
关于改进的激活函数TReLU的研究
2019-01-24 09:35宋文爱宋超峰
小型微型计算机系统 2019年1期
张 涛,杨 剑,宋文爱,宋超峰
(中北大学 软件学院,太原 030051)
1 引 言
近年来,深度学习(Deep Learning)在机器学习研究的各个领域都取得了引人注目的成果,自从2012年Alex Krizhevsky教授第一次利用深度学习系统Alexnet[1]赢得ILSVRC[2](ImageNet Large Scale Visual Recognition Challege)竞赛冠军后,以后每年的冠军都是由改进后的深度学习方法获得的,其中一个很重要的因素就是激活函数的发展.
在2016年的国际机器学习大会(ICML2016)上Bengio教授给出了激活函数的定义:激活函数是映射 h:R→R,且几乎处处可导[3].在卷积神经网络中,激活函数运行时通过激活某一部分神经元,将激活的神经元特征通过函数保留并映射到下一层.由于线性函数构建的线性模型不能很好的处理实际环境中非线性分布的数据,所以在深度学习中的激活函数一般都是非线性的.
最早广泛使用的激活函数是Sigmoid和Tanh,而由于这两种函数都都具有软饱和性[3],在深层卷积神经训练中会造成梯度消失的现象,如Sigmoid 网络在 5 层之内就会产生梯度消失现象[4],所以无法很好的完成训练.直到2010年,Hinton教授提出了新型激活函数Relu[5]才有效缓解了之前的梯度消失的问题,并成功在2012年应用于Alexnet模型.而ReLU激活函数仍然存在“神经元死亡”[5]和偏移现象[6]的问题会影响网路的收敛性.针对这一问题,2015年何恺明等提出PReLU[7]激活函数,通过在负半轴引入可变斜率α,使激活后的特征值近似0均值,从而避免了该问题的产生.PReLU负半轴的激活值的存在,导致所有落在负半轴的特征都能获得激活,缺乏对噪声的鲁棒性[6].因此,本文提出TReLU激活函数,通过在负半轴保持一定的激活值和软饱和特性,有效解决了ReLU和PReLU激活函数存在的问题,实验表明,提出的激活函数对于不同的数据集和不同的优化方法具有鲁棒性,具有一定的实用价值.
2 相关工作
2.1 激活函数的非线性特性
假设一个线性模型的输出为y,输入为x,则一个线性模型的公式为:
y=wx+b
(1)
现在假设有两层神经网络,其中第一层的输入为x,则第一层进行线性变换后的得到的结果为:
y1=w1x+b1
(2)
经过第二层线性变换的到的结果为:
y2=w2y1+b2
(3)
将式(2)代入式(3)得:
y2=w2(w1x+b1)+b2=(w1w2)x+(w2b1+b2)
(4)
由式(4)可知,线性模型经过两层神经网路后依然是线性模型,它和单层的神经网络并没有什么区别.以此类推,任意层的神经网络和单层神经网路的表达能力并没有什么区别,依然解决的是线性问题,这就决定了线性模型的局限性.
在现实世界中,绝大部分的问题不是线性可分的,所以在深度学习中的激活函数一般都是非线性的.现在一般常用的激活函数有Sigmoid,Tanh,ReLU和PRelu.
2.2 Tanh激活函数

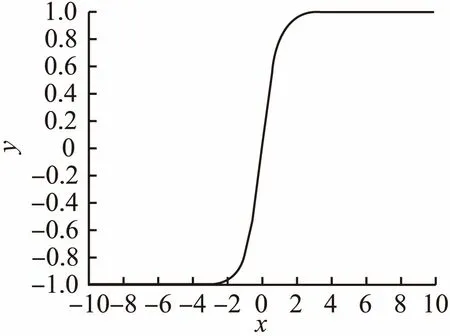
图1 Tanh函数图像Fig.1 Image of Tanh function
2.3 ReLU激活函数
Relu激活函数是目前最受欢迎的激活函数.其定义为:f(x)=max(x,0),对应的函数图像见图2.从图2可知,当x<0时,函数具有硬饱和性质,随着训练的进行,部分输入会落入硬饱和区域,导致对应的权重为0,无法更新,这就是“神经元死亡”[5].

图2 ReLU函数图像Fig.2 Image of ReLU function
ReLU函数还存在的一个问题是偏移现象.因为所有x<0的数值经过ReLU函数后都变为0,所以函数输出的均值恒大于0.这就导致在反向传播算法中,假设有两个特征值a1,a2,经过权值w1和w2后输出结果y,最后经过softmax输出结果L,加入对权值W求偏导,得到:
(5)
(6)
因为激活函数是ReLU,且激活值不为0,所以a1和a2的值均大于0.通过公式(5)和公式(6)可知,由于a1和a2大于0,所以w1和w2同号,也就是权值的梯度必须在第一和第三方向移动,无法获得最快的梯度下降结果.
2.4 PReLU激活函数
PReLU激活函数是2015年提出来的.其公式为f(x)=max(αx,0),对应函数图像如图3所示(假设α为0.25).PReLU函数中的α参数是非固定的,可以在训练中进行学习.该函数虽然保证了输出结果0均值分布,但是同时在负半轴对所有特征值进行了激活,这样导致一部分噪声也会获得激活,进而影响最终的收敛效果.
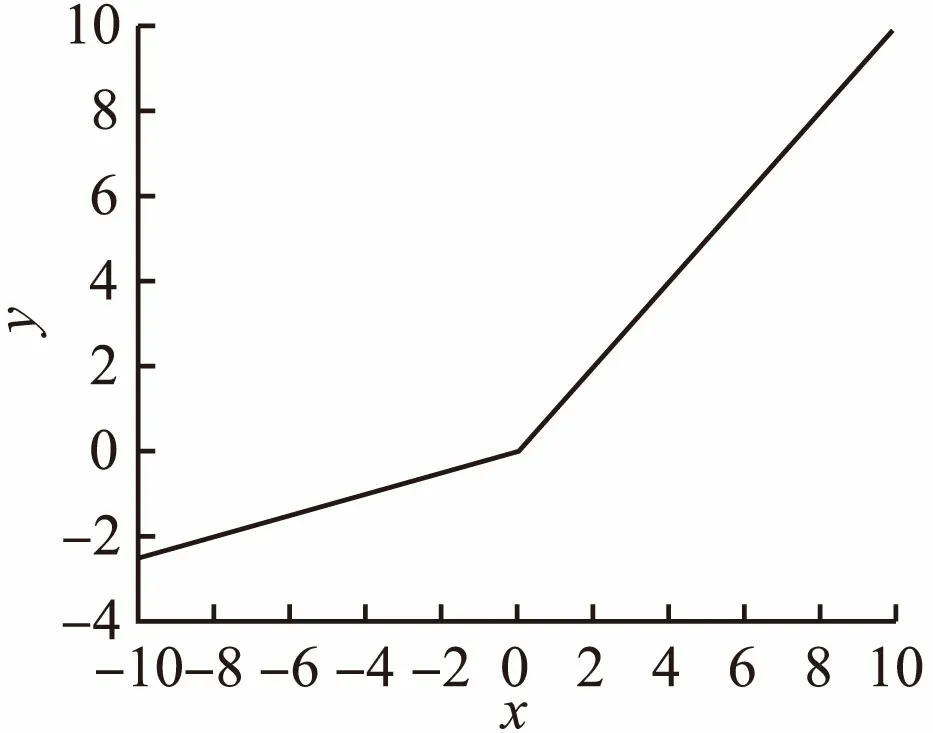
图3 PReLU函数图像Fig.3 Image of PReLU function
针对现有激活函数存在的这些问题,本文结合Tanh函数和PReLU函数的优点,提出了TReLU激活函数,保留了PRelu函数收敛速度快,可以缓解梯度消失的优点,同时利用Tanh函数引入负半轴激活值和它的软饱和特性,防止了“神经元死亡”和偏移现象,对噪声也更具有鲁棒性.
3 改进后的激活函数TReLU
改进后的激活函数命名为TReLU,表达式为:
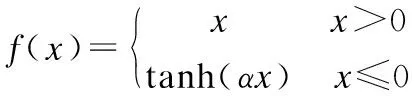
(7)
对应的函数图像如图4所示(假设α取1).
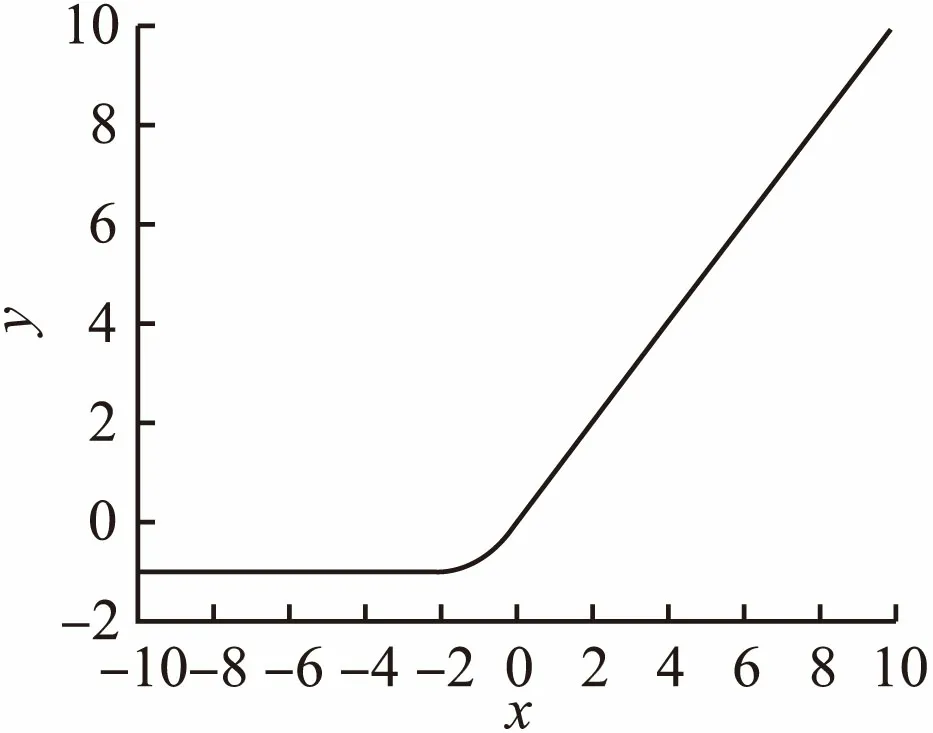
图4 TReLU函数图像Fig.4 Image of TReLU function
参数α是一个可变参数,用来控制函数的非饱和区域.初始值设为1,函数在原点处近似线性,可获得较快的收敛速度.
跟现有的激活函数Sigmoid,ReLU和PReLU激活函数相比,本文提出的激活函数具有以下优点:
1)缓解了梯度消失的问题.由于x>0时,函数导数值恒为1,所以TReLU函数在x>0时保持梯度不衰减,从而缓解了该问题.
2)激活了负值.TReLU函数在负半轴非饱和区保留了部分梯度值,当激活值落入非饱和区时,仍能获得有效的激活,保留了图像部分有效的特征.同时通过参数α控制非饱和区域的大小,可以对负值特征进行更加有效的激活.如图5所示,分别为α取1,0.1和0.01对应的函数图像,图6显示了反向传播算法中对激活函数求导,负半轴向前一层传递的信息.从图中可以看出,随着α值的变小,函数在负轴的非饱和区域不断扩大.在实际训练中,随着训练的不断进行,通过自动调整α的参数,可以将更多落在负轴的特征值激活,同时向前一层传播的信息也更多,缓解了神经元死亡的现象.
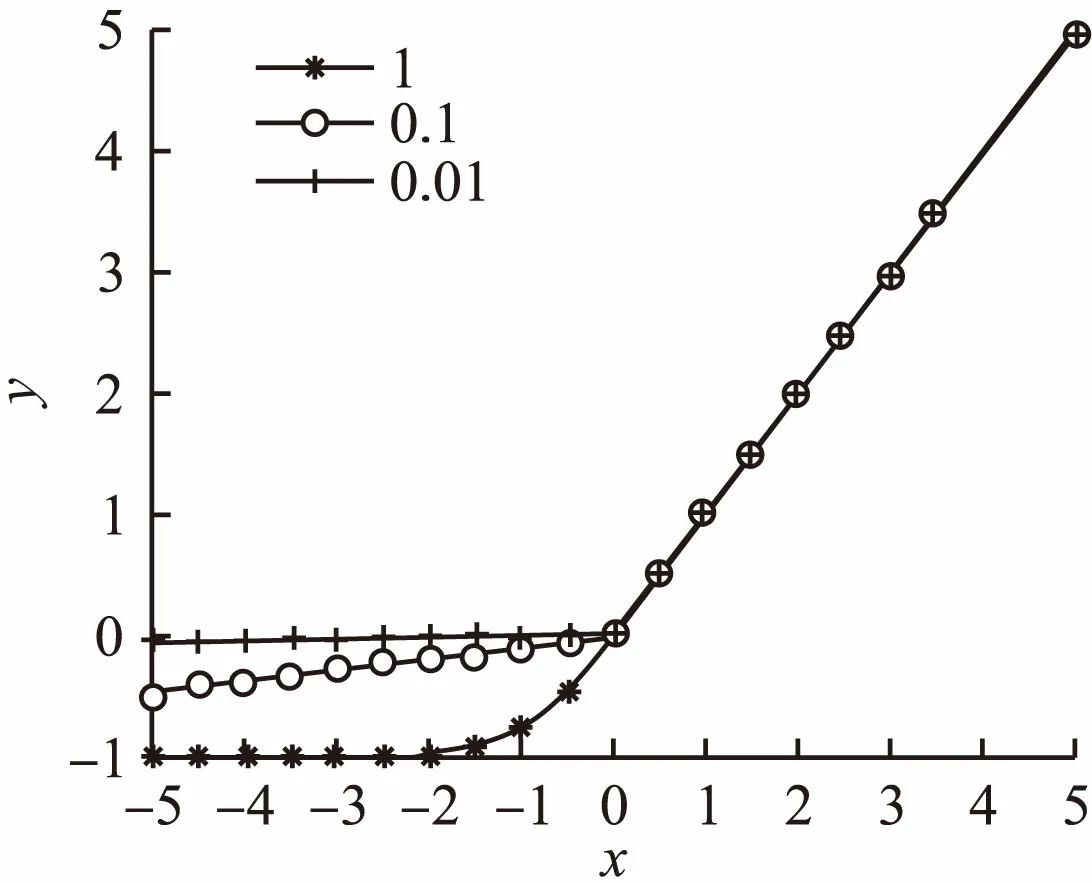
图5 不同α对应的函数图像Fig.5 Function image of different α
3)近似于0均值分布.PReLU函数在负半轴有激活值,这就保证了输出的均值近似于0.上一层输出的均值近似于0,这样就有效缓解了ReLU激活函数的偏移现象,权值可以获得较快的更新,从而获得较快的梯度下降速度.
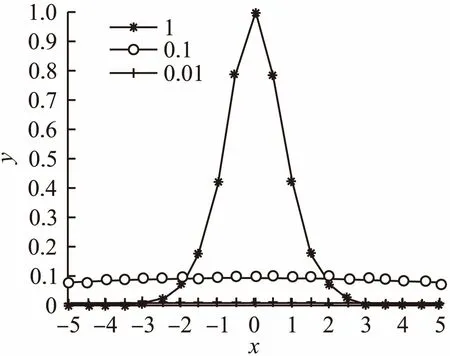
图6 不同α对应的导数图像(x<0)Fig.6 Derivative image of different α(x<0)
4)对噪声具有健壮性.PReLU函数在负半轴具有软饱和性,在x<0时,函数输出范围在[0,1)之间.软饱和性意味着函数可以减小输出到下一层的信息的变化,这样表现出来的特征对噪声具有健壮性,同时复杂性也降低了[9].
4 实验结果及分析
4.1 实验环境及评价方法
实验的操作系统为Windows10 64位操作系统,显卡为NVIDIA GeForce GT 630.目前构建卷积神经网络有许多成熟的开源框架,如Caffe[10]、CNTK[11]、TonsorFlow[12]等.
本文实验使用TensorFlow,使用了CUDA加速,结果分析基于TensorFlow的可视化工具Tensorboard,通过最终结果的准确率曲线和损失函数下降曲线分析实验在不同阶段的运行状态.为了更准确的评估本文提出激活函数的有效性,分别在MNIST、Cifar-10和开源遥感影像数据集NWPU-RESISC45[13]上对比分析Sigmoid、Tanh、ReLU、PReLU和TReLU五种激活函得出结论,并对后三种激活函数在ImageNet数据集上的表现进行了对比.
4.2 MNIST
MNIST数据集是一个简单的手写数字数据集.它的训练集包含6万张图片,测试集包含1万张图片,图像均为灰度图并且数字大小居中,图片尺寸均为28*28.本组实验参数设置如表1所示,所用结果模型及参数如图7所示,两个卷积层实验结果的准确率曲线和损失函数下降曲线见图8和图9.表2显示的是实验最终结果在测试集上的准确率.由图可知,Sigmoid激活函数准确率上升速度和损失函数下降速度都不如其他几种函数,说明Sigmoid函数的饱和性质和非原点对称的特点大大影响了其收敛效果,同时在MNIST数据集上,其他几种函数在测试集上都获得了将近100%的准确率,损失函数也接近于0,说明TReLU激活函数的有效性.由表2可以看书,在测试集上TReLU获得了最高的准确率,说明在MNIST数据集上本文提出的激活函数效果优于其他几种激活函数.
表1 MISIT对照组参数设置
Table 1 MISIT control group parameter settings

学习率(Learning_rate)0.01训练步数(Global_step)5000批数量(Batch_size)128优化方法(Optimizer)GradientDescentOptimizer
都用了5*5的过滤器,第一个卷积层通道数为32,第二个卷积通道数是64,卷积步长均为1,池化层过滤器大小为2*2,步长为2.
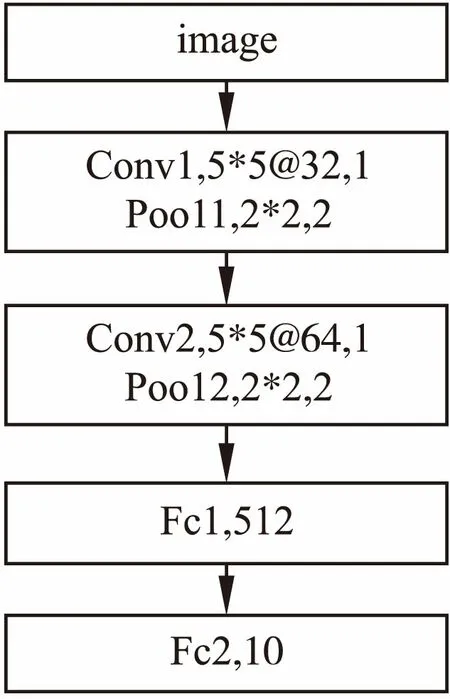
图7 MNIST实验组网络结构及参数Fig.7 MNIST experimental group network structure and parameters
表2 MNIST实验组结果
Table 2 MNIST experimental group results
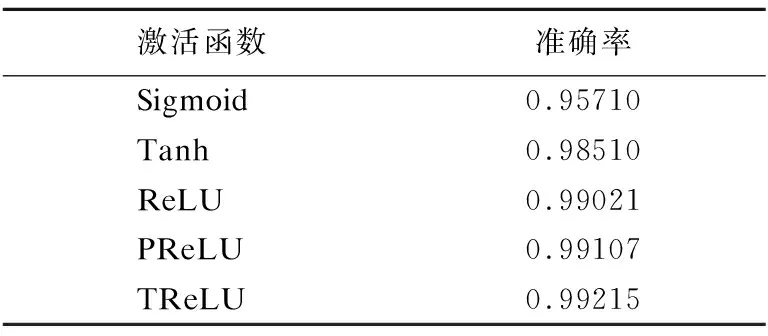
激活函数准确率Sigmoid0.95710Tanh0.98510ReLU0.99021PReLU0.99107TReLU0.99215
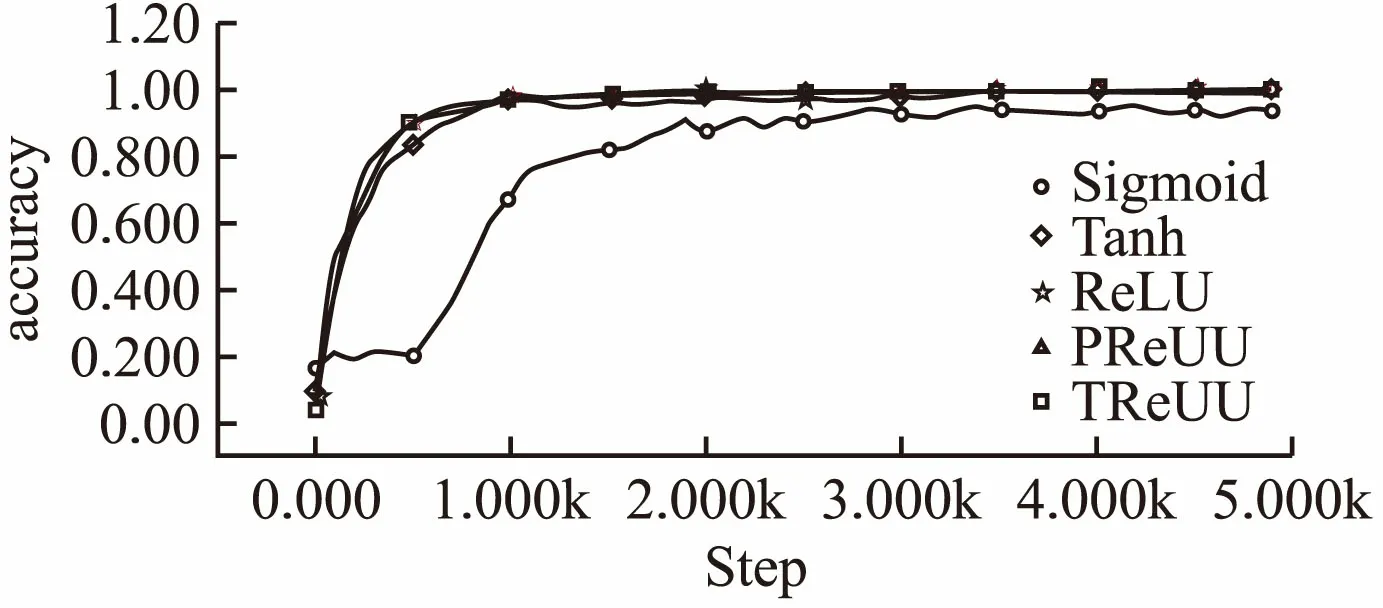
图8 MNIST实验组准确率曲线对比图Fig.8 MNIST experimental group accuracy curve comparison chart
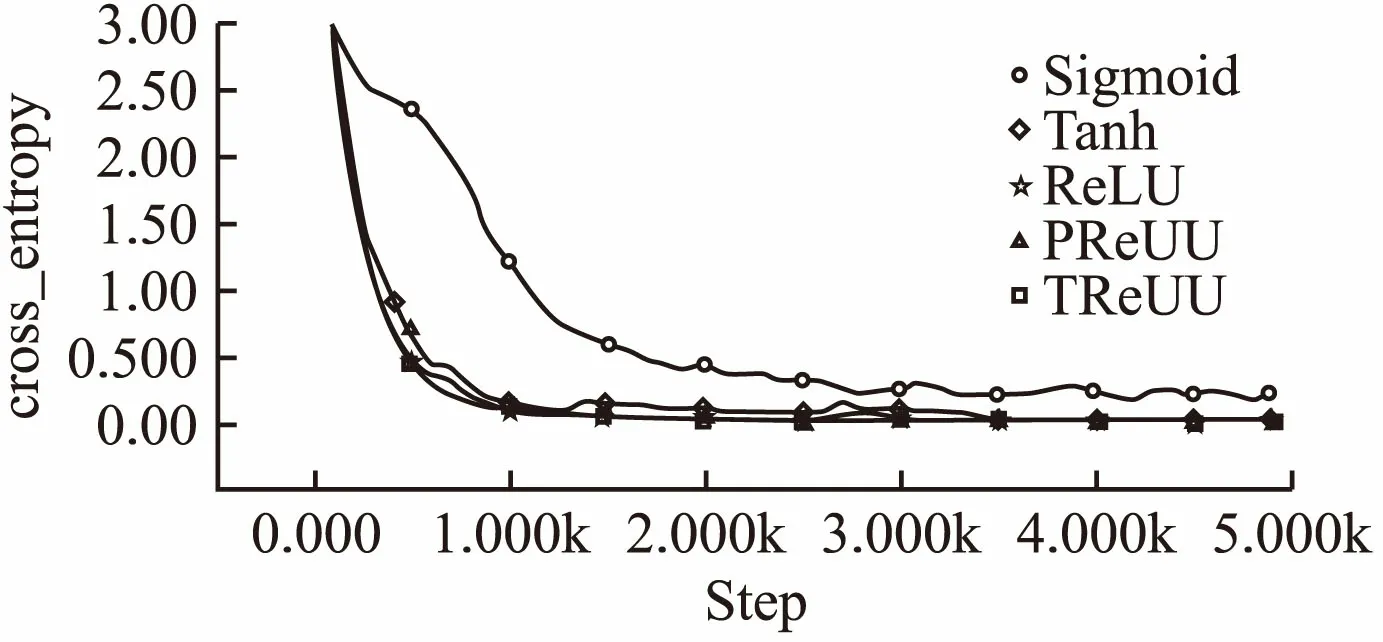
图9 MNIST实验组损失函数曲线对比图Fig.9 MNIST experimental group loss function curve comparison chart
4.3 Cifar-10
Cifar10数据集收集了来自10个不同种类的6万张图片,图像的像素均为32*32且都是三通道彩色图片.实验中,
表3 Cifar10对照组参数设置
Table 3 Cifar10 control group parameter settings

学习率(Learning_rate)0.001训练步数(Global_step)3000批数量(Batch_size)128优化方法(Optimizer)AdamOptimizer
将图片随机剪切为24*24的像素,并且加入了随机翻转,随机亮度变化,随机对比度变化从而丰富图像的种类,缓解过拟合现象的发生.本组实验参数设置如表3所示,所用结果模型及参数如图10所示,两个卷积层都用了5*5的过滤器,且通道数都为64,卷积步长均为1,池化层过滤器大小为3*3,步长为2.
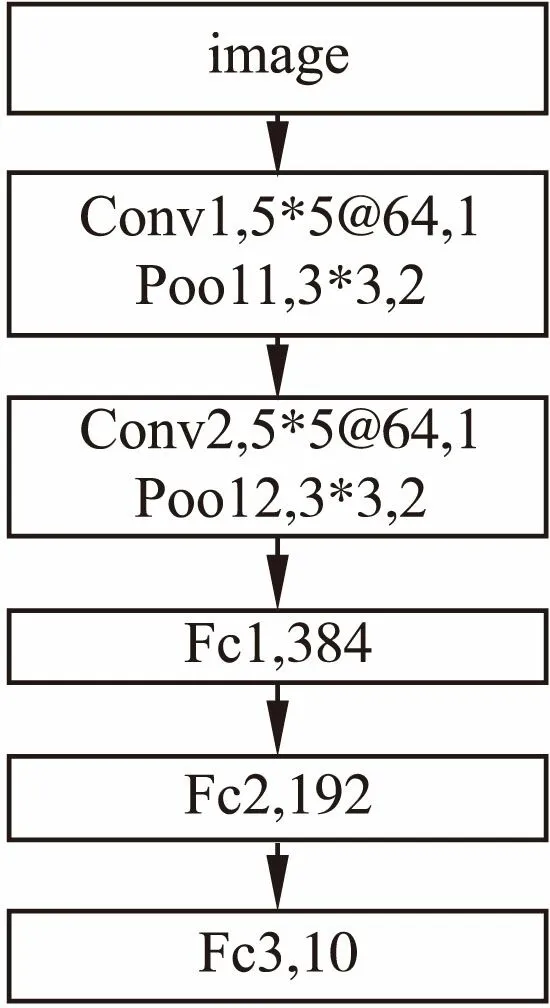
图10 Cifar10实验组网络结构及参数Fig.10 Cifar10 experimental group network structure and parameters
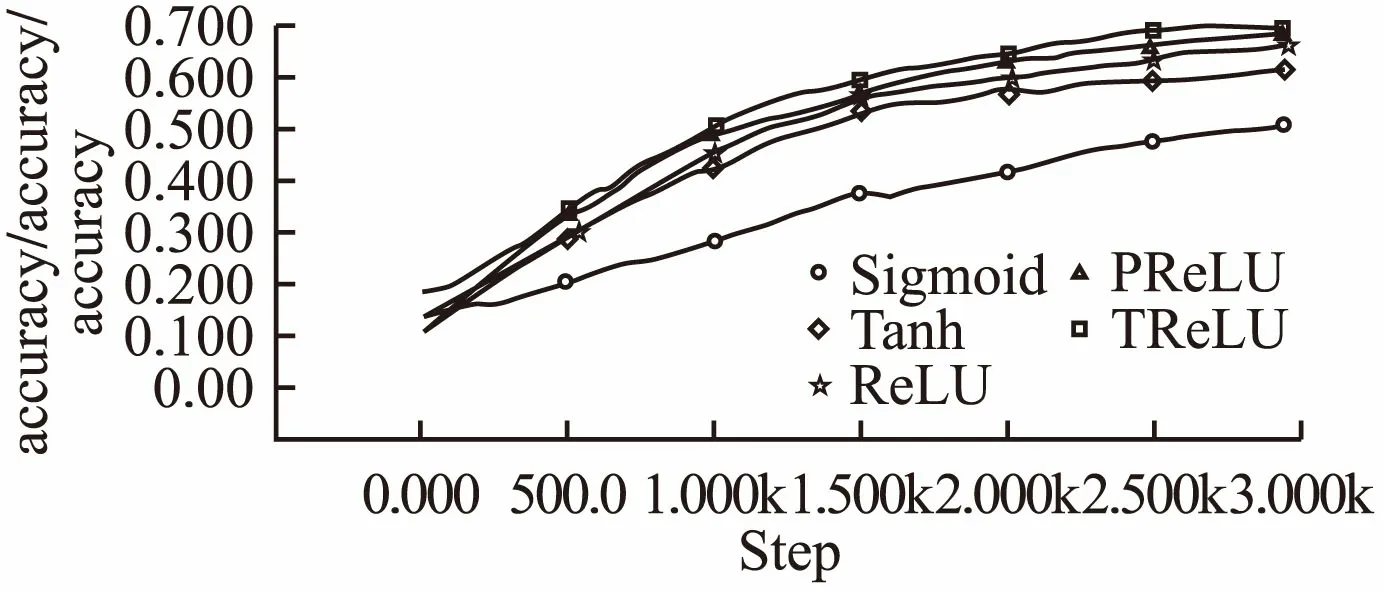
图11 Cifar10实验组准确率曲线对比图Fig.11 Cifar10 experimental group accuracy curve comparison chart
实验结果的准确率曲线和损失函数下降曲线见图11和图12.表4显示的是实验最终结果在测试集上的准确率.本组实验采用了较复杂的三通道图片进行实验,同时采用了不同的优化方法.通过图像曲线可以看出五种激活函数在测试集上都获得准确率的提升和损失函数的下降.Sigmoid函数在准确率和损失函数上都获得了最差的效果;Tanh函数比Sigmoid函数收敛速度快,同时效果比Sigmoid函数要好,说明关于原点对称的激活函数收敛速度更快;ReLU函数在600步以后收敛速度比Sigmoid函数快,最终效果也比Tanh好,说明随着训练的进行,Tanh函数由于其本身的饱和性质,特征损失较多,而ReLU激活函数由于正半轴非饱和性质,特征获得了保留获得了较好的效果;PRelu激活开始开始200步后收敛速度就超过了ReLU说明保留负轴的特征激活值对结果的提升有一定的帮助;TReLU激活函数在1000步后收敛效果好于PReLU,说明去除噪声的干扰提取的特征对最终结果的提升也有一定的帮助.由表可知,本文提出的激活函数TReLU在Cifar10测试集获得了最好的效果,实验结果仍然优于其他几种函数,同时对不同的优化方法有鲁棒性.
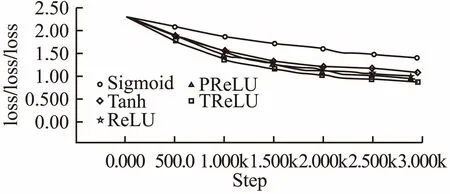
图12 Cifar10实验组损失函数曲线对比图Fig.12 Cifar10 experimental group loss function curve comparison chart
表4 Cifar10实验组结果
Table 4 Cifar10 experimental group results

激活函数准确率Sigmoid0.598Tanh0.666ReLU0.712PReLU0.726TReLU0.746
4.4 NWPU-RESISC45
NWPU-RESISC45数据集是西北工业大学提出遥感影像分类大型基准数据集.这个数据集共有31500张图像,涵盖45个场景类,每个类有700张图像,图像大小均为256*256像素,场景中包括了飞机场,网球场,道路,桥梁,港口,河流等常见的遥感影像场景.实验中随机选取20%的数据作为训练集,剩余80%数据作为测试集,将所有图片随机裁剪为实验结果的准确率曲线和损失函数下降曲线见图15和图16.表6显示的是实验最终结果在测试集上的准确率.本组实验选取了较大的三通道图片,实验数据比前两个实验的数据更加复杂.从图像中可以看出,50步以后Sigmoid激活函数准确率不再上升,损失函数不再下降,说明函数的梯度已经消失;Tanh,ReLU和PReLU激活函数由于自身存在的局限性,最终的准确率和损失函数都没有获得很好的效果,而TReLU克服了这三种的激活函数的缺点,同时也结合了他们的优点,最终获得在训练集上获得了最好的效果,同时在测试集上也获得了最高的准确率,说明在NWPU-RESISC45数据集上本文提出的激活函数优于其他几种激活函数.

图13 部分NWPU-RESISC45数据集图片Fig.13 Part NWPU-RESISC45 dataset pictures
表5 NWPU-RESISC45对照组参数设置
Table 5 NWPU-RESISC45 control group parameter settings
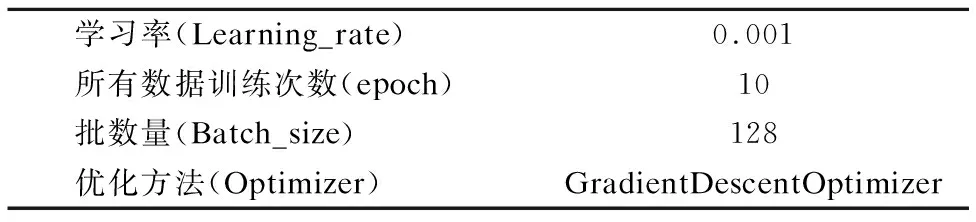
学习率(Learning_rate)0.001所有数据训练次数(epoch)10批数量(Batch_size)128优化方法(Optimizer)GradientDescentOptimizer
227*227像素并且进行随机翻转.如图13为部分数据图像.本组实验参数设置如表5所示,所用结果模型及参数如图14所示.
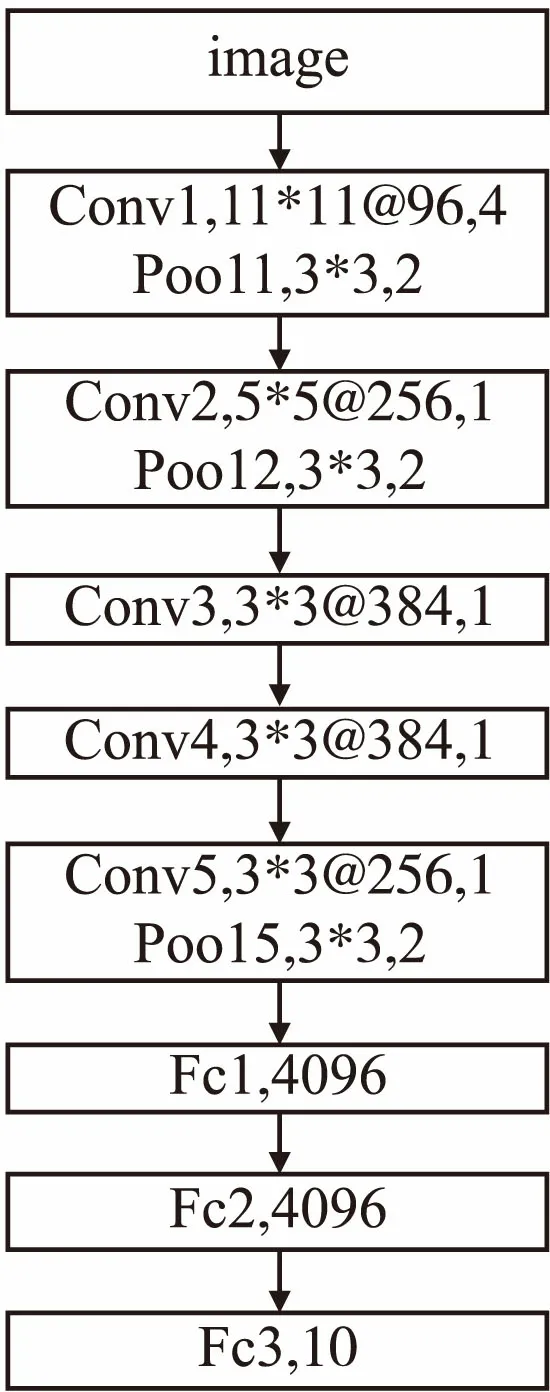
图14 NWPU-RESISC45实验组网络结构及参数Fig.14 Cifar10 experimental group network structure and parameters
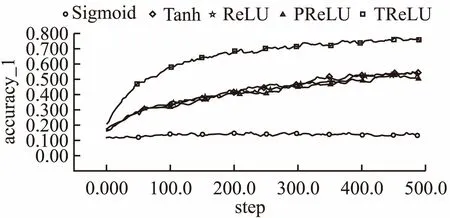
图15 NWPU-RESISC45实验组准确率曲线对比图Fig.15 NWPU-RESISC45experimental group accuracy curve comparison chart
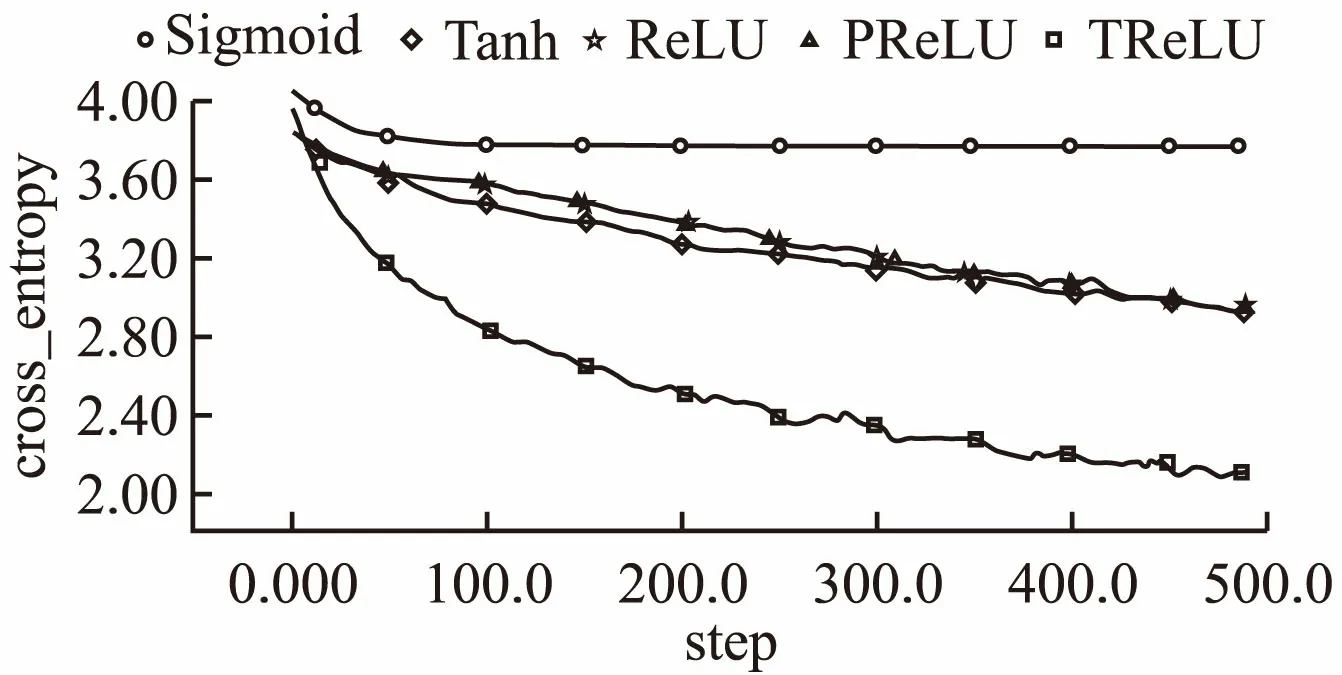
图16 NWPU-RESISC45实验组损失函数曲线对比Fig.16 NWPU-RESISC45 experimental group loss function curve comparison chart
表6 NWPU-RESISC45实验组结果
Table 6 NWPU-RESISC45 experimental group results

激活函数准确率Sigmoid0.1563Tanh0.5009ReLU0.5078PReLU0.5052TReLU0.7076
4.5 ImageNet
为了更加贴近真实环境下的图像识别问题,斯坦福大学的李飞飞教授提出了ImageNet大型图像数据库[14].ImageNet每年都会举办图像识别相关的竞赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC),本实验组采用的是ILSVRC2012图像分类数据集.数据集一共有120万张图片,包含了自然界中1000种类别的物体,分为训练集,校验集和测试集,每张图片所属的类别是唯一的,且图片的大小不一.本组实验参数设置如表7所示,所用结果模型及参数设置采用经典的AlexNet[1].
表7 ImageNet对照组参数设置
Table 7 ImageNet control group parameter settings

学习率(Learning_rate)0.001所有数据训练次数(epoch)80批数量(Batch_size)256优化方法(Optimizer)Momentum
根据Krizhevsky[15]等的研究表明Sigmoid和Tanh激活函数在Imagenet数据集上的表现不如ReLU,所以本组实验仅对Relu、PReLU、TReLU三种激活函数进行对比.实验结果的准确率曲线和损失函数下降曲线见图17和图18.表8显示的是实验最终结果在测试集上的准确率.从图像中可以看出,ReLU激活函数在本组数据集中的表现最差,刚开始PReLU的准确率增长速度优于TReLU,而后期随着TReLU准确率增长速度超过了PReLU,并在测试集上获得了最优的准确率,也获得了最低的损失函数值,同时通过在测试集上的准确率对比,本文提出的激活函数也获得了最好的效果.
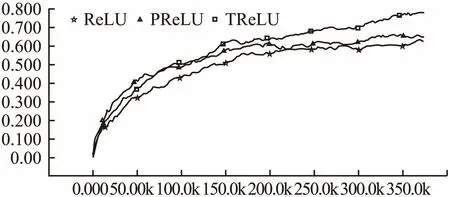
图17 ImageNet实验组准确率曲线对比图Fig.17 ImageNet experimental group accuracy curve comparison chart
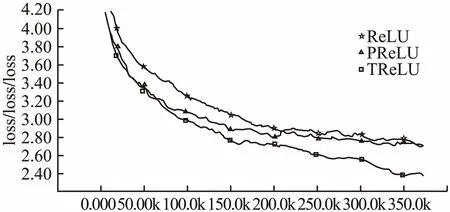
图18 ImageNet实验组损失函数曲线对比Fig.18 ImageNet experimental group loss function curve comparison chart
表8 ImageNet实验组结果
Table 8 ImageNet experimental group results

激活函数准确率ReLU0.6193PReLU0.6544TReLu0.7139
5 结束语
激活函数作为深度学习重要的研究内容,本文针对之前激活函数存在的一些问题进行了改进,提出一种新的激活函数TReLU,通过增加负半轴激活值,缓解了ReLU激活函数“神经元死亡”的问题,实现激活值近似0均值分布,从而解决了偏移现象的问题,同时在负半轴具有软饱和性质比PRe-LU激活函数在噪声上更具鲁棒性.实验结果表明,改进后的激活函数在四种不同的数据集上都获得了最优的效果,同时对不同的优化方法也具有鲁棒性,具有一定的实用价值.
猜你喜欢
橡塑技术与装备(2022年6期)2022-06-02
计算机研究与发展(2022年1期)2022-01-19
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
计算机应用(2020年12期)2020-12-31
汽车实用技术(2019年1期)2019-10-21
军民两用技术与产品(2017年13期)2017-12-18
汽车实用技术(2015年8期)2015-12-26
