
政府公开信息自动标引的设计与实现
2019-02-14 01:33江华丽曹祺陈刚
数字图书馆论坛 2019年1期
江华丽 曹祺 陈刚
(1. 武汉大学国家网络安全学院,武汉 430072;2. 灰觋集团有限公司,北京 100080)
1 研究背景
政府信息公开制度,是确保关联方及时获悉和学习国家方针政策,了解政府工作动态,进而有效执行的前提和基础。鉴于该制度的重要性,2007年4月5日,国务院通过《中华人民共和国政府信息公开条例》(国令492号)[1],并于2008年5月1日起正式实施。李盛[2]指出,“如果政府和群众之间的信息沟通渠道不畅通,就可能引发社会恐慌,甚至造成严重的社会危机”。国务院网站公布的文件,是按照政府信息公开条例目前的执行标准《政务信息资源目录体系》(GB/T 21063),该标准的主要作用在于尽可能相对完整和科学地保存政府公文的内容信息。而广大普通用户通常是通过大众的媒体渠道,如各种搜索引擎和新媒体等方式获取公开海量的政府信息,这也需要对相关公文进行自动化标引。同时,具体通过标引来添加相关标签,以便更好地被用户阅读访问和二次加工。
2 研究现状
目前,对于政府公开信息的自动化标引研究主要分为两类研究方法:一类是基于计算机相关技术,先从技术上来分析词频、词义,然后进行相关的标引,最后由行业专家进行修正;另一类是基于行业知识,先由行业专家进行分析和加工,进而进行人工或者计算机类辅助分析。本文主要是第一类研究方法。
对于第一类研究方法,贾君枝等[3]对比分析了各种自动标引方法的优缺点,将标引法分为词典标引、统计标引、单汉字标引、语义标引、神经网络标引和专家系统标引。本文的研究在词典标引的过程中,核心是元数据的分析和解析。在公文元数据分类领域,张新民等[4]对比了中国、英国、美国的政府信息公开的元数据定义指南,本研究参考了他的元数据定义规范。
第一类研究方法的核心是生成词库和标引流程,吴洁明等[5]设计流程图和标引流程,主要分为词库维护、自动化标引模块和人工修正模块。基于不同政府信息的词库可以挖掘出不同的结论,如邓雪琳[6]通过对政府工作报告中的关键词、高频词、关键段落字数开展计量,提出了相同同意度和信度两种测量模式,回溯性地测量了改革开放以来中国政府职能转变的特点,并预测了中国政府职能未来转变的趋势。在基于计算机技术建立词库的过程中,除根据政府公开的文件建立主题词库外,还可以基于相关的期刊进行词库建立。利用这些基于期刊的关联词库来对政府公文的词库进行修正。如朱晓峰等[7]选取了2006—2015年WOS和CNKI数据库,利用citespace分析了相关政府公开信息的主题词,研究相关趋势并生成相关主题词库。
对于第二类研究方法,王志刚[8]基于文本挖掘提出理念词频率概念,即在每万字的政府工作报告中某政府理念出现的次数,他通过政府公文计算其理念词频率,进而分析理念词频率和实际经济增速的变化。然而,理念词的内涵首先需要由相关行业的专家来定义,为此,这种分析的难度就在于行业专家定义词库本身。潘松[9]分析了公文中的汉语成语,基于汉语成语的语义来判断分析公文的褒贬色彩,但这种分析需要行业专家对公文中的成语进行预处理和定义。程大荣[10]通过政府公开刊载的意见统计来分析意见的使用频率、发文机关、发文形式、文种名称前缀修饰词、正文内容层次等5个方面的情况,但这种分析同样需要行业专家对发文机关的业务有一定的认识和理解。
3 实验与分析
3.1 数据分类
本文的政府公文实验数据来自国务院官方网站的“政府信息公开”专栏。国务院公文数据分为公文元数据和公文全文数据。其中,公文元数据包含索引号、主题分类、发文机关、标题、发文字号、发布日期、成文日期、主题词8种类别。本文研究发现,公文的索引号并不是唯一标识符,如国函〔2016〕64号和国办函〔1992〕4号这两份公文的索引号均为000014349/2016-00057,但它们的发文字号是唯一标识符。
发文字号主要分为国令、国发、国函、国发明电、国办发、国办函、国办发明电和其他8种类别。发文机构分为国务院和国务院办公厅,其中,“国发”代表国务院发文,“国办发”代表国务院办公厅发文,国务院发文的权威性高于国务院办公厅发文。从发文类别上看,国务院的发文分为国令、国发、国函和国发明电4类。
发文分为自上而下制定和自下而上制定两类。自上而下制定是指基于现有法律制定的条例,如针对全国人大通过的《中华人民共和国个人所得税法》制定《中华人民共和国个人所得税法实施条例》;又如本文研究的《中华人民共和国政府信息公开条例》(国令492号)就暂无对应的法律,属于先实施条例,待条例成熟后再决定是否转化为法律。
国发和国函的区别在于,国发一般是针对全国,而国函是针对行业或者地域,不具备全国性。如《国务院关于支持自由贸易试验区深化改革创新若干措施的通知》(国发〔2018〕38号),而同样是自贸区公文文件,针对地方的公文文件《国务院关于同意设立中国(海南)自由贸易试验区的批复》,则是属于国函〔2018〕119号。
一份国令往往对应多份国务院文件或者国务院办公厅文件,如《中华人民共和国政府信息公开条例》(国令492号),其相关的国办文件有《国务院办公厅关于推进社会公益事业建设领域政府信息公开的意见》(国办发〔2018〕10号)、《国务院办公厅关于推进公共资源配置领域政府信息公开的意见》(国办发〔2017〕97号)和《国务院办公厅关于推进重大建设项目批准和实施领域政府信息公开的意见》(国办发〔2017〕94号),它们分别是政府信息公开条例在社会公益、公共资源配置和重大建设项目领域的细则。
明电属于一般不具备保密属性的政府公文,如《国务院办公厅关于2019年部分节假日安排的通知》(国办发明电〔2018〕15号)。对于国务院办公厅的文件的规则也类似于此。
3.2 数据采集
本文研究发现,政府公文的唯一标识符是政府文号,考虑到历史公文数据的正确性,本文对于实验数据的准备主要是基于政府信息公开目录纸质文档。这些文档可以从政府信息公开的专栏中下载获取,本文具体的数据清洗流程如下。
(1)下载政府信息公开目录纸质文档,采用Apache PDFBox抽取政府文号,并校对政府文号。文号校对主要是针对历史公文,如国发〔1969〕50号文件,其纸质目录的文号为(69)国发文50号。本文利用Java模板技术进行字符串替换,共计得到1969—2018年的4 833条公文元数据。
(2)根据公文号下载对应的公文,采用Selenium引擎Chrome版进行下载。本文研究发现,并非所有的公文都保存为文本或者网页形式,还有一些公文是以图片数据形式保存。作者对下载的公文采用Apache PDFBox抽取全文数据,发现全图片公文数据只有190条,占比仅为3.9%。如《国务院办公厅转发国家计委、交通部关于加强港口建设宏观管理意见的通知》(国办发〔1995〕56号)就是全图片公文。
(3)本文将采集的数据存入MySQL数据库,方便下一步进行标记实验。MySQL中元数据主要采用直接文本存储,而对于公文的全文则通过HtmlParser的Java库去掉HTML标签,存储到MySQL数据库。
3.3 数据标引流程原理
本文标引流程设计的核心是先分类后标引,如对行业、地域等进行分类。标引的原理是根据词性建立范式,并基于固定表达(如“军民融合”)进行范式的过滤。因此,该方法标引的同时,程序会生成中间临时文件。这些中间临时文件就是根据范式的规律和政府规划用语的固定表达而生成的词库。本文的范式是基于词性创建的,固定表达来自规划文件中高频词(如“一带一路”“军民融合”)的统计,且不对这些固定表达进行修改。本文与TF-IDF等其他方法的一个明显区别,就在于它在标引过程中产生了新的分类体系,以及基于文件本身生成的词库文件。这也是本文数据标引流程设计的创新之处。
3.4 数据标引定义过程
本文研究是通过文本标引来进行自动分类,自动标引生成标签(Tag)。
本文进行自动标引的主要原理是建立标题、公文号和自动标引关键词集的三元关系,见公式(1)。

其中,Result代表是否成功标记;pcode代表公文号;title代表标题;keywords代表自动标引生成关键词集合,每个关键词之间用“/”符号分割,keywords初始值为NULL;state代表自动标引后状态,未参与标引初始state值为0,已经参与自动标引但是标引失败state值为1,成功标引state值为2;method代表生成标引的分类器方法,初始方法method值为NULL。
对于《国务院关于苏州市城市总体规划的批复》(国函〔1986〕81号)标记为:Result(国函〔1986〕81号)= F(国务院关于苏州市城市总体规划的批复,NULL,0,NULL)。
对于《国务院办公厅关于印发“十二五”全国城镇生活垃圾无害化处理设施建设规划的通知》(国办发〔2012〕23号)则标记为:Result(国办发〔2012〕23号)= F(国务院办公厅关于印发“十二五”全国城镇生活垃圾无害化处理设施建设规划的通知,NULL,0,NULL)。
3.5 基于地域关键词的标引
本研究主要基于自然语言处理技术(natural language processing,NLP),采用的NLP引擎为复旦大学开发的FudanNLP。本文实验主要分为7个步骤。
(1)加载数据源。对全集按照公式(1)进行标记,共有4 833条,计数方法为Count,见公式(2)。
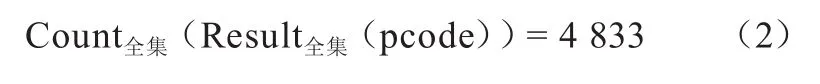
(2)初始化数据。对全集中每个标题进行筛选,并且进行初始化标记。如对于《国务院关于苏州市城市总体规划的批复》(国函〔2016〕134号),按照公式(1)标记记录为公式(3)。

(3)遍历数据分词。对公式(3)的字符串采用Fudan NLP进行分词,分词的字符串为“国务院关于苏州市城市总体规划的批复”,分词的结果为:
国务院/名词 关于/介词 苏州市/地名 城市/名词 总体/名词 规划/名词 的/结构助词 批复/量词
从结果中可以看到,如果关系的是地域,则需要提取苏州市。由此公式(3)就变换为公式(4)。

(4)数据标引。对于分词的数据需要进行标引,标引的目标是把词变成统一的词组。则可以对不同的词组从多个不同维度添加标签。对于公式(4)中,苏州市是地域名词,地域名词之后的名词可能是对该地域的说明,如“城市”。而名词之后出现的词语如果是“总体”,则属于修辞名词。“总体”之后“规划”属于类型名词关键词。因此需要进行检查地域名词之后的名词,使其满足范式。本文通过词频统计,发现满足的范式为:[地名][地名补充关键词][修辞名词][类型名词关键词]。
类型名词代表该公文的主要作用,如“规划”,则公式(4)的状态改为公式(5)。

根据词频统计结果,地名补充关键词结合LOCATION集合主要包含以下名词,见公式(6)。

(5)标引压缩。考虑到关键词搜索时要进行歧义消除,需要对公式(5)进行压缩,即删除“[修辞名词]”,同时对名词的并列语进行处理。如对《国务院关于辽河、松花江流域综合规划的批复》(国函〔1994〕82)进行提取,关键词集合见公式(7)。

(6)标引存储。对于公式(5),进行标引压缩后,其最终结果如公式(8)。

Result(国函〔2016〕134号)由于标引成功,其结果Result(国函〔2016〕134号)值为真。
(7)更新计数器。完成“国函〔2016〕134号”后,更新公式(2)中数量,计数器减1。基于地域方法的遍历,本文研究发现共有316条符合地域关键词范式,即对于符合地域关键词的范式标记为:Count地域关键词(Result地域关键词(pcode))。
实验结果在MySQL数据中如图1所示。

图1 基于地域关键词的数据标引结果
3.6 基于行业关键词的标引
除地域关键词外,还有一类属于行业,如《国务院关于印发新一代人工智能发展规划的通知》(国发〔2017〕35号)。这类规划中不包含地域名词,与上述处理方法的差别主要在于数据标引和标引压缩两步。
从词频的统计结果来看,这类规划多为五年规划,如《国务院办公厅关于“七五”期间以煤代油计划安排问题的通知》(国办发〔1985〕76号)。范式如:[规划关键词]…[行业名词或者物品名词]。
其中,规划关键词包含“五年规划”中的关键词“五”,采用类似的程序处理流程,文本发现满足规律的共计114条,记为公式(9)。

实验结果在MySQL数据中如图2所示。
基于以上研究发现,不论是基于地域关键词还是基于行业关键词,对于标引后的标题数据在搜索时都可以更加精确;但考虑到政策文件的特殊性,不适合直接基于NLP的方法标引,而需要根据标题结合词频统计的原理分析得出不同的范式,并生成不同的模板进行处理。加之,国家的五年计划都具备连续性,如果用同一类数据生成同样的数据标引,则能更高效地搜索该规划从“十一五”“十二五”“十三五”发展的历史沿革。具体来说,以基于地域关键词的数据进行查询,可以看到长春市、大连市、乌鲁木齐市的城市规划在国务院文件中至少提过3次,进一步以关键词“长春市/城市/规划”为例查询数据,结果如图3所示。
“长春市/城市/规划”在国函〔1985〕63号、国函〔2011〕166号和国函〔2017〕87号分别被提到,从这3份文件中也可以看出长春市规划的历史沿革和改革的延续性。

图2 基于行业关键词的数据标引结果

图3 长春市城市规划次数
4 对比实验与分析
4.1 对比实验的设计
本文的研究思路是基于词频统计结果,通过不断地分类和提取范式,是一种半自动化半人工、交互式的分析方法。如果利用已经分析完成的词库和范式库,可以对其他相同领域的公文数据进行标引。
除了本文的标引方法,常见的其他标引方法还有TFIDF(Term Frequency-Inverse Document Frequency)模型和主题模型。这几类模型的发展顺序是首先是TFIDF模型,在TF-IDF模型的基础上发展了LSA(Latent Semantic Analysis)模型,在LSA的技术上发展了pLSA(probabilitistic Latent Semantic Analysis)模型,最后在pLSA模型的基础上发展了LDA模型。
TF-IDF模型通过对语料库进行分词,进而建立关键词库。其中词频(TF)指的是关键词在语料文件词中的频率,而逆文档频率(IDF)指关键词在文件总数的频率,程序处理时需要先对逆文本频率取对数,然后计算TF和IDF的乘积(即为TF-IDF值),最后根据TF-IDF进行提取的关键词用来对该文档进行标引。TF-IDF模型是对一份文档的所有词频进行标记,导致词频和文档的构成矩阵维度巨大。相关学者在此基础上,用文档部分关键词代替全文档,这就是LSA模型的核心思想。
LSA模型是通过建立关键词和文档的矩阵,对矩阵进行奇异值分解(singular value decomposition,SVD)降维,用部分关键词代替整个文档的属性,而LSA技术的主要作用就降维。LSA的局限性在于,对于矩阵进行SVD分解需要保证各个主题关键词是互相垂直的向量,如果一个关键词存在多个含义,则会导致无法区分而造成错误,这在中文的政府公文分析中尤为严重,因为中文的词义比英文复杂。
在LSA的基础上,相关学者提出了pLSA模型。与LSA的区别就是pLSA增加了文档在语料库中的概率。
在pLSA模型基础上发展的是LDA模型,LDA模型在pLSA的基础上增加了主题的Dirichlet先验分布后得到的贝叶斯模型,pLSA只能对语料库中文本进行语义识别,而无法识别不在语料库的文本语义,但是LDA模型可以。
本文测试TF-IDF模型和LDA模型采用的语料库为上文中基于地域关键词的数据的公文标题数据,测试数据为316条,本文对比研究的程序基于Python的NLP框架gensim进行编码,具体测试代码分为模型训练代码和模型测试代码。
4.2 对比实验的结果
如图4~图7所示,对比实验结果(均取前10)。
通过图4和图5对比发现,默认gensim并没有将长春作为一个单词给分割,因此TF-IDF模型的实验效果和LDA模型的实现效果都不好,都不如本文研究方法。
通过对比图6和图7发现,默认gensim虽没有将长春作为一个单词给分割,但是将规划作为一个词语,并且LDA模型会优先考虑包含“规划”的词组,如“总体规划”,而TF-IDF则更考虑完全匹配的词。

图4 关键词为“长春”(TF-IDF模型结果)

图5 关键词为“长春”(LDA模型结果)

图6 关键词为“长春/规划”(TF-IDF模型结果)

图7 关键词为“长春/规划”(LDA模型结果)
4.3 现象的原因分析
根据4.1的实验和4.2的数据显示,LDA的效果不如TF-IDF,因此,本文主要分析TF-IDF方法和本文方法存在的区别及原因。
在实验中,TF-IDF方法对搜索“长春”的结果错误,原因是在进行gensim分词时,采用Python的jieba分词引擎。该分词引擎是基于中文通用词库,在分析本文时,分词的词语是“长春市”,而不包含“长春”,由此导致结果错误。
本文的数据标引是基于NLP的模板范式,先考虑词性,即基于词性自建词库,然后建立基于词性的句式模板,并用该模板来匹配关键词,而不采用通用词库。
尽管TF-IDF的优势在于自动化处理,但是TF-IDF加载通用分词引擎,需要增加停用词(stopwords),而停用词只能删除,不能合并。在本文研究中,jieba分词引擎将“军民融合”分词为“军民/融合”。对于“军民融合”属于规划中的固定表达,TF-IDF采用通用词库分词会导致结果错误,而本文的优势就在于基于词法、句法的规律提取词性范式,并且是先分类后标引。如“建立人工智能特色小镇”属于建设类而不属于技术类规划,“人工智能芯片”则属于技术类规划。因此,通过本文的研究方法,不会出现词语搜索错误的情况,即不会出现图4和图6的情况。这也是本文相较于TF-IDF的主要优势。
本文提取词时会根据FudanNLP引擎考虑词义,如根据地理位置和行业进行区分。另外,在未来的研究中,本文会进一步考虑词语的上位词关系、同义词关系,这是TF-IDF无法处理的情况。
然而,本文方法的局限在于,需要半人工的提取范式和行业词库。
5 研究结论
本文提出了一种综合词典标引和语义标引的方法来分析政府公开信息数据,使用复旦大学的FudanNLP开源包对公文标题进行分词、词性标注等处理,再通过句法和语义分析方法提炼范式,最后寻找满足范式的关键词作为标引。
同时,将本文的标引方法与TF-IDF模型和LDA模型进行了对比研究。本文标引的准确度比TF-IDF模型和LDA模型高,主要在于该标引方法不会出现搜索不到的情况,但是本文标引的自动化程度不如TF-IFD模型和LDA模型。本文需要结合行业知识构建词库和范式。
由于本文的范式是基于词性和行业特点,本文的词库会根据词性抽取具体的固定表达;同时,本文先分类后标引,标引基于范式提炼词库,因此,效果会比常见TF-IDF好,不会出现明显错误和搜索不到的问题。
另外,本文的主要工作为将自然语言处理方法应用于对政府公开信息数据的分析,而对相关公文进行标引便于民众在新媒体和搜索引擎中搜索政府公开信息,因此对公文进行自动化标引具有重要意义。
同时通过本方法进行自动化标引的关键词库,可以作为其他相关研究者底层技术的词库。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
资源信息与工程(2019年2期)2019-05-09
电脑爱好者(2017年5期)2017-05-04
图书馆理论与实践(2016年11期)2016-12-20
中国卫生标准管理(2016年3期)2016-02-05
中国卫生标准管理(2016年8期)2016-02-05
