
大数据下的销售异常发现与定位模型研究
2019-01-24 09:35刘菊君杨先圣
小型微型计算机系统 2019年1期
刘菊君, 姜 磊, 彭 雄,周 倩,杨先圣
1(湖南科技大学 计算机科学与工程学院,湖南 湘潭 411201)2 (步步高商业连锁股份有限公司,湖南 湘潭 411201)
1 引 言
在信息时代下,信息对企业在日趋激烈的竞争中脱颖而出发挥了关键作用.对企业来讲,数据就是信息.因此收集、管理、分析数据并将其转换成准确有利的信息辅助决策从而获取高额利润并抢占市场逐渐步入企业决策者的视野.零售业数据庞大,因此及时发现异常、提高准确性并进行异常的定位尤为重要.
由于销售数据受到外界因素的影响,比如节日、促销等,某些销售数据所具有的属性并不完全一致,从而致使其失去可比性,无法直接进行数据分析或使其准确率降低.因此本文提出的基于权重处理销售数据的异常挖掘模型,首先解决了数据可比性的问题,然后再进行离群点检测实现异常发现,最后实施对异常数据的定位,与以往直接进行数据分析、仅挖掘异常数据的方法相比具有创新和实用意义.
本文在以步步高商业连锁股份有限公司在长沙地区所有销售数据为挖掘对象,将此异常挖掘模型结合Hadoop[1]云计算平台的Spark[1]框架实际应用于该超市后获得了相关专业人员与管理人员的高度认可.本文与以往异常检测方法相比优势在于:一方面,本文中的挖掘模型利用各种商业活动产生的运营数据分析出基于事实和可行性的结论,取代以往财务人员分析各种财务报表得出结论的方式,降低了采取人力根据经验分析数据报表可能出现的错误与不确定性,有利于企业管理层与决策层从更理性与清晰的角度作出商业决策,抓住商业机遇,从而提高企业利润与市场份额.另一方面,数据可比性得到有效解决,提高了准确性.最后该模型不仅可实现异常的判断,还提出从不同角度分析销售数据,实现异常的定位,从而实现责任到人,在这种情况下,管理层可迅速、准确的找到症结所在并为销售决策提供经验,对公司意义重大.
2 相关工作
零售业相关销售数据量庞大,单机处理海量销售数据效率过低,在大数据平台下处理数据成为必然.Apache Spark[2,3]是一个类Hadoop MapReduce[4]的分布式处理框架,具有MapReduce所具有的优点,但不同的是Spark计算产生的中间输出与结果可保存在内存中,不再需要读写HDFS[1],因此 Spark 更适用于数据挖掘与机器学习等需要迭代的算法.当前 Spark 机器学习算法[5]广泛应用在聚类分析、分类、回归分析等领域[6-10].由此Apache Spark成为该模型各核心算法实现的有利工具.
目前国内外主流的离群点检测方法基本分为5 类:基于分布的、基于深度的、基于聚类的、基于距离的和基于密度的[11].基于分布的方法根据分布模型采用不一致性检验来确定离群点[12,13],该方法对模型的依赖度较高;基于深度的方法给每个数据对象分配一个深度值, 将数据对象按分配的深度值映射到二维空间的相应层上, 处在浅层上的数据对象比深层上的更有可能是离群点[14,15],分配合适的深度值是采用此方法必须解决的问题;基于聚类的算法将数据集分成若干簇, 不属于任何簇的数据点就是离群点[16],难题在于簇的大小与个数很难确定,比较典型的算法为DBSCAN[17];基于距离的方法假设数据样本中的某个点在距离上明显远离大部分点则会被视为离群点,此方法的缺点在于必须事先确定距离等相关参数,另外,时间复杂度较高,不适用于大数据集;基于密度的方法是基于距离方法的拓展,离群点的密度与周边正常点的密度差别较大,其同样具有时间复杂度的问题且密度较难确定.销售数据均为一个时间对应一个销售值,因此在处理销售数据时只需考虑销售金额这一维度,不需将时间维度考虑在内,从而上述离群点检测方法中距离、密度等标准在处理销售数据时并不适用,且不同销售数据遵循不同规律,较难找到统一的模型.普遍的离群点检测方法均在所有点具有同样属性,即具有可比性的前提下进行试验,而销售数据不满足该前提,因此上述离群点检测方法并不适用于销售数据的异常挖掘且无法应用于现实场景.而模型中采用的针对权重曲线的离群点检测方法适用于普遍销售数据实现异常发现,另外异常定位的实现也使得该模型具有现实意义.该模型解决了可比性、需寻找合适模型、设定相关参数、甚至算法无效的难题.
3 销售数据异常发现与定位模型
企业数据量庞大,因此该异常发现与定位模型(Anomaly Detecting and Locating Model, ADLM)在Spark平台下具体实现,分为两个部分:异常发现;异常定位.异常发现通过权重曲线和异常判断挖掘出所有销售异常数据,而由于连锁超市经营的门店、大类众多,互相影响,仅从地区总销售判断异常过于片面与粗略,会导致错漏某些细节异常,比如某一个月从地区上表现为正常,但其中某些大类或门店也可能存在异常,只是这些异常正好被其余大类或门店弥补,从而致使整体正常,因此实现准确的异常定位需要从四个角度进行上述的异常发现并得到结果,分别为总销售、大类级别总销售、门店级别总销售、门店-大类销售.将四个角度的分析有机结合即可实现责任到人,四个角度分别对应的职位或人员为地区总经理或管理者、大类经理、店长、店内大类主管.
3.1 异常发现
3.1.1 权重曲线
权重曲线与原销售数据曲线相比具有的特征更清晰、更详细、更有说服力,对洞悉某些营运现象更有利.对零售业来讲,销售额是一个反映运营现象的重要指标,以得到某个企业月销售额的权重曲线为例,得到权重曲线主要步骤如下:
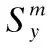
(1)
2)计算m月的月权重指数Im.将12个月份中加权和最小的月权重指数设为1.0,其余月份的月权重指数表示为:
(2)
3)计算所有年份每一年中的每个月份的单位权重(月权重值),月权重值表示为:
(3)
3.1.2 异常判断
将销售曲线转换成权重曲线,使得数据之间具有可比性,平衡了节假日等因素的影响.在对转换后的权重曲线进行离群点的检测时,异常判断的方法类似于盒图最小(最大)观测值这一思想.该检测方法的核心思想是首先计算出对应数据的平均值,然后在平均值的基础上分别以同样的倍数增加和减少得到两个阈值,超出阈值的则为离群点即异常数据.在得到权重曲线后异常判断的步骤如下:
1)计算平均月权重值A.
2)设置阈值Tmin和Tmax.阈值计算如公式(4)和公式(5)所示.
Tmin=(1-β)A
(4)
Tmax=(1+β)A
(5)
3)参数β的确定.β从0开始等差(差值按需求自行设定)递增,当离群点的个数与总个数之比大于设定的离群率(离群率根据需求设定)时停止递增,β取值为满足条件的最大值.
4)若月权重值超出阈值范围上限,则该月为较好异常,标记为1;若月权重值超出阈值范围下限,则该月为较差异常,标记为-1;若月权重值在阈值范围值内,则该月销售正常,标记为0.
3.2 异常定位
异常定位是指进行异常发现后可以对异常数据进行分析并了解异常出现在哪个层次或者说哪些人需要对该异常负责.
异常定位通过概率模型来解决.在异常定位是涉及到两个指标:每个异常月份mi各标记(-1/1/0)分别对应的个数占比NRi及销售数值占比SRi,分别表示如下.
NRi=CSi/Ni
(6)
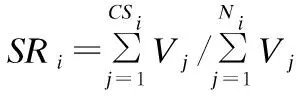
(7)
其中,CSi表示在异常月份mi各标记分别对应的总个数;Ni表示在异常月份mi各标记的总和;Vj表示异常月份mi对应的销售数值.每个级别的异常定位具体描述如下:
1)总销售(地区或企业) .若总销售在异常月份mi被标记为f (-1或1),且当月大类级别或门店级别同被标记为f的大类或门店统计后的NRi或SRi大于1/2,那么该异常定位于总销售,责任人员为地区总经理或管理者;否则定位于大类级别或门店级别,负责人员为异常大类的大类经理或异常门店的店长.
2)大类级别/门店级别.若大类级别/门店级别总销售在异常月份mi被标记为f (-1或1),且门店-大类同被标记为f的门店/大类统计后的NRi或SRi大于1/2,那么该异常定位于大类级别/门店级别总销售,责任人员为异常大类的大类经理/异常门店的店长;否则定位于门店-大类级别,责任人员为店内大类主管.
3)精准定位.在大类级别/门店级别的异常定位中,当异常定位于门店-大类级别时,结果并不准确,即当从大类级别递进到门店-大类级别将异常定位于门店-大类级别时只能保证大类级别未出现异常.例如,假设A类在某月出现异常,且当月只有B店内A类出现异常,此时异常会定位于B店A类,责任定位于B店A类主管,而问题在于若B店在门店级别异常定位于门店级别时,那么明显之前定位的B店A类则并不准确,应该更正为B店.所以要实现更精准的定位,需要将大类级别与门店级别的定位进行有机结合,即当从大类级别出发定位到门店-大类级别时应结合异常门店的门店级别的定位,并当从门店级别出发,异常门店也定位于门店-大类时才可最终从大类级别出发精准定位于门店-大类级别,责任人员为店内大类主管.从门店级别出发同理.
4 实 验
4.1 基本数据
步步高商业连锁股份有限公司以Access的形式提供了海量财务数据,共有SHOP、ACCTURE、PERIOD、CATE、YEAR、MONTH、ACCOUNT、VALUE八个字段,各个字段所表示的内容如下:
1)SHOP:长沙西站店、金星店、永安店......(共经营37个门店);
2)ACCTURE:达成率、实际、增长率、预算;
3)PERIOD:当期数、累计数;
4)CATE:床上用品、休闲食品、饮料、熟食......(共经营36个大类);
5)YEAR:FY14、FY15、FY16;
6)MONTH:1月、2月、3月、4月、5月、6月、7月、8月、9月、10月、11月、12月;
7)ACCOUNT:销售收入、销售毛利额、合同收入、总毛利......(共21个项目);
8)VALUE:具体数值.
4.2 数据预处理
此次研究首先确定了ACCTURE、PERIOD、ACCOUNT,分别为实际、当期数、销售收入,根据该公司的当期实际销售收入以及模型中异常判断与定位的相关需求,我们从四个方向进行详细的分析,分别是长沙地区、大类级别、门店级别,门店-大类级别,因此首先需要针对前三个方向进行数据的预处理,具体如下:
1)长沙地区.将各个月份的销售收入进行总计,即将所有CATE、SHOP的当期实际销售收入按月总计得到各个月份的地区总销售收入.
2)大类级别.将各个月份的销售收入按照各自不同的CATE进行总计,即对每一个CATE都将所有SHOP的当期实际销售收入按月总计得到不同大类各个月份的大类级别销售收入.
3)门店级别.将各个月份的销售收入按照各自不同的SHOP进行总计,即对每一个SHOP都将所有CATE的当期实际销售收入按月总计得到不同门店各个月份的门店级别销售收入.
4.3 实验环境
由于数据量庞大,此次实验在以Hadoop为基础的spark平台下进行,具体配置如表1所示.

表1 Spark集群环境Table1 Environment of Spark cluster
4.4 实例分析
在此次实际应用中,共从长沙地区、大类级别、门店级别,门店-大类级别四个角度对销售数据进行异常判断与定位.其中前三个角度代入模型的初始数据为数据预处理后的数据,确认参数β时的等差差值取值为0.05.在对四个角度均按照模型进行异常发现得到所有相关数据后,汇总各个角度各类异常数据,最后进行异常定位.以下内容以每个角度中的某一个例子来说明模型中异常定位的原理:
1)长沙地区
长沙地区总销售在异常判断后结果可视化如图1所示,图1表明FY15-01与FY15-09为异常月份.
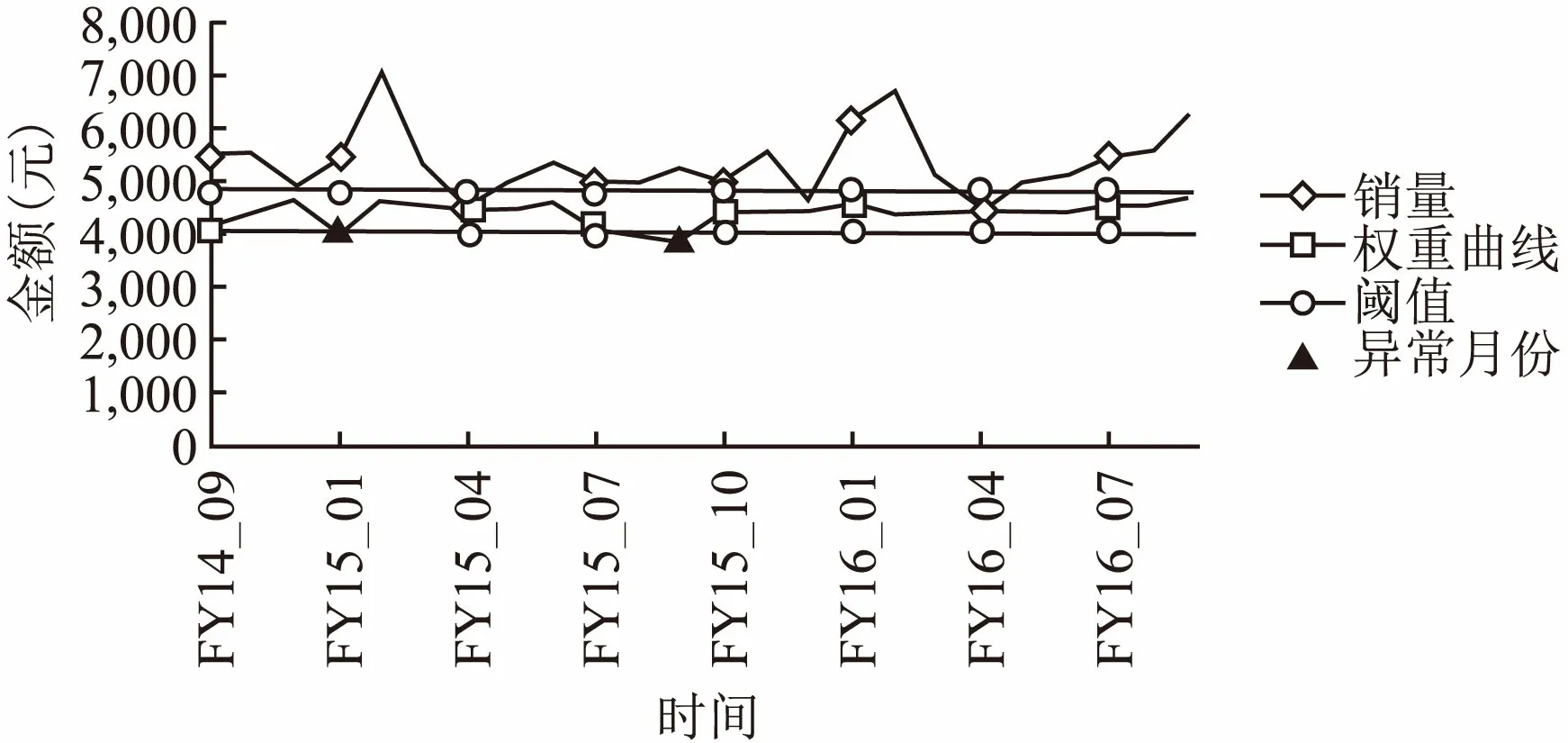
图1 长沙地区总销售Fig.1 Total sales in Changsha
对长沙地区进行异常定位分析时,从逐级追究的概念出发,只需也只能将定位方向确认到大类级别或门店级别,因此首先汇总上述两个异常月份大类级别与门店级别的各类异常数据,即总计这两个异常月份大类级别的各类异常大类占比与门店级别的各类异常门店占比,如表2所示.
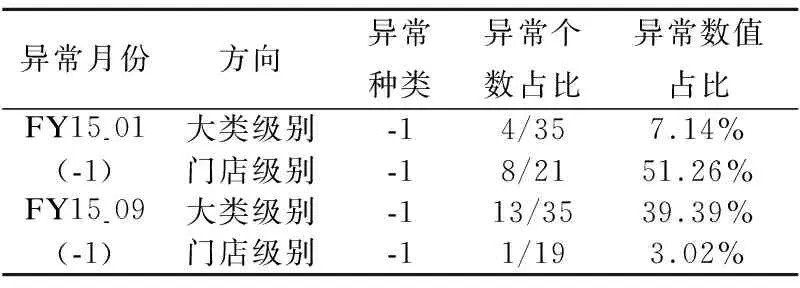
表2 长沙地区异常统计Table 2 Anomalies statistics in Changsha
根据表2中每个月份中与对应月份异常种类一致的异常大类或门店的个数占比和数值占比进行异常定位,实现责任到人,可得出结果如表3所示.若仍需更加详细的定位详细则继续从如表3中的异常定位的角度下钻.

表3 长沙地区异常定位与责任到人Table 3 Anomalies positioning and responsibilities to people in Changsha
2) 大类级别
以品类冷冻冷藏为例,结果可视化如图2所示.图2表明FY15-07与FY15-08为异常月份.
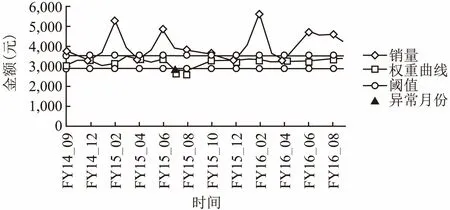
图2 长沙地区大类级别(冷冻冷藏)总销售
Fig.2 Total sales at the level of category(the frozen and the chilled) in Changsha
在各异常月份店内有经营冷冻冷藏的异常门店汇总如表4所示.仅从大类级别出发,异常定位及责任到人结果如表5所示.从逐级追究的概念以及单独从大类级别出发,仅能将责任确认到地区大类经理或大类主管,从而忽略了店长,因此如表5中的定位并不十分准确,后续第(4)小节中的精准定位是必需的(门店级别同理).

表4 长沙地区大类级别(冷冻冷藏)异常统计Table 4 Anomalies statistics at the level of category (the frozen and the chilled) in Changsha

表5 长沙地区大类级别(冷冻冷藏)异常定位与责任到人Table 5 Anomalies positioning and responsibilities to people at the level of category(the frozen and the chilled) in Changsha
3)门店级别
以金星店为例,结果可视化如图3所示.图3表明FY15-01、FY15-02、FY15-06与FY15-08为异常月份.在各异常月份金星店内销售异常的大类汇总如表6所示.异常定位及责任到人结果如表7所示.
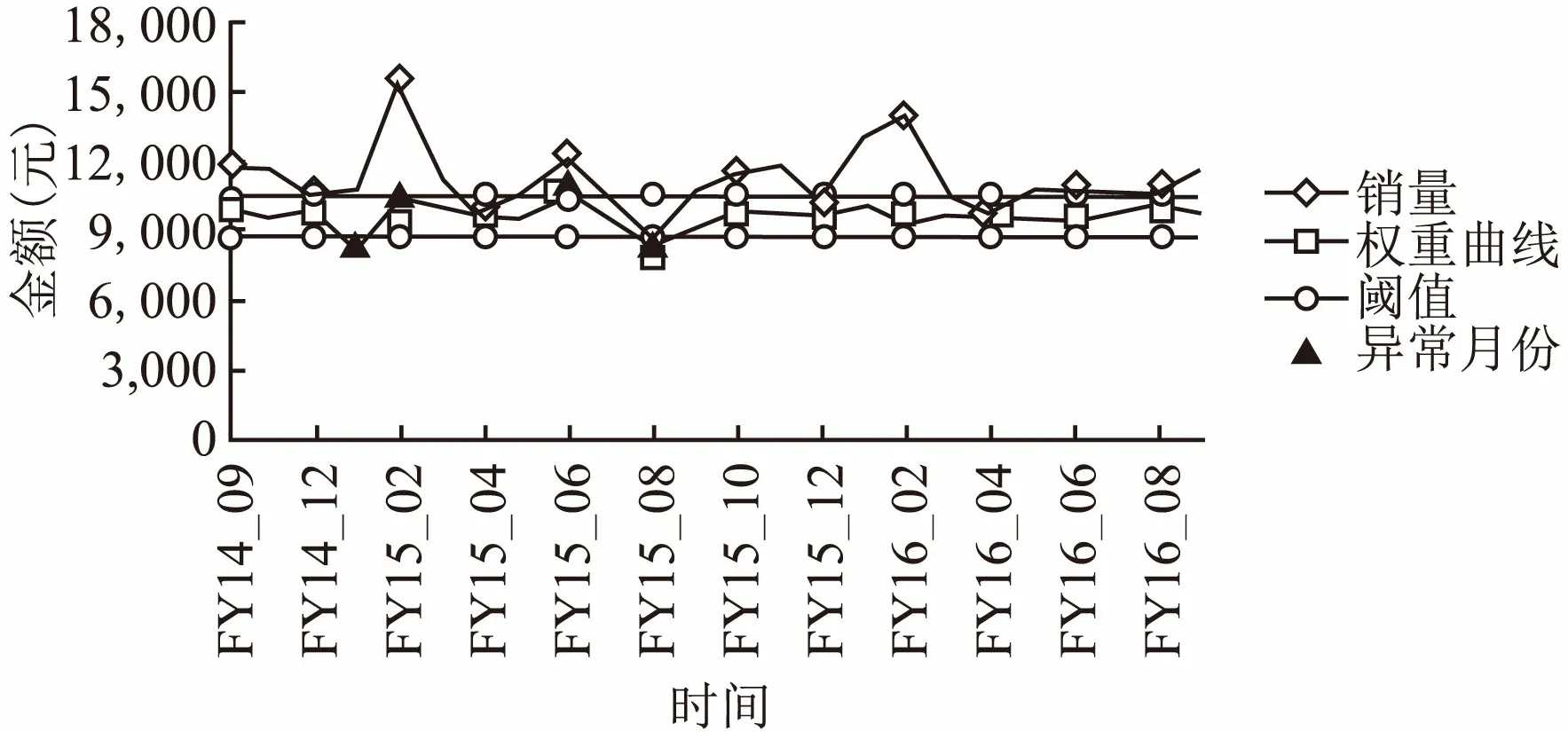
图3 长沙地区门店级别(金星店)总销售Fig.3 Total sales at the level of shop(Jinxing Shop) in Changsha表6 长沙地区门店级别(金星店)异常统计Table 6 Anomalies statistics at the level of shop (Jinxing Shop) in Changsha

异常月份异常种类门店-大类异常大类个数占比异常大类数值占比FY15-01(-1)-1休闲用品,冷冻冷藏…17/3355.30%FY15-02(1)1DIY课,休闲食品…1/341.70%FY15-06(1)1冲调饮品,手机数码部…2/1121.80%FY15-08(-1)-1DIY课,冰箱/冰柜…16/3353.60%

表7 长沙地区门店级别(金星店)异常定位与责任到人Table 7 Anomalies positioning and responsibilities to people at the level of shop(Jinxing Shop) in Changsha
4)精准定位
以上文大类级别冷冻冷藏为例,该大类在FY15-08销售异常(标记为-1),同时在FY15-08金星店和王家湾店的冷冻冷藏也被判断为销售异常(标记为-1),因此大类级别的冷冻冷藏在FY15-08的异常被定位于门店-大类.按照模型中异常定位中精准定位的原理,以金星店为例(王家湾店同理),由上文可知金星店在FY15-08异常被定位于门店级别(标记为-1),因此需将文中大类级别冷冻冷藏在FY15-08的异常定位修正为门店级别(异常门店的店长).反之,在该例中,若金星店或王家湾店在门店级别FY15-08被标记为0或异常同样定位于门店-大类,则不需修正大类级别冷冻冷藏FY15-08的异常定位.
在大类级别或门店级别中异常被定位于下一级,即门店-大类级别时,均需如上例将大类级别与门店级别结论有机结合得到精准定位,然后返回修正大类级别或门店级别的结果.
4.5 对比实验与评估
提出的异常发现与定位模型在异常定位这一角度具有创新、独特的优势,因此在确认此模型的适用性时仅在异常发现这一角度进行了对比实验,首先是原始销售曲线与权重曲线的对比,然后是离群点检测方法的对比.其中,与异常判断这一步骤对比的离群点检测方法采用的是孤立森林(iForest,Isolation Forest).在使用不同方法时使其离群率一致从而保证结果的准确性和可比性.实验部分详细结果如表8所示.
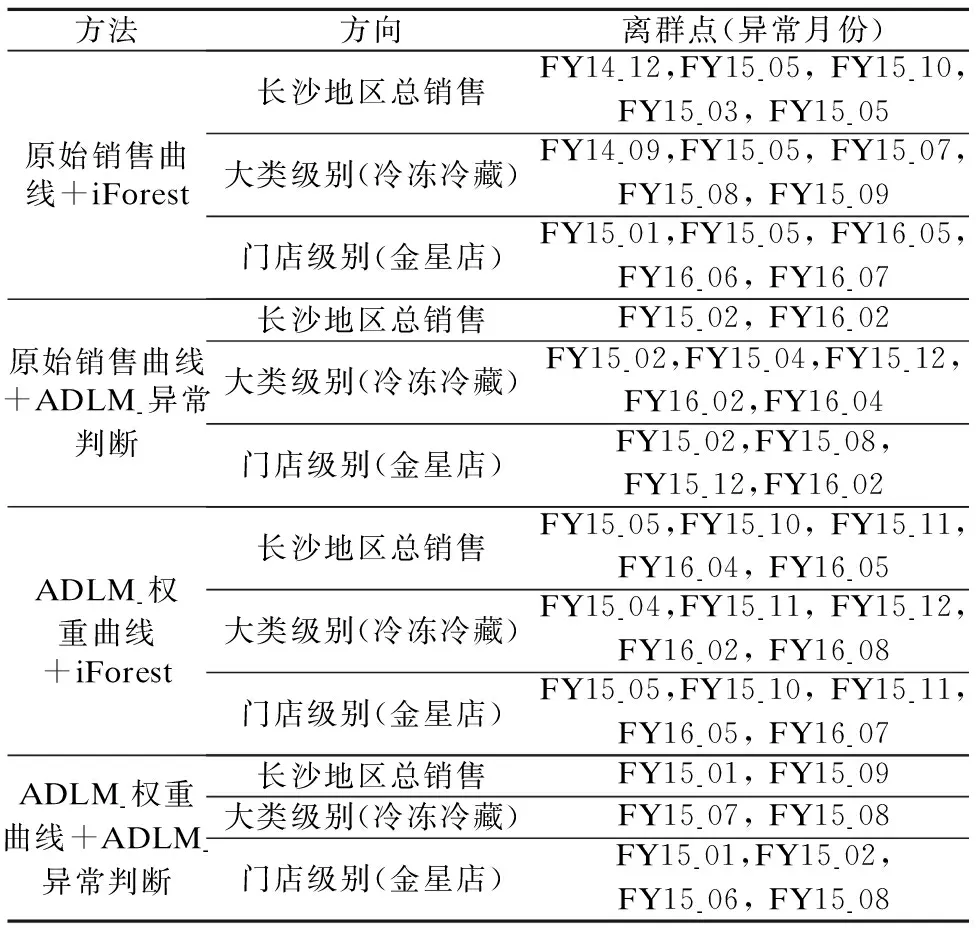
表8 部分详细结果Table 8 Partial detailed results
在总样本数和离群率确定的情况下,与ADLM异常判断这一步骤中采取不超过离群率的最大值方法相比,iForest的原理决定了其每一次检测所得到的离群点个数完全相等且大于等于ADLM异常判断检测出的离群点个数.对企业而言,并不是检测出离群点个数越多越好,其根本需求是找出典型、显著、对经营影响最大的离群点从而采取措施.ADLM相当于只是设定了最高离群率,在最高离群率的保证下检测出相对显著的离群点这一方法较好的解决了这一需求,显然iForest无法做到.综上在超市相关人员确认下各方法总体准确率对比如表9所示.

表9 各方法对比结果Table 9 Comparison of each method
5 结束语
随着大数据的兴起,各个行业日趋重视自身的大数据挖掘,零售行业也不例外.本文通过对销售数据异常挖掘模型的构建研究销售大数据,实现对销售数据的异常判断与定位.同时通过该模型在步步高连锁超市的实际应用验证了该模型的可行性.未来的工作是希望实现销售数据的准确预测,对管理、决策起到辅助作用.
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
计算技术与自动化(2022年1期)2022-04-15
———占旭刚4
北广人物(2020年48期)2020-12-22
经济数学(2020年4期)2020-01-15
军事文摘(2018年24期)2018-12-26
晚晴(2018年3期)2018-12-06
诗选刊(2018年7期)2018-07-09
北方音乐(2018年8期)2018-05-14
中学生天地(B版)(2017年5期)2017-06-01
教育教学论坛(2017年5期)2017-03-06
