
非确定、不保真、复杂资源环境的正反双向动态平衡搜索服务
2019-01-24 09:30段玉聪邵礼旭曹步清周长兵唐朝胜宋正阳
小型微型计算机系统 2019年1期
段玉聪,邵礼旭,曹步清,周长兵,唐朝胜,宋正阳
1(海南大学 信息科学与技术学院, 南海资源利用海洋国家重点实验室,海口 570228)2(湖南科技大学 计算机科学与工程学院, 湖南 湘潭 411201)3 (中国地质大学 信息工程学院, 北京 100083)
1 引 言
网络上资源存在时效性,在为特定用户搜索答案时以前的资源在当下可能失效或者不适用.同时,资源的来源也是衡量资源可信度的一个指标,存在个人或机构为了自身利益传播倾向于自身利益的虚假信息,正确的答案便会因为虚假信息的相对高频度出现而被淹没.知识图谱是一种用于存储直接容纳丰富语义的非结构化和结构化信息的知识库.知识库包含一组概念,实例和关系[1].基于对现有知识图谱概念的拓展,[2,3]将知识图谱扩展为包括数据图谱、信息图谱和知识图谱等三个层面的解决框架.Chaim[13]阐述了定义数据,信息和知识等概念.
在[4]中,作者提出通过构建数据图谱,信息图谱和知识图谱的架构来回答5W问题[14].Sen[5]采用主题模型作为相似度计算的依据,消除不可见文本的引用.Malin等[6]提出利用随机漫步模型对演员合作网络数据进行实体消歧,并取得了比基于文本相似度模型更好的消歧效果.Wu等[7]选择维基百科作为数据源,通过自动抽取生成训练语料,用于训练实体属性标注模型.对于关系抽取,出现了大量基于特征向量或核函数[8]的监督学习方法、半监督学习方法[9]和弱监督学习方法[10].Banko等[11]提出了面向开放域的信息抽取方法框架,并发布了基于自监督学习方式的开放信息抽取原型系统.郭剑毅等[12]采用支持向量机算法实现了人物属性抽取与关系预测模型.本文通过引入知识图谱对资源进行组织,在用户进行递进搜索遍历处理资源框架时准确推荐相应的资源,并将此搜索策略应用于医疗资源处理系统中,为医疗工作者提供高效高准确度医疗数据检索服务.
2 数据、信息和知识图谱处理架构
本文提出基于数据图谱(DGDIK)、信息图谱(IGDIK)和知识图谱(KGDIK)三层架构对资源进行建模,对数据图谱上资源进行去冗处理,集成相关资源得到信息图谱,信息图谱允许资源缺失现象存在,在知识图谱上通过关系推理可以构建出新的实体或关系,挖掘隐式存在的资源,增加图谱的点密度和边密度.经过数据的采集和清洗、信息集成、知识描述和推理,最终构建出资源处理架构.图1 给出了基于数据图谱、信息图谱和知识图谱的资源处理框架.
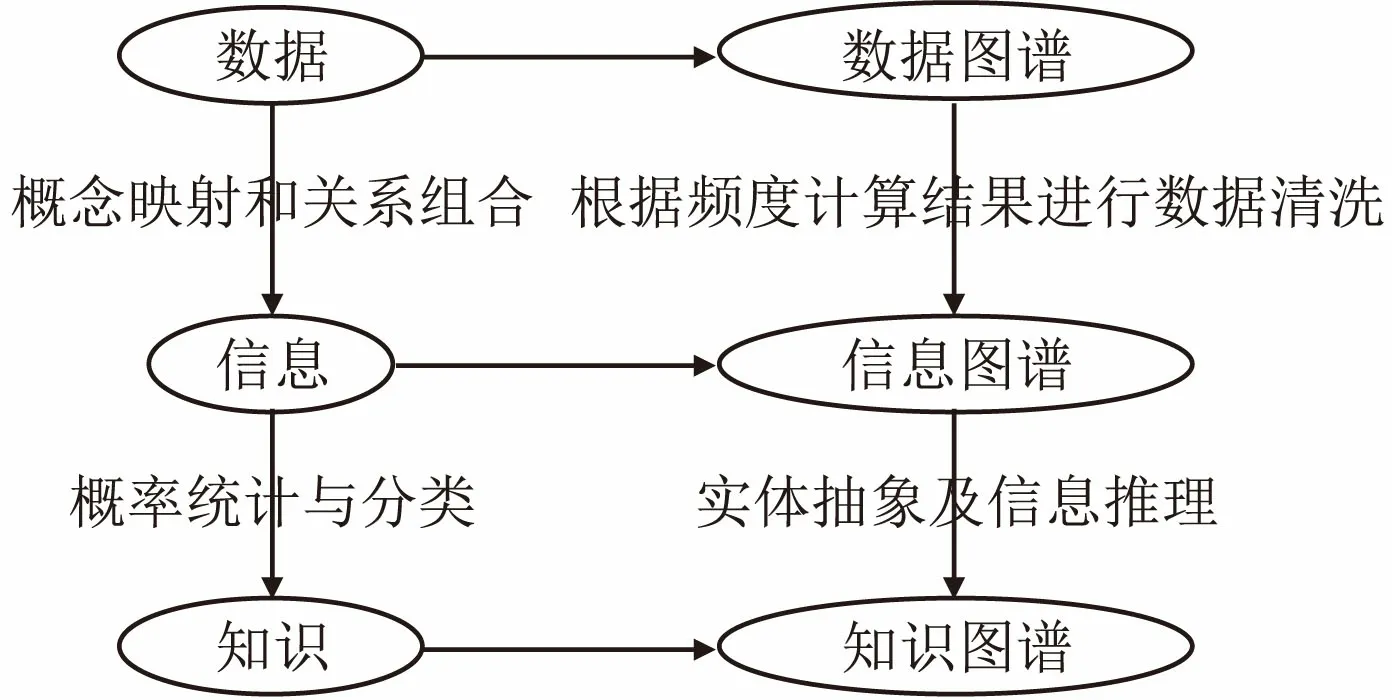
图1 基于数据图谱、信息图谱和知识图谱的资源处理框架Fig.1 Processing framework of data, information and knowledge graphs
2.1 数据图谱
数据是通过观察获得的数字或其他类型信息的基本个体项目,但是在没有上下文语境的情况下,它们本身没有意义.数据图谱可以通过数组、链表、队列、树、栈、图等数据结构来表达.在数据图谱上,通过计算数据的频度,得出数据在数据图谱上的支持度和置信度来删除错误或无用数据,删除的条件是必须同时满足支持度和置信度的阈值要求,阈值过大不利于图谱表达的准确性,过小会不利于表达的完整性,可以根据计算图谱反馈的结果信息动态调整.数据图谱能记录关键词出现的频度,包括结构、时间和空间三个层次的频度.但数据图谱上未对数据的准确性进行分析,可能出现不同名称的数据但表示同一含义,即数据冗余.综上,数据图谱只能对数据进行静态分析,无法分析和预测数据的动态变化.结构频度、空间频度和时间频度的定义如下:
· 结构频度:表示数据出现在不同数据结构中的次数.数据的结构频度应根据数据出现的最大数据结构进行计算.例如,如果在图形结构的分支中以树结构出现的数据,将按图结构来计算数据的结构频度为1,不重复计算数据在树结构中出现的频度;
·空间频度:本文将空间频率定义为在不同空间位置出现的数据时间,描述多个对象的相对位置.利用空间频率来识别物体之间的空间关系,一旦它们被下层识别并用边界框标记;
·时间频度:本文将时间频率定义为在不同时间段内数据出现的次数.初始获取到的数据集合可能不完整,对于具有时间性的流式数据,一旦观察到这些数据,应该及时做出响应,因为过期的数据是无意义的.
2.2 信息图谱
信息是通过数据和数据经过组合之后的上下文传达的,经过概念映射和相关关系连接之后的适合分析和解释的信息.信息图谱上的频度指的是实体与实体之间的交互的频度,信息图谱可以表达实体之间的交互关系,根据数据图谱上记录的数据频度和信息图谱上记录的交互频度计算多个交互实体的综合频度,筛选综合频度低于阈值的结点,并把交互频度高的实体进行集成从而提高模块的内聚性.在信息图谱上可以进行数据清洗,消除冗余数据,根据实体之间的交互度进行初步抽象,提高设计的内聚性,降低耦合度.通过圈定特定数量的实体,计算内部交互度和外部交互度,内聚性等于内部交互度和外部交互度的比值,设定所圈定的实体之间必须是相互连通的.
2.3 知识图谱
知识是从积累的信息中获得的总体理解和意识,将信息进行进一步的抽象和归类可以形成知识.知识图谱可以通过包含结点和结点之间关系的有向图来表达.知识图谱可以表达各种语义关系,在知识图谱上通过信息推理和实体链接提高知识图谱的边密度和结点密度,知识图谱的无结构特性使得其自身可以无缝链接.信息推理需要有相关关系规则的支持,这些规则可以由人手动构建,但往往耗时费力.使用路径排序算法将每个不同的关系路径作为一维特征,通过在知识图谱中构建大量的关系路径来构建关系分类的特征向量和关系分类器来提取关系,关系的正确度超过某一阈值后认为新关系成立.关系的正确度Cr可以通过以下公式衡量,Q表示实体E1到实体E2的所有关系,π表示一类关系,θ(π)表示关系的权重,可由训练得出,最后正确度超过某一阈值后认为该关系成立:
(1)
3 正反双向动态平衡搜索服务
3.1 正反向搜索投入分配
根据用户对实际问题的描述,获取用户的搜索需求,而用户的搜索需求在某个层面上完全能转换成正反两个倾向,例如,用户在专利申请时的需求:"联系人变更要不要收费?",正面倾向为:联系人便变更要收费,反面倾向为:联系人变更不收费.根据用户的搜索需求进行主动建模,统计正向资源和反向资源在资源总数所占的比重,正反资源权重计算公式如下:
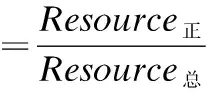
(2)
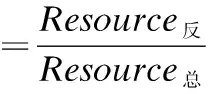
(3)
其中Resource正表示正向资源数,Resource反表示反向资源数,Resource总表示资源总数.
用户投入的预等待时间(T)已知,建立用户投入模型.本文设定每次搜索的项数和每项要搜索的时间是固定的.根据公式(4),利用用户给出的预等待时间计算正反双向递进搜索的次数.
T=S_times*S_items*Pert_item
(4)
其中,S_times表示预等待时间决定搜索的次数,S_items表示每次搜索的项数,Pert_item表示每项要搜索的时间.
3.2 正反双向动态平衡递进搜索服务
对于用户提出的问题,按照正向和反向倾向进行双向搜索,遍历处理资源架构,寻找相关资源.根据得到的资源按照资源中的关键词进行关联因素递进搜索,并计算得到信息的熵值,熵值范围是0到1,熵值越大,信息倾向越分散,可信度越低.
(5)
资源是有时效性的,entropyT是按照某一关联因素进行递进搜索时,在Tk时间下得到的资源的熵值,pi是每类答案出现的概率,Entropy表示按照某一关联因素进行递进搜索时,在不同时效下得到资源的加权平均熵值.
(6)
(7)
每递进搜索一次,根据得到的递进搜索项的熵,计算资源可信度(Confidence):
(8)
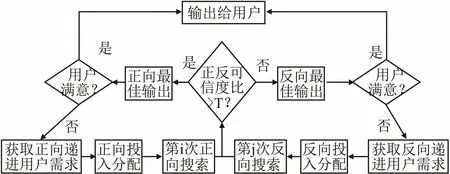
图2 正反向不同投入动态平衡的有限次数递进搜索策略Fig.2 Incremental search strategy of investment driven balanced search
根据得到的资源的可信度,判断正反双向资源可信度的比值是否大于阈值T或小于1/T,该阈值可根据学习算法得到.若满足阈值条件,返回可信度高的搜索结果给用户;否则返回进一步分配投入继续递进搜索.图2给出了正反向不同投入动态平衡的有限次数递进搜索策略.
4 正反双向动态平衡搜索策略流程
图3展示了基于数据图谱、信息图谱和知识图谱的正反双向动态平衡搜索策略具体流程.首先根据已有资源体系建立处理资源框架,获取用户搜索需求.统计正向资源和反向资源在资源总数所占的比重(weight).根据问题所占权重确定投入分配比例,并确定正反向递进搜索次数.
其次,对于用户提出的问题,按照正向和反向倾向进行双向搜索.并对得到的资源进行关联因素递进搜索,计算得到各类资源的熵值.并计算各类资源的时效性,之后在不同时效下得到资源的加权平均熵值.每递进搜索一次,计算资源可信度.最后判断与可信度法阈值的大小关系,推荐给用户高可信度且可信度大于阈值的答案.
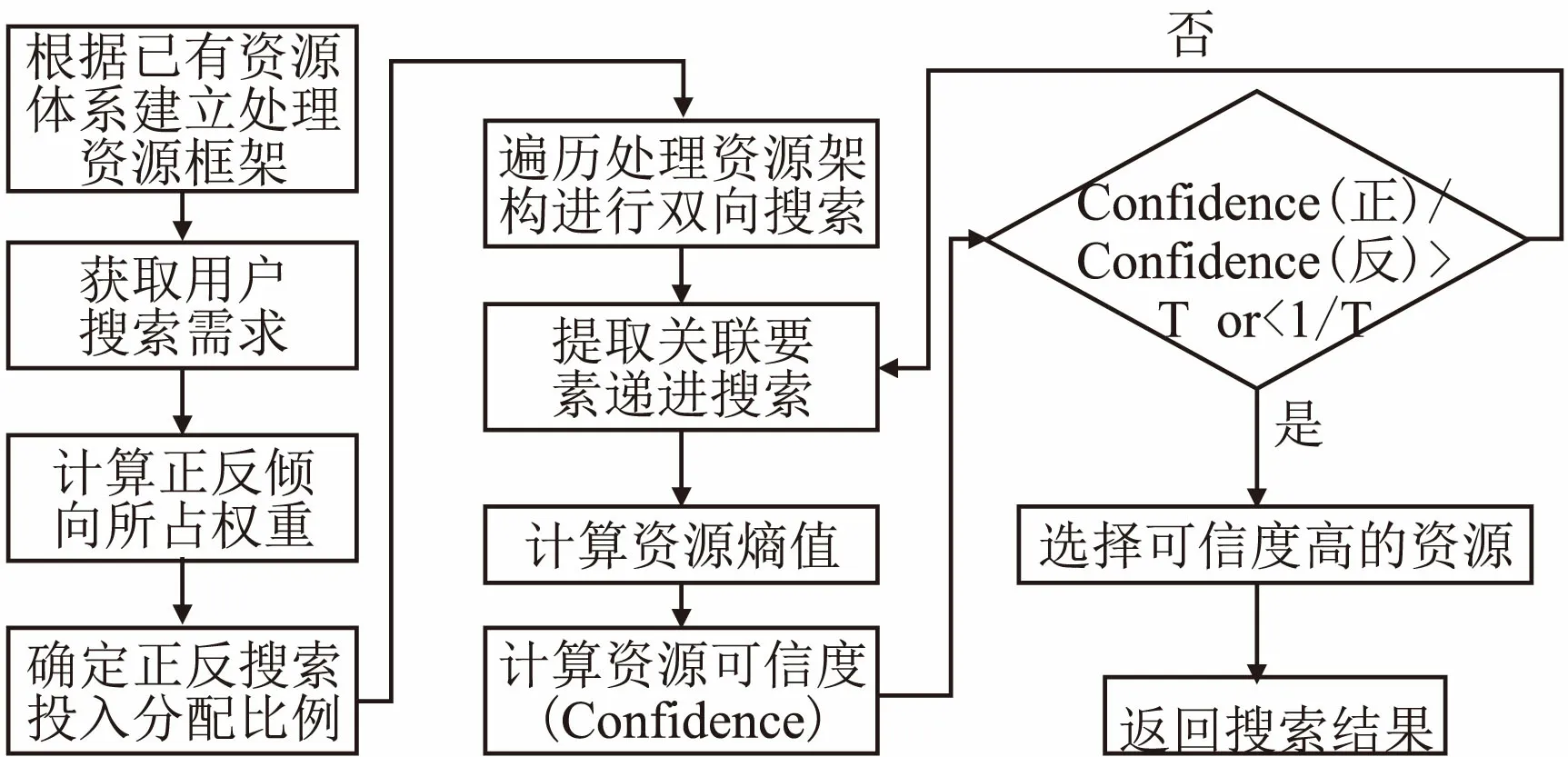
图3 正反双向动态平衡搜索策略流程Fig.3 Bidirectional dynamic search process
5 正反双向动态平衡搜索服务的应用
5.1 应用背景
目前医疗数据有海量性、多态性、微观性、隐私性、追踪性、全面性、冗余性等特征.大量的医疗数据来源复杂,这些数据在存储和搜索推荐时效率低下,且推荐准确度低.本文提出的搜索策略可应用于医疗资源处理系统,并以肝癌患者的治疗方式搜索需求为例说明该策略的可行性.
5.2 正反双向动态平衡搜索服务示例
本文通过抽取部分互联网资源并进行统计,根据资源分布情况对正反向搜索进行投入分配,根据关键词"肝癌患者 治疗方式 化疗 可行?"搜索时获得425,000条结果,有106250条数据表现为正向倾向,有246500条数据显示为反向倾向.假定用户的预投入时间为120分钟,单次递进搜索投入固定为每次递进搜索的答案项数(20项)和每项的投入时间(0.5分钟)的乘积为10分钟.得到资源后在正反向分别进行递进搜索,以正向递进搜索为例,当进行第一次正向递进搜索时,用户正向递进搜索需求是:"肝癌患者 化疗 治疗金额?",得到相应资源归类并统计第一次正向搜索相关资源.资源具有时效性,计算相应正向资源的时效性,结果如表1所示.
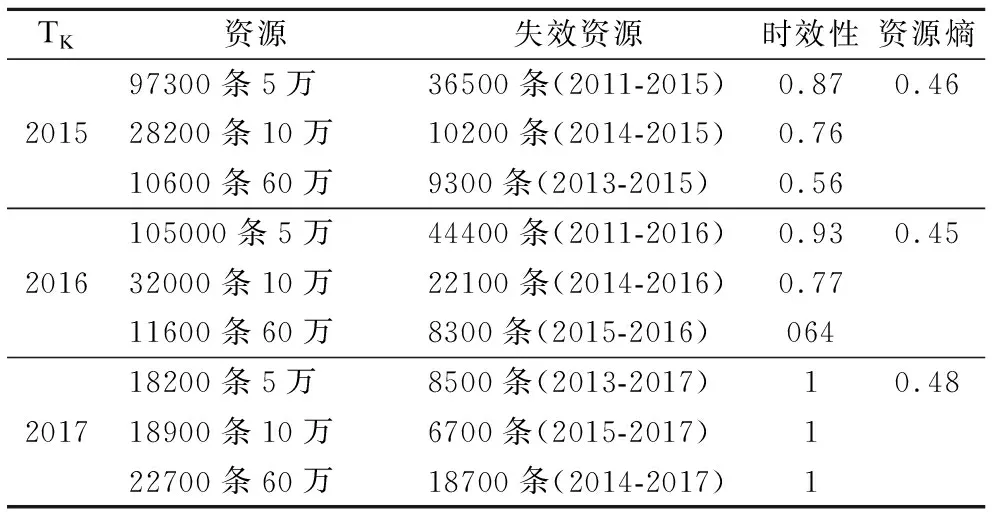
表1 不同时间下资源熵及时效性计算
计算三类正向结果的平均熵,第一次正向递进搜索时,递进搜索次数(S_amount)是1,三种搜索结果的递进搜索的条目总数(Item_amount)分别为231000、97800、84700.利用公式(7)计算可信度.结果如表2所示.
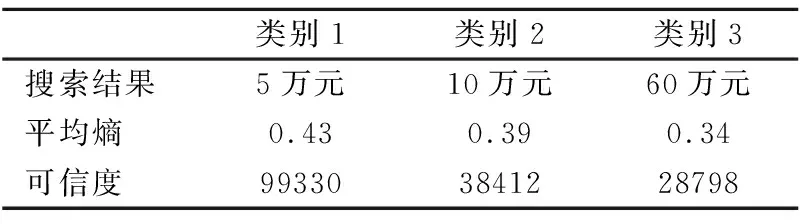
表2 三类正向结果的平均熵和可信度计算
对计算得到的可信度进行排序,推荐可信度高的答案给用户,即付费5万元.本文设定可信度阈值T=100000,正向答案的最高可信度搜索结果为99330,小于可信度阈值T,因此,返回继续投入进行下一次递进搜索,进行到第三次时正向搜索结束.图4给出了正向递进搜索资源各项指标计算.反应第一次正向搜索时,各项指标对推荐正确答案的影响程度.反向递进搜索同样如此,反向递进搜索7次,输出结果可信度大于阈值即推荐给用户.
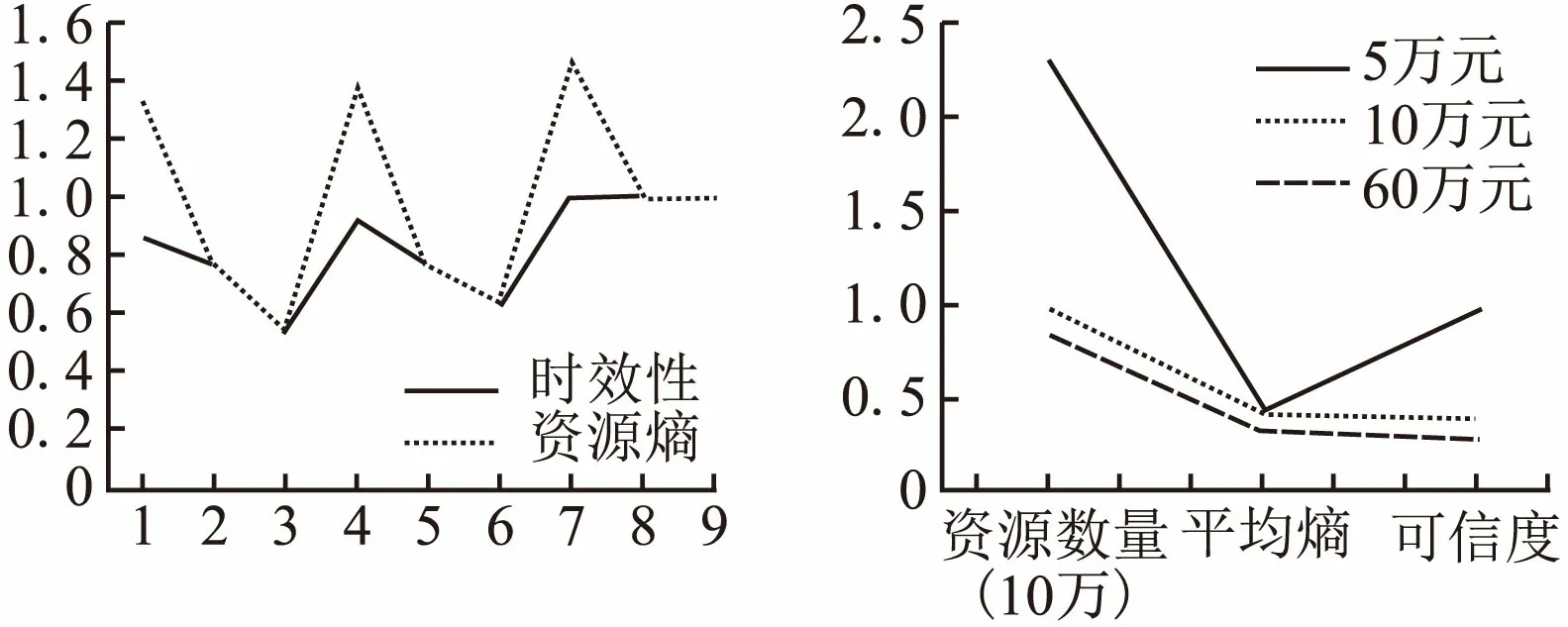
图4 正向递进搜索资源各项指标计算Fig.4 Calculation on the indicators of incremental search
6 相关工作
Mccarthy等[15]使用决策树来学习如何在商业合资企业领域分类不同短语的系统,解决共指消解问题.本体(特别是OWL中表达的形式本体)被用作语义网中的知识表示的标准形式[16],微软发布的Probase利用统计机器学习算法抽取出概念之间的"IsA"关系,以数据驱动的方法构建本体[17].对于复杂的实体关系,借助TBox和ABox将基于描述逻辑的推理归结为一致性检验问题,简化并实现关系推理[18].杨志等[19]利用动态规划的思想提出了一种基于本体的服务推荐方法,在这种方法中,隶属度作为衡量指标在服务推荐结果中区分相关度高低的服务.彭建伟[20]中提出了一种改进的Memetic算法以及一种基于Memetic算法的个性化学习路径推荐策略.Fader等[21]提出一张开放问答(OQA)方法,从未标记的问题语料库和多个知识库中挖掘数百万个规则来解决问题解析和查询重构等问题.Wang等[22]提出一种通过概念注释来促进跨语言知识链接的方法,丰富跨语言知识的链接.Fu等[23]提出了一种语义导向的跨语言本体映射(SOCOM)框架,以增强涉及多语言知识库的基于本体的系统的互操作性.王泊学[24]设计并实现了一种基于上下文感知的自适应服务组合系统,将原本由服务提供者处理的上下文环境转移到服务组合系统中.[25]提出了一种协同过滤方法,用于预测Web服务的QoS值,并通过利用用户的过去使用体验来优化Web服务推荐.
7 结 论
面对非确定、不保真、超复杂资源环境,本文通过引入数据图谱、信息图谱和知识图谱三层架构,提出了一种正反双向动态平衡搜索策略,在面对检索出的高时效性且超复杂的非确定不保真资源时,按照资源正反倾向进行递进搜索,同时在执行策略时建立了模糊词汇表,过滤掉倾向不明确的无用资源,通过对问题进行有限次数的递进搜索,避免面对无穷尽超复杂性问题时搜索陷入死循环的情况,通过每次搜索的条目数以及每项条目对应资源的熵值计算该倾向资源的可靠性,虚假信息以及失效信息会随着递进搜索的次数被排除,提高了搜索资源的质量.同时,本文应对当前医疗数据的高时效性以及复杂资源环境,将此搜索策略应用于医疗资源处理系统中,为医疗工作者提供高效高准确度医疗数据检索服务.
猜你喜欢
出版人(2022年11期)2022-11-15
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年19期)2021-11-27
——入侵植物响应人为扰动的适应性进化方向探究
发明与创新(2021年2期)2021-01-19
人大建设(2018年7期)2018-09-19
中学物理·高中(2017年12期)2018-03-07
理科考试研究·高中(2017年7期)2017-11-04
新高考·高一物理(2016年11期)2017-07-07
妇女之友(2017年3期)2017-04-20
新课程·中旬(2016年11期)2017-02-10
