
基于GBRT树模型分位数回归预测的CPFR补货方法
2019-02-07 05:32孙延华张冬杰曾庆维金健陈桓姚小龙
软件导刊 2019年12期
孙延华 张冬杰 曾庆维 金健 陈桓 姚小龙

摘要:随着大数据的发展和物流科技信息化进程的加快,企业供应链数据呈爆炸式增长,且种类繁多、关系网络复杂,而传统cPRF技术中的预测模型已经不能适应供应链大数据需求预测,更不能依据需求预测进行有效的库存管理,经典的周期库存盘点策略也不能很好地适应非正态分布的需求数据,如何对供应链大数据进行准确预测并补货已成为供应链研究的热点。依据大数据的分位数回归预测技术,利用历史数据信息进行准确预测,并将分位数回归预测与补货模型合理有效连接,通过真实数据仿真分析,表明在98%的服务水平下,平均库存得到了降低。
关键词:大数据;物流供应链;CPRF;分位数回归预测;服务水平;库存
DOI:10.11907/rjdk.192360
中图分类号:TP306 文献标识码:A 文章编号:1672-7800(2019)012-0035-05
0引言
在经济全球化和科技物流迅速发展的今天,企业供应链的科学有效管理依赖于现代信息技术,各供应链企业也积累了丰富的供应链大数据,如何利用大数据技术进行供应链优化受到高度关注。CPRF技术是计算机领域与供应链库存管理领域相结合的研究热点。供应链是指围绕核心企业,通过对信息流、物流、资金流的控制,从采购原材料开始,制成中间产品以及最终产品,最后由销售网络将产品送到消费者手中,并将供应商、制造商、分销商、零售商、最终用户连成一个整体的功能网链结构模式。同一个企业可能构成该网链的不同组成节点,但更多情况下是由不同企业构成该网链的不同节点。供应链管理是一种集成管理思想和方法,是在满足一定客户服务水平条件下,为使整个供应链系统成本最小,将链上各节点有效组织在一起而进行的产品制造、转运、分销及销售的整体管理模式。
库存表示用于将来目的的资源暂时处于闲置状态,设置库存的目的是防止短缺,其对企业供应链管理具有重要作用,可提高服务水平并降低成本。优秀的库存管理模型既能减少缺货成本,又能提高企业服务水平,而过多的库存也会给企业带来损失,库存过多会长久地积压在库,势必造成资金周转缓慢、资本回报率低。要进行精确的库存管理,合理的预测模型必不可少。CPRF技术是最新的供应链管理技术,可提高预测准确度,最终达到提高供应链效率、减少库存和提高消费者满意度的目的。
随着经济全球化的加快,零售企业将面临全世界范围内的巨大竞争压力,迫切需要利用有价值的商业信息和知识应对日益剧增的市场挑战。随着计算机信息技术的快速发展,大量信息技术如条形码、电子收款机、POS系统已在零售业广泛使用,这些信息系统的日益庞大积累了大量销售交易数据,如何基于零售业销售信息得到准确的预测知识,以帮助零售企业作出正确决策,更好开发CPRF技术中的预测模块,是当前零售业亟待解决的问题。
数据挖掘是从大量、不完全、有噪声、模糊、随机的实际数据中,提取隐含、未知而又潜在有用信息与知识的过程。而传统零售业的销量预测有季节分析模型、马尔科夫预测模型等,但这些模型都是基于简单的统计技术,利用历史数据和商品销量数据,不能深层次地挖掘影响销量的一些原因与特征,数据维度单一,数据量大小对于预测准确性提升有限,对于长期变化规律的场景捕捉能力差。本文利用数据挖掘技术挖掘各种影响销量的相关特征,建立树模型对其销量进行预测。预测模型能快速捕捉到市场变化,具有强大的特征识别和挖掘能力以及防止过拟合的优势,非常适合突发事件预测。本文将计算机大数据机器学习技术与供应链CPFR技术相结合,提出基于分位数回归预测的补货模型。
1相关研究
1995年,沃尔玛与其供应商Warner-Lambert等5家公司共同开发出CPFR(collaborate Planning Forecastingand Replenishment)技术。CPFR是零售行业中的一种供应链管理方案,在提升供应链运行效率的同时也加强了供应链各环节之间的协同合作能力,它是在VMI(供应链管理库存)之后集预测和补货于一体的供应链整合全新技术。CPFR的预测提高了需求预测准确度,从而能科学有效地制定库存策略,降低生产、运输、库存持有成本,提高销售量,进而提高供应链运行效率。
现有销量预测算法主要分为时间序列预测算法和机器学习预测算法。时间序列方法采取自回归的方式(Auto-Regression,AR),用历史上因变量y的取值预测y。Box& Jenkins在1970年提出ARIMA模型,其中ARIMA(p,d,g)稱为差分自回归移动平均模型,P为自回归项,g为移动平均项数,d为时间序列平稳时所做的差分次数。ARIMA用差分将非平稳时间序列转化为平稳的时间序列,再进行滑动平均。另一种通用的时间序列方法是指数平滑方法(Exponential Smoothing),Peter Winters & Charles holt在1960年提出其中3次指数平滑方法(Triple ExponentialSmoothing),也称为Holt-winters模型,Holt-winters季节模型在每个周期中采用水平、趋势及季节3个权重更新分量,可同时修正时间序列的季节性和倾向性,并能将随机波动的影响适当过滤掉,适于趋势性和季节性的时间序列。Taylor在2017年提出Prophet模型,采用广义加法模型拟合平滑和预测函数。模型整体由3部分组成:增长趋势、季节性趋势、节假日,并且加人了噪声扰动项,提升了模型的鲁棒性,达到了时序模型的最好性能。机器学习模型预测算法主要有线性回归、SVM、决策树模型以及深度学习模型。线性回归指利用线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。Vapnik在1998年提出SVM(support Vec-tor Machine),其基本思想是用少数支持向量代表整个样本集,通过核函数将输入空间的数据映射到更高维特征空间,然后在新的空间内按照结构风险最小化原则构造一个最优分割面,对于有异常值、数据量小、维度高的数据集有很好效果。决策树模型由于单棵决策树性能限制,大多采用集成学习方法,分Bagging和boosting两类。其中,Bag-ging的代表作是随机森林,由Leo Breiman提出,它通过自助法(Bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,结果按投票法而定,在计算速度和分布式计算方面有很大优势。Boosting的代表作是梯度提升树,是由FRIEDMAN于2001年提出的一种改进算法。它是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论加起来作为最终答案。与随机森林不同的是,每次建立模型是在之前建立模型损失函数的梯度下降方向,改进了传统Boosting对正确和错误样本进行加权的方法。深度学习模型善于提取时间和空间类的复杂特征;RNN(Recurrent Neural Net-work)对于时序数据可以自动提取时间维度的特征。Schmidhuber在1997年提出LSTM(Long Short-TermMemory),引入输入门、输出门和遗忘门的概念,解决了RNN梯度消失的问题,是目前处理时序数据性能最好的深度学习模型。Kyunghyun在2014年提出GRU(Gated Re-current Unites),将LSTM输人门、输出门和遗忘门缩减为两个门:更新门和重置门,减少了模型参数,对于小数据集有更好的表现。
2预测模型
GBDT是一个梯度提升模型,使用基于机器学习算法的决策树,该算法是对随机森林的进一步改进,在模型的树模型中包含了分类树和回归树。决策树常用来处理分类问题,在商品销量预测中可以对商品离散型特征进行有效处理和预测;回归树常用来处理预测问题,对商品的时间等连续性特性更加敏感。GBDT采用梯度提升方式,将分类数和回归树进行有效叠加,该算法应用于商品销量预测中,可以有效地将商品的基本属性,如类别、周期性指数等离散特征与按时间滑动窗口获取的连续销量的连续特征有效结合,使商品销量预测的多方面特征得到更综合的利用。
分位数回归是基于被解释变量的条件分布拟合解释变量的回归模型。传统回归方法研究自变量与因变量条件期望之间的关系,而分位数回归是通过估计被解释变量取不同分位数时,对特定分布的数据进行估计,可以进一步推论因变量的条件概率分布。梯度提升树(GradientBoosting Tree)算法是用训练样本集产生多棵弱回归树集成形成强回归树的集成学习方法,在基于表格类数据的机器学习任务方面显示出最好效果。
最近几年,3种高效的GBRT实现方式被提出:XG-Boost、LightGBM和CatBoost。这3种模型在工业界、学术界和数据科学竞赛中被广泛采用。本文应用XGBoost、LightGBM和CatBoost 3种GBRT算法分别建立分位数回归模型,根据模型评价指标对其进行对比研究。
2.1XGBoost
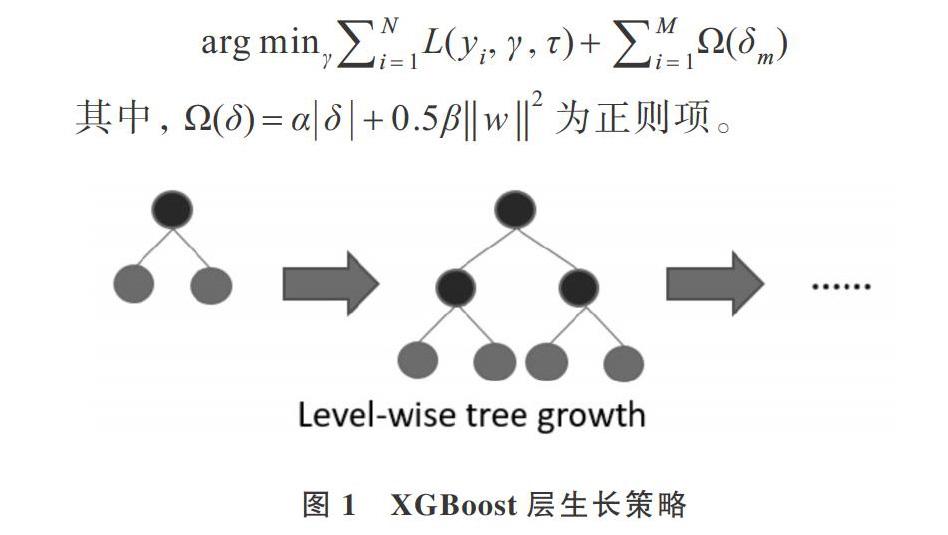
XGBoost(Extreme Gradient Boosting)对损失函数进行泰勒公式二阶展开,在损失函数后面增加正则项,用于约束损失函数下降和模型整体复杂度,并且在计算叶子节点基尼指数时采取并行计算方式模型,能自动利用CPU进行多线程并行计算,是GBRT基础上的一种优化算法。XG-Boost层生长策略如图l所示。XGBoost的目标函数为:
2.2LightGBM
Light Gradient Boosting Decisition Tree(LightGBM)由Guolin于2017年提出,与普通的GBRT模型有如下两点区别:
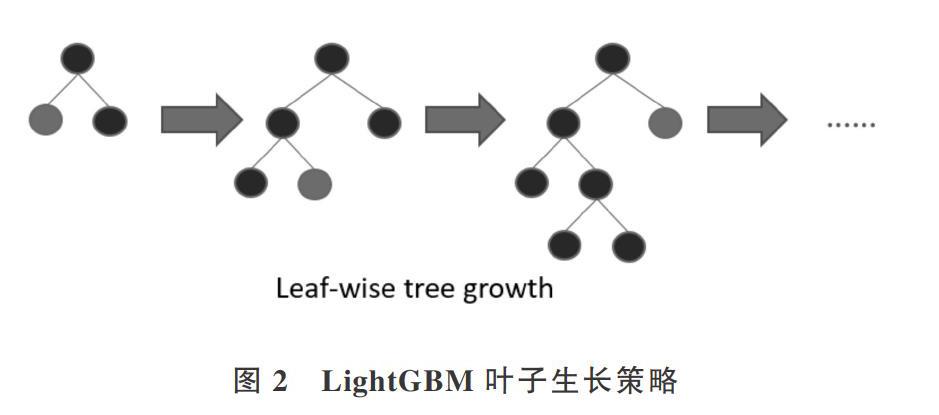
(1)带深度限制的Leaf-wise叶子生长策略。相比于普通GBDT工具使用按层生长(Level-wise)的决策树生长策略,具有控制模型复杂度、降低过拟合的效果。LightG-BM叶子生长策略如图2所示。
(2)直方图算法。其基本思想是先将连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,遍历寻找最优分割点,降低了内存消耗和时间复杂度。
2.3Catboost
2017年,由Yandex公司推出的CatBoost算法是一种擅长处理类别特征(categorical Features)的梯度提升(GBRT)算法。CatBoost运用一种有效方式将类别特征转化成数值型数据并且防止过拟合:OneHotMaxSize(OHMS)。CatBoost在执行随机排列后能有效处理类别特征,通过使用多个排列训练不同模型防止过度拟合,进而获得对梯度的无偏估计,以减轻梯度估计偏差的影响,提高模型鲁棒性。主要通过以下3步完成:
(1)将初始数据进行随机排列,产生多个随机排列。
(2)将具有浮点或类别的标签值转换为整数。
(3)通过式(4)将分类变量转换成数值型变量。其中,CountInClass是具有当前分类特征值的对象标签为1出现的次数,totalCount是具有与当前值匹配的分类特征值的对象总数,Prior是分子的初始值。
2.4性能比较
各机器学习算法性能比较如表l所示。
3实验结果
利用某零售业供应商19家门店2015年1月-2019年5月牛奶的历史销量数据,训练数据集达百万以上,通过GBRT树模型分位数回归算法预测2019年6月1日-14日的销量。其中50分位数的MAPE误差为:
4CPRF库存补货方法
4.1經典库存管理模型
在周期盘点策略中,库存每盘点之后随即发生一次订货,使得现有库存水平加上补货量达到目标最大库存,假设为OUL,盘点周期等于连续两次订货的时间间隔T,并假设已知如下参数:D=每个时期的平均需求;σp=每个时期需求的标准差;L=平均提前期;T=盘点间隔期;CSL=期望周期服务水平。
为确定所需安全库存,跟踪店面经理每次发出订单后随时间顺序发生的各时间点。店面经理在时点0下达第一个订单,订货批量和现有库存之和达到目标最大库存,订单一旦发出,经过提前期L补充订货将送达。下一次盘点库存的时间为T,这时,店面经理下达第二个订单,订货在T+L时送达。目标最大库存水平表示满足时点0到达时点T+L期间需求的库存,如果在0到T+L的间隔期内,需求超过目标最大库存,仓库将出现缺货。因此,在经典周期盘点策略中,必须确定一个目标最大库存水平使得等式成立。
4.2基于GBRT树分位数回归补货模型
在经典库存管理模型中,需求数据必须满足正态分布的假设前提,而实际零售业的需求分布并不能很好地满足正态分布。本文提出一种基于分位数回归预测的补货模型,假设分位数为Cr,则目标最大库存为:
5仿真分析
为了验证分位数模型对CPRF补货方法的有效性,使用与预测算法相同供应商19家门店牛奶2018年7月-2019年4月的真实销量数据,每天门店销售约千种sku,特征维度上百维,对其进行仿真分析。
由图4可看出,使用分位数模型的平均库存要低于经典模型下的平均库存。为了进一步验证模型的有效性,对不同模型下的库存覆盖天数和服务满足率进行分析。由图5可以看出,使用分位数模型的覆盖天数小于经典模型下的覆盖天数;由图6可以看出,使用分位数模型的服务满足率大大高于经典模型下的服务满足率。仿真结果表明,使用分位数模型效果优于经典模型下补货模型。
6结语
本文对CPFR预测补货方法进行了改进,将GBRT树模型引入分位数回归预测算法中,分别比较了GBRT的主要3种实现方式:XGBoost、LightGBM、CatBoost 3种算法,结果显示LightGBM算法效果最好。对50%分位数进行了测试,计算MAPE值,结果表明效果较好。将分位数回归预测与补货模型相结合,将98%分位数作为补货模型的输入,并引入新的安全库存计算方法,对零售业的19家门店作仿真测试分析。结果表明,在满足98%的服务水平下,其平均库存、平均覆盖天数和服务满足率均优于经典库存管理模型。分析仿真结果可知,仍有几个门店存在异常值,其结果不甚理想。对于CPRF方法,如何将预测与补货更好地相结合仍值得研究。未来研究中可以设计精度更高的预测算法,并对鲁棒性更好的补货模型加以优化,以完善供应链的CPRF方法。
猜你喜欢
四川劳动保障(2021年8期)2021-12-02
活力(2019年19期)2020-01-06
中国粮食经济(2018年11期)2018-12-27
——HeightsTM用高效率和智能化提升服务水平
数字通信世界(2017年3期)2017-03-29
中国房地产业(2016年7期)2016-09-24
中国老区建设(2016年5期)2016-02-28
河南科技(2014年23期)2014-02-27
