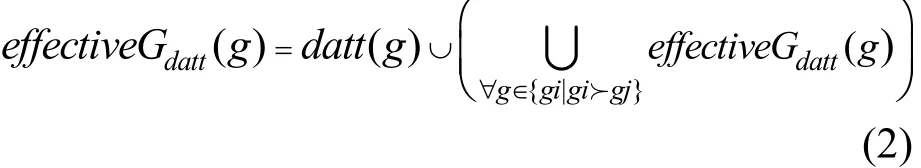
定义6数据有效属性effectiveDdatt,由自身具有的属性、所属数据组的所有属性,以及数据组通过继承其他组所得的属性这3部分组成。当为数据设置属性时,无须为每个数据都设置属性,只需将相同属性的数据添加到同一数据组,然后设置其最小权限范围的属性及属性值。数据组中的数据通过数据组的层次关系间接获得层次化的属性和属性值。本文通过这种数据组层次结构为安全管理员提供了简单灵活的数据属性管理,简化了角色-权限的分配。对于 ∀datt∈DATT,∀g∈G,有
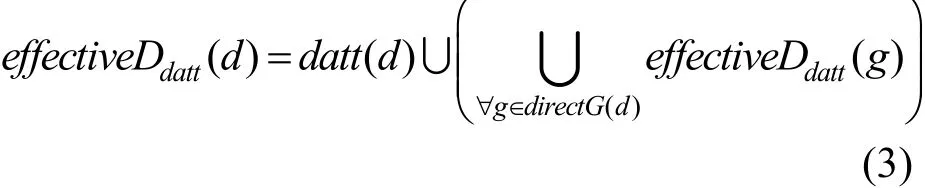
定义7基于属性的权限AP⊆DATT×EATT×OPATT,其中,∀eatt∈EATT,∀opatt∈OPATT,数据属性满足 ∀datt∈DATT⊆effectiveDdatt(d)。通过定义数据属性、环境属性和操作属性动态地确定数据的访问权限,实现了灵活的授权管理。
定义8模型中的函数
1) 用户-角色分配assignRole(u):U→ 2R,等价于UR⊆U×R,其中,∃r∈{ri|ri≻rj,ri,rj∈R},表示用户到角色多对多的映射关系。
2) 角色-权限分配assignPerm(r) :R→ 2AP,表示角色到权限多对多的映射关系。
3) 用户会话user_session(u) :U→ 2S,表示单个用户到会话集合的映射函数。
4) 角色会话role_session(s) :S→ 2R,表示会话到角色集合的函数,其中,会话所对应的角色应满足R⊆UR。
5) 角色权限判定规则如下:当用户在会话中所获得的角色r满足数据d的属性、环境属性eatt和操作属性opatt时,允许角色访问。

3 模型实现
为了将MT-MHAC模型应用到Hadoop平台中,本文利用基于Apache Atlas的元数据管理工具来集中管理汇集到平台中的多源异构数据。另外,在基于Apache Ranger的权限管理框架上进行了修改和扩展,以实现本文所提出的MT-MHAC模型。Ranger主要由2部分组成:策略服务器和插件。策略服务器即权限管理模块,负责管理策略和从Unix或LDAP同步的用户/用户组,以及为集成到组件中的插件提供策略信息和用户信息。插件是内嵌在组件中的权限判定引擎,通过从策略服务器定时轮询获取更新策略来评估访问请求。本文在权限管理模块中定义了访问控制策略决策点(PDP, policy decision point)、访问控制策略管理点(PAP, policy administration point)和访问控制策略信息点(PIP, policy information point),并且修改了Ranger的权限判定引擎和策略的定义。在权限管理模块中添加用户-角色表、数据属性表和环境属性表,以便安全管理员定义用户-角色关系、数据属性和环境属性。具体的实现细节如图2所示。
在模型的运行过程中,系统对用户访问数据的控制有2个重要阶段。一是授权阶段,当用户进入 Hadoop平台时,安全管理员在权限管理模块中将用户-角色表定义为用户所分配的角色;然后选择合适数据属性datt、环境属性eatt(如时间、位置等)和操作属性opatt,为角色设置基于属性的权限策略,建立角色与权限之间的关联关系,这样使用户拥有的角色在不同状态下的权限也不同,从而可以动态地确定用户的访问权限。二是鉴权阶段,权限管理模块中的PIP先从组件(图2中的Hive)中获取当前会话的用户信息和环境信息,从而根据用户-角色表得到其拥有的角色,然后通过查询数据属性表、环境属性表和操作属性表分别得到访问请求中数据的有效属性、环境属性和操作属性,将其与从 PAP获取的访问权限策略中对应的策略项进行一一匹配。若均匹配,则权限管理模块中的 PDP将权限判定结果true返回给组件中的 Ranger插件,即访问控制策略执行点(PEP, policy enforcement point),否则返回false。组件中的PEP根据PDP返回的结果执行具体的操作。
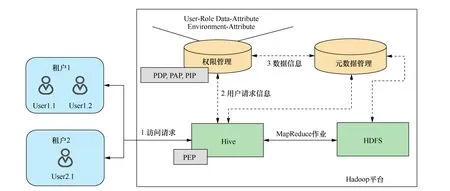
图2 MT-MHAC模型在Hadoop中的实现框架
例如,用户u提交访问Hive中数据d的请求,权限管理模块首先获取用户的访问请求信息request(u,d,op),根据环境属性表和操作属性表得到访问请求的环境属性eatt和操作属性opatt,再从元数据管理模块中获取d的属性信息,然后获取用户-角色表和角色-权限策略。根据访问权限判定算法(算法1)对访问请求request进行判定,并将访问判定结果返回给Hive中内嵌的Ranger插件,最终由Ranger插件执行允许访问或拒绝访问。
算法1访问权限判定算法
输入u,d,op
输出result ,result ∈ boolean

4 实验分析
4.1 用例
本节以下述应用场景为例说明MT-MHAC模型的有效性和优势。现有2个公司TOK和SUN租用同一大数据平台存储企业的数据,这里,同一大数据平台中角色定义和数据属性、环境属性等定义都相同。例如,定义了角色developer和direct,数据组analysis、collect和log,数据属性type={general、develop、network},环境属性location={china、sichuan、beijing }。其中,direct≻developer,analysis≻collect,analysis≻log。另外,数据组analysis包含的属性为type={develop},数据组collect包含的属性为type={general},数据组log包含的属性为type= {network}。根据各公司的访问需求定义了部分权限策略如下。另外,对不同组件中数据的操作不同,如HDFS中文件操作为r/w/x,Hive中数据操作为create/delete/update等。为了简化权限策略,这里没有定义数据的具体操作,均为access。
Policy1:{developer,type= network,location=sichuan,op=access}。
Policy2:{developer,type= general,location=beijing,op=access }。
Policy3:{direct,type= develop,location=beijing,op=access}。
假设有TOK公司员工Ablett和SUN公司员工Carl,且2个公司分别在四川和北京。TOK公司和SUN公司的安全管理员分别为Ablett和Carl分配了角色developer和direct。通过测试结果表明,根据Policy1定义的权限策略,Ablett只能访问本公司数据组为log中的数据。由于存在角色继承和数据组继承关系,根据 Policy2和Policy3定义的策略可知,员工Carl除了能访问数据组为analysis的数据之外,还具有数据组collect中数据的访问权限。通过该角色层次结构和数据组的层次结构,简化了角色分配和数据属性分配,从而为管理员提供了权限的简单管理。另外,虽然SUN公司的员工Carl通过角色继承拥有了developer角色,但根据策略中环境属性的定义,其不能访问TOK公司数据组为log中的数据。
上述实验表明,本文所提出的模型根据用户的角色以及角色是否拥有当前会话上下文环境下对数据的访问权限,严格限制租户之间数据的访问,实现了对多租户之间数据的安全隔离;并且通过层次化的角色和数据属性,简化了管理员的权限分配工作;基于属性的权限策略也为租户间及内部提供了细粒度、灵活的访问权限管理。另外,当平台中增加用户和数据或用户权限发生变动时,不用添加角色,通过更新基于属性的权限策略即可实现用户权限的变更。
4.2 性能分析
为了验证 MT-MHAC模型的性能,本文在Hadoop平台中进行了实验测试,其中Hadoop版本是2.7.3,Apache Ranger版本是0.7.0。本文通过测试时间开销来分析模型的性能,将MT-MHAC模型与RBAC模型、ABAC模型的访问控制决策时间进行对比,分析MT-MHAC模型的性能优势。根据访问控制策略判定用户的访问请求是访问控制过程中关键步骤,也是影响访问控制决策时间的主要因素。因此,本文为验证模型对 Hadoop平台的性能损失,将统计不同数量的访问控制策略下 MT-MHAC模型和 RBAC模型、ABAC模型的访问控制决策时间对比,结果如图3所示。
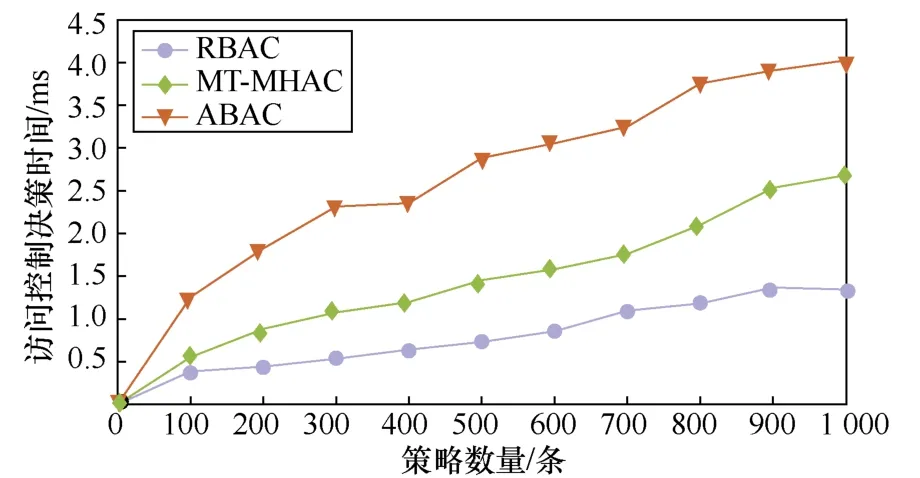
图3 策略数量与访问决策时间对比
随着访问控制策略的增加,三者的访问控制时间均呈上升的趋势。其中,MT-MHAC模型的整体访问决策时间与 RBAC模型相比稍高,是由于使用数据属性、环境属性和操作来确定角色的权限,但同时相比RBAC模型增加了角色权限匹配的灵活性。另外,通过添加数据组层次结构简化了角色权限匹配,MT-MHAC模型的访问决策时间低于ABAC模型。从图3中可看出,策略数量1 000条以内访问控制决策所用的时间仅在4 ms以内。即使策略数量达到上万条甚至几十万条,访问控制决策的时间开销依然能保持在毫秒级别。由此可知,MT-MHAC模型的访问控制时间开销对整个访问过程的性能影响较小。
5 结束语
本文针对大数据平台下如何实现多源异构数据的访问控制,确保租户数据的安全隔离问题,提出了MT-MHAC模型。该模型结合RBAC模型中角色层次结构,增加了数据组的层次结构,父数据组的权限可以直接从子数据组继承,简化了角色权限分配;使用基于属性的策略定义角色与权限的分配关系,提供了细粒度、灵活地授权;可通过数据组层次关系获得其他数据组的继承属性,提供了数据属性的简单管理。另外,本文利用Hadoop平台中的数据治理工具Apache Atlas集中管理这些异构数据,并在Apache Ranger的基础上进行修改,实现了本文所提出的模型;并且通过实验性能分析验证了MT-MHAC模型在对性能损失基本可以忽略的情况下,实现了大数据平台中多源异构数据灵活、细粒度的访问控制,保证了多租户数据之间的安全隔离。
猜你喜欢
高技术通讯(2021年1期)2021-03-29 02:29:44
法律方法(2017年2期)2017-04-18 09:00:37
中国公共安全(2017年11期)2017-02-06 05:28:08
计算机与数字工程(2016年11期)2016-12-13 06:51:06
通信学报(2016年11期)2016-08-16 03:20:32
项目管理技术(2016年6期)2016-05-17 05:38:29
现代工业经济和信息化(2016年19期)2016-05-17 05:38:20
信息安全研究(2016年10期)2016-02-28 20:18:36
特别文摘(2014年17期)2014-09-18 01:31:21
西安工程大学学报(2014年2期)2014-02-28 18:02:52
