
含代码的IT社区答案质量评价模型
2019-01-24 09:30许能闯高喜龙
小型微型计算机系统 2019年1期
许能闯,袁 健,高喜龙
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
近年来,技术问答社区给广大开发者获取信息提供了新的平台,促进了技术交流、分享和积累.如今,技术问答社区中的信息已经成为开发者学习和工作中的重要参考点,因此从社区大量问答中快速寻找符合用户要求的高质量信息十分重要.比如Stack Overflow作为一个著名的编程技术问答社区网站,集中了许多的问答数据集.但是,丰富的答案集中答案质量良莠不齐,如何快速识别出对提问用户有用的最佳答案[1],如何让开发者能迅速从众多答案中挑选出参考价值较高的答案内容,是问答社区发展急需解决的问题.若能定量地对各种答案进行质量评价并按质量从高到低对答案进行排序,将大大节省用户寻找高准确率答案的时间.
Stack Overflow这类编程技术问答社区,其问题较专业化,问题和答案有别于一般的问答社区.问题和答案除了文本外,还有大量的编程代码,对IT技术网站来说,代码语义描述的信息更加详细,更符合用户所需答案的配对.以往的研究通常是致力于文本语义的理解,有对普通社区问答的质量评价研究[2],但没有针对Stack Overflow这类含代码的IT社区问答的质量评价研究.文本语义和代码语义是完全不同的,故对其的理解也不同.因此,IT技术问答社区中的问题答案既需要对文本语义的理解,也需要对编程代码进行语义的理解.以往的答案质量评价都没引入代码特征,若能找到一种含代码特征的质量评价模型,将能提高IT技术网站的答案质量评价水平,提升辨析答案的准确率.通过分析IT技术问答的特点以及对文本和代码的语义相似度的研究,本文提出了一种含代码的IT社区答案质量评价模型(Code-based IT Community Answer Quality Evaluation Model,简称CICAQEM),该模型收集社区中带有源码问题答案对,分析问题中文本、代码和答案中文本、代码的语义相似程度,同时引入对作者的答案代码质量评价,再用最大熵模型进行量化计算得分,通过评分实现对答案的量化质量评价.
2 相关工作
对IT技术问答社区的问题答案对进行分析,发现其问答内容由文本和代码两类组成,对它们应分别用不同的方法进行质量评价.
文本内容的质量评价的核心是文本语义的相似度分析.通常采用主题模型定量分析[3].张成[4]等人提出了一种基于概率潜在语义分析(PLSA)模型的自动答案选择方法.在主题建模思想的基础上,利用社区问答系统中的用户资料,以PLSA模型表达社区问答系统中的用户兴趣分布,依据答案和问题之间的主题匹配度对候选答案进行排序.Ma[5]等人利用PLSA模型对社区问答系统的提问者、回答者和投票者的三种角色进行建模,通过问题和答案的主题相似度,依据降序对答案进行排序.上述的方法均使用了LDA主题模型来挖掘语义,很好地解决了多义词的问题,降低了选择无关答案的概率[2].LDA主题模型是目前公认的较成熟的文本语义相似度分析方法.
代码内容的质量评价的核心是代码语义相似度分析和回答者的答案代码质量评价.
代码语义的理解与文本语义不同,与文本语义相似度分析方法也完全不同.代码语义分两种:代码文本语义和代码结构语义.代码的文本语义与普通文本语义类似,而代码结构语义则完全不同,代码结构语义的分析需要将代码转成中间代码,既要保证最终的目标代码不变,又要方便计算不同代码之间的相似度.通常采用代码相似性检测技术[6]检查代码相似度.代码相似性检测技术的发展主要经过了两个阶段.早期的研究主要基于属性计数的方法,其基本原理是从源代码中抽取各种属性度量元作为相似性评判的依据[7].属性计数方法的优点是与所用的程序设计语言无关,无需分析代码的语法结构,实现较为简单,但是缺点也非常明显,属性计数是一种全局代码度量的模式,不能分析部分程序段相似性检测[6].基于结构度量的方法主要是分析程序的结构信息以及执行流程[8].它是根据程序的内部结构信息来判断两个程序之间是否相似.结构度量技术是代码克隆检测方法的一个子集,包括基于Token的方法、基于抽象语法树(AST)的方法和基于程序依赖图(PDG)的方法等,基于Token的方法[9-12]优点是无需语法分析工具,容易多语言扩展,时空效率好,但是其忽略了程序语法和语义信息,只在词法级别做相似性检测,相似值的参考价值低,在结构度量上已经很少使用;基于抽象语法树的方法[13]优点是考虑了程序语法结构信息,抽象语法树采用的是上下文无关文法,同时抽象语法树作为代码编译期的中间代码,保证了和源代码具有相同的目标代码,与源代码有相同的结构信息,在代码相似性检测上具有良好的检测能力[14],缺点是寻找树相似的匹配算法复杂度高,时空效率低;基于程序依赖图的方法[15-17]综合考虑了程序的语法和语义特征,对相似性检测有很好的检测能力,但是建立程序的依赖关系图代价非常高,对图结构的操作时空效率极低,在相似度计算上子图同构查询属于NP-hard问题,目前该方法较少使用.综合以上分析,本文提出了基于SimHash的代码相似度模型(Code Similarity Model Based on SimHash,简称CSMBSH),既具有抽象语法树方法的优点,又提升了算法效率.
在回答者的答案代码质量评价上,由于不同开发者的喜好不同,编码水平的不同,书写的代码质量参差不齐,因此从开发者书写代码的角度对代码质量进行评估,考虑人为因素对书写代码优异程度的影响,此类方法可以很好地衡量代码的优劣程度.Boehm[18]等人于1976年提出了定量的评价软件质量的概念,孙梦粼等[19,20]通过研究分析和大量实验验证,选取了函数参数、路径数、层次数等16个度量元作为评价软件质量的度量指标.IT技术问答中每个答案集的代码片段跟一个软件相比,规模比较小并且其答案还有广大用户的跟帖评论,因此本文提出了基于度量元的代码质量评价模型(Code Quality Evaluation Model Based on Measurement Element,简称ACQEMBME),该模型引入度量元作为评价指标,并增加用户评论评估来弥补单从回答者方面上考虑的不足,实现了答案代码质量评价.
综上所述,本文提出一种新的答案质量评价模型——含代码的IT社区答案质量评价模型,该模型先从主题的角度筛选出与问题文本相似度较高的答案集,在该答案集下,抽取关键代码特征片段,计算问题中代码和答案中代码的结构相似度,引入基于度量元的代码质量评价,用最大熵模型(Maximum Entropy Model,简称MEM)融合不同类型质量评价模型的结果来进行量化计算,通过评分实现对答案质量的评价.该模型把代码结构作为答案评分的参考点,对软件开发社区问答答案评估和筛选具有重要意义.经实验证明,含代码的IT社区答案质量评价模型更符合IT社区问答的特点,能有效地提高答案质量评估效果.
3 算法模型
3.1 含代码的IT社区答案质量评价模型CICAQEM
含代码的IT社区答案质量评价模型的基本思想是:先选用LDA主题模型筛选与输入问题相似的问题集,再次筛选相似问题集的答案集,形成问题答案集,一个问题对应多个答案,计算答案与问题的文本相似度.在代码方面,对代码进行预处理,使用JDT(Java Development Tools)构建代码的抽象语法树,采用SimHash算法计算树结点的签名,对树结点的签名进行加权、合并、降维生成树的签名,通过海明距离计算签名相似度达到计算代码的结构相似度的目的.同时引入评价代码质量的度量元,对基于度量元计算出来的得分通过权值进行加权合并生成预估评分,根据用户评论的命中数对预估评分进行处理,得到回答者答案代码质量的评价得分.最后使用最大熵模型对答案文本相似度、代码结构相似度、回答者答案代码质量评估值进行融合计算,通过评分实现对答案质量评价的量化.
模型描述如图1所示,共包括三个子模型:1)基于SimHash的代码相似度模型;2)基于度量元的代码质量评价模型;3)最大熵模型.
含代码的IT社区答案质量评价模型描述如下:
Step1.通过用户的提问,使用LDA主题模型过滤掉无关问题,收集对应的问题集、答案集、评论集;
Step2.通过LDA主题模型过滤掉不相关的答案,收集相似度大于阈值的答案集,提取问题集和答案集的代码进入Step 3,选中答案集对应的评论集进入Step 4,统计记录答案文本相似度;
Step3.对代码进行预处理,如后3.2.2中所述方法,构造代码的抽象语法树,计算AST的相似度;
Step4.如后3.3中所述方法提取代码中的度量元,初步计算回答者的代码质量,通过评论集对代码的评价,反馈调整代码质量得分;
Step5.根据Step 2,Step 3,Step 4对应得出的答案文本相似度、AST相似度、代码质量评分,通过如后3.4中所述的最大熵模型来确定每项评价指标所占的权重,给出答案最终评分.
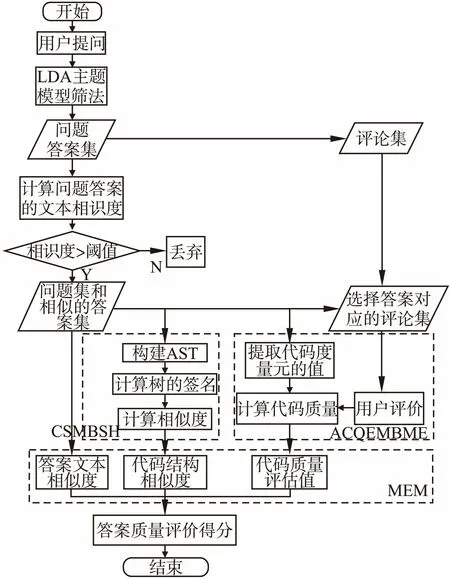
图1 含代码的IT社区答案质量评价模型系统流程图Fig.1 CICAQEM system flow chart
3.2 基于SimHash的代码相似度模型CSMBSH
3.2.1 SimHash算法
在SimHash算法[21]中,产生用于分割空间的随机向量:取第k个特征的hash签名的第i位,若为0,则改为-1,若为1则不变,作为第i个随机向量的第k维值.由于hash签名是f位的,因此产生f个随机向量,对应f个随机超平面.
随机超平面局部敏感哈希算法,算法的主要思想是在高维空间中通过生成随机超平面将此空间分割成两部分[23].给定两个向量,若它们之间的夹角较小则它们会以一个很大的概率落在超平面的同一侧.反之,则它们落在同一侧的概率将会很小.通过降维技术,可将高维的向量用较低维度的签名来表示.所以,用两个向量的签名的不同二进制位的数量,即海明距离,来衡量这两个向量的差异程度.
SimHash基于随机超平面局部敏感哈希算法,该算法将每个结点特征映射成n维向量空间,对于很多的特征来说,它们对应的向量是均匀随机分布的,并且对同一特征来说对应的向量是唯一的[23].将SimHash引入抽象语法树,通过对得到的树结点的向量求和,来表示整棵树,以及计算向量的夹角来表示树的相似度.使用降维,保留向量和的象限信息,由于64位树的签名可以表示264个象限,足够表征一棵树的唯一性,所以海明距离就是两棵树的相似度.
3.2.2 基于SimHash的代码相似度模型CSMBSH
CSMBSH模型描述如图2所示,总共包括三个部分:1)构建抽象语法树(AST);2)计算树的签名;3)计算相似度.
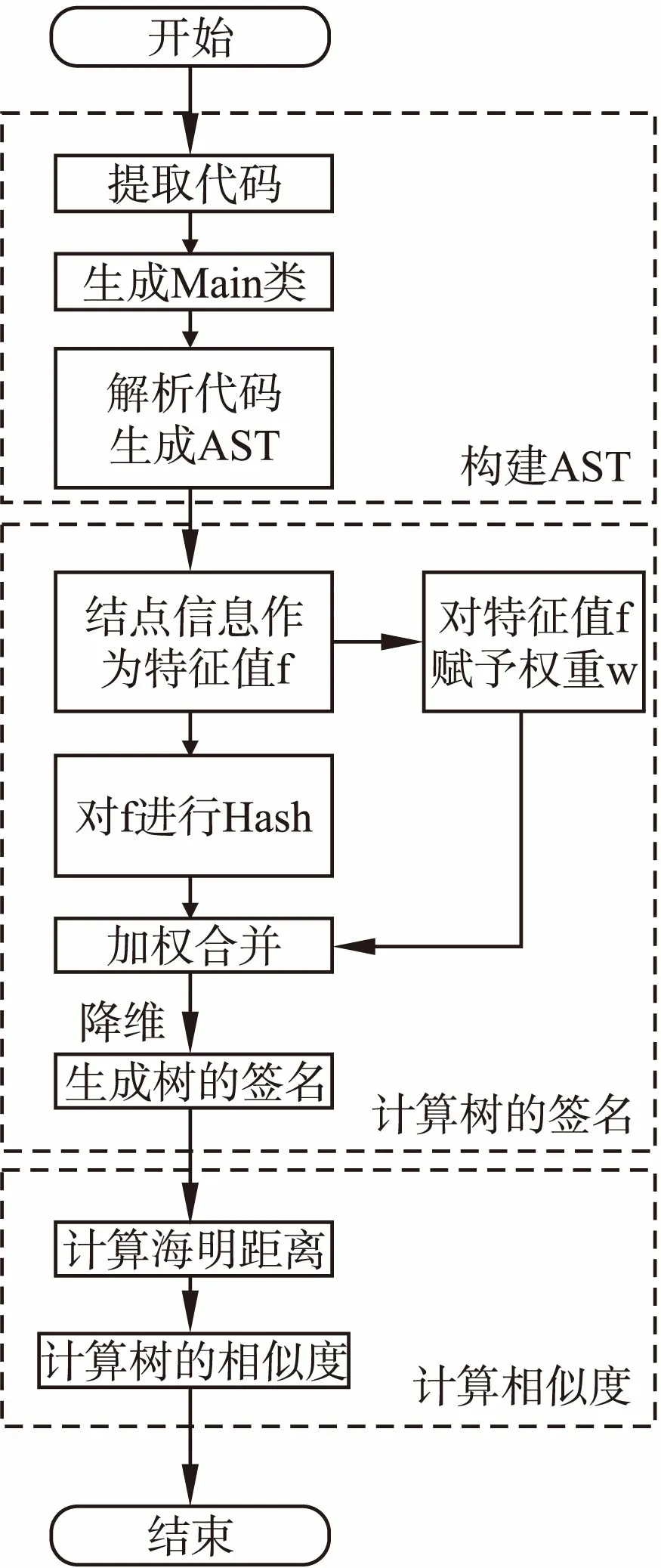
图2 代码相似度模型流程图Fig.2 Code similarity model flow chart
Step1.提取代码.提取问题集和答案集中代码部分,代码部分包含类、方法和代码片段;/*构建AST,以Java为例*/
Step2.生成Main类.创建一个命名为Main的类,将代码中的片段放入main方法中,而代码中的方法作为类文件中的方法排列到Main类文件中,生成如图3所示Main类.
如果代码区域包含类,则该类的属性部分插入到Main类的属性中,命名为:类名_属性名(例如类A中的name属性,则命名为a_name)为一个整体构成一个类文件,该类的方法加入到Main的后续函数中,方法命名为:类名_方法名,最终形成这个Main的类文件;

Step4.结点赋予权值.对每个结点的特征值赋予权重,语句(如IfStatement、WhileStatement等)结点赋予权值w为1;表达式(如Assignment、MethodInvocation)等结点赋予权值为2;TypeDeclaration类(类型声明)、MethodDeclaration类(方法声明)的权值为3;/*计算树的签名*/
Step5.特征值Hash.计算特征值的hash值(生成64位hash值);
Step6.加权合并.
①树单个结点加权过程:计算第i个结点的hash值,每位如果为1,则n维向量hi 的第i位的数值为权值w,如果为0,则这一位数值为-w,形成n维向量hi,hi形如(w1,-w2,w3,…,w63,-w64),结点计算加权的过程称作签名,第i个结点的签名记做hi,hi =(w1,-w2,w3,…,w63,-w64);
②树结点合并过程:树结点的签名等于子结点签名的和加上根结点的签名,即求树的向量和(树的向量和用treeH表示,treeH = 左子树签名 + 右子树签名 + 根结点签名);
Step7.降维.降维过程为将向量和treeH中每位大于0则为1,小于0则为0,降维后的向量用reduTreeHi表示第i个结点为根的子树的签名(H的下标i).我们以根结点的reduTreeH1(H的下标为1)作为整颗树的签名,这样我们就得到了AST的签名(64位hash值);
Step8.海明距离计算.通过海明码计算签名的相似性,海明距离(Hd)计算公式见公式(1),求a按位异或b(记作a XOR b)运算结果中1的个数,q表示问题中的抽象语法树的签名,a表示其中一个答案的抽象语法树的签名,其中sum1(x)是求出x化为64位二进制数1的个数,x为一个整型数;
Hd=sum1(qXORa)
(1)
Step9.计算相似度.把海明距离代入公式(2)计算相似度(Sim).
(2)
3.3 基于度量元的代码质量评价模型ACQEMBME
ACQEMBME模型描述如图4所示,总共包括两个部分:1)计算代码质量预评估值;2)基于用户评价的代码质量评价值.
Step1.选取度量元指标.通过分析Stack Overflow的代码结合孙梦粼等[19]研究选取代码度量指标分别是:函数参数个数、路径数、注释率、语句的平均长度、函数中可执行语句数、圈复杂度;
Step2.收集度量元的值.统计每份代码中的每个度量元的值;
Step3.计算单个度量元下代码的评分.由量化标准的模型[19]选用公式(3)计算g(x),其中x表示函数模块中某个度量元的值,g(x)表示根据度量元的值所计算出来的评分值0≤g(x)≤1,a、b、c、d都是待定参数,具体取值参考文献[19];
g(x)=c(x+d)b-1e-a(x+d)
(3)
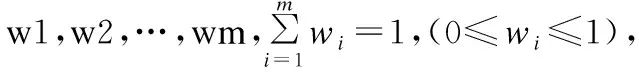
(4)
Step5.计算用户评价的评分.制作优秀的代码评论集的词条,把好评的词条加入到字典词库中,对每条评论集做对词级的切分,每个词的命中则match++,通过公式(5)计算用户评价的评分,matchi为第i个评论词条的命中数,lengthi为第i个评论词条总长度,n为答案对应的评论集大小;
(5)
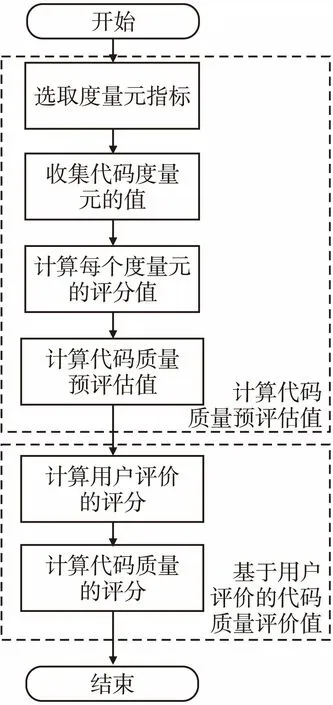
图4 基于度量元的代码质 量评价模型流程图Fig.4 ACQEMBME flow chart
Step6.计算代码质量的评分.通过用户评价代码作为参考点,修正公式(4)的代码质量预估值Qpre,得到最终的代码质量评价值Q,0≤Q≤1,见公式(6),其中φ是常量,0≤φ≤1,通过实验确定系数φ.
Q=(1-φ)*Qpre+φ*As
(6)
3.4 最大熵模型MEM
最大熵模型如图1中MEM子模型图所示,MEM将CICAQEM中的三个评价指标值进行融合.指标一为答案文本相似度s:问题与答案的主题相似度越高,则该答案越有可能是高质量答案;指标二为代码相似度Sim:在文本相似度过滤掉无关答案的前提下,代码的结构越相似,说明描述同一个问题的概率越高;指标三为回答者的代码质量Q:回答者的代码质量越高,说明回答者的工程能力越强,则该答案是最佳答案的概率越大.
MEM的流程描述如下:
Step1.依据文献[3]计算答案文本相似度s;
Step2.根据公式(1)和公式(2)计算代码相似度Sim;
Step3.根据公式(6)计算回答者的代码质量Q.
Step4.计算答案的质量评分.为了确定上述指标的权重,采用最大熵模型[24]确定权重,计算评分,从而得到答案的质量评分.如公式(7)所示:
(7)
R(s,Q,Sim)为归一化因子,计算如公式(8)所示:
(8)
其中s、Q、Sim是3个评价指标.A为文本相似度过滤后的答案集.
4 实验分析
实验选取Stack Overflow中的问答数据,Stack Overflow是IT技术性问答网站,从StackExchange上下载Stack Overflow的数据,问题集和答案集在Posts.xml中,评论集在Comments.xml文件中.抽取2016年10月到2017年9月的数据,提取Tag为Java的记录.筛选出有标签的Post信息,由此得到了实验数据集,包括51782个问题、267630个答案、1037923个评论.实验在Windows7平台(CPU 2.60GHz,内存8G)下的eclipse中运行.
4.1 评价指标
1)NDCG:
采用衡量排序质量的评价指标——NDCG[25](Normalized discounted cumulative gain)来衡量上述模型对答案排序质量.
(9)
其中,DCG(n)为排序结果最好的状态下的DCG(Discounted Cumulative Gain)值的归一化因子,r(i)为排在第i位的答案的得票数.NDCG@n表示测试数据中排在前n位的答案的NDCG(n)的均值,取NDCG@1,NDCG@5,NDCG@10作实验对比.
2)平均最佳答案相似度(Similiarity):
平均最佳答案相似度是先求出每个问题对应答案集中评分最高的答案作为最佳答案,然后根据各自的算法计算问题与最佳答案的相似度值作为最佳答案的相似度.相似度计算见公式(1)和公式(2).最后计算所有问题算出来的最佳答案相似度的平均值就是平均最佳答案相似度.
3)平均算法运行时间(Runtime):
实验中的平均算法运行时间是指在每组数据集(包含多个问题)在当前实验平台下每个问题算出NDCG@1的平均时间.
4.2 实验结果
4.2.1 代码相似度计算实验对比
实验选取基于SimHash的代码相似度模型(CSMBSH)相似度计算和子树的匹配算法[22](Sub Trees Matching,简称STM)相似度计算以及贪婪字符串匹配算法[13](GST:Greedy String Tiling,JPlag系统采用的相似度计算算法)相似度计算进行对比.
实验收集5组问题答案对的数据集进行实验,每组数据的问题集(Question Set)不一样,编号为1,2,3,4,5.问题集中问题个数分别为50,100,150,200,250.实验结果如下:平均最佳答案相似度值的对比数据如表1,对比图如图5,平均算法的运行时间对比数据如表2,对比图如图6所示.
表1 平均最佳答案相似度数据对比表
Table 1 Average best answer similarity data comparison
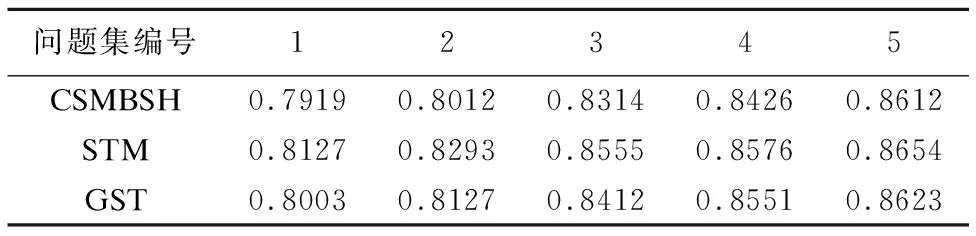
问题集编号12345CSMBSH0.79190.80120.83140.84260.8612STM0.81270.82930.85550.85760.8654GST0.80030.81270.84120.85510.8623
表2 相似度计算算法的平均运行时间对比表
Table 2 Average running time of similarity computing algorithm comparison
Table
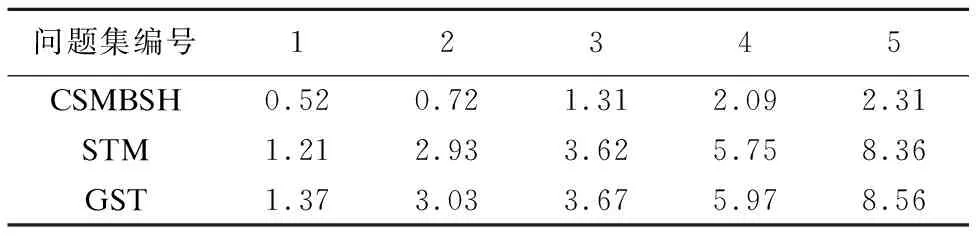
问题集编号12345CSMBSH0.520.721.312.092.31STM1.212.933.625.758.36GST1.373.033.675.978.56
由图5和图6可知子树的匹配算法平均最佳答案相似度、平均算法运行时间指标上优于GST.由图5可知,在不同数据集下,CSMBSH和子树的匹配算法的最佳答案相似度的值误差很小,数值基本相同,表明CSMBSH模型中树的签名可以很好地表现AST的结构特征,并且由图6可知在算法性能上CSMBSH模型计算相似度算法的运行时间远小于子树的匹配算法,说明CSMBSH模型相似度算法很好地解决了子树匹配算法复杂度高,时空效率低的问题.
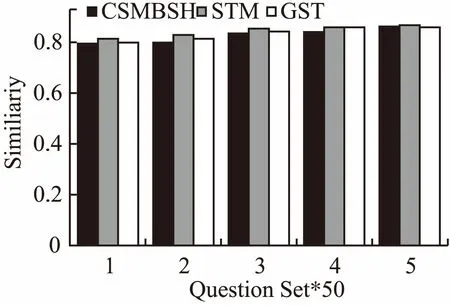
图5 平均最佳答案相似度值的对比图Fig.5 Comparison diagram of the average best answer similarity value

图6 相似度计算算法的平均运行时间对比图Fig.6 Comparison diagram of the average running time of similarity computing algorithm
4.2.2 NDCG的对比实验
以往没有含代码的答案质量评价模型,选取基于LDA的主体模型和基于混合式的社区问答答案质量评价模型[2](Answer Quality Evaluation Model based on Hybrid Method,AQEMHM)作对比实验,实验结果数据见表3,对比图如图7所示.
表3 三种方法的NDCG值比较
Table 3 Comparison of NDCG values of the three methods
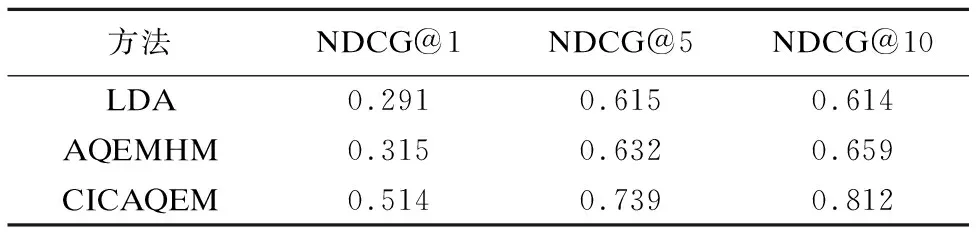
方法NDCG@1NDCG@5NDCG@10LDA0.2910.6150.614AQEMHM0.3150.6320.659CICAQEM0.5140.7390.812
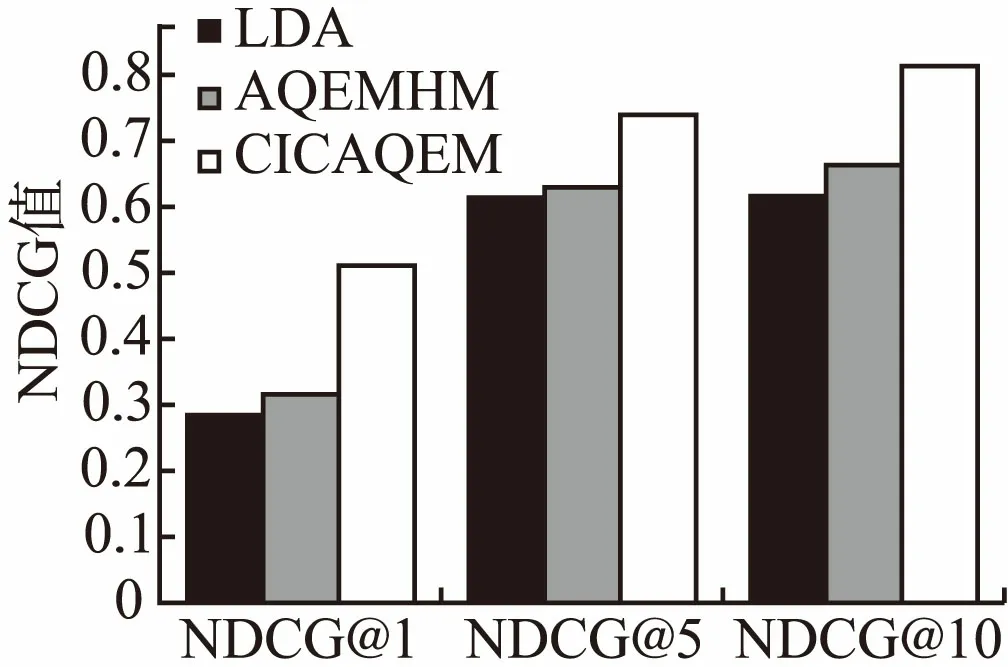
图7 NDCG对比图Fig.7 NDCG comparison diagram
由图7可以看出,含代码的IT社区答案质量评价模型(CICAQEM)比LDA和AQEMHM模型在NDCG指标上表现都好,充分证明引入代码质量评价提高了答案评价的有效性,含代码的IT社区答案质量评价模型更符合IT社区问答的特点,更能有效地提高答案质量评估效果.
5 结束语
文中提出了一个含代码的IT社区答案质量评价模型,从问题答案文本和代码的角度对社区问答系统的答案质量进行评分.实验结果表明,文中的方法可以有效地对混合了文本和代码的答案进行评分,符合人类对参考答案准确度的认知.由于以往没有含代码的答案质量评价,文中的模型结合了文本和代码的分析,使问答社区的答案筛选更精确,并且在计算相似度的运行效率上高于以往的子树匹配算法.未来的工作主要是研究抽象语法树的树形结构,挖掘更多的结构信息、语义信息,改进SimHash的提取过程,从而可以更好地从语义方面对答案质量进行评价.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
长江学术(2016年4期)2016-03-11
股市动态分析(2015年16期)2015-09-10
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
