
面向智能避障场景的深度强化学习研究
2019-01-10 05:16刘庆杰林友勇李少利
智能物联技术 2018年2期
刘庆杰,林友勇,李少利
(中电海康集团研究院,浙江 杭州 310012)
0 引言
随着人工智能技术的发展和各种传感设备的普及,移动机器人/无人车自动驾驶等技术日趋成熟,但具备自主决策能力的智能体(智能体指宿主于复杂动态环境中,自治地感知环境信息,自主采取行动,并实现一系列预先设定的目标或任务的实体,如移动机器人/无人车)还相对薄弱。2016年初DeepMind团队开发的AlphaGo战胜李世石,成功地将具有自主决策能力的强化学习技术引爆科技圈。强化学习是一种通过与环境不断交互获取奖惩并做出最优决策的机器学习方式,在机器人和工业自动化、博弈决策等领域都有广泛的应用,因此将其应用到移动机器人/无人车等智能体的自动行驶中具有可行性。本文针对智能体行驶过程中面临的避障问题展开研究。
传统避障算法,如模糊控制法、启发式搜索等面对未知的环境时依靠人为规则策略和经验做决策,存在通用性和灵活性差的缺点。智能避障算法,如具备自主学习功能的DQN算法,在无需人为策略和经验指导下即可做出决策。基于深度强化学习算法的智能体在模拟环境中对各种常见场景经过一定时间自主学习,通过在环境中获得奖惩指引智能体做出动作,以提升自主决策能力的准确性和鲁棒性。
1 深度强化学习算法原理与网络模型设计
本节先介绍深度强化学习算法的基本概念和工作原理,进而设计了应用于避障场景的神经网络模型。
1.1算法基本原理
深度学习是机器学习领域非常重要、应用非常广泛的一个分支。其起源于人工神经网络,是一种基于数据感知的表征学习方法,可以实现任意复杂度连续函数的逼近。深度学习经过多年发展,典型卷积神经网络、循环神经网络和对抗神经网络等在人脸识别/通用物体识别、语音/文本翻译、人机对话和问答等领域取得了巨大成功。
强化学习是机器学习的另一个重要分支,不同于常见的有监督学习和无监督学习算法,强化学习擅长于解决序列决策问题:通过自主感知环境采取动作,并根据环境的反馈获取新的奖赏,进而选取具有最大化奖励的策略作为最优策略。强化学习的目标为寻找获得最大累积奖赏的策略,示意图如下图1所示。
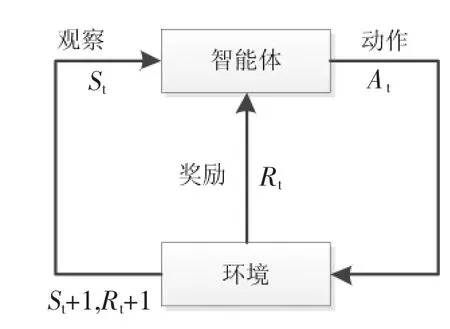
图1 强化学习示意图
传统强化学习对于连续状态空间的表达能力相对较弱,维度灾难的存在导致难以高效地求解最优策略。而深度学习擅长处理高维度的问题,因此本文将具有决策能力的强化学习和擅长处理高维感知数据能力的深度学习结合,构成深度强化学习新技术应用于智能体避障方案中。
1.2 网络模型设计
深度强化学习DQN算法是基于价值函数,将深度学习与强化学习结合,从而实现从感知环境到执行动作的端到端学习算法,在Q-learning算法中Q值的更新方式见公式(1):
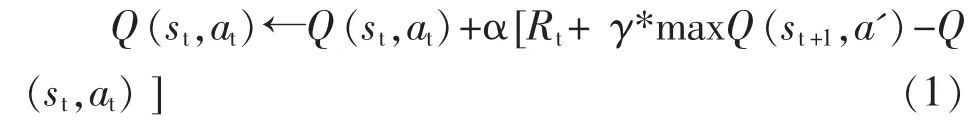
式(1)中:Q(st,at)为衡量当前状态 st下采取动作at能够获得收益的期望值,环境根据智能体的动作反馈相应的回报Rt,γ为奖励衰变系数,表示对未来奖励的重视程度,α 为学习率,maxQ(st+1,a')表示下一时刻状态下采取某个动作得到的最大Q值。
当状态和动作空间离散且维度不高时使用Q-table表存储更新每个状态-动作对应的Q值。由于智能体感知的环境是连续的,采用表格化的Q-learning来存储状态值在现实中存在占用内存空间过高、运算量大等问题。本文采用神经网络和Q-learning算法结合的深度强化学习算法DQN来拟合Q函数,解决占用内存过高和运算量大的问题。算法以移动机器人/无人车等智能体获得的环境状态信息作为网络输入,每个动作对应的评估值作为网络Q值输出。DQN网络结构流程如图2所示。
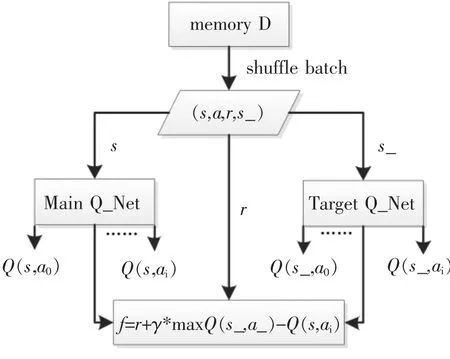
图2 DQN网络结构流程
在神经网络训练中,若输入样本之间具有高度关联性,则神经网络无法很好收敛。因此采用经验回放的技巧,把存储到记忆库中的样本随机打乱以消除样本之间的关联性。为解决计算当前Q值和下一状态目标Q值采用同一网络会出现更新不稳定的问题,在计算目标Q值时不直接使用预更新的Q网络,而是增加Target Q网络来计算,这样做的目的是为了减少目标计算与当前值的相关性,使训练更新更加稳定。
与有标签样本的监督学习不同,DQN算法通过奖励值和Target Q中获取的Q值自动进行标注,通过不断试错方式获取奖惩来寻找最优策略,可以有效解决环境中存在的各种特殊情况。
2 智能避障仿真系统设计
为了验证DQN算法模型在与环境交互过程中所具备的避障能力,构建了一个实验室仿真系统。该仿真系统包含二个主要模块:环境感知模块、实时决策模块、动作控制模块。通过在智能体的不同方向上部署多个传感器从环境中获取数据,经过DQN神经网络实时决策模块预测智能体需要执行的动作,经由动作控制模块指导智能体完成具体转向。仿真系统整体架构如图3所示。
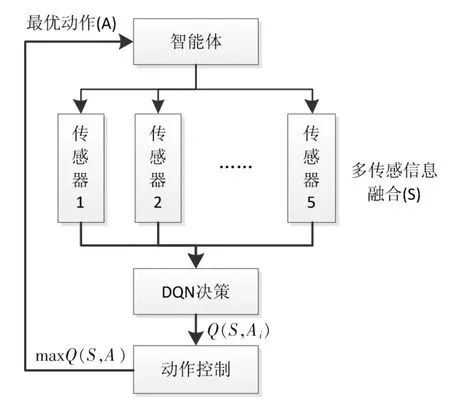
图3 仿真系统整体架构
2.1 环境感知模块
智能体(如移动机器人/无人车)的车身及内部布设了大量的传感器和摄像头来感知外界的环境信息,并根据环境变化做出相应的决策执行动作,如左转、直行、右转、刹车等。为简单起见,实验中通过5个超声波传感器分别获得左方、左前方、前方、右前方和右方共5个方向障碍物的距离信息,同时能获取障碍物相对智能体的位置和角度信息,将多传感信息融合或环境感知的信息作为神经网络的输入。
2.2 实时决策模块
收集的传感数据是以时间序列的连续状态,融合信息采用智能体与障碍物之间的相对距离、相对角度等参数作为神经网络的输入,相对于采用具体位置坐标信息作为神经网络输入,输入样本数据之间的特征方差更小,更容易收敛,因此鲁棒性也更好。
由于只有当智能体到达目的地时才会给予正向的奖励值,因此奖励过于稀疏,训练多轮也很难获得比较好的结果。现实中随着智能体与环境的交互,状态在不断发生改变,障碍物和目的地之间的距离也在发生变化,因此每个状态下的奖惩都会对智能体的行进方向起指导性作用,增设奖惩和状态关系表,使得奖励不再稀疏更有利于训练。状态-奖惩设置如表1所示。
智能体到达目的地给予+10奖励,碰到障碍物给予-10的惩罚。每一时刻根据智能体距离终点的距离,如当智能体的位置比上一时刻距离终点更近则给予+0.5的奖励;如果相比上一时刻距离终点更远,则给予-0.5的惩罚。
将新的观察参数作为神经网络输入,结合奖惩机制进行实时决策。改进的策略为获得+10奖励的轨迹数据赋予更高的权重,基于此,DQN算法会更加重视顺利达到目的地的那些参数信息,加速网络收敛。
2.3 动作控制模块
仿真环境下,根据智能体速度、位置等参数结合网络预测得到的转向角动作,可计算得到下一个状态下的智能体位置信息,从而更新环境。更新后智能体获得环境新的观察信息,进行新的预测,如此往复形成整个闭环。
3 避障实验与结果分析
3.1 参数设置
初始智能体位于起始坐标(0,0),速度为6m/s,到达目的地(350,0)所在3m半径范围内视为完成任务;中间随机设置5个半径为4m的障碍物,智能体驶入障碍物范围内即视为失败。5个传感器因此可获得5个观察状态信息,根据马尔科夫决策过程,强化学习包含<s,a,r,s_>四个参数,分别表示当前状态、获得的动作、奖励以及下一个状态,因此存储到记忆库中的数据为12维度。
本文在模拟真实环境情况下,实现智能体自动避障的控制算法基于Tensorflow框架,设计了全连接神经网络作为DQN的Q网络,共有4层网络结构:输入层为12维的特征张量;隐含层含128个节点,为防止过拟合增加dropout层,丢弃概率keep_prob设置为0.5;输出层为3维张量,分别表示动作的Q值(直行、左转、右转)。记忆库memory buffer容量为20000条,随机batch_size设置为256条。和深度神经网络一样,训练的目标是最小化损失函数L,损失函数定义如下:
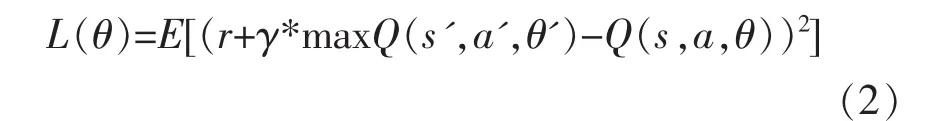
式(2)中r为当前获得的奖励,奖励值的设定按照表1进行;θ为待优化的神经网络参数;γ表示对当前利益和未来利益的关注度因子:γ值越高,表示智能体更加关注未来奖励,γ值越低表示关注眼前利益。考虑到不仅要关注眼前利益也要考虑未来的奖励,因此 γ 值设为 0.9。r+γ·maxQ(s',a',θ')为目标Q值。
Q-learning中Q值的更新是利用奖励Reward和Q函数计算得到的目标Q值进行的,DQN中直接将目标Q值作为样本标签,训练的目标让当前Q值趋近于Target Q值。正如公式(2)所示,将第一项r+γ*maxQ(s',a',θ')作为真实标签,优化方法采用梯度下降法通过不断迭代训练减小损失,使得主网络预测的Q值逐渐逼近真实Q值。
3.2 结果分析
训练采用ε-greedy贪心策略,增加一定的探索机制,有利于更新Q值从而获得更好的策略。起初阶段采用随机探索动作,随着训练的深入进行,逐步采用网络预测代替随机探索,在网络输出的3个动作Q值之间选择最大的输出动作作为下一步要执行的动作,发送给动作控制模块完成具体转向任务。
图4展示了智能体训练2500局的表现,横坐标为训练局数(碰撞到障碍物或者达到目的地为一个episode),纵坐标为行驶时长。图中可以看出随着训练的进行,智能体的运行时间慢慢变长,从最开始的15s左右经常避障失败到运行2500局时能安全躲避障碍物,表现出一定的智能化特征。
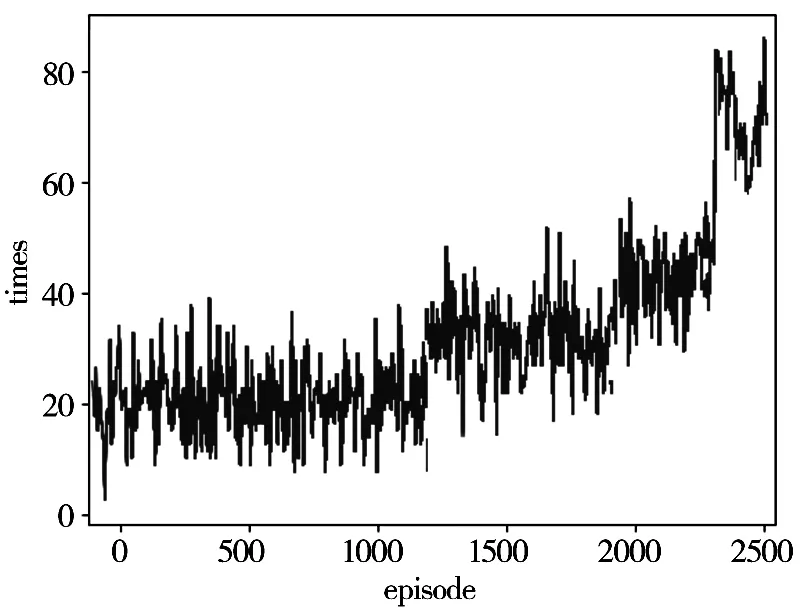
图4 训练过程表现
图5具体展示了智能体经过学习,躲避障碍物到达目的地的轨迹路径。智能体在初始位置(0,0)开始出发,途中分布着5个随机障碍物,在正右方向(350,0)处为目的地。图中可以看出智能体已经学会了如何躲避障碍物,且运行轨迹相对平稳地到达目的地。
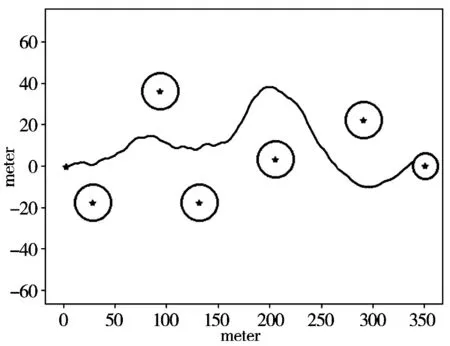
图5 运行轨迹
4 结语
本文对深度强化学习技术在智能避障场景下的应用进行了研究初探。通过多传感信息融合,结合深度学习的数据感知能力和强化学习的自主决策能力,采用相对位置参数、改进了奖惩机制,使得网络训练更加有利于收敛,且鲁棒性更好。仿真实验表明,在无人为策略指导的情况下,智能体经过大量自主探索试错,学会了如何在未知环境中搜寻最优路径,从而实现躲避障碍物的目的。此算法设计对无人车自动驾驶、巡检机器人以及无人机自主飞行都具有一定的指导意义。在智能机器人和工业自动化、博弈决策等领域,基于自主学习决策的深度强化学习技术都将会有广泛的应用前景。
猜你喜欢
现代电力(2022年2期)2022-05-23
纺织科学研究(2021年9期)2021-10-14
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
电子制作(2019年19期)2019-11-23
创新作文(1-2年级)(2019年4期)2019-10-15
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
电子制作(2019年24期)2019-02-23
海军航空大学学报(2015年4期)2015-02-27
军事历史(1997年5期)1997-08-21
