
云环境下基于线性回归和协同过滤的负载预测方法
2019-02-12 08:23栾奇麒,许杰雄,杨勤胜,豆龙龙
无线互联科技 2019年23期
栾奇麒,许杰雄,杨勤胜,豆龙龙
摘 要:文章针对云环境下容器负载的预测分析问题,根据现有相关集群数据对系统资源进行可视化与分析,利用数据的相关性,结合线性回归、协同过滤算法,对容器的负载进行动态预测。
关键词:云环境;线性回归;协同过滤;负载预测
1 云计算技术为预警提供数据支持
云计算作为新兴技术,能够将网络资源、硬件资源等按需求分配给相应的计算节点来执行任务,于是“云”便作为一种服务提供给用户[1]。为保障用户的服务质量并降低系统成本,实时、高效地监控云系统资源,并实现准确地预测、分析成为亟需解决的问题。本文提出并实现的一套云资源监控预警系统,能够直观地看到目前云平台的资源使用情况,并能够对资源进行简单的预测,根据资源使用的历史数据找寻相应的规律,挖掘数据间隐藏的关系。对资源的状态变化进行预测,能够有效地对可能发生的状况进行预警,从而为将来预警措施的实现提供相应的数据支持。
本文数据集采用阿里云2018trace,目的是对系统整体进行相应的分析以及分析、预测某一台具体机器的CPU,Mem,Netin,Netout,Disk的走势,从而为将来的预警分析提供相应的数据支持,建立更加高效、稳定的平台。
2 Ceilometer功能分析
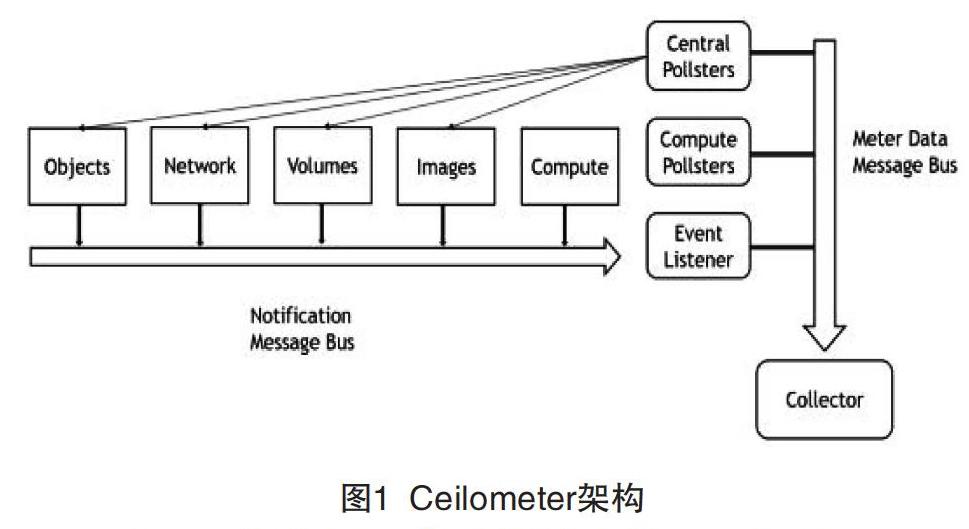
为了能够更好地收集系统信息以及进行资源的计量,Ceilometer应运而生[2]。2012年,Ceilometer公布了第一代版本,主要完成对一些重要数据的计量,包括Compute,CPU,Network,Memory,Volume,Image等,其架构如图1所示。
图1 Ceilometer架构
Ceilometer收集信息主要通过两种方式:(1)Notification,一切OpenStack服务都发送关于系统状态或执行操作的通知,一些通知包含可以计量的信息,例如,OpenStack计算服务创立的VM实例的CPU时间。之后通知代理负责使用该Notification,通过消息总线,将Notification转换为相应的事件和度量,但需要注意的是并非所有的Notification都会被消耗,只有那些可被捕获且能够用于分析、监控目的的Notification可以被消耗。(2)Polling,每个Compute节点上都运行Compute agent,通过调用Image的driver以轮询的方式来获取资源的各种统计使用数据。Management server上则运行Central agent,通过调用OpenStack各个组件以轮询的方式收集资源使用统计数据。
通过以上两种方式得到的数据,在经过消息队列处理之后,被Collector接收,再通过一个或者多个分发器(dispatchers)原封不动地将它保存到指定位置。
3 基于线性回归和协同过滤的负载预测模型
对于云资源态势的预测,国内外也有一些研究,大部分的是像亚马孙的AWS,没有注重数据之间的关联,即没有对数据进行深入的挖掘,得到的结论比较单薄,且大多结论的可信度不高。国内的一些研究运用到了诸如Apriori算法,运用数据关联分析去进行预测,非常适合云资源态势的预测,能够挖掘出更多的数据相关性。事实证明,运用数据关联得到的结论也更好。
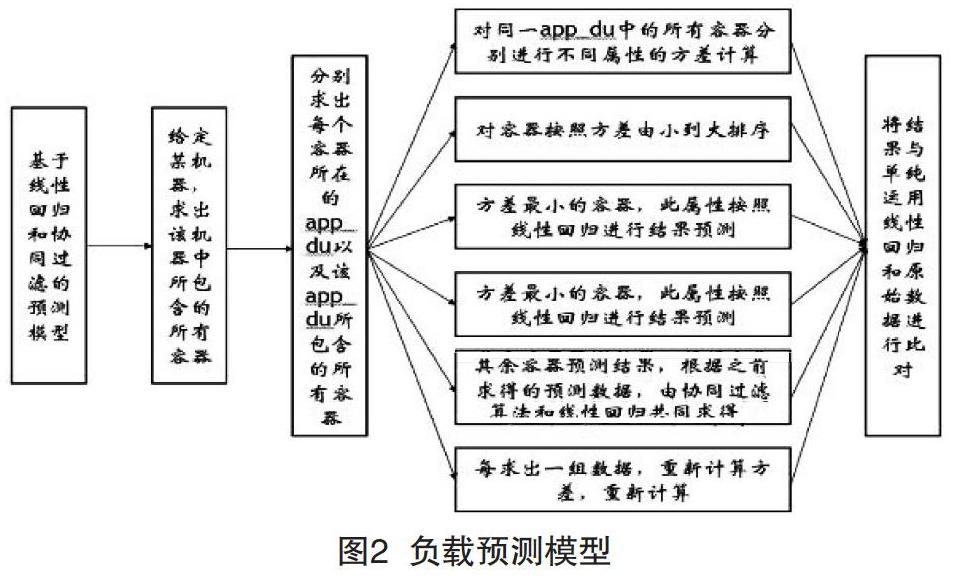
图2是基于线性回归和协同过滤的预测模型,包括给定机器并求出该机器所包含的所有容器功能、给定容器求出该容器所在的app_du以及该app_du所包含的所有容器功能、对同一app_du中的所有容器进行分析预测、将机器中的所有容器预测完毕的结果进行结合、线性回归和协同过滤占比系数的确定等。
图2 负载预测模型
对于同属于一个app_du的容器,即同属于一个应用程序,其之间的相关性是显而易见的。当有新的任务到来时,同属于一个app_du的所有容器一定是共同工作的,当任务处理完毕,这些容器也一定是同时歇息,其之间的资源走势,不管是数据的峰值,还是数据的变化,都有着极大的相似性,不需要再调用额外的算法去破坏这种相关性,得到更好的结果。
数据预处理:根据图2的模型,需要对所分析的数据进行预处理。数据表中的每一条数据都标明了机器号、容器号以及app_du号,所以数据的提取比较方便,但是数据表中的数据过大,需要做额外的处理。具体做法是运用字典排序对原始数据进行处理,可以添加标记,记录每次已经处理过的数据位置,下次可以直接从标记处进行处理,而不用从头开始,能够节省查找的时间。同时,数据表中有大量的非法数据以及空白数据,在读取的过程中设计了相应的判断,对于非法数据进行抛弃操作,保证实验结果的精度、可信度。
4 实验结果
实验用的数据集是阿里2018年发布的最新数据,该数据集包含的內容十分丰富,Job,Task,Instance,Machine,Container等数据都能找到。本数据按照时序排列,时间戳time_stamp代表从开始计时的第一天起所经过的秒数,本数据集共采集了8天的数据,足够满足本次实验的要求。
第一步:对系统整体进行分析,希望达到的效果是能够直观地看到系统目前的资源利用率以及给定相应的阈值,能够得到超出此阈值的机器,以便管理员进行排查。
第二步:选取一台机器,求出其包含的所有容器以及每个容器所在的app_du,取出它们按照时序排列的诸多属性的数据。
第三步:根据每个容器所在的app_du,按照上文所介绍的基于线性回归和协同过滤的预测模型,分别对每个app_du中的所有容器进行预测。
第四步:在对每个app_du中的容器进行预测之后,取出其中被选定机器包含的所有容器的数据。
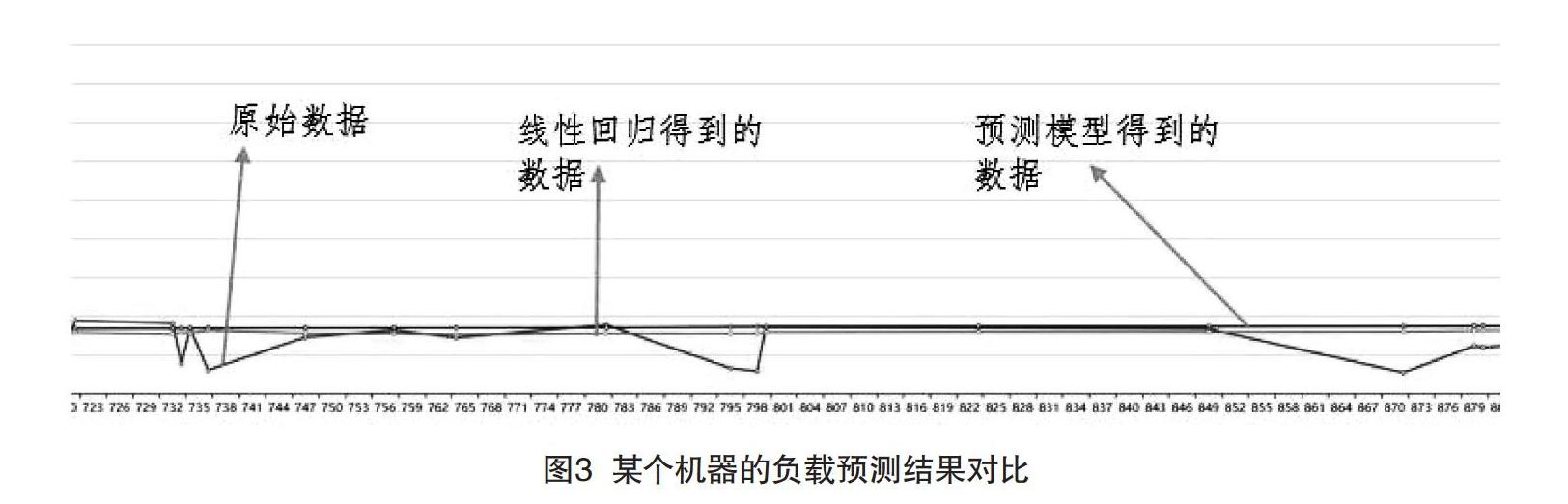
第五步:将此预测数据、单纯运用线性回归进行预测的数据、和原始数据运用Echarts这一组件,在Web页面上进行可视化和比对,从而突出本预测模型的效果。
圖3展示了针对其中某个容器的具体预测结果,运用折线图的形式来表示。基于预测模型得到的效果更佳。
5 结语
本文针对负载预测问题,提出了一种结合线性回归和协同过滤的融合方法,考虑数据间的关联性,实现更好的负载预测效果。
作者简介:栾奇麒(1990— ),男,江苏泰兴人,助理工程师,学士;研究方向:云计算。
图3 某个机器的负载预测结果对比
[参考文献]
[1]孙岩炜,郭云川,张玲翠,等.基于多选项二次联合背包的态势感知资源分配算法[J].通信学报,2016(12):56-66.
[2]赵少卡,李立耀,凌晓,等.基于OpenStack的清华云平台构建与调度方案设计[J].计算机应用,2013(12):3335-3338,3349.
Load prediction method based on linear regression andcollaborative filtering in cloud environment
Luan Qiqi, Xu Jiexiong, Yang Qinsheng, Dou Longlong
(JiangSu Frontier Electric Technology Co., Ltd., Nanjing 210000, China)
Abstract:Aiming at the prediction and analysis of container load in cloud environment, the system resources are visualized and analyzed according to the existing cluster data, and the container load is predicted dynamically by using the correlation of data, linear regression and collaborative filtering algorithm.
Key words:cloud environment; linear regression; collaborative filtering; load forecasting
