
一种面向领域的Web服务语义聚类方法
2019-01-24 09:29何泾沙何克清
小型微型计算机系统 2019年1期
赵 一,李 昭,陈 鹏,何泾沙,何克清
1(三峡大学 计算机与信息学院,湖北 宜昌 443002)2(武汉大学 计算机学院,武汉 430072)
1 引 言
随着SOA(面向服务的架构)技术的发展,互联网上的服务资源呈现出快速增长的趋势.据统计,Web服务搜索引擎网站注册的Web服务已超过数万个,ProgrammableWeb (PWeb)网站上发布的各种Web API也超过16000个.Web服务遵循的协议也存在较大差异,根据PWeb网站的统计,遵循简单服务协议(Simple Object Access Protocol,SOAP)的服务约占16%,标准通用标记语言远程过程调用(XML Remote Procedure Call,XML-RPC)的服务约占10%,而遵循代表性状态传输(Representational State Transfer,REST)的服务所占比例已经多达73%.同时,各种服务描述语言也逐渐增多,如WSDL、WADL、WSMO等,还有大量的服务描述是基于自然语言文本.这种非结构化的描述方式为服务文档分析与处理带来了极大的困难.如何提高服务发现的效率和精确度,已成为服务计算领域的研究热点.
服务描述文档是服务聚类的数据基础,而服务聚类是服务发现的一种重要辅助手段.目前,服务聚类的主要方法包括以下几种:
①基于用户偏好相似度的服务聚类,如文献[2]提出了一种用户自身偏好的关键属性描述,并剔除不满足相应约束的相似类,再结合用户给定各属性的权重值选择最佳候选服务.
②文献[3]提出了基于WSDL、OWL-S和文本等方式描述的Web服务进行聚类.
③基于自然语言本文相似性的服务聚类方法,文献[4]提出一种两阶段的服务聚类方法.第一步,利用融合领域特性的支持向量机(Support Vector Machine,SVM)对服务进行分类;第二步,对分类得到的领域服务集进行面向主题的聚类.文献[5]提出一种使用本体辅助的支持向量机和面向领域的服务特征降维技术,建立服务的特征内容向量.接着,使用一种标签辅助的主题服务聚类方法T-LDA建立融合标签信息之后的隐含主题表示,进而在同一领域进行聚类.但是,上述几种服务聚类算法存在以下不足:
首先,有的方法考虑了利用KF-IRF(Keyword Frequency-Inverse Repository Frequency)生成领域词汇排序表和领域表征度DR(Degree of Representation)来筛选领域特征词汇,而该方法解决关系描述复杂的服务文档特征词汇提取效果不佳,因为有些泛化的主题包含的单词为功能词或是公共词条.如果用KF-IRF和DR来筛选并剔除词汇,就会混淆表征服务内容能力的功能词和重要公共词条,最后导致被误删.
其次,虽然考虑了自然语言描述的服务,以及服务的表征能力,但是没有考虑表征词汇的同义词.现有的方法大多直接对互联网中采集的数据集进行直接聚类,而没有对服务领域进行划分.比如,地图查询领域和网络购物领域分别具有功能相似的“目标定位”和“商品定位”服务,如果在服务聚类时不考虑其所属领域信息,这两个来自不同领域的服务有可能被划分到同一类簇中.
再者,尽管在同一服务领域对服务进行聚类,但并未关注句子之间的语义联系,会出现“词汇鸿沟”现象.因为在服务中,任意两个名词之间都是孤立的,从两个向量关系中看不出两个名词之间是否有联系.例:图像识别(Image Recognition)领域中的人脸辨识服务和面部分析服务,若从单个词向量来聚类,会出现同义词汇丢失,造成降维后聚类的准确率偏低,导致同一类别的服务被LDA方法划分到不同类簇中,从而形成错误的聚类结果,本文利用了同义词汇表对聚类降维更加提升了降维的准确率.因此,面对互联网上服务呈指数型增长以及服务的异构性,已有服务聚类算法存在的不足,如何准确有效地解决服务聚类问题,已成为当务之急.
面向领域的服务聚类,本文提出了基于两阶段的服务聚类方法.首先,从PWeb网站的Web服务描述文本中,抽取某一服务名词的属性描述或功能描述,随后生成结构化文本,并剔除动词之前的服务名词,因为该名词往往是抽象名词,会影响LDA聚类精度,所以要剔除抽象名词.再使用TF-IDF算法计算出服务描述中的关键词,并根据给定的阈值剔除服务特征值低的关键词汇,并利用深度学习算法(Word2vec)查找要剔除的关键词,同理根据阈值剔除其特征值低的同义词,再使用决策树分类器来划分Web服务类别.
最后,使用LDA对分类得到的领域服务进行面向主题的聚类.这里需要特别提到的是,在Web服务描述中存在大量同义词,所以我们需要对服务描述文本做预处理,然后才能调用Word2vec算法对特定领域中的词汇按照其领域关联度进行排序,并通过排序表进行领域划分.该方法避免了传统LDA服务聚类导致的划分错误的现象,并根据同义词表精确筛选表征服务内容能力弱的词汇,有利于提高服务资源聚类的准确率,最后达到了服务资源进行高效的组织管理的需求.
2系统框架
为了实现按语义划分领域和基于主题的服务聚类方法,本文使用Word2vec方法建立服务描述的结构化模型,然后利用决策树算法进行领域划分,最后用扩展的语义主题模型(S-LDA)建立融合语义信息和服务描述特征向量的服务隐含主题模型,并基于隐含主题模型完成服务聚类.面向领域、语义辅助的服务聚类模型DSWSC描述如图1所示.

图1 面向领域、语义辅助的Web服务聚类框架Fig.1 Domain oriented semantic Web service clustering framework
DSWSC模型对Web服务聚类分为四步,第一步数据爬取与预处理阶段,该阶段爬取了Pweb网站服务名称和服务短文本描述,然后读取PWeb文件夹中的每个文档,并利用去停用词工具(例如https://github.com/fxsjy/jieba/),去掉影响文本分析的停用词,生成待分类Web服务描述文本;第二步针对服务短文本建立结构化关系,同时切分短句并引入关键短句标注,从而使得语法关系更加清晰,利用神经网络模型转换关键短句为词向量,然后用Word2vec的Softmax层归一化,并使用决策树分类器划分服务领域,在此基础上计算余弦相似度,找出该领域类似的词,按相似度进行大小排序;第三步融合语义信息的主题聚类,建立服务的隐含主题;第四步利用第三步得到隐含主题,应用S-LDA语义-主题-文档模型对服务在同一领域进行聚类,形成Web服务类簇,这些类簇有助于提升服务搜索引擎效率.
2.1 数据爬取和预处理
本文对截止2017年3月的PWeb网站的数据进行了爬取,如图2所示,我们爬取的内容格式是由Web服务名和服务描述组成的自然文本,其描述结构为“Web服务名”+“动词”+“服务描述内容”.本文选用“jieba”分词包进行分词,停用词表是CSDN.NET网站所提供的词表(http://blog.csdn.net/u014470581/article/details/51598258),包括891个停用词.

图2 PWeb网站爬取的服务信息
Fig.2 Example service information in PWeb
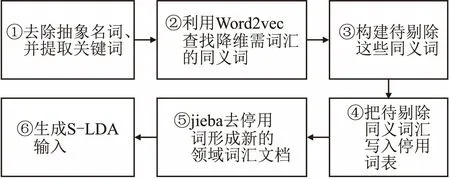
图3 LDA聚类的预处理步骤Fig.3 Preprocessing steps of LDA clustering
在进行文本聚类时,由于自然语言的复杂性导致了句法分析难度的增加,本文在进行文本分类前,增加了文本预处理模块,其具体步骤如图3所示:①去掉动词前的名词,可以定位文档中关键描述信息,例句“4Chan is a forum for image posting and discussion.Users can post images to different threads,separated categorically into themes like videogames,anime,music,and more.”中描述Web服务的关键词汇是“image posting”,而不是服务名称“4chan”,服务真正重要的信息在服务名词和动词之后,所以分类时需要提取动词之后的有用信息,再利用TF-IDF算法提取关键词汇.②接着生成关键词汇表.③利用关键词汇表去寻找文本中的同义词.④剔除特征值低的关键词汇和同义词.⑤使用去停用词工具再剔除特征值低的词汇后形成新的领域词汇文档.⑥最后降维生成的新领域词汇文档作为S-LDA模型的输入,预处理阶段完成.
2.2 Word2vec词向量训练
建立Word2vec中的3层神经网络,如图4所示,它包含两种训练模型,分别是CBOW(Continuous Bag-of-Words Model)[17]和Skip-gram[18],其基本思想是根据上下文来预测周边单词出现的概率,假如给定一句话g,这句话由词汇w1,w2,w3…wT组成,来预测其中一个单词wt出现的概率,计算公式如下:
(1)
context表示的是wt的上下文,并以One-hot representation表示成词向量,然后将向量相加,这里用C表示词向量之和,V表示语料库里面的词总个数,则C表达为|V|xn.在通过Word2vec模型时,将矩阵C中的行向量作为输入,记为C(wt-n),C(wt-n+1)…,C(wt-1),C(wt).通过隐藏层的CBOW模型,对输入层的V个词向量做累加求和,即
(2)
其中Xw
表示向量的每个元素未归一化,再利用函数softmax对Xw进行归一化处理,最终得到
(3)
其中,输入向量Xw为上下文词汇词向量之和,矩阵ρ表示输出层和输入层的关联系数,矩阵σ表示输入层到隐含层的权重矩阵,b为隐含层到输出层的偏置向量,d是输入层到隐含层的偏置向量,tanθ为隐含层激活函数.本文通过对自然语言文档建模,并利用了上下文信息获得向量空间中的词向量表示,使得之后的分类信息更加丰富,但是大部分服务描述都是使用英文,本文只专注研究英文服务文本,即对英文自然语言文本的处理,所以选用停用词表示以英文为基础.我们的研究团队也研究中文的自然语言处理文本,在此篇文章中不做详细说明.
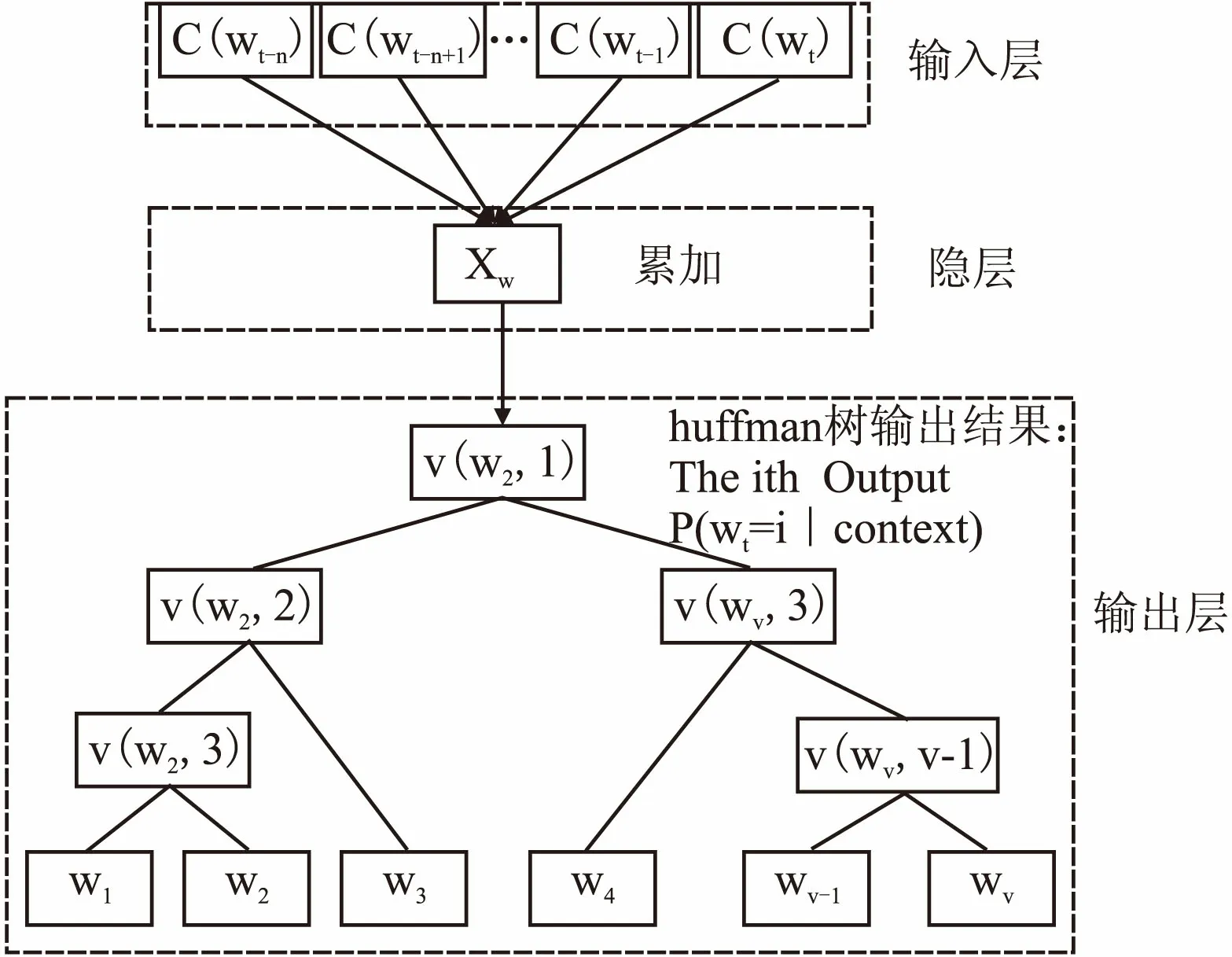
图4 CBOW同义词查找模型结构Fig.4 CBOW synonym search model structure
2.3 基于词向量的Web服务领域划分
因为现有服务聚类方法只对单一类型的服务文档进行聚类,缺乏考虑服务的领域特性的应用,针对该问题,在对服务进行领域分类的基础上,提出了一种基于概率、融合领域特性的服务聚类模型,以便于服务可以按领域进行聚类.根据TF-IDF查找对文档影响最大的描述词汇,通过Word2vec 3层神经网络结构寻找每个领域相关的所有文本,但是有些领域的训练集规模较小,使用小规模训练集进行分类时,得不到较高的分类准确率,所以我们目前只关注服务个数大于50个的领域.然后使用工具对每个文档提取代表性的关键句,使每个关键句的词汇都具备描述该领域的特征向量,由此形成了能代表该领域的特征向量,把领域特征向量送入分类器(本文使用语义-决策树分类器),最后得到Web服务文本的分类结果.具体算法如下:
算法1.基于词向量的Web服务领域划分
输入:Web服务文本集 Service,组成文本的单词wt,输入层到隐含层的权重矩阵σ,输出层和输入层的关联系数ρ,隐含层到输出层的偏置向量b,输入层到隐含层的偏置向量d;
输出:服务领域分类结果Domain.
1wt-n,wt-n+1…wt-1,wt←|V|xn//组合成矩阵
2 FOR EACH
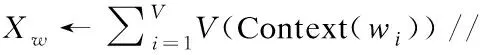
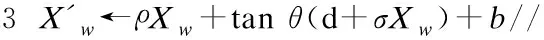
4 IFwt∈V&&w1…wv-1,wvSimilar towt//找出相似的同义词
5 vector←w1…wv-1,wv//组成同一领域的词向量表
6 Service←Decision tree classification//使用分类器分类
7 RETURNDomain
8 END
本节主要目的是为后续面向领域的Web服务语义聚类提供数据支持,所以,利用Word2vec算法对分类后得到的该领域中所有服务文档所包括的词汇进行相似度值的大小排序,生成了按领域词汇特征值大小的排序表,该表为第三节的S-LDA服务聚类模型提供了基于语义的服务特征降维方法.
3 语义辅助的Web服务聚类方法
在第2章中,对服务进行了按领域分类的步骤之后,我们将在此领域分类上对服务进行领域聚类.Web服务文本词汇丰富,语句结构复杂,因此,面向领域的特征降维在服务聚类中非常重要.本文通过特征降维来加快Gibbs抽样,能够快速达到细致平稳条件,从而使得马尔科夫链收敛到平稳分布,并获得稳定的样本,进而选择表征服务贡献度大的词汇,剔除贡献不大的高频词汇,来实现特征的降维.
本文创新点就是引入语义Word2vec模型对Web服务领域进行分类,并在分类之后对表征该领域的服务词汇进行相似度的排序,并生成领域词汇排序表,进一步使用词汇领域的语义表征度(Semantic Representation)来筛选领域特征词汇.
语义表征度SR:是指一个特证词Fi对一个领域dj的表征程度,其公式:
(4)
其中,|Bi|
表示领域dj中包含特征词ri的web服务文档数,|SBd|
表示领域dj中服务文档总数,SSi表示特征词Fi和领域的相似度,所以SR(Fi,dj)越大,说明Fi不仅与领域有相似度,因在服务文档中出现频繁,故对该领域的表征度越强.例如图像领域中的“image”在该领域的大部分服务中都会出现,能显出该词在面向领域的服务表征度很高.由于在该领域中大多数文档都会出现,所以进行领域服务聚类时的作用没有其它特征词大.因此,本文利用相似度与频率的综合,形成了剔除阈值C(0~1之间百分数),使用剔除阈值来剔除出过于频繁的特征词汇,从而实现了合理的特征降维方法.同理,文档中也存在该词的众多同义词,有的超出了阈值也需要剔除.
S-LDA模型中,语义辅助的特征词汇Sd被作为每个服务聚类都要用到的观察变量;s为隐变量,表示从语义词汇列表Sd中选取给定单词相关的语义参数.且每个语义参数都会和主题上分布的θ相关,而θ是先验参数α通过狄里克雷分布得到主题向量,所以这两个参数共同决定了主题z,又因为一个单词对应一个主题,所以z的分布决定了单词w的概率.β是各主题对应的单词概率分布矩阵,我们在先验参数β加了主题-领域相似度矩阵λ,来调控单词概率分布.
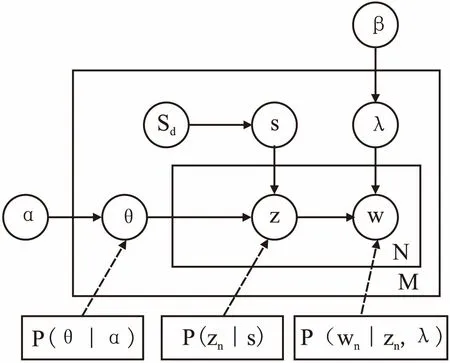
图5 S-LDA模型结构Fig.5 S-LDA model structure
图5对应的S-LDA生成过程包括:
①对每个特征词汇r=1,…,R选择θr~Dirichlet(α)
②对每个主题k=1,…,K选择λk~Dirichlet(β)
③对于每个Web服务s=1,…,S有:给定每个文档的特征语义向量rs;Web服务中每个单词wsi,i=1,…,Vs,选择一个主题:zn~p(zn|θ);选择一个单词:wsi~p(wsi|zn,λ).
所以在给定θ、λ和Sd后, 每个Web服务的条件概率可以通过累加隐变量s和z 得到,则主题下生成单词的联合概率为:
p(w|α,β,θ,λ,Sd)
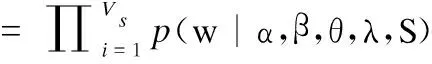
S|α,β,θ,λ,Sd)
k,θ)·p(zsi=k|rs=S,λ)·p(rs=S|Sd))
(5)
公式(5)说明基于DSWSC模型,使用Gibbs抽样得到的模型参数计算每个服务所包含的不同主题概率,如果一个服务包含某个主题的概率越大,则该服务属于该主题的可能性就越大,假设服务Si包含n个主题T1,T2,T3,…Tn,p(Si,Tj)表示服务Si包含的不同主题的概率.
令Web服务Si被分给p(Si,Tj)值最大的主题类簇
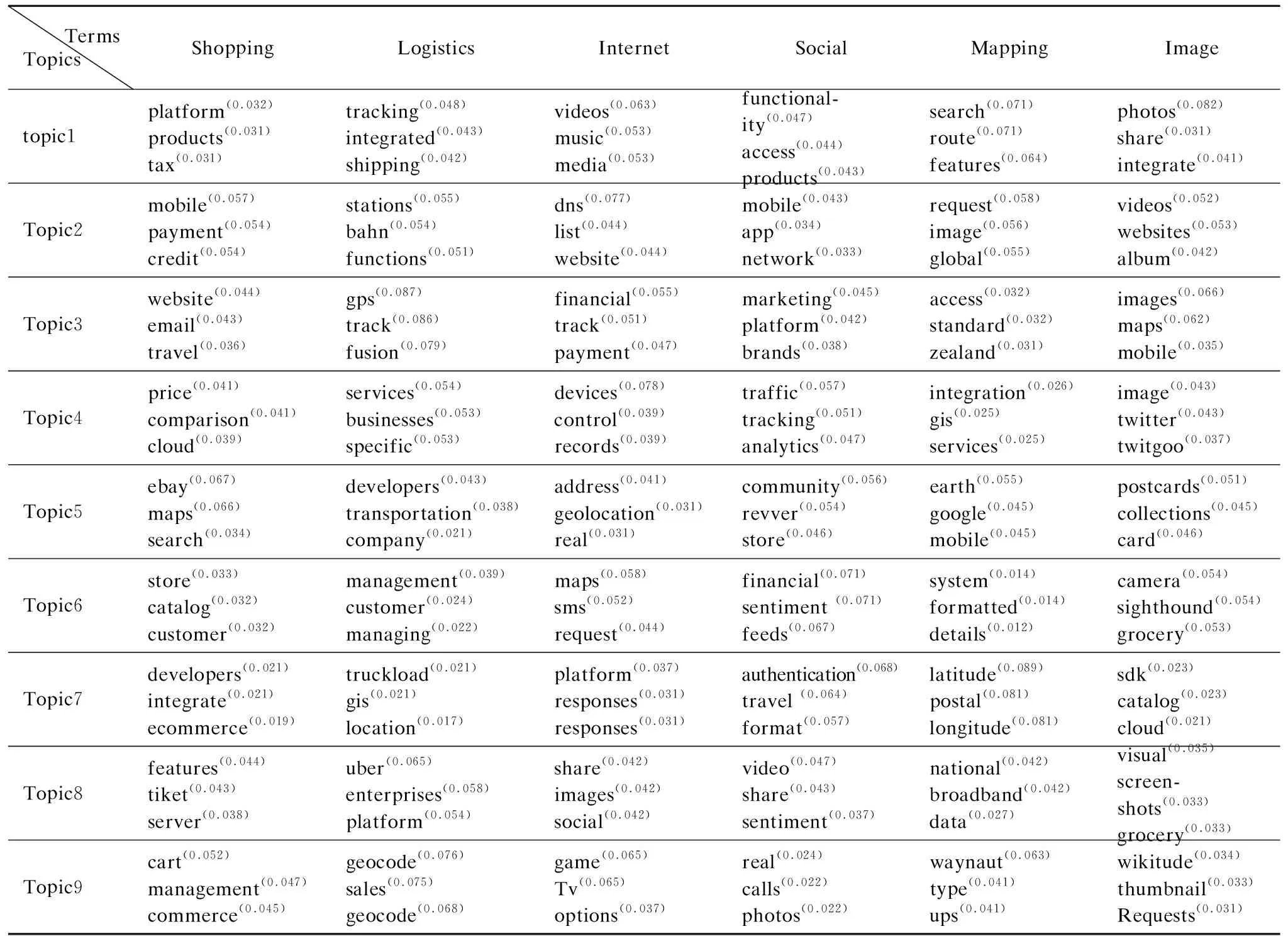
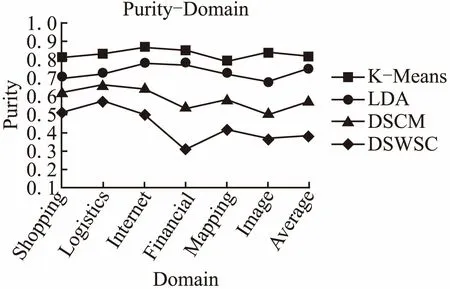
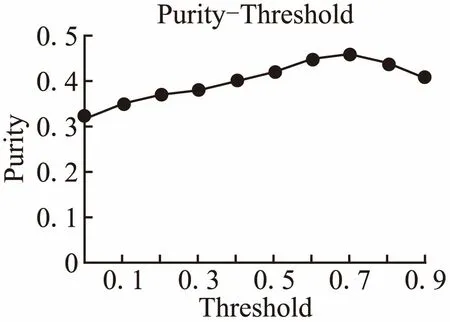
Tmax(Si)=TK∧∀j((j≠k)→p(Si,Tj) (6) 且服务是由词汇组成,所以将公式(5)与公式(6)结合: (7) 其中∑iθi,k∑iλi,k为归一化参数,目的是降低泛化主题的概率,因为泛化主题中包含了缺乏表征的公共词汇,我们需要剔除的这些表征能力差的词汇,得到能准确表征一个Web服务包含某个主题的准确概率, S-LDA算法的描述如算法2所示. 算法2.语义辅助的Web服务聚类方法 输入:Web服务文本集Si,组成文本的单词ws,服务文档总数|SBd|,包含特征词ri的web服务文本数|Bi|,SSi表示特征词Fi和领域的相似度,观察变量特征词汇Sd,s表示从语义词汇列表Sd中选取给定单词相关的语义参数,剔除阈值C(0~1之间百分数),超参数α,β,主题语义参数分布θ,单词-领域相似度矩阵λ,聚类主题数Tn; 输出:聚类结果; 2 FOR EACH termFi∈Sd 3 if(Fi∈Sd(k)&&Fi.SR(Fi,dj)>C) //如果表征度大于剔除阈值C,就剔除该特征词汇 4Sd←Fi// 将Fi加入领域特征集Sd 5 θr~Dirichlet(α)←Sd//剩下的表征词汇作为超参zn的观察值 6wti←λk~Dirichlet(β) //每个主题与词汇的狄里克雷先验分布 7 θ←p(Si,Tj)//服务特征降维得到每个服务与其包含不同主题的概率分布 8 p(w|α,β,θ,λ,Sd)←LDAGibbs(α,β,θ,λ,Sd) //得到服务主题类簇 9Tmax(Si)←parse(p(w|α,β,θ,λ,Sd)) 10 RETURNTmax(Si) 11 END 其中,第1步利用语义对领域词汇进行排序,生成排序词汇表,然后计算其表征度;第2步到第3步对领域词汇的表征度阈值C进行过滤;第4步将过滤好的特征词汇加入特征集;第5步到第6步做超参先验计算;第7步利用特征集Sd对服务进行特征降维,形成本文模型的输入,第8步通过LDA的Gibbs抽样得到每个服务与包含主题的概率分布;第9步将每个服务聚类到其主题分布概率最大的主题类簇. 实验工具为Anaconda2(64-bit)、Spyder,使用系统为Windows 7(64-bit),所有数据都运行在一台IntelCore i7 7700k@4.2GHz主频,GPU GT840M,DDR3 8GB的PC上,程序实现是使用pyhon语言. 表1 服务数量前6位的领域Table1 Top 6 domains that have most services 首先,我们对Web服务数据集进行爬取,一共收集了PWeb网站上来自81个领域,约9600多个服务描述文本.进行服务分类时,当领域服务数较少时,训练时难以得到较高的准确率.因此,我们选择了服务数量最多的6个领域:Shopping、Logistics、Internet、Social、Mapping、Image,本文通过划分领域实验,在服务数量划分为6个领域时,对服务聚类效果最佳. 表1列出了服务数量排名前6的领域分类结果,这6个领域包含1950个服务样本,我们在此数据集的基础上进行聚类实验. 从表2可知,与SVM分类方法相比(如文献[4]),本文方法(语义-决策树)可以得到更多的服务个数,这样就可以提供一定数量的跨领域服务分类样本,其中Shopping服务数为357,Logistics服务数为347,Internet服务数为301,Social服务数为294,Mapping服务数为294,Image服务数为286,但只考虑单个服务只属于一个领域的关键字分类方法,不能很好的契合现实Pweb网站的真实分类情况,我们考虑单个服务跨领域的情况,这样可以减小服务判断的误差. 表2 分类结果对比Table 2 Example of the classification results 本文的方法相似度排序原则是以语义辅助为基础,找出的都是上下文有关联的词汇,因为使用了语义辅助的分类方法,所以能对服务领域进行细致分类,但文献[5]的方法就没有细分“Tools”领域,如对“Tools”分为一类,导致服务领域分类为粗粒度级别.本文对“Tool”服务领域类别采用决策树分类器细分“image”,“management”,“collection”,“compress”,“reservation”,使之成为不可再分的细粒度级别领域. 从表3中可以得到主题-特征词的分布情况,我们完成了对聚类实验在熵(Entropy)、聚类纯度(Purity)、准确率(Precision)、召回率(Recall)和F指标(F-measure)评估工作. (8) 聚类纯度:对于一个聚类i,其聚类纯度为 pui=max(puij),则整个聚类划分的纯度为 (9) 准确率:表示的是预测为正的样本中有多少是真正的正样本,正样本为TP,负样本为FP. (10) 召回率:表示的是样本中的正例有多少被预测正确,正样本为TP,负样本为FN. (11) F指标: 因为P和R指标有时候会出现矛盾的情况,所以需要综合考虑,最常见的方法就是F值. (12) 本章节将DSWSC方法得出的实验数据与其他的三种方法进行了对比,从图6中可以看出,在纯度指标上,本文所提的DSWSC聚类方法在这6个领域的平均纯度为0.83;而DSCM聚类方法平均纯度为0.75;LDA聚类方法平均纯度为0.58;K-Means方法平均纯度为0.38.比DSCM提高了8.1%.聚类纯度值越大,则聚类效果越好,因此,本文方法的聚类效果比现有方法有明显提高. 同样,从图7中可以看出实验结果表明,采取语义辅助的服务特征降维方法可以有效地改进聚类效果. 图6 聚类纯度比较Fig.6 Comparisons of purity 图7 聚类熵比较Fig.7 Comparisons of entropy 本文方法结果优于LDA和DSCM策略的原因在于它们都没有考虑语义的影响,因为同义词广泛分布在Web文本中,所以不同词汇有可能表述的是一个主题.本文利用深度学习word2vec算法解决了该问题,因此,在各项Web服务聚类指标上均得到了提高,如图8所示. 图8 聚类F值比较Fig.8 Comparisons of F-measure 图9 表征度阈值对聚类的影响Fig.9 Influence of the threshold on clustering 图9显示了表征度阈值C的不同取值对服务聚类效果的影响.如图9所示,表征度阈值C能够过滤表征Web服务领域的特征词,当阈值C取70%时,聚类效果达到峰值,之后又会下降,所以本文的表征度阈值选0.7,刚好可以控制筛选出能体现服务特征的词汇. 服务聚类是服务计算研究中的一个重要问题,近年来国内外在这一领域已经开展了大量工作.例如,文献[6]在存储Web服务相关信息的基础上,从服务的接口(输入和输出)和能力(前置和后置条件)两个方面,利用本体概念间的语义推理关系及概念的状态路径等信息进行计算,实施Web服务聚类的方法.文献[7]使用层次Agglomerative算法对功能相似的服务进行聚类,以改进服务发现效率.文献[8]使用K-means算法对服务和需求进行聚类,降低了服务搜索空间.文献[9]挖掘Web文档中词汇间的树状概率层次关系,提出一种以词汇信息分布作为特征标志的聚类算法InfoSigs,实现对Web对象的细粒度聚类.算法构建一个信息传递有向无环图,根据词汇在图中信息分布的集中度赋予其合理的权重,产生代表性的特征向量,来提高聚类结果粒度.文献[10]提出一种基于图论的方法,通过计算待分类服务的相似度矩阵,并通过相似度阈值,逐个提取其中的最大完全子图,且每个子图的节点对应一个聚类. 由于主题模型LDA在文本建模方面的优势,使用LDA进行服务聚类的研究也非常多.例如,文献[11]在各级词频语义区使用Web游离文档检测,然后以中、高频语义区的语义作为文档特征进行文档聚类,并采用文档类别与语义互作用机制对聚类结果进行修正.文献[12]应用大奇异值的维度来描述语义元素之间的共性,并通过采用不同维度来实现文档在不同概念力度下的聚类.文献[13]则直接用LDA算法对WSDL描述文档建立语义层次模型,得到每个主题对应的关键词分布,然后基于主题对Web服务进行检索. 在经过LDA对主题文档进行建模的研究热点之后,人们开始把目光转向LDA结合语义表征的处理方法来寻求技术突破,就目前我们知识所及,主要有如下两篇文章结合了LDA和语义关系做服务聚类和发现,一是文献[13]提出一种自组织的聚类算法(Taxonomic) ,对Web服务进行语义分类组织,来促进服务发现.二是文献[14]提出了一种基于LDA聚类的语义Web服务发现方法.即首先对OWL-S Web服务文档解析,得到文档词汇向量,然后对文档词汇向量进行扩充,使文档语义信息更加丰富,再对文档扩充词汇向量集合建模,并进行训练和推断,得到文档-主题分布,并对Web服务文档聚类,最后通过查找Web服务请求记录,在簇中寻找满足需求的Web服务. 除了以上研究方向外,还有对特定服务描述文本的研究,比如文献[15]提出一种从QoS(quality of service)、Interface 、ServiceName 、Capability等方面进行本体推导并聚类.文献[16]解决了基于传统协同过滤算法的QoS预测,所面临推荐系统中的冷启动和稀疏性问题,然后利用LAC算法对服务聚类. 上述方法也有几点不足: ①大多数Web服务基于功能、流程、QoS等方面进行直接聚类,没有考虑服务是多样性的,描述语言复杂,单一的方法只能解决单一描述的文本. ②没有考虑Web服务的领域特性. ③尽管已经使用了LDA主题文档聚类算法,结合了语义信息,但是并没有给出一个科学通用的自然语言描述的Web服务分析方法,比如领域划分出现的名词混淆和语义关系不明确等. 针对以上问题,本文在服务聚类过程中,利用TF-IDF对自然语言描述的Web服务文档,进行关键词查找,并使用Word2vec算法查找关键词的同义词并生成一个同义词表,然后提出了一种基于S-LDA模型,该模型通过引入语义信息结合概率的方式对服务进行聚类. 我们在原有LDA服务聚类的基础上,引入了Web语义服务聚类方法,第一步设计了一种针对服务描述的方法来表征PWeb上的服务文本,并使用神经网络模型(Word2vec模型)获得服务描述中的同义词表,然后通过表征度阈值对特征词汇筛选,接着用决策树分类器对服务领域分类,第二步使用语义辅助的LDA对各领域的服务进行聚类.实验结果表明,面向领域的Web服务语义聚类效果比原有的DSCM、LDA和K-means聚类效果有所提高. 接下来,我们会从语义层次上更进一步挖掘用户需求信息,根据用户提出的具体查询需求,实现更完善地服务聚类和服务发现.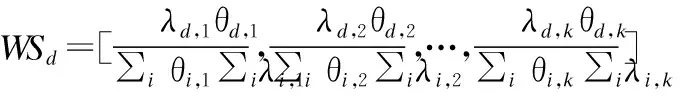
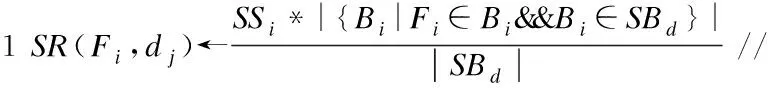
4 实验数据分析

4.1 Web服务领域分类分析

4.2 Web服务聚类评价指标
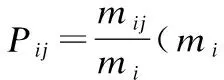
4.3 Web服务聚类结果比较与分析

5 Web服务聚类相关工作
6 总 结
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
电脑爱好者(2017年7期)2017-05-06
互联网天地(2016年1期)2016-05-04
长江学术(2016年4期)2016-03-11
