
基于神经网络的地铁短时客流预测服务
2019-01-24 09:30侯晨煜周艺芳
小型微型计算机系统 2019年1期
侯晨煜 ,孙 晖,周艺芳,曹 斌,范 菁
1(浙江工业大学 计算机科学与技术学院,杭州 310023)2(杭州数梦工场科技有限公司,杭州 310024)
1 引 言
地铁凭借其准时、快速、性价比高等优点逐渐成为城市重要的交通工具.但是由于地铁站空间封闭的特殊性,在地铁站中的乘客容量有限.因此在某些情况下,如:发生突发事件、遭遇恶劣天气或在早晚交通高峰时段、节假日等,客流量在短时间内大规模的增加可能会影响地铁运营和乘客安全.如果能够提供地铁客流预测服务,提前准确预测地铁站的客流情况,地铁工作人员提前做出相关控制措施,则能够有效防止危险的发生并维持地铁秩序.基于上述动机,本文提出一种地铁客流短时预测服务,通过对历史数据的分析,预测未来时刻的地铁客流量,方便地铁工作人员进行地铁流量控制,防止发生安全事故.
地铁由于其准时、快速的特点,乘客在地铁站中的逗留时间相对于公交车、飞机来说非常短,并且地铁一次可容纳乘客较多,所以地铁客流在短时间内会呈现快速变化的趋势.本文主要研究目的是利用神经网络提供地铁短时客流预测服务.不同于日客流量、月客流量或年客流量预测,短时客流预测问题情况更加复杂.在大多数情况下,短时客流预测受许多因素影响,且容易发生突变,呈非线性关系.因此使用非线性的预测方法(主要有:非参数回归模型、神经网络、支持向量机等)效果更佳.本文采用了经典的BP神经网络以及处理时序数据效果极好的递归神经网络来进行地铁短时客流预测.
为了确定神经网络中合适的梯度下降算法和激活函数,本文分别选取了三种梯度下降法和三种激活函数,分别组合并进行实验比较,最终确定效果最好的组合作为神经网络的参数.其中梯度下降算法分别是较简单的SGD、使用同一学习率的Adagrad以及能够自适应学习率的adam算法.激活函数分别是最常用的sigmod函数,tanh函数以及近几年非常受欢迎的relu函数.最后我们通过实验证明了基于adam算法和relu激活函数的BP神经网络以及基于adam算法和tanh激活函数的递归神经网络算法性能最佳.
由于本文采用的数据源为真实地铁客流数据,其存在噪声较大的问题,因此我们在进行预测之前,使用卡尔曼滤波器对其进行去噪平滑处理.
最后,我们通过大量实验证明了BP神经网络和LSTM递归神经网络的最佳参数(包括梯度下降算法和激活函数).另外实验还证明了1、卡尔曼滤波有助于提高预测准确度.2、BP神经网络和RNN神经网络的预测效果相差不大.
本文的贡献主要总结如下:
1)使用BP神经网络和RNN神经网络提供地铁短时客流预测服务.
2)利用卡尔曼滤波消除原始数据的噪声并提高预测准确率.
3)通过实验证明了基于adam算法和relu激活函数的BP神经网络与基于adam算法和tanh激活函数的RNN神经网络效果最佳,两者在预测效果上相差不大.
2 神经网络
在这一小节中,我们首先介绍一些神经网络的知识,包括神经元、BP神经网络、基于梯度下降法的反馈原理以及递归神经网络.
2.1 神经元
神经元是神经网络中最基本的成分.在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元的电位;如果某神经元的电位超过了一个阈值,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质.

图1 神经元示意图Fig.1 Structure of a neutral cell
图1展示了经典的M-P神经元模型.神经元接收来自n个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将于神经元的阈值进行比较,再通过“激活函数”来产生神经元的输出.
2.2 BP神经网络
BP神经网络是指用BP(BackPropagation,误差逆传播)算法训练的多层前馈神经网络.其一般具备3层或3层以上神经元的神经网络,如图2所示.包括1层输出层、隐藏层(中间层)和1层输入层.上下层实现的是全连接,产生的信号向前传送,反馈的误差信号逆向传播.隐藏层可以有单层,亦可以为多层,最简单的BP网络的传播激活函数一般使用sigmoid函数.学者认为当神经网络的隐藏层神经元足够多时,就可以以任何精度逼近任何一个有限维的函数.对于每个训练样例,BP算法会先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果.然后计算输出层的误差,再将误差逆向传播至隐层神经元,最后根据隐层神经元的误差来对连接权重和阈值进行调整.BP神经网络不断进行迭代,直到该网络输出误差缩小到阈值以下或进行到预先设定的迭代次数方可停止.
2.3 反馈原理
BP神经网络基于梯度下降策略,以目标的负梯度方向对连接权重和神经元阈值进行调整.梯度下降的大致思路如下:随机选择一个点,从该点出发沿着该点的导数最大值的负方向前进,每次前进η的步长.到达新的点后,重复上述步骤,则可以以最快的速度寻找到最值.但是,基本的梯度下降算法在实际应用中还存在较多的缺陷,如:当η设置过小时,收敛速度过慢,计算量大;当η设置过大时,又会产生震荡;有时还会收敛到局部最小.
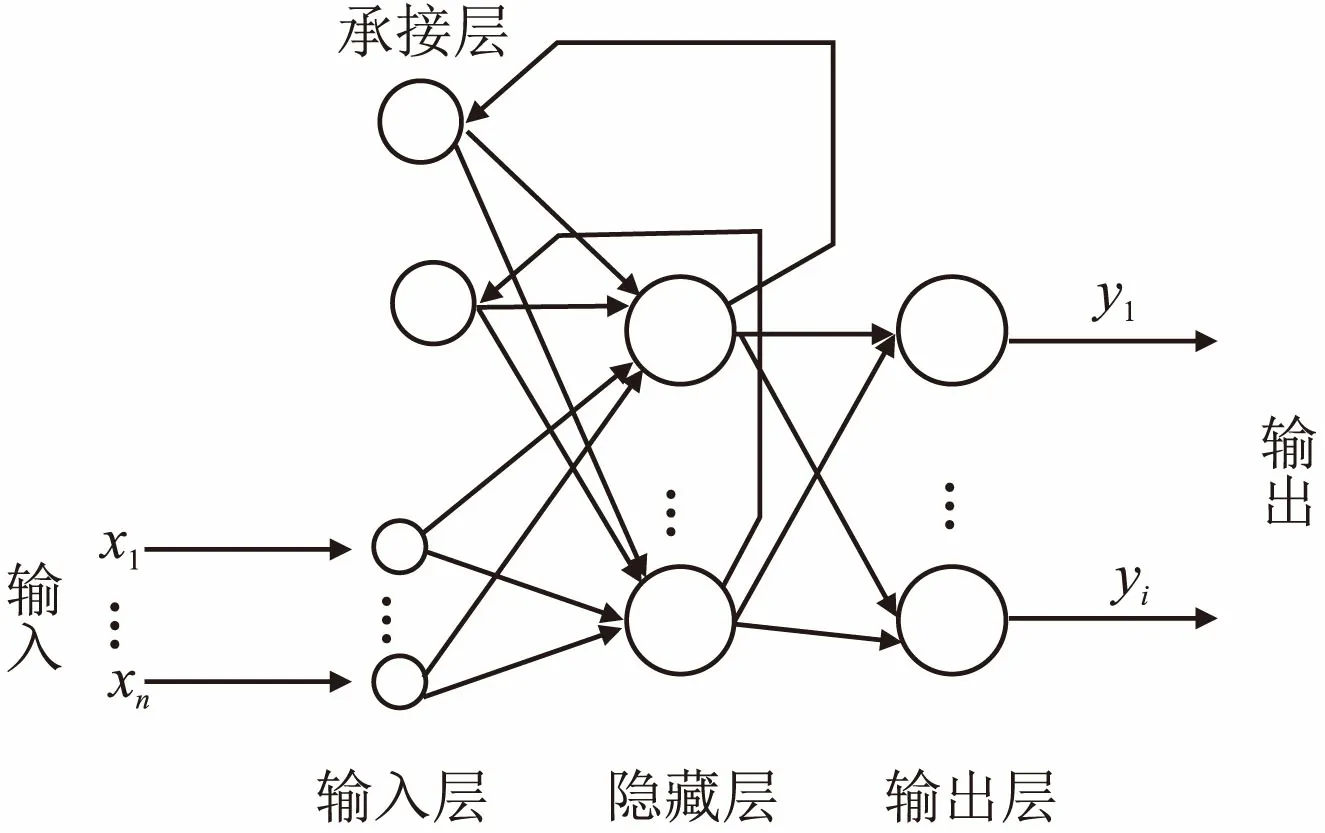
图3 RNN神经网络示意图Fig.3 Structure of the RNN
2.4 递归神经网络
与前馈神经网络不同,递归神经网络允许网络中出现环形结构,从而可让一些神经元的输出反馈回来作为输入信号.这样的结构与信息反馈过程,使得网络在t时刻的输出状态不仅与t时刻的输入有关,还与t-1时刻的网络状态有关,从而能处理与时间有关的动态变化.
观察图3可知,除基本结构的隐藏层外,递归神经网络还具有一个“特别的隐藏层”,称为承接层.该层从隐藏层神经元的输出接收到反馈信号.该信号通过处理后,前向传递给隐藏层作为输入,但在时间上有一定的延迟.递归神经网络的这种构造使得它不仅可以识别和产生空间模型,还能辨认和产生时间模式[1].
2.5 LSTM长短时记忆单元的递归神经网络
虽然递归神经网络在解决时序问题上的效果更好,但是仍存在一定缺陷.具体缺陷在于它的递归机制和反向传播算法.当递归次数较多时,若第一次输入的信息很重要,但是由于递归多次以后(即与权重进行累乘之后)极易出现梯度爆炸(权重大于1)和梯度消失(权重小于1)[2],导致训练失败.加入LSTM长短时记忆单元可以有效解决递归网络带来的梯度消失和梯度爆炸问题.
LSTM层与普通递归神经网络的隐藏层相比多出了三个控制器,(输入控制、输出控制、和遗忘控制),图4是LSTM的内部结构.在训练的过程中,信号不仅通过输入控制和输出控制,而且要经过遗忘控制单元.在这个单元中,LSTM会根据以往的训练反馈对某些信息进行遗忘(即不对权重进行改变),同时选取一定的神经元进行权重更新.LSTM把原本RNN的单元改造成一个叫做CEC的部件,这个部件保证了误差将以常数的形式在网络中流动,并在此基础上添加输入门和输出门来使模型变得非线性.同时还能调整不同时序的输出对模型的影响,因此能够有效解决RNN的梯度爆炸和梯度消失问题.
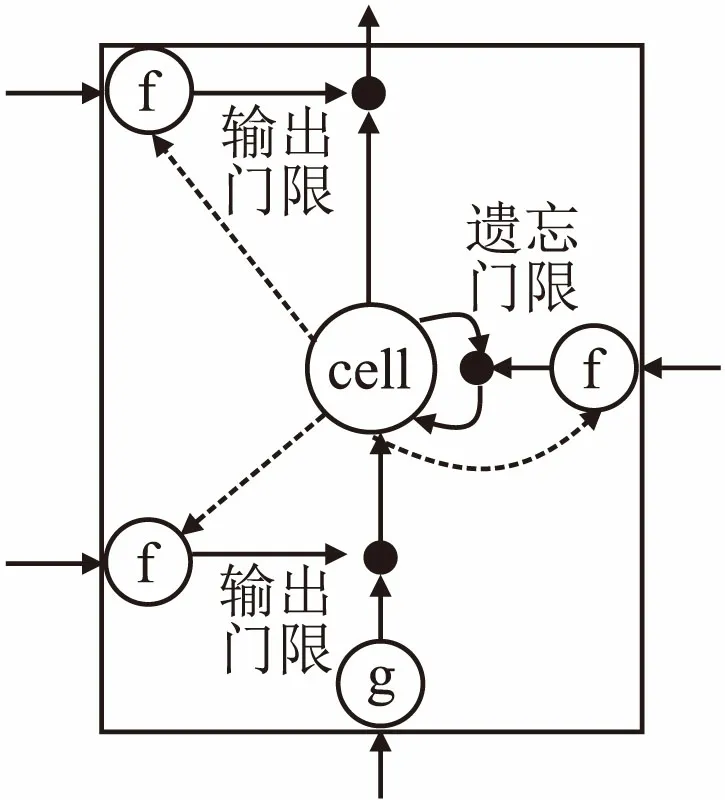
图4 LSTM单元示意图Fig.4 Structure of the LSTM cell
LSTM将信息存放在递归网络正常信息流之外的门控单元中.这些单元可以存储、写入或读取信息,就像计算机内存中的数据一样.单元通过门的开关判定存储哪些信息,以及何时允许读取、写入或清除信息.但与计算机中的数字式存储器不同的是,这些门是模拟的,包含输出范围全部在0~1之间的sigmoid函数的逐元素相乘操作.相比数字式存储,模拟值的优点是可微分,因此适合反向传播.
这些门依据接收到的信号而开关,而且与神经网络的节点类似,它们会用自有的权重集对信息进行筛选,根据其强度和导入内容决定是否允许信息通过.这些权重就像调制输入和隐藏状态的权重一样,会通过递归网络的学习过程进行调整.也就是说,记忆单元会通过猜测、误差反向传播、用梯度下降调整权重的迭代过程学习何时允许数据进入、离开或被删除.
3 地铁短时客流预测算法设计
3.1 参数设定
由于现阶段神经网络的参数选择没有固定实施标准,并且是否能够选择合适的参数对于神经网络的预测精确度有极大的影响,因此参数选择问题受到了学者们的极大重视.大多数情况下,研究者仅能通过经验或者借鉴相似问题的参数选择方案.然而本文问题的独特性使得神经网络的参数选取异常困难,因此本文在借鉴其他论文的经验后,选取一定的参数进行实验和验证,找出最适合的参数.
3.1.1 激活函数
激活函数是一个神经元中输入输出的映射函数(如图4中的f).关于激活函数的选取,目前没有统一的定论,实践过程中更多的还是结合实际情况考虑.传统的BP神经网络和递归神经网络使用的激活函数为Sigmod函数.为了优化神经网络性能,如解决梯度消失问题,研究人员在激活函数方面提出了很多改进方法.Sigmod函数和tanh函数因其求导容易计算速度快,被普遍用于BP神经网络,但是他们都存在软饱和性,因此容易出现梯度消失问题.Relu函数在近几年非常受欢迎,其有效缓解了梯度消失问题同时在SGD中能够快速收敛,因此越来越多被证明可用于神经网络[3].同时Le[4]也在2015年提出relu和LSTM有相当的效果.
3.1.2 评价函数
在训练好预测模型后如何评判该模型的性能也十分重要.与分类问题不同,回归问题中的预测值与真实值并不存在性质相同的关系,因此不能使用准确率来评判回归模型的性能.但是却可以对预测值和真实值进行量值上的比较,本文采用平均绝对误差(MAE)作为评价函数.MAE值越小,模型效果越好.
MAE(Mean absolute error)平均绝对误差:
其中fi为实际值,yi为预测值,模型总共预测N条记录的值,所以最终需要取平均.
3.1.3 其他参数
本文仅对以上几种激活函数和梯度下降算法进行了对比实验,神经网络中还有很多决定神经网络性能的参数,本文使用学界一般使用的参数调整办法,设置4层BP神经网络,假设有n个输入,则神经元节点个数分别为(0.75n,0.752n,0.753n,1).递归神经网络的隐藏层神经元节点个数为0.75n.训练周期epochs设定为50,批含量设定为1.损失函数与测量标准相同,均使用平均绝对误差.
3.2 特征选择
综合考虑地铁客流分布和预测效果的现实意义,本文以1小时为时间粒度,统计每个小时内的购票数量作为该小时内的客流量.我们选取24小时作为时间窗口大小,对于要预测的时刻,把该时刻之前24小时的客流量分成24维特征,作为神经网络训练的输入.
3.3 数据预处理
由于训练模型的数据采用的是实际数据,可能会存在一些噪声点,即偏离正常范围(统计学中的置信区间)较远的信息点.这些点以统计学的理论来说在真实情况中是小概率事件,因此若使用这些噪声点作为训练数据,就可能导致神经网络在判断趋势时出现判断偏差,进而引起神经网络训练失败.所以,在训练预测模型前往往需要对数据源进行去噪处理,学界一般使用拉以达准则进行去噪处理,其基本思想是以给定的置信概率(如99.7%)为标准,此时若待测点的标准差大于标准偏差的三倍(不在置信区间内),就认为它不属于随机误差,而是具有粗大误差的异常值,需要将其从测量数据中删除.
由于本文使用的是时序数据,数据之间具有时间上下文的关联性,因此将某条数据从中删除是不合理的,并且拉以达准则假定系统状态恒定,这在现实情况中也是不合理的.卡尔曼滤波器作为一种常见低通滤波器在信号处理中被广泛应用,设定不同维度的均方误差矩阵就可以适应动态时变系统,因此更适合用于本算法.
3.4 算法步骤
地铁客流预测算法主要流程如图5所示.算法包含如下步骤:1)首先对历史数据进行预处理,提取有效信息,并且对数据进行格式化:按照预设的时间间隔(以每小时为粒度)构建时间客流序列,并且人工设置某些参数;2)特征提取:将预处理后的数据源和进行特征提取,构建特征矩阵;3)将特征矩阵通过卡尔曼滤波器进行校正和精确预测调优,降低噪声的影响效果;4)将滤波后的特征矩阵分成训练集和测试集,将训练集输入到人工神经网络中进行预测模型训练;5)将训练好的模型使用测试集进行性能评估;6)根据单一模型的预测和评估结果,选择最优模型作为输出.
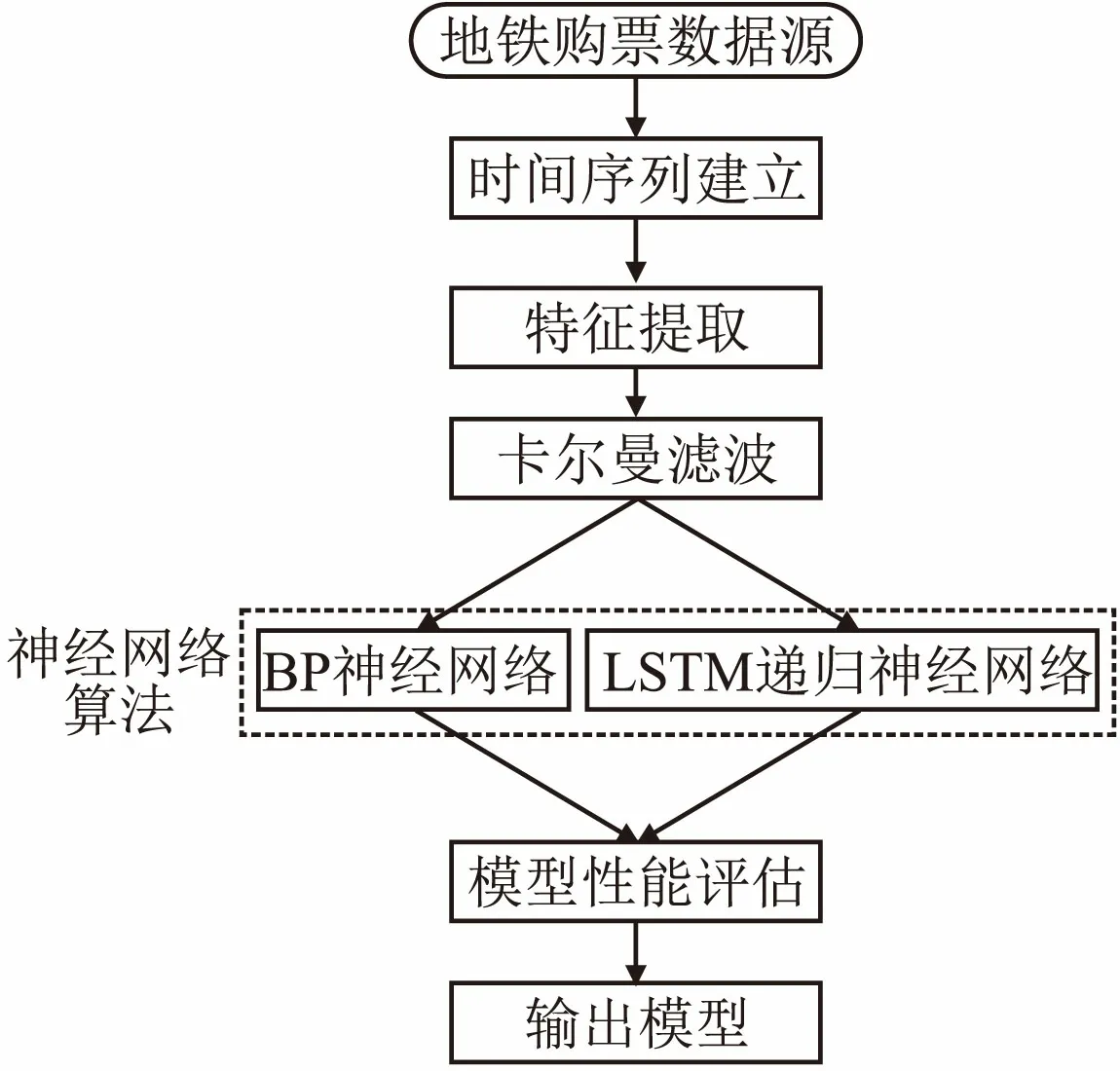
图5 算法结构图Fig.5 Structure of our algorithm
图6展示了BP神经网络的结构,由于输入值挑选过去24小时的人数序列,因此特征个数为24,则输入神经元个数为24.最后神经网络的输出值为当前预测时刻的人数,因此输出层神经元个数为1.本文设置共设置了3层隐藏层,其中隐藏层的神经元个数为0.75n,其中n为该隐藏层输入节点个数,所以如图7所示第一层隐藏层的神经元个数(即输出)为18,第二层隐藏层包含13个神经元,第三层隐藏层包含9个神经元.另外,除输出层固定使用sigmod激活函数外,其余3层隐藏层的激活函数采用通过对比实验来确定.
LSTM神经网络结构比较简单,仅使用一层隐藏层LSTM层,和一层输入层以及输出层,其中LSTM层的隐藏层的神经元个数为18.与一般全连接层不同的是LSTM递归层的输入是3D张量,它包含输入集,时间步长和输入集特征数,此处假定时间步长为1进行实验.与BP神经网络相同,输出层使用SIGMOID激活函数,LSTM层使用对照组进行实验.
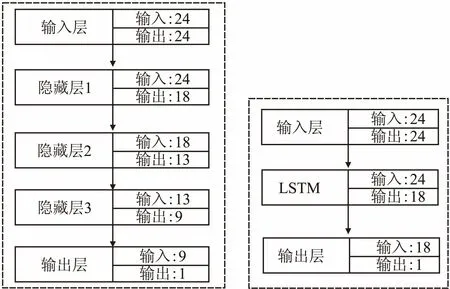
图6 BP神经网络流程Fig.6 BP network process图7 LSTM的RNN神经网络流程Fig.7 LSTM network process
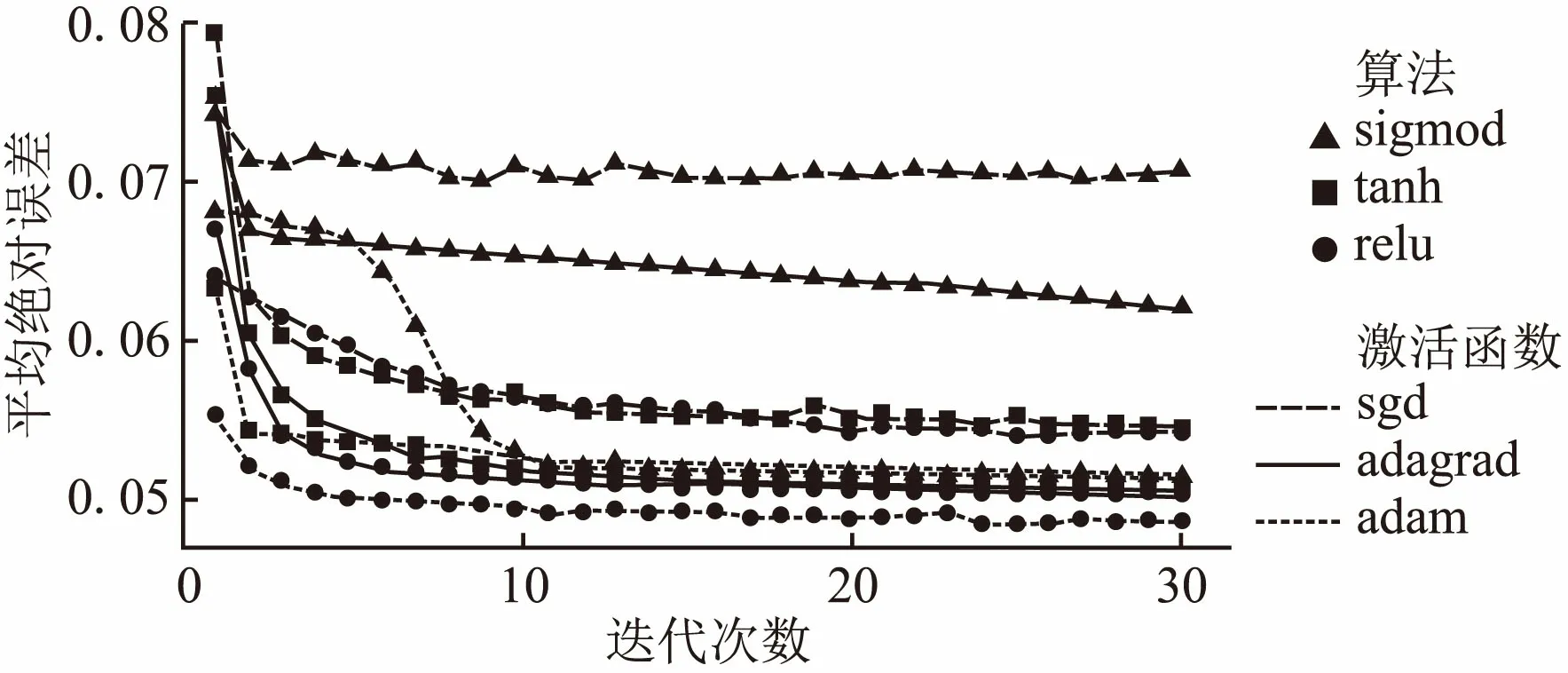
图8 不同BP神经网络比较Fig.8 Comparison of different BP neutral networks
4 实 验
4.1 实验数据
本次实验所使用的数据来自杭州地铁公司提供的杭州某线路购票数据,时间跨度为2017.2.2到2017.4.1日.数据包括起点站名称、起点站ID、终点站名称、终点站ID、购票时间、购票数量、购票金额、跨站个数以及支付方式等信息.我们提取其中起点站名称、购票数量以及购票时间三个信息,从而计算每个站点的客流量.因为用户在乘坐地铁时存在诸多不确定性,无法较为准确地估计用户到站时间,所以我们不把用户到达终点站时作为流量进行计数.实验数据被平均分成五份,在每次实验时,把其中四份作为训练集,另外一份作为测试集,从而完成交叉实验.
4.2 神经网络参数确定
首先为了确定最适合两种神经网络的参数,我们采用控制变量法对3种激活函数(relu、sigmoid、tanh)和3种优化梯度下降算法(普通SGD、adagrad、adam)进行对照实验,并选择30次迭代次数的作为正式实验训练周期.
观察图8实验结果可以发现,所有函数的收敛速度不同,且最终达到的收敛效果也不一样.对于不同激活函数(图中不同点),relu函数(实心圆)和tanh函数(实心正方形)的平均绝对误差更低,在效果上明显优于sigmoid函数(实心三角形),其中relu函数的效果更好;对于梯度下降算法(图中不同线段),在激活函数相同的前提下,sgd算法(长虚线)的平均绝对误差是最大的,而adam算法(短虚线)和adagrad算法(实线)的效果相对较好.其中adam算法能够到达更低的平均绝对误差.综上,对于BP神经网络来说,a-dam算法和relu函数所达到的预测效果更好.
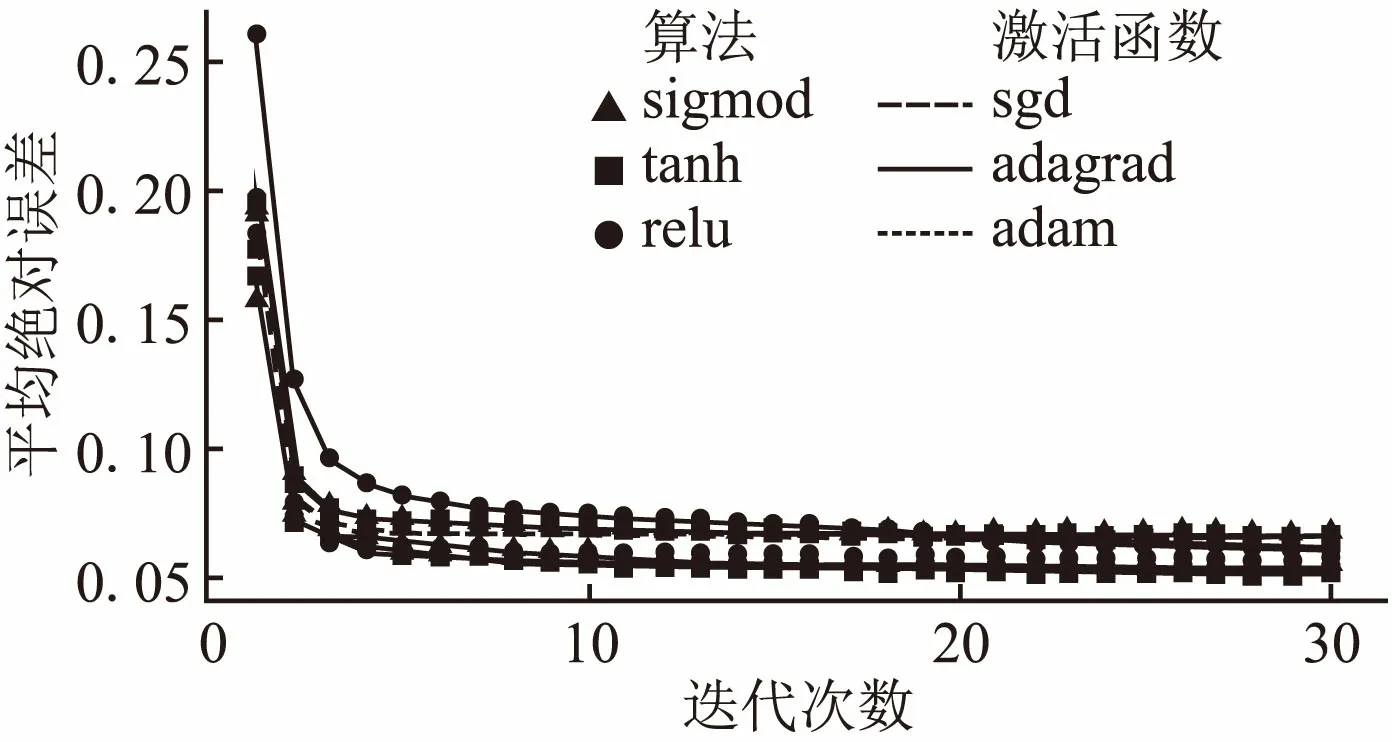
图9 不同LSTM递归神经网络比较Fig.9 Comparison of different recurrent neutral networks
观察图9的实验结果,我们发现不同算法和激活函数组合的LSTM神经网络都呈现出快速收敛的趋势,在达到20次迭代时基本都达到了收敛状态.这是因为LSTM神经网络不仅能够利用上一次的输出结果作为新的输入进行计算,同时LSTM神经元中的遗忘阀门能够将未达到阈值的输出结果进行遗忘.这样的好处是能够实现重要的早期序列对最终结果的影响,同时消除不重要的序列的影响.从图中我们还可以看到,在保持梯度下降算法不变的情况下,三种激活函数的效果互有好坏.而比较不同梯度下降算法的效果时,我们发现三条基于adagrad算法的神经网络的误差曲线(实线表示)位于最高,这说明adagrad算法的性能最差.而基于adam算法的神经网络的误差曲线(短虚线表示)位于最低,说明adam算法最适合于LSTM递归神经网络.而sgd算法效果居中.最终,我们根据图中最低的一条曲线确定LSTM递归神经网络使用adam算法以及tanh函数的效果最好.
4.3 卡尔曼滤波效果
这一小节,我们进行了大量实验考察卡尔曼滤波对预测效果的影响.我们共进行了2组实验:1、基于BP神经网络(图10(a)).2、基于LST递归神经网络(图10(b)).每组实验分别在有卡尔曼滤波和无卡尔曼滤波的情况下进行,并且每组实验进行5次交叉实验,最终结果如图10所示.由图10
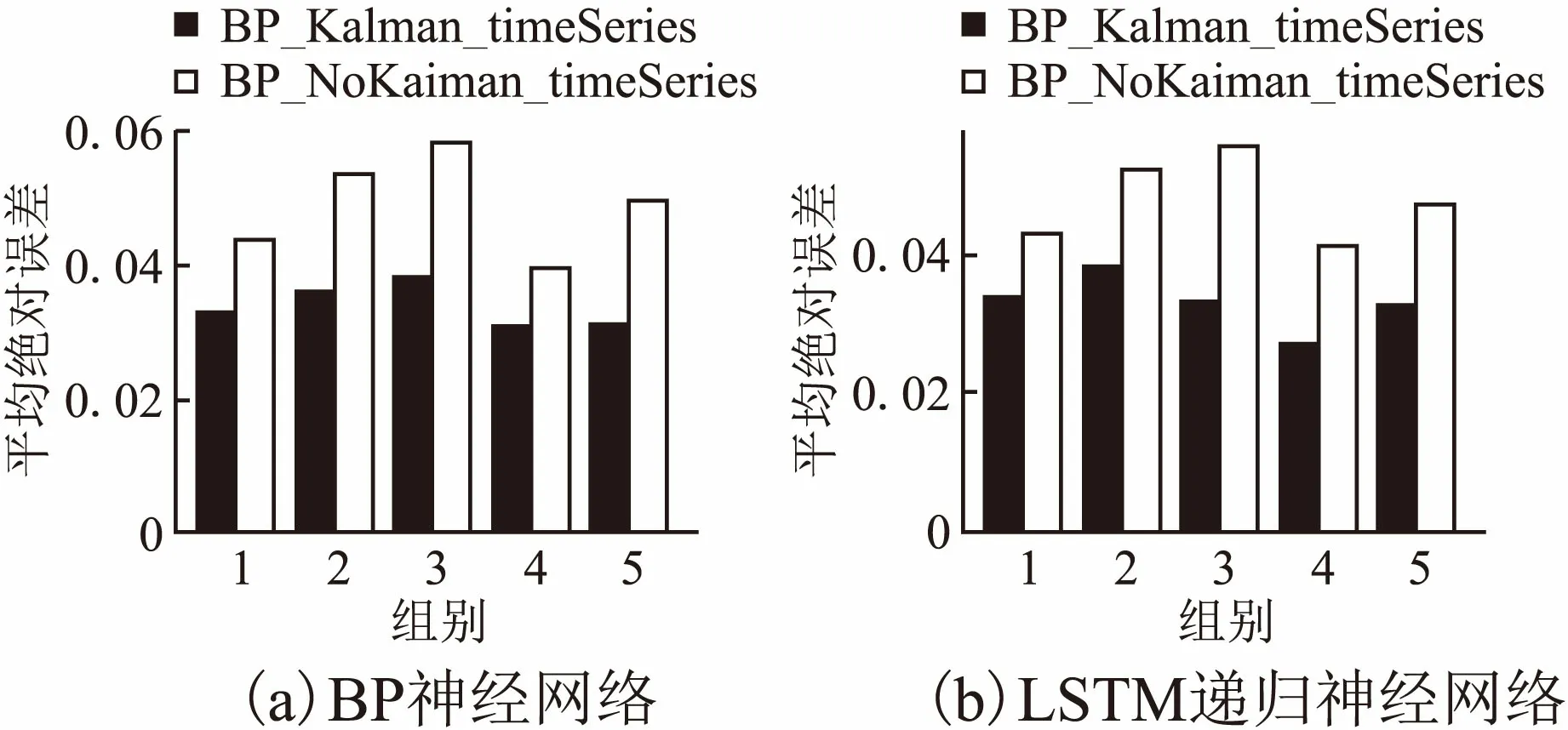
图10 卡尔曼滤波性能比较Fig.10 Efficiency of Kalman filtering
可知,算法经过卡尔曼滤波去除噪声之后的MAE明显低于未经卡尔曼滤波过滤的MAE,这说明卡尔曼滤波有助于提高算法准确度.
4.4 神经网络比较
这一小节,我们比较两种神经网络的预测效果.我们同样进行了2组实验:
1)无卡尔曼滤实验(图11(a)所示).
2)有卡尔曼滤波实验(图11(b)所示).
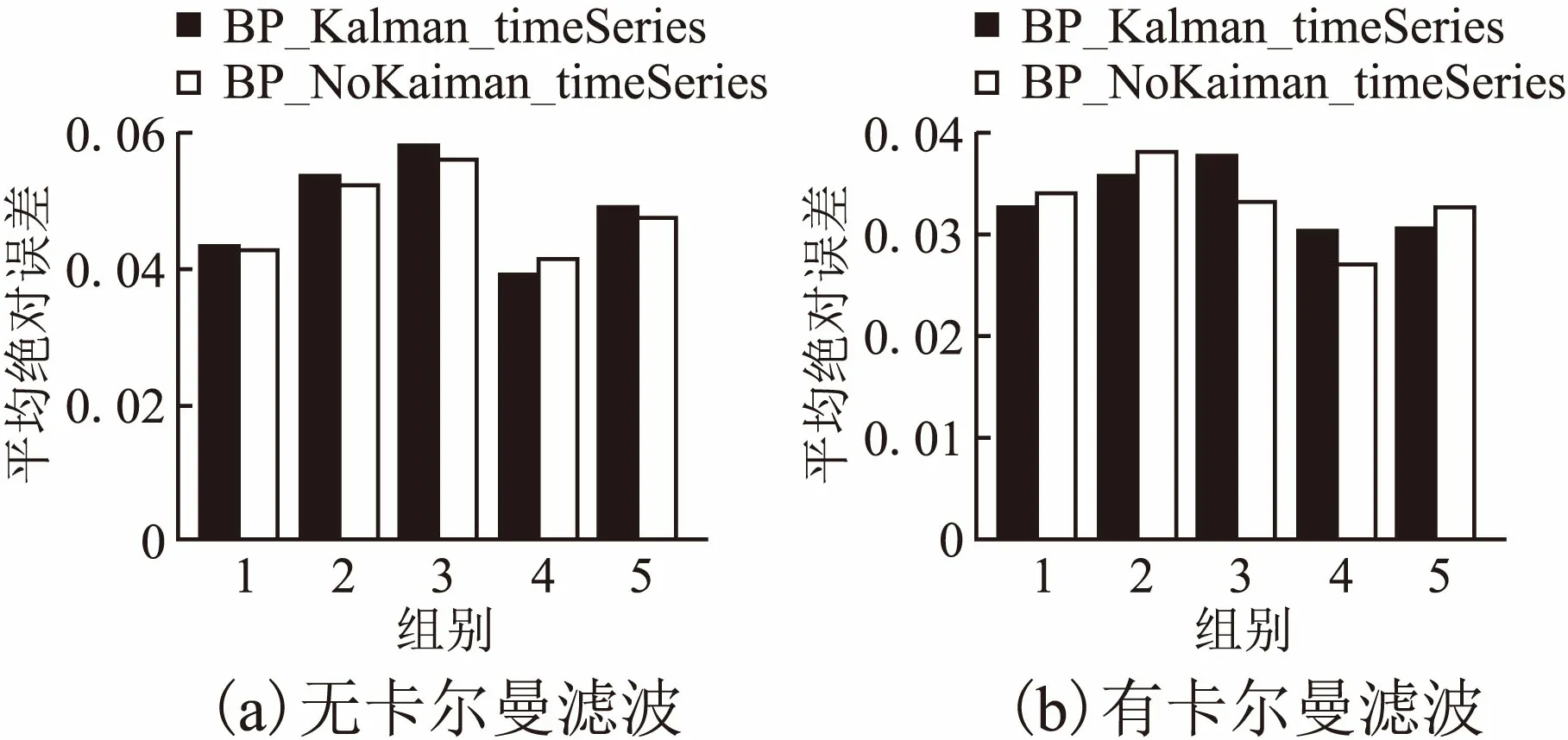
图11 神经网络比较Fig.11 Comparison of neutral networks
从图11两幅图中可以看到,BP神经网络与LSTM递归神经网络MAE差距不大,且有时BP神经网络更优,有时递归神经网络效果更优,这说明BP神经网络与LSTM递归神经网络在客流预测模型训练上的效果相当.这个现象可能与BP神经网络使用了relu激活函数有关,有学者指出它的效果可以媲美LSTM单元.
5 相关工作
学界关于预测交通流量的线性预测方法主要有以下几种措施:历史平均预测模型、时间序列预测模型和卡尔曼滤波模型等.1993年Kaysi提出的LISB系统[5]使用的是历史平均预测方法,此算法是将历史数据与当前数据进行加权组合,其缺点在于权重确定过程费时费力,无法反映非线性预测流的随机性,因此对突发事件的客流预测效果不好.
时间序列预测模型是将历史客流按照一定的时间间隔量化为一个时间序列,同时分析这个时间序列的变动特征来预测将来的发展趋势.其中被应用的最广泛的一种是季节性时间序列模型ARIMA[6,7],它相比于其他方法考虑到客流量随时间变化的波动性,且可定量化评估外界因素对其造成的影响[8],但是其假定时间滞后,变量之间是线性关系,因此它可能也并不适用于测量非线性结构[9],并且其数据可能遗漏,使得模型的精度降低.客流预测问题情况复杂,多数情况下存在多属性呈非线性关系,因此使用非线性的预测方法效果更佳.非线性的预测办法通常具备较高的预测准确度,但同时带来的问题是计算的复杂性大,当数据量巨大时所需的开销大,因此学界提出的该方法主要用于进行小规模的预测上,在高并发云计算蓬勃发展的今天这些方法将被广泛使用.主要有:非参数回归模型、神经网络、支持向量机、灰色理论和马尔科夫链等[10-13].
非参数回归模型[14]是一种非参数方法,该策略对非线性的动态系统更加合适,它可根据充足的历史数据,无需先验信息,寻觅历史数据中与当前时刻类似的“近邻”,并用这些“近邻”预测下一时刻值[15].因而,该办法针对特殊事件的预测效果要比参数建模精细且准确[16].
神经网络也属于非线性方法,是一种模仿人脑构造解决问题的系统策略.它以大量神经元处理单元连接成拓扑结构,比传统的预测方法更适合变化较为复杂、非线性的条件,它对任意方法都可以进行映射,具有良好的自适应性,因此被频繁作为建模方法[17].目前学界已广泛运用的神经网络预测模型包括BP神经网络、时延递归神经网络、径向基神经网络等.例如,Deng等[18]使用BP神经网络模型对公路客流量进行了很好的预测;Hussein Dia等[19]使用时延递归神经网络预测未来5分钟的公路流量精确性达到90%以上;Xiao等[20]也证明RBF神经网络在预测高速公路短期交通流量是可行的.
6 总 结
本文利用卡尔曼滤波,结合神经网络算法,提供了一种准确度较高的地铁客流短时预测服务.该服务利用预测时刻的前24小时客流量作为输入,通过卡尔曼滤波对数据进行过滤,再用BP神经网络和LSTM递归神经网络进行预测,最终预测准确率高达95%左右.本文还通过控制变量法进行多组实验,证明卡尔曼滤波对预测起到积极作用,并且基于adam算法和relu激活函数的BP神经网络与基于adam算法和tanh激活函数的LSTM递归神经网络在预测效果上几乎相近.
本文后续工作将从以下几个方面展开:
1)考虑时间衰减效应.在之后工作中,对于预测时刻的前24小时客流量特征,进行时间衰减考虑,即较远时刻的客流量的影响因子降低,较近时刻的客流量的影响因子提高,并通过实验证明其有效性.
2)考虑其他例如:天气、节假日、早晚高峰等复杂特征.
猜你喜欢
环球时报(2022-12-12)2022-12-12
中国设备工程(2022年19期)2022-10-12
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
北京航空航天大学学报(2021年7期)2021-08-13
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2019年23期)2019-02-23
北京航空航天大学学报(2017年9期)2017-12-18
