
流式应用层协议载荷封装交付算法优化
2019-01-24 09:29张润滋王劲林叶晓舟
小型微型计算机系统 2019年1期
张润滋,王劲林,陈 晓,叶晓舟
1(中国科学院声学研究所 国家网络新媒体工程技术研究中心,北京 100190)2(中国科学院大学,北京 100190)
1 引 言
随着互联网爆发式的发展,网络流量规模日益增长.伴随而来的,是对网络处理设备的高性能需求.无论是网络安全的数据分析、取证[1],还是网络流量的深度解析、管理[2],越来越多的网络设备涉及到IP层和TCP层以上的数据处理,面向应用层的网络流量分析随处可见.以TCP/IP网络四层模型为例,绝大多数的传输层及以下的网络功能都有较为成熟的处理和加速套件,如协议栈[3].这使得开发者能够从复杂的底层协议处理中解脱出来,来面对更为关键的面向应用的业务.与底层(TCP/IP及以下)协议的处理方式不同,应用层协议分布更广泛,任务也更复杂.
一个典型的网络流量实时审计采集系统的模块架构如图1所示.数据流输入到系统以后,经过滤操作,需要采集的数据流被TCP/IP协议栈处理,进而提交到数据流管理模块.为了提取数据流应用层的数据内容,需要完成后续的协议解析操作,并将解析后的有效字段载荷内容进行提取,并封装到日志中保存或者发送出去.本文将针对虚线中的三个相关模块及其流程,提出一种优化的载荷封装交付算法,通过优化各个环节处理方法,提升系统的处理性能.
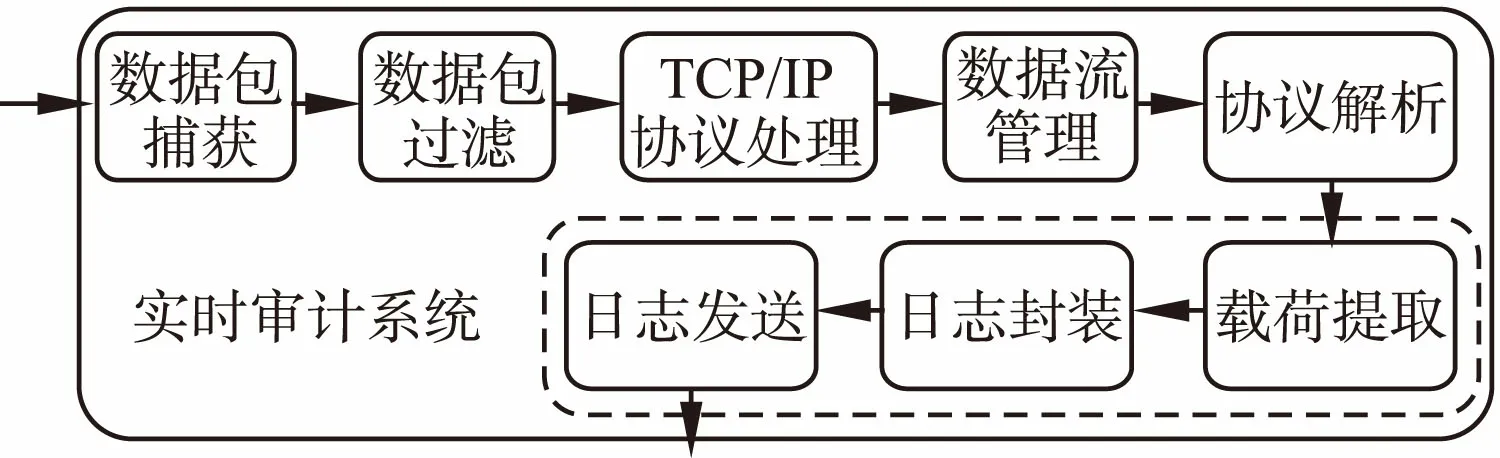
图1 一个典型的网络流量审计采集系统模块架构Fig.1 A typical network traffic audit acquisition system module architecture
2 相关研究
为了高并发、高吞吐的实现应用层协议解析及内容提取,已有研究在许多方面提出优化策略与算法.其中,文献[4]提出了基于状态机的HTTP Chunked流式解析算法.该算法从解析算法入手,减少了HTTP报文处理中的内存拷贝开销,能够有效降低处理时间和内存占用.文献[5,6]在有包间依赖关系的情况下,对聚合数据流缓存策略进行了优化.其中,文献[6]建立了缓冲串及缓冲模型,并以最小化交付时延为目的,提出了缓存管理算法OBMG.该算法以贪心的策略优化了数据载荷的拷贝过程,实现了交付延迟的大幅度降低.
不同于以上相关工作,本文针对高层协议载荷的封装及交付过程,在缓存策略、封装策略、发送策略三个方面进行了优化,能够充分提高载荷提取发送的性能.
3 高层协议载荷封装交付模型及算法
3.1 模型建立
以网络流量审计采集系统为例,其主要任务是将指定数据流中的高层协议按照协议规范进行解析,然后提取需要的内容字段并写入日志,以供后续的分析处理[1].以HTTP协议的审计为例,所需提取的字段可能包括:URL、请求方法、协议版本、响应状态码、Cookie、请求消息内容、相应消息内容等等.每一条HTTP数据流,包括客户端与服务端之间两个方向的单向数据流,提取后的各个审计字段将记录在一条日志当中.

图2 缓冲串加法操作示意图Fig.2 Buffer string addition operation schematic
需要注意的是,TCP协议采用流式发送的方法,即数据段与数据包之间没有一一对应关系.系统收到的数据包可能包含高层应用的一个或多个完整字段,同时,也可能只包含字段内容的一部分.因此,较长的字段内容或被"割裂",封装在多个网络数据包中传输.
字段的解析顺序由应用的交互决定,一般情况下字段间没有交叉,按照到达顺序逐个解析并写入日志.本文所涉及的载荷封装及交付过程,符合文献[6]提出的缓冲模型.该模型定义了字串缓冲过程的加法运算、消除运算以及逆缓冲串,并提出了缓冲的ABD(arrival,buffering,deliver)过程.其中,对于缓冲串b,其对应的字串和位置分别为s(b)和a(b),则缓冲串b1、b2的缓冲串加法操作如图2所示.
本文不关心高层协议解析的具体过程和方法,只涉及已提取出字段的日志封装、缓存、发送过程.具体可描述为如下AED子流程:
1) Arrival:经过协议解析,一个或多个字段,或者字段的一部分被解析出来;
2) Encapsulation:将当前字段内容写入指定格式的日志缓存中;
3) Delivery:将缓存的日志内容提交,以发送到指定接收端,或者写入磁盘.
如图3(a)所示,AED过程是流式的处理过程,在多核系统中,同一个核心上可能同时处理交错到达的多条应用数据流.值得注意的是,AED子过程之间不是互相独立的,前一个子过程决定了后一个子过程的最早触发时机.只有存在Arrival状态的字串,才会触发Encapsulation进行封装操作;一个完整的Encapsulation操作结束之后,才可能触发Delivery操作.因此,缓冲池的状态可以描述成一个状态空间,表示为如图3(b)所示的状态转移图.其中S0,S1,S2,S3分别表示缓冲区无内容、缓冲区非空但字段封装不完整、缓冲区有且只有一个完整封装字段、缓冲区有不止一个完整封装字段.
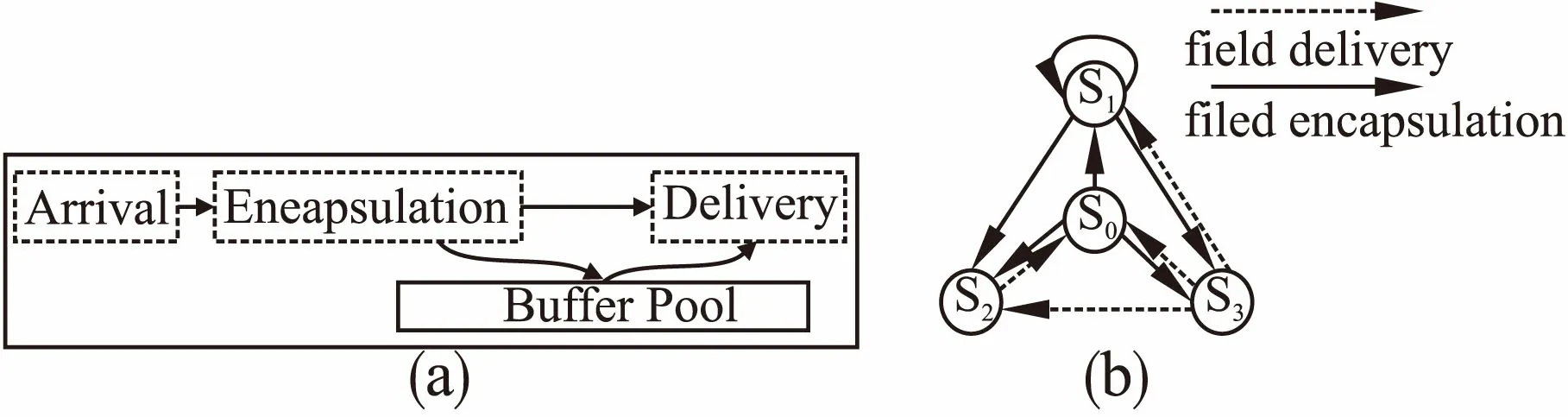
图3 AED过程示意图(a)以及缓存状态转移图(b)Fig.3 AED process diagram (a) and cache state transition (b)
显然,载荷字段封装以及交付过程中,缓存池状态满足马尔科夫性质.即封装交付过程中缓存池组装日志的下一状态只与当前状态相关,与历史状态无关.在高速处理环境下,状态之间切换的触发时机,直接影响着系统的内存使用情况和日志传输效率.
3.2 算法描述
3.2.1 PFED算法
基于上一节所描述的状态转移模型,首先分析朴素字段封装交付算法PFED(Plain Field Encapsulation and Delivery Algorithm).该算法描述如下:
算法1.PFED
1.procedureFIELD ENCAPSULATION AND DELIVERY
2.encap_buffer←InitPerFlow()
3.whilecurrent_field←Arrival()do
4.encaplsulate_field←Encapsulation(encap_buffer,current_field)
5.status←EncapsulationStatus(encapsulate_field)
6.ifstatus=COMPLETEDthen
7.Delivery(encapsulate_field)
8.else
9.encap_buffer←encap_buffer⊕current_field
10.endif
11.endwhile
12.endprocedure
PFED算法顺序的执行载荷的封装和交付操作.每当有新的载荷字段到达,PFED执行封装操作,如果缓冲区及新的载荷能够组成完整的字段内容,则直接交付该封装字段;否则,将当前载荷内容添加到缓冲区中,即与原缓冲区字串执行缓冲串加法操作.在此,对于尚未完整到达的载荷字段,需要将不完整的封装结构缓存到与数据流相关的封装缓冲区中.
该算法存在如下问题:
1)在一个处理核心上,如果当前处理的字段内容较长,即"割裂"字段到达并分布在多个数据包内,当前缓存池状态将持续处于S1状态,等待更多该字段内容的到达,以实现完整的封装,这意味着,在高并发、高吞吐的场景下,众多处于该状态的缓存池将占用较大的内存空间,同时只有部分字段完成封装和日志交付.
2)为了保证内存的块的使用效率,发挥多核处理器上内存管理的优势,在交付过程中一般采用固定大小的消息缓冲块来交付每一个封装好的字段内容.因此,"交付效率"(DE,Delivery Efficiency)就是一个值得关注的问题.交付效率是当前交付消息中,有效内容的总长度与消息长度的比值.如果当前处理的字段大多数都比较小,对于每个有效字段内容,都需要封装一个固定大小的封装头和固定的封装消息缓存块,则有效内容在交付的消息中所占长度比例相对较低,导致总体"交付效率"低.
3.2.2 SFED算法
为了克服以上状态转化模型及PFED算法的问题,本文进一步提出了流式字段封装交付算法SFED(Streaming Field Encapsulation and Delivery Algorithm).该算法在的核心在于优化了状态转换之间的触发机制,主要有如下两点:
1) 对于可能"割裂"的字段,不再等待收取完整才触发交付;采用嵌套AVP(Attribute-Value-Pair)封装结构来保证协议任意字段的流式发送,而避免缓存不完整的字段内容;
2) 当缓冲池中存在完整可发送的字段日志时,不再立即触发交付流程;设置缓冲池的交付触发阈值,只有缓存池中缓存的字段日志总长度达到一定值时,才触发交付.
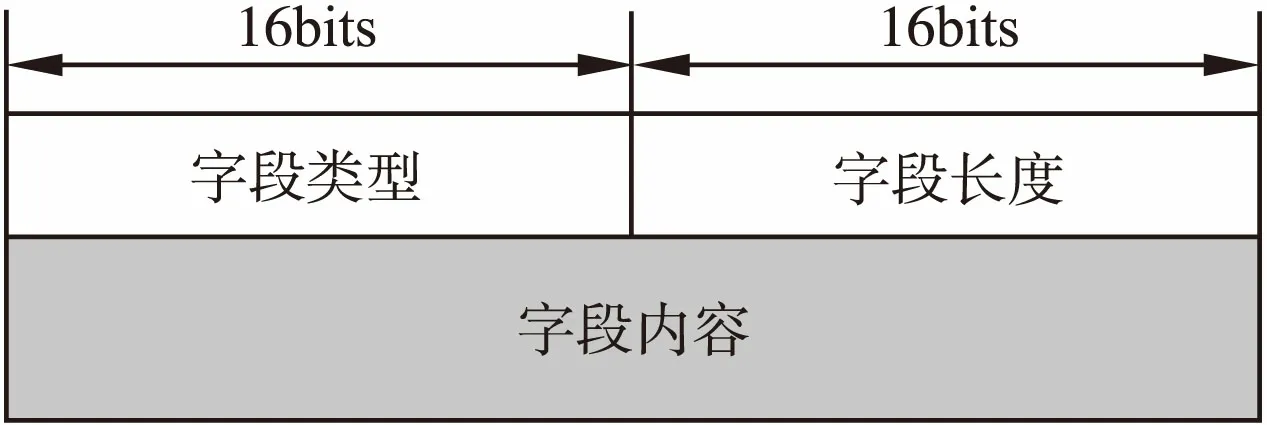
图4 一个典型的AVP封装结构Fig.4 A typical AVP encapsulation structure
其中,一个典型的AVP封装结构如图4所示.将可能"割裂"的字段封装为嵌套结构,外层AVP类型值指定为字段的类型值.作为外层AVP的内容,封装两个内层AVP结构:第一个AVP指示本段分段内容的编号,第二个AVP封装实际的本段内容,该AVP结构由接收端负责解析和组装.通过上述封装结构,虽然增加了部分冗余信息,但有效的避免了"割裂"字段内容的缓存,实现了任意字段日志的流式发送.
基于以上分析SFED算法描述如下:
算法2.SPED
1.procedureFIELD ENCAPSULATION AND DELIVERY
2.deliver_buffer←InitPerThread()
3.whilecurrent_field←Arrival()do
4.avp_field,avp_size←AvpEncapsulation(current_field)
5.buffer_size←BufferPoolSize(deliver_buffer)
6.if(buffer_size+avp_size)≥THRESHOLDthen
7.Delivery(deliver_buffer)
8.Delivery(avp_field)
9.else
10.deliver_buffer←deliver_buffer⊕avp_field
11.endif
12.endwhile
13.endprocedure
值得注意的是,SFED不需要配置与数据流对应的封装缓冲区,取而代之配置的是与每个处理线程/核心对应的交付缓冲区.即,缓冲区块的数目从数据流数目级别降低到线程/核心数级别.这大幅度减少了所需要的缓存空间,对于资源受限的边缘设备有着重要的意义.另外,对于记录有些长度没有限制的字段内容,SFED算法有着先天的优势.举例来说,HTTP协议没有规定URL的最大长度.如果浏览器或者其他客户端发出了过长的URL请求,SFED亦能够在不消耗大量内存空间的情况下,流式完成封装.此外,某些协议如果出现恶意攻击,数据请求和响应的内容也可能长度超出设想.这种状况下,PFED算法会无限制的缓存这些字段内容,导致系统内存耗尽,自动陷入"拒绝服务"的状态当中.而SFED算法自然地避免了类似问题的发生.
相对于PFED算法,SFED算法通过嵌套的AVP封装消除了对长字段内容的缓存操作,实现了任意字段数据的流式发送;另一方面,针对连续到达的字段长度较小的字段内容,SFED算法使用了固定大小的阈值缓冲池.类似于TCP的Nagle算法[7],SFED算法能够聚合发送长度较短的字段内容.聚合发送的优势在于,在交付有效内容总长度一致的情况下,更少的数据分块能够提升单个交付消息中的有效内容长度,提升交付效率,即有效内容的网络发送效率和磁盘写入速率.
4 性能测试
本文在基于Cavium OCTEON CN6645芯片[8]的多核网络处理器上实现了网络流量审计采集系统.Cavium多核架构相当于硬件多线程,软件系统总体架构如图5所示.该系统运行在多核异构操作系统上,部分核心运行实时系统,负责采集环节各个模块的实现,日志发送模块将采集的原始日志交付给Linux系统进行后续处理.实时系统与Linux系统之间,通过Cavium芯片的work消息机制完成通信.
本文通过IXIA测试设备对HTTP流量进行测试,系统输入交换机旁路镜像流量.日志提取的HTTP字段包括:Host, URL, Method, Request/Response Content,以及IP地址、端口、关联用户、时间戳等信息.HTTP页面大小分别为1B、20B、100B、1KB、3KB、16KB.采集实时系统运行在3个核心上,本文对比了PFED算法以及不同阈值参数的SFED算法的单核最大吞吐性能,最终结果如图5所示.
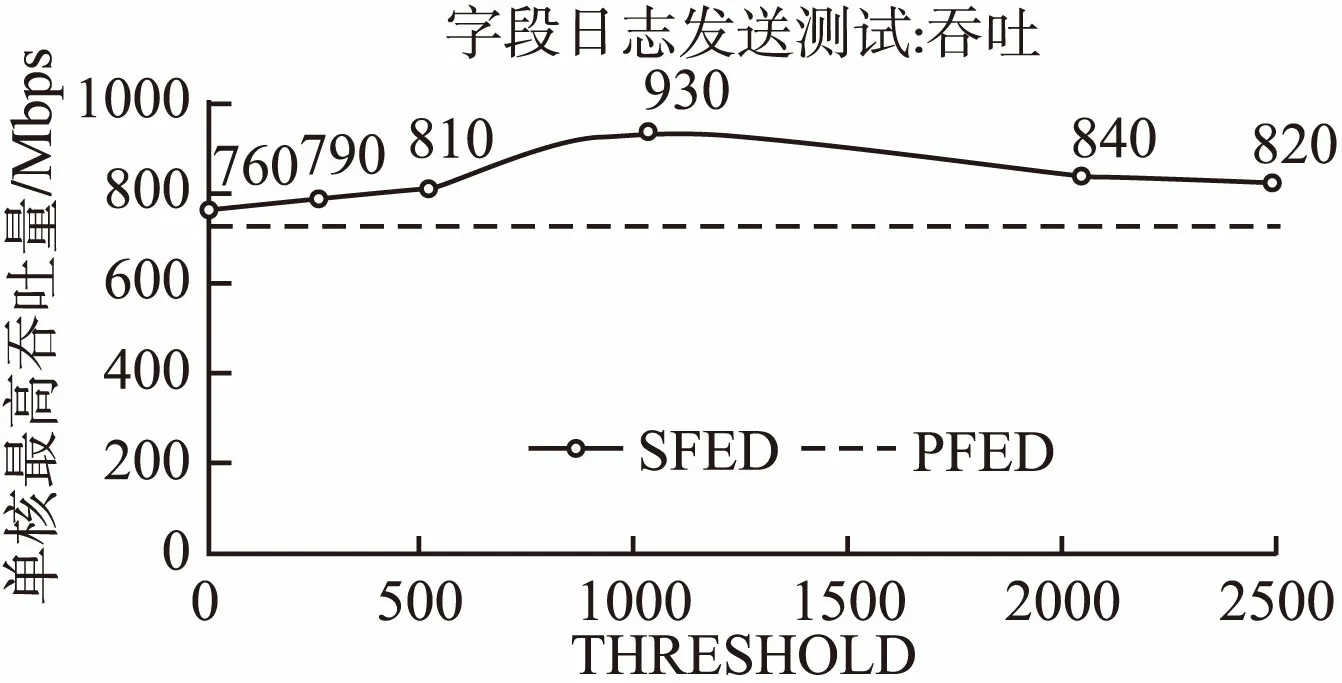
图5 字段日志发送吞吐测试Fig.5 Throughput test of field logs sending
流式发送的SFED算法在字段封装交付过程中,由于能够避免长字段缓存引起的内存瓶颈,有效提升了系统的吞吐量,测试点吞吐量始终在PFED算法数值之上.随着SFED算法阈值的提升,短字段内容的聚合发送效率逐渐提升,系统吞吐性能随之提升;在超过某个临界点(在1024附近)以后,吞吐性能开始下降,这是因为设置较高的阈值,某些较长字段被拷贝到交付缓冲区,这些拷贝操作带来的开销超过了通过聚合发送带来的性能提升收益,如果进一步增大阈值,系统性能会大幅度下降.
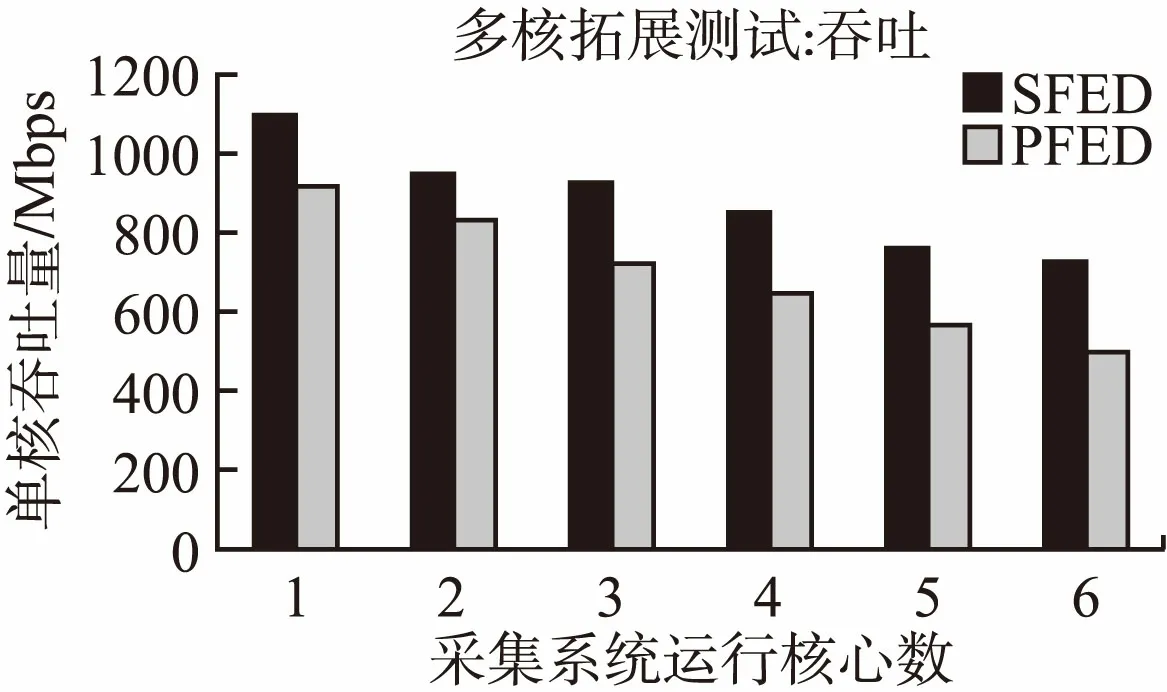
图6 字段日志发送多核拓展吞吐测试Fig.6 Throughput extensibility test of field logs sending
本文同时测试了在HTTP页面为16KB时,SFED和PFED算法的多核拓展性能.如图6所示,SFED算法单核平均吞吐量始终高于PFED,随着采集系统运行核心数目增加,吞吐量总体呈现下滑趋势.导致下滑的因素主要有两点:
1)多个核心在数据拷贝过程中,对多核之间的共享缓存等资源产生竞争,导致系统总体性能有所下降;
2)系统输入数据的PPS(Packets per Second)大量增加,逐渐逼近了采集系统日志交付性能的限制.
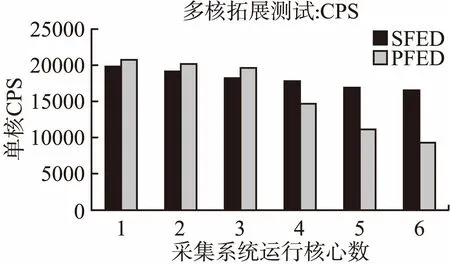
图7 字段日志发送多核拓展CPS测试Fig.7 CPS scalability test of field logs sending
在HTTP页面大小为1B时,两种算法的单核的平均CPS(Connections per Second)性能如图7所示.在核心数较少时,PFED算法CPS略高,是由于SFED算法相对于PFED算法,引入了额外的数据拷贝计算开销.但当核心数超过3个,PFED算法性能大幅下降.原因在于,在CPS测试过程中,大量的短字段内容导致交付效率大幅降低,系统处理的数据包
PPS达到上限;相对来说,SFED算法有效聚合了大量载荷小的数据包,提高了总体的传输效率.
5 总 结
本文针对网络处理设备中的应用层载荷提取过程,提出了流式的载荷字段封装交付算法SFED.相对于朴素字段封装交付算法PFED,所提算法通过合理的嵌套AVP封装,实现了长字段内容的流式交付,避免了对字段内容的缓存操作;同时,对短字段内容应用了聚合发送策略,有效提升了载荷的交付效率,提升了系统的总体性能.
猜你喜欢
现代建筑电气(2022年6期)2022-12-16
电脑爱好者(2021年23期)2021-12-08
计算机时代(2021年9期)2021-10-08
商品与质量(2019年27期)2019-12-02
办公室业务(2019年13期)2019-08-01
中国新通信(2017年3期)2017-03-11
时代人物(2014年10期)2015-01-28
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
环球时报(2012-01-12)2012-01-12
