
DeepTriage:一种基于深度学习的软件缺陷自动分配方法
2019-01-24 09:36宋化志马于涛
小型微型计算机系统 2019年1期
宋化志,马于涛
(武汉大学 计算机学院,武汉 430072)
1 引 言
软件维护的目标不仅是为了修复软件缺陷,更是为了改善软件特性从而提升软件质量.随着软件开发的复杂度越来越高,软件维护也面临着巨大挑战.为了提高软件维护的效率,缺陷跟踪系统BTS(Bug Tracking System)被广泛用于缺陷管理[1,2],如Bugzilla和JIRA.在BTS中,每个缺陷被描述成具有规范格式的缺陷报告,包含缺陷重复出现的描述信息以及缺陷的状态更新信息[3]等,但形式各异且存在大量冗余.开源项目中新的缺陷报告每天不断涌入并累积.例如,Eclipse在2007年平均每天要新增30个缺陷报告[4];从2001年到2010年,接近3万5千名开发者或用户提交了超过33万个缺陷报告[5].使用人工的方法来处理类似大规模的缺陷报告是一项极具挑战性的任务.
缺陷分配是将一个新的缺陷报告分配给一个最合适的开发者并尽快修复的过程[4,6-8].新缺陷报告的分配工作往往是由专家级的开发者来完成的.但是,这种人工分配的方式不仅耗间,而且效率也不高.例如,在人工分配的Eclipse缺陷报告中,有44%的缺陷报告分配错误,而且从一个新的缺陷报告形成到第一次分配给开发者,平均要花费19.3天[4].因此,为了减少人工分配的人力成本和时间成本,Anvik等人[6]较早提出了缺陷自动分配的方法.他们将每个缺陷报告映射为一个文档,将缺陷的修复者映射为这篇文档的标签,从而使用文本分类的技术来预测合适的开发人者.另一方面,从开发者合作关系的角度Jeong等人[4]较早提出了基于投掷图(tossing graph)的方法.他们的实验表明,考虑开发者之间的投掷信息有助于进一步提高预测效果并缩短缺陷报告投掷的路径长度.Bhattacharya等人[9]的工作和后续的相关研究[10,11]也表明,这类综合文本分类和投掷图的混合方法确实能获得更好的预测效果.
目前,深度学习技术已成功应用于图像分类、语音识别、文本翻译等领域,其优势在于通过组合低层特征形成更抽象的高层特征,以发现数据的分布式特征表示.考虑到缺陷报告中文本的多样性和复杂性,本文的基本思路是将缺陷报告映射为一个二维的向量矩阵,利用深度学习算法挖掘隐藏在文本内容中的隐式特征,并完成分类任务.遵循该思路,本文提出了一种基于卷积神经网络CNN(Convolutional Neural Network)的缺陷自动分配方法,其主要贡献如下:
1)针对缺陷报告中的文本信息,经过词向量化(word embedding)处理后,利用CNN对文本特征进行自动提取,然后构造相应的分类器.在Eclipse和Mozilla上的实验结果表明,所提方法在准确率(accuracy)方面优于以往研究中表现最好的支持向量机SVM(Support Vector Machine).
2)使用不同的深度学习算法进行对比实验,发现多层平行的CNN结构在Eclipse和Mozilla两个数据集上都能取得最好的预测效果,是一种有效的人工神经网络结构.
本文余下部分包括:第2节介绍和本文相关的研究工作,第3节介绍相关的背景知识,第4节详细描述实验模型以及实验步骤,第5节分析和讨论实验结果,第6节总结全文并对今后工作进行展望.
2 相关工作
2.1 基于文本分类的缺陷分配
Cubranic等人[12]较早将缺陷分配问题转化为文本分类问题,利用朴素贝叶斯NB(Naive Bayes)算法来预测新的缺陷报告应该分配给谁来解决最为合适.由于仅仅使用了Eclipse缺陷报告的描述(description)和总结(summary)信息,准确率只有30%.Anvik 等人[6,7]扩展了上述工作,使用NB、SVM、C4.5决策树等机器学习算法进行对比,发现SVM的准确率最高.Ahsan等人[13]使用特征选择和隐语义索引LSI(Latent Semantic Indexing)方法来降低文档输入矩阵的维度,然后使用SVM取得了最佳的预测效果,平均精确率(precision)和召回率(recall)分别达到30%和28%.上述方法对文本的处理大多采用词袋模型,但词袋模型往往忽略重要的词序信息.在本文中,我们使用的卷积神经网络(CNN)可以弥补这一不足,即通过设置不同的卷积核大小可以捕捉不同的短语,从而提高文本挖掘的效率.
Xie等人[10]利用斯坦福大学的主题建模工具TXT(Stanford Topic Modeling Toolbox)将缺陷报告按照主题进行分组,然后通过分析开发人员在不同分组的兴趣和经验,为新的缺陷报告推荐一组合适的开发者.实验表明这种方法优于SVM、KNN(k-Nearest Neighbor)等机器学习算法.类似地,Yang等人[14]也使用TMT工具来确定新的缺陷报告的主题,然后利用多特征和社交网络技术来预测合适的开发者.Naguib等人[15]将概率生成主题模型LDA(Latent Dirichlet Allocation)引入缺陷分配中,并提出了相应的排序算法来预测合适的开发者.他们的实验表明,该方法的平均准确率可达到88%.Zhang等人[11]也使用LDA模型来挖掘历史缺陷报告的主题,然后提取具有相同主题的开发人员之间的相互关系,并从中抽取相关特征来对开发者进行排序预测.与文献[10]、文献[15]所提的方法相比,其F-measure值分别提高了3.3%和16.5%.此外,Xuan等人[16]提出了一种半监督学习的文本分类方法——基于期望最大化的NB方法,其结果的准确率比单纯的NB方法提高了6%.上述使用主题模型进行建模的方法也存在一些限制,比如主题数目的设定、主题建模粒度的限定等.与此相对应的是,本文中我们提出的方法没有这样的限制.
2.2 基于深度学习的文本分类
Collobert等人[17]使用卷积过滤器处理连续文本来获取局部特征,并利用最大池化(max-pooling)获取全局特征,在不需要大量先验知识的情况下,在标记系统(tagging system)中取得了良好的效果.Kim 等人[18]使用一种包含多种过滤器和两种词向量通道的单层CNN,在情感分析和问题分类中取得了不错的效果.Kalchbrenner等人[19]提出了基于k-max-pooling机制的动态CNN方法,在情感预测和问题分类任务中比基准方法的错误率下降了25%.进一步地,Lei等人[20]在对单词进行处理时使用基于张量代数的操作来代替标准卷积层中词向量连接的线性运算,以获取非连续词向量的非线性关系,并在标准的情感分析任务中取了当时最好的结果.Zhang等人[21]也提出基于字符的CNN模型,其结果优于传统的词袋(bag of words)模型和基于单词的CNN模型.
Zhou等人[22]综合CNN和递归神经网络RNN(Recurrent Neural Network)各自的优点,提出了C-LSTM分类模型,在情感分类和问题分类任务中,其效果优于单独的CNN和LSTM(Long Short-Term Memory)模型.Johnson等人[23]提出了基于LSTM的区域向量(region embedding)模型,充分利用半监督的神经网络方法和two-view词向量方法的优势,在给定数据集上均取得了当时最好的结果.Miyato等人[24]将对抗和虚拟对抗训练拓展到文本领域,对RNN中的词向量而非原始输入进行扰动,在多个基准的半监督和监督任务中取得了很好的效果.
总的来说,虽然深度学习在文本挖掘和文本分类领域研究势头强劲,但在软件缺陷自动分配领域,还暂时缺少将深度学习技术引入到缺陷自动分配中的工作,相关的技术、方法和实施流程值得深入研究.
3 方法框架
3.1 词向量模型
在自然语言处理中,文本常常被转化为向量,以便计算机进行处理.向量化文本的粒度一般分为字符、单词、短语等,考虑到缺陷报告中文本的实际情况,本文采用的是广泛使用的词向量化.单词粒度的文本向量化方法一般又可以分为两类表示方法:稀疏向量和稠密向量.稀疏向量采用一位有效编码(one-hot)向量形式,即每个向量的维度为整个词汇表的大小,只有单词在相应词汇表位置的数字为1,其余全为0.稠密向量,其向量长度一般为100~600维,远远小于词汇表的大小,但它可以表示词与词之间更丰富的语义相似程度.因此,本文采用的是稠密向量表示方法.
一般来说,要想得到一组好的稠密词向量,不仅需要好的表示模型和参数调试,更需要大量的语料数据.本文使用提前训练好的词向量作为基准向量,即基于Word2Vec[25]的CBoW(Continuous Bag-of-Words)模型在Google News数据集(约1000亿个单词)上训练的词向量模型(下载网址:https://code.google.com/archive/p/word2vec).
3.2 卷积神经网络
一个CNN由两部分组成:卷积和池化.卷积用于捕捉局部特征,不同的卷积核捕捉大小不一的局部特征;池化用于将卷积层捕捉的特征按一定方式提取并加以利用,如求最大值、求均值等.本文CNN模型的设计和构建过程如下:
首先,将每个缺陷报告的英文文本提取出来,经过分词、去停用词、提取词干、词向量化等一系列文本预处理后,得到相对“规范”的文本.
其次,假设一个文本的长度为s,其中每个单词都可使用Word2Vec训练的d维向量表示(或采用随机数进行向量表示),那么该文本可表示为一个s×d维的向量矩阵.与Collobert等人[26]的工作类似,本文使用的卷积核的宽度与表示词向量的维度相同.因为在词向量的所有维度上,每个维度都是相互独立的,只需在行维度进行卷积操作即可.此外,假设卷积核的长度为h,并用其代表卷积的区域大小.
再次,假设使用W来表示区域大小为h的卷积核的权重矩阵,卷积核的参数量为h×d.这里,缺陷报告文本的向量矩阵记为A∈s×d(n表示n维的坐标空间),其子矩阵记为A[i:j],表示矩阵A从第i行到第j行的子矩阵.每次卷积操作可得到一个输出序列(向量),记为ot∈s-h+1,其中的元素为:
(1)
其中,i∈[1,s-h+1],运算符“·”表示矩阵之间的数量积.如果对输出序列ot加上偏置b∈s-h+1和激活函数f,那将得到一个特征映射(feature map)序列ct∈s-h+1,其中的元素为:
(2)
然后,由于每个特征映射向量的维度是由文本的长度和区域大小共同决定的,本文用池化操作将每个特征映射转化为一个固定大小的向量.一种常见的池化策略是1-max池化[26],它是从每个特征映射序列ct中提取一个具有最大值的标量,这里记为si.利用该池化操作,将从特征映射中提取出来的结果进行连接便组成了“最高层特征”,记为S=[s1,s2,…,sm]∈m,然后将其放入Softmax层便可得到分类结果,记为k.本文缺陷修复的类别标签使用one-hot形式表示(共有k维),假设V∈k×m表示Softmax层(softmax()函数)的权重矩阵,分类的类别可由公式(3)计算得到.最后,将最小化分类的交叉信息熵(如公式(4)所示)作为训练目标(即损失函数),利用给定的训练集训练预测模型.
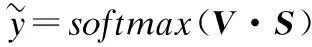
(3)
(4)
在Softmax层本文使用Dropout[27]作为一种正则化方法,此外也可采用L2正则化来防止过拟合的发生.这里,需要估计的参数包括卷积核的权重矩阵、激活函数里的偏置以及softmax()函数的权重矩阵.网络的优化方法采用的是SGD(Stochastic Gradient Descent)和反向传播算法[28].由于篇幅限制,本文省略了具体的推导过程.
算法1.单层卷积神经网络S_CNN的预测算法(Python)
输入:训练文本集Train_Text,测试文本集Test_Text,训练文本集标签Train_Label
输出:测试文本集标签Test_Label
01.BEGIN
02.TRAIN
03. # 生成batch序列对
04. {(Batch_Xs,Batch_Ys)}=Batches_Generator(
Train_Text,Train_Label)
05.FORBatch_X,Batch_YIN{(Batch_Xs,
06. Batch_Ys)}:
07. X=Embedding(Batch_X)# Embedding层
08. # Relu为激活函数
09. Conv_X=Relu(W1·X + B1)# 卷积层
10. Pool_X=Max_Pool(Conv_X)# 池化层
11. # 将池化后的特征连接起来
12. Feature_X=Concatenate(Pool_X)
13. P=Softmax(W2· Feature_X + B2)# 公式(3)
14. Cost=Sum(-Batch_Y·LogP)# 公式(4)
15. 使用Adam优化器最小化目标Cost
16. 并更新变量:W1,B1,W2,B2
17.ENDFOR
18.ENDTRAIN
19.TEST
20. Test_Label=[] # 初试标签列表
21. {(Batch_Xs)}=Batches_Generator(Test_Text)
22.FORBatch_XIN{(Batch_Xs)}:
23. X=Embedding(Batch_X)
24. Conv_X=Relu(W1· X + B1)
25. Pool_X=Max_Pool(Conv_X)
26. Feature_X=Concatenate(Pool_X)
27. P=Softmax(W2· Feature_X + B2)
28. Y_Pred=ArgMax(P)# 得到概率最大的标签
29. Test_Label.Append(Y_Pred)
30.ENDFOR
31.ENDTEST
32.RETURNTest_Label
33.END
值得一提的是,本文设计了两种不同的卷积结构来进行实验.第一种,单层CNN(S_CNN)采用相同的卷积区域长度,并使用100个卷积核进行训练,其结构如图1所示,相应的预测算法描述(伪码使用Python语言编写)见算法1; 第二种,多层平行CNN(M_CNN)采用不同的卷积区域长度,并使用平行结构进行训练,其结构如图2所示,相应的预测算法描述与S_CNN基本一致,不同的是在算法中将其09和10步骤并行处理.
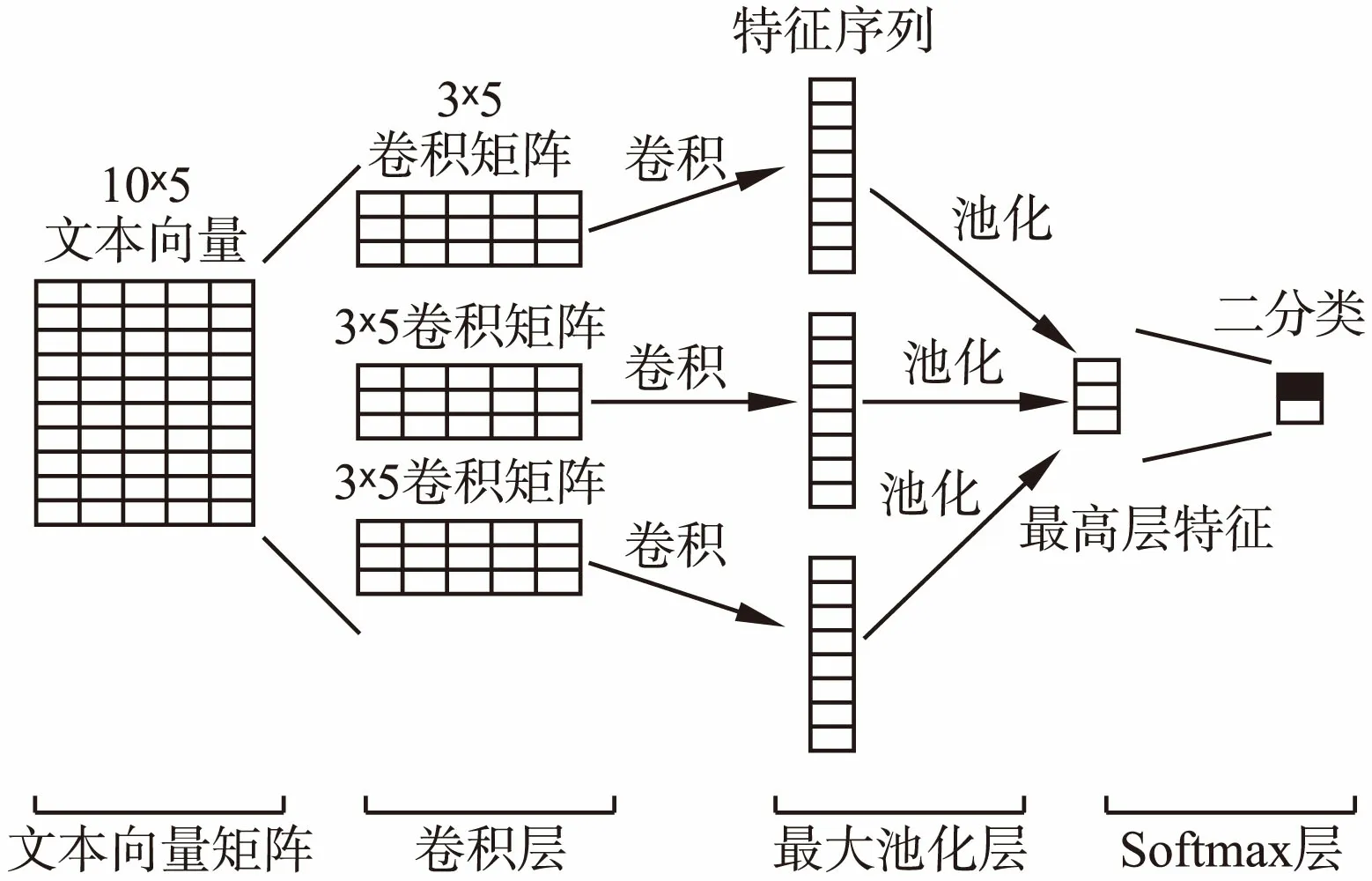
图1 S_CNN的网络结构Fig.1 Architecture of the single-layer CNN(S_CNN)
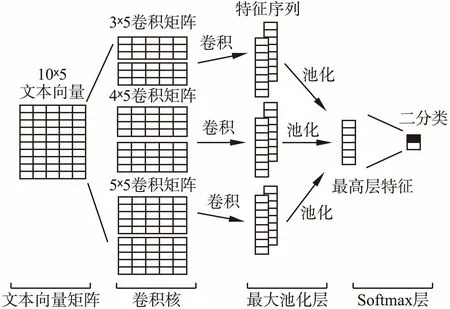
图2 M_CNN的网络结构Fig.2 Architecture of the multi-level parallel CNN(M_CNN)
4 实验及结果分析
4.1 数据准备与预处理
在软件开发过程中,一旦发现软件出现缺陷需要修复,相关人员会以报告的形式将其提交到缺陷库中形成缺陷报告.一个缺陷报告主要包括三个部分:第一部分是总结和预定义字段(主要包括状态(status)、所属产品(product)、所属组件(component)等);第二部分是描述,介绍如何实现缺陷的复现,帮助开发者了解缺陷发生的过程,以便查找缺陷产生的原因;第三部分是评论(comment),主要记录开发者针对缺陷的一些思考和建议.
本文选取了Bugzilla中Eclipse和Mozilla两个大型开源软件项目的缺陷数据作为实验的数据集,原始数据源于文献[29].以Eclipse为例介绍数据的收集过程.本文选取了2001.10~2011.09这10年间产生的20万个缺陷报告,它们的状态为VERIFIED、决议(resolution)为FIXED.每个缺陷报告对应的总结、描述、评论等文本信息放在一起,组成一个文本,然后进行自然语言处理,主要包括分词、去除非字母表字符、去除停用词、词干提取、词向量化等操作.对于缺陷报告的样本类别,本文将最后一个解决缺陷的开发者作为最终的类别标签,而不是考虑所有在缺陷投掷过程中出现的开发者以及发表过评论的开发者.同样地,本文也收集了1998.04~2011.05这13年间的22万个Mozilla缺陷报告.实验数据集的基本情况如表1所示.
表1 实验数据集
Table 1 Experimental dataset

软件项目缺陷编号时间数据量Eclipse1~3575732001.10~2011.020万Mozilla37~6600361998.04~2011.0522万
4.2 实验设计
4.2.1 实验环境
本文实验是在Dell T5810 Precision图形工作站进行的,其配置为8核Intel E5-1620V3 处理器、16GB内存、单卡图形处理器GPU(型号为华硕GTX 1080).图形工作站的操作系统为Ubuntu 16.04,实验所采用的深度学习框架为TensorFlow 1.1.0,Python版本为3.5.3.实验所用算法的具体配置见网址https://github.com/huazhisong/graduate_text.
4.2.2 验证模式
为了模拟实际的应用场景,按照文献[30-33]中的“十折”增量(ten-fold incremental)方式进行验证.将按时间先后顺序排序的数据集等分为互不相交的11份.首先,在第1轮时,使用第1份数据作为训练集,第2份数据作为测试集;在第2轮时,使用第1份和第2份数据作为训练集,第3份数据作为测试集;依此类推,到第10轮时,以第1到第10份数据作为训练集,第11份数据作为测试集.这样,针对每种算法,我们都可以在不同的训练集上训练十次.最后,以10轮结果的平均值作为最终的结果.
4.2.3 基准方法
SVM一般用于做二分类应用(当然,SVM也可以改造为支持多分类的模型),它的基本模型是定义在特征空间上的间隔最大的线性分类器.SVM的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题.间隔最大使SVM有别于感知机(perceptron).除了作为线性分类器,SVM还包括核技巧,这使它也成为了一种非线性分类器.值得一提的是,之前的工作(如文献[6,7,13])已证明了SVM在缺陷自动分配问题上的高效性和优势.
RNN是一种可以通过链式结构来存储和传递历史信息的神经网络结构.当处理序列数据时,它的输入由当前输入值xt和前一个节点的隐藏节点的输出ht-1组成.虽然RNN已成功应用于自然语言处理的多个应用,但由于有时连续多个输入之间的间隔过大,导致标准的RNN很难学习到长期的依赖,而且训练不容易收敛.Hochreiter等人[34]提出了一种新的结构LSTM,而且Ilya等人[35]将其应用到机器翻译领域,取得了良好的效果.这里,本文选择文献[34]提出的标准LSTM模型作为对比实验的基准模型;此外,也选取了文献[36]提出的BiLSTM作为对比实验的基准模型.
4.2.4 评价指标
和文献[4,12,29,33]一样,本文采用的评价指标为准确率(也称为命中率),其计算公式如下:
(5)
其中,Tk为在给定k名开发者的情况下预测成功(与类别标签完全匹配)的缺陷报告数目,N代表缺陷报告的总数.
4.3 实验结果
表2和表3显示的是本文所提方法和基准方法在Eclipse数据集上分别预测1名和5名开发者的结果.总的来说,本文提出的CNN模型要明显优于基准模型.在仅预测1名开发者的情况下,S_CNN的平均准确率比SVM的增加了15.69%,而M_CNN增加了22.96%.在预测5名开发者的情况下,与SVM相比,上述两种模型的平均准确率也分别增加了10.87%和17.48%.类似地,表4和表5显示了相关所有方法在Mozilla数据集上的预测效果.在预测1名和5名开发者的情况下,M_CNN的平均准确率比SVM的分别增加了16.01%和14.50%.这表明CNN在基于文本分类的软件缺陷自动分配问题上是有效的.
相比较CNN而言,RNN模型在Eclipse数据集上似乎并不十分有效,其效果远低于CNN模型的.甚至与SVM相比,LSTM模型取得的效果也并不占优,而BiLSTM的效果要更差一点,这说明需要更好地挖掘和利用文本的序列信息,来进一步改善RNN的预测效果.
表2 Eclipse数据集中Accuracy@1的实验结果(%)
Table 2 Results of Accuracy@1 on the Eclipse project

Accuracy12345678910AVGSVM30.6938.7239.5340.7141.2940.4542.7443.6244.7040.2740.27S_CNN41.85 51.76 55.19 55.13 62.16 54.84 62.88 61.87 61.69 52.29 55.96M_CNN50.2757.9662.0861.6967.1966.5968.9068.4269.1560.0263.23LSTM35.59 35.74 35.97 41.5336.5342.6242.91 48.71 44.79 28.48 39.29BiLSTM35.95 36.17 35.13 39.7937.3140.9042.74 32.14 37.59 31.99 36.97
表3 Eclipse数据集中Accuracy@5的实验结果(%)
Table 3 Results of Accuracy@5 on the Eclipse project

Accuracy12345678910AVGSVM48.4350.2352.2654.3356.3258.3461.2448.4350.2352.2657.05S_CNN51.6261.6466.5766.9875.1669.3575.4074.2873.9264.2667.92M_CNN60.7067.4073.3072.4078.9079.2180.8780.3879.9272.2774.53LSTM50.5753.2654.6959.2655.4261.1961.3766.3561.6144.6056.83BiLSTM50.3253.3852.7657.0555.8258.4359.0650.1853.8046.7553.75
表4 Mozilla数据集中Accuracy@1的实验结果(%)
Table 4 Results of Accuracy@1 on the Mozilla project

Accuracy12345678910AVGSVM35.4136.937.0840.5841.7140.9842.542.9944.6342.6535.41S_CNN19.40 33.04 32.69 38.63 50.88 50.26 60.65 55.66 57.86 36.39 43.54 M_CNN29.4347.8244.6450.0156.2153.8864.2163.7358.6545.6651.42LSTM17.45 25.05 27.60 24.46 24.85 35.94 41.57 37.78 46.20 39.71 32.06 BiLSTM16.84 24.09 25.12 23.62 33.77 22.85 42.71 31.76 37.11 28.54 28.64
表5 Mozilla数据集中Accuracy@5的实验结果(%)
Table 5 Results of Accuracy@5 on the Mozilla project

Accuracy12345678910AVGSVM43.2144.2346.5548.4449.465051.2454.2555.3254.1249.68S_CNN30.45 45.52 41.88 49.54 63.12 63.43 73.51 66.85 69.25 49.64 55.32 M_CNN42.64560.3354.4960.6668.01568.52579.06576.1671.9859.92564.18LSTM32.04 41.02 40.97 37.01 38.82 51.80 59.25 58.34 61.98 55.27 47.65 BiLSTM29.49 39.16 38.27 35.96 51.56 36.82 61.49 47.55 53.27 42.71 43.63
在Mozilla数据集上,RNN模型的预测效果也比本文提出的CNN模型的效果要差,而且差距比较明显,如表4和表5所示.类似地,从平均准确率指标来讲,LSTM模型接近于SVM,但是BiLSTM模型要逊于SVM.
4.4 高效性的理论分析
本文提出的基于CNN的缺陷自动分派算法比基准的机器学习SVM算法、深度学习LSTM算法和BiLSTM算法都要高效,原因分析如下:
首先,在这些方法中,CNN的运行效率最高.CNN本身的结构是平行的,非常适合并行计算,加上使用了GPU加速,因而在运行效率上要比SVM快,更比LSTM这种串行结构的算法要快.
其次,CNN比SVM更注重词序性.SVM以加速N-Gram形式来增加词序信息,但是这样不仅加大了数据的维度,增加了计算量,而且会增加其矩阵的稀疏性,反而有可能降低分类的准确性.值得注意的是,LSTM是适合用来处理序列信息的,但是由于实验数据的文本长度均接近200个英文单词,这么长的序列在很大程度上限制了LSTM读取文本序列的能力,因为它要处理的依赖过长.
最后,CNN能快速有效地捕获局部词序信息.CNN虽然在文本建模上的效果比不上LSTM,但是CNN能捕获局部的词序信息,并将其全局共享.这一特性对文本分类效果的影响尤为重要,因为关键的文本分类信息往往就是一两个区域的短语决定的.
4.5 效度分析
虽然本文提出的基于CNN的文本分类方法在缺陷自动分配中取得了良好的效果,但是该方法的局限性(仅仅只考虑文本特征,未涉及缺陷所属项目和组件、开发者活跃程度等其他因素)以及一些潜在的威胁(potential threats)可能会影响实验的结果.
首先,文本直接将缺陷报告文本进行向量化表示,然后使用CNN自动获取文本特征,在这个过程中并未使用自然语言处理领域最新的方法,如生成对抗网络(Generative Adversarial Network)和注意力模型(Attention Model).这表明该方法还存在进一步提升的空间.
其次,由于受硬件设备的条件限制,本文中CNN的网络结构是比较简单的(浅层)神经网络结构,这显然不能达到当前最好的分类水平.因此,后续工作将继续设计更深层的神经网络结构进行实验.
然后,基准方法只选取了SVM、LSTM和BiLSTM三种经典的分类算法/模型,而且其参数均使用的默认设置.由于一些复杂的机器学习分类算法和最近提出的人工神经网络模型缺乏实现代码,难以复现其效果,本文并没有考虑将它们作为基准方法进行对比.
最后,本文的实验只在Eclipse和Mozilla两个数据集上进行了测试,因而并不能保证本文所提方法在其他开源软件项目上的通用性.
5 总 结
针对软件缺陷报告文本的特点,本文将深度学习中的CNN模型引入到软件工程领域的缺陷自动分配任务中.利用缺陷报告的总结、描述和评论等文本信息训练开发者预测模型,在Eclipse和Mozilla两大数据集中进行了实验,本文所提方法与机器学习的SVM算法和深度学习的RNN模型相比,在准确率上具有明显优势,从而验证了CNN结构的有效性,为缺陷自动分配问题提供了一种新的解决思路.
今后的研究工作主要包括:1)引入最新的生成对抗网络和注意力模型等方法提升文本特征的提取效果,从而进一步提高CNN模型的预测效果;2)考虑缺陷所属项目和组件、开发者活跃程度等因素,构建针对异构特征的混合模型.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
经济(2016年29期)2016-12-27
高中生学习·高三版(2016年9期)2016-05-14
CHIP新电脑(2016年3期)2016-03-10
新高考·高二数学(2015年11期)2015-12-23
