
自适应学习系统个性化知识推荐技术研究*
2019-01-09 12:17:30袁路妍
中国教育信息化 2018年24期
袁路妍
(绍兴职业技术学院 信息工程学院,浙江 绍兴 312000)
一、引言
自适应学习系统 (Adaptive Learning System,ALS)通过其自身的领域知识库、用户特征库和专家库为学习者提供个性化的学习资源[1]。系统的关键是推荐的学习资源要能够与学习者本身的知识水平、学习偏好相匹配,推荐技术的运用是能够使学习者将要学习的知识与原有的知识达到主动、快速的衔接,帮助学习者发现他们所需学习资源。
常用的推荐技术包括“协同过滤推荐、基于内容推荐、关联规则推荐及混合推荐四种”[2]。其中,协同过滤推荐[3]是依据用户对项目的评分矩阵实现个性化推荐,但在系统实际运行中大部分用户很少参与项目评论,且新用户的不断增加,使得评分矩阵出现稀疏性问题,导致推荐准确率不高。基于内容的推荐,是计算项目特征与用户兴趣模型相似度进行推荐。用户兴趣模型的建立依赖学习者的历史数据,故存在系统冷启动问题。基于规则的推荐[4],依据用户浏览历史作为推荐意见,分析用户和兴趣之间的关系,并制定相应的规则,该方法简单明了,但同样存在系统冷启动问题,这使得难以保证为新用户推荐资源的质量。混合推荐是融合了各种推荐技术的优点而提出的新型推荐技术[5],与单一某种推荐模式相比,具有较高的可用性,如杨武等人[6]关于新闻推荐的研究。
可见,推荐技术的选择直接影响主动推荐学习资源的质量及适应性学习能否实现,现有的推荐技术未能够很好地将领域知识模型及学习者模型充分考虑进去,导致知识推荐质量不高。为此,笔者对领域知识模型、学习者模型作了系统化、多维度的建模并构建了两者之间的匹配规则,依据学习者的学习能力、知识水平、学习方式、学习偏好推荐学习资源。为提升关联规则的有效性,对领域知识模型、学习者模型均采用本体技术进行构建。为避免冷启动问题,系统依据Felder-Silverman学习风格量表[7]测试新用户学习风格,并结合基本注册信息完成学习者模型的初始化。
二、领域知识模型构建及特征表示
1.领域知识模型构建
领域知识模型是关于领域知识的知识,是自适应学习系统的核心组件,其内容涵盖课程教育目标、学习资源、课程结构、教学策略、练习测试题库等。本文将教育目标、知识点、学习资源、测试试题作为领域模型的核心要素,然后利用本体技术实现领域模型的构建,其结构图如图1所示。在模型构建时分析出各要素之间的关系(先后、父子、兄弟),并分析要素的属性(难度系数、预设学习时间、媒体类型等)且进行语义标注。将问题、知识点作为搜索关键词,采用语义搜索、全文搜索技术搜索其对应的试题、媒体材料库(图片、视频、文本),建立问题、知识点与试题、媒体材料库之间的物理和逻辑关联。

图1 领域模型的一般结构
2.领域知识模型特征表示
(1)学习资源对象风格表示
假定学习资源对象 (Learning Resource Style)在Felder学习风格的四个维度都存在值,则学习资源对象风格可以表示成一个四元组:

其中,<Fi,Xi>(1≤i≤4)表示知识对象在 Felder学习风格中某个维度的取值,Fi表示风格类型(Fi∈{直觉型/感知型,视觉型/言语型,活动型/反思型,全局型/序列型}),Xi的取值为-1或1。Xi的取值一般在资源创建时由教师予以设定。
(2)领域知识的难易程度表示
领域知识对象的难度等级是在课程资源创建时由任课教师创定,依次为“容易”“普通”“较难”,形式化表示为:

三、学习者模型构建及特征表示
1.学习者模型构建
“学习者模型是对学习者的若干特征信息的抽象描述,包括其在学习过程中呈现出来的知识状态、目标、背景、认知风格和爱好等”[8]。如何准确地描述和量化学习者的特征信息直接影响主动推荐学习资源的质量以及适应性学习是否能实现。学习者的特征数据主要包含学习者主动反馈的信息数据 (也称之为显示数据反馈)和学习者与系统交互的历史行为数据(也称为隐式数据反馈)。显示数据反馈主要让学习者在注册系统时填写问卷的方式,缺点是对用户存在比较大的干扰性,优点是可以实现系统前推测学习者的风格。隐式数据反馈主要依据学习者的历史学习记录提取用户兴趣特征,优点是对学习者不存在干扰性,能够实时反映学习者的兴趣变化,缺点是无法实现系统前推测学习风格。为此本系统学习者模型构建采用显示数据反馈和隐式数据反馈相结合,其数据维度包含学习者基本信息、学习风格、学习者认知水平、学习历史、学习偏好。“学习者模型表示方法与领域知识密切相关,领域知识是使用本体技术构建,因此学习者个性化特征也应该采用本体技术”[9]。
2.学习者模型的特征表示
(1)学习者基本信息
学习者基本信息在整个学习过程中保持不变,可形式化表示为:

(2)学习风格
依据Felder学习风格量表,学习者的学习风格(Learning Style)可以表示为一个四元组:
由于其定位于中高端消费,且配送范围只有3千米,所以盒马鲜生在选址上面临着比一般商超更高的要求。这样看来,盒马鲜生试图通过门店与仓储合一的模式降低成本,实则是走到了事情的反面。

其中,Fi表示风格类型,Yi的取值为0或1。
(3)学习者认知水平
学生的认知水平可以形式化表示为:
Manegelever=(M1,M2,M3,…,Mn),代表学习者对领域知识的掌握程度,Mi表示学习者对知识单元i的掌握程度。对每个知识单元,学习者的认知状态可以表示为:

其中KN表示知识点,A表示知识点是否适应学习者、V表示知识点是否已经访问,T表示知识点是否测试、AL表示知识点掌握程度。A、V、T取值为0或1,默认为0;AL取值为1、2、3依次代表掌握程度为初级、中级、高级,知识点的掌握程度是根据对应学习任务完成情况测试结果而定。
(4)学习历史
学习历史用于记录最近访问学习资源情况,形式化表示为:
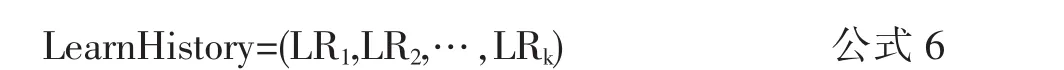
(5)学习偏好
学习者学习偏好(User Profile)信息主要选取用户主动反馈数据:学习者留言、搜索关键词、用户评价信息。将用户偏好信息进行分词,提取关键名词,采用向量空间模型(Vector Space Model,VSM)进行表示,考虑到学习者主动反馈信息是一个连续的过程,因此在提取关键名词时加入“最近访问时间”特征。因此,最终的关键词权重的计算如公式7:

式中的t为关键词ti最后一次被检索时间与当前时间相差的天数。
3.学习资源推荐
本系统关键任务是如何依据学习者模型个性特征数据:学习历史(LearnHistory)、学习偏好(User Profile)、知识掌握水平(Manegelever)、学习风格(LearnStyle)、学生基本信息(Studentprofile),以及领域模型个性特征数据:领域知识对象风格(Object Style)、知识点的难度等级(Object level),实现学习资源、学习路径的主动推荐。现实中没有两个学习者是相同的,每个学习者的教育背景不同,智力水平不同,学习方式不同,注意力跨度及遗忘时间不同,因此为每个学习者推荐有效的个性化学习资源是一项复杂的任务,本系统个性化知识推荐实现主要依据学习者模型与领域知识模型的相似度实现。
计算学习者模型与领域知识相似度的公式如下:
(1)学习风格(LearnStyle)与知识对象风格(Object-Style)相似度(LOS)计算见公式 8:
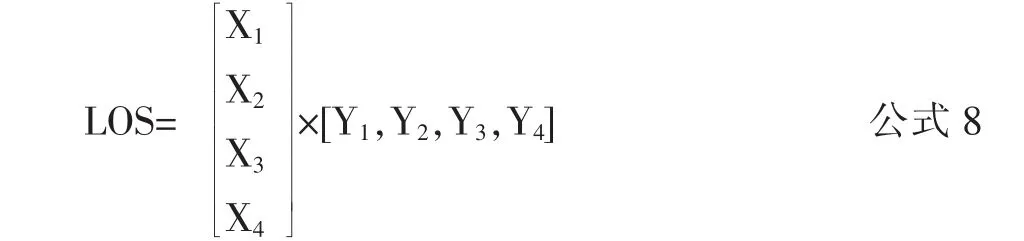
LOS的值越大,学习者的学习风格和知识对象风格相似度越高。
(2)知识掌握水平(Manegelever)与知识对象难度(ObjectClever)匹配程度是由两者的差值(H)决定,见公式9。

(3)学习者与知识对象的相似度S计算公式如下:

其中A和B是可以自行设定的权重参数。
四、结论
自适应学习系统的投入使用,可以打破“一个尺寸适合所有人”的同质性,使每位学习者的学习内容可以随着数据的收集、分析和反馈加以改变和调整,实现高度个性化的教与学。学习者模型是ALS的核心,模型能否真实反映学习者的知识水平和兴趣变化,直接影响了系统推荐质量,作者在构建学习者模型时增加了数据的维度并引入了时间遗忘机制,使得对学习者的特征刻画更加准确。由于学习是一个复杂而隐性的过程,随着物联网和大数据技术的发展,学习者模型数据的采集应融合多种数据采集技术如学习者皮肤电测、面部识别、眼动追踪,从而使学习者的特征刻画更加精确、全面,进一步推动教学向差异化、个性化变革。
猜你喜欢
小哥白尼(军事科学)(2021年7期)2021-11-20 06:14:52
小哥白尼(军事科学)(2021年6期)2021-11-02 05:25:14
小哥白尼(军事科学)(2021年2期)2021-10-12 05:50:28
学生天地(2020年15期)2020-08-25 09:22:02
意林·少年版(2020年2期)2020-02-18 11:14:52
青年生活(2019年23期)2019-09-10 12:55:43
海外华文教育(2016年4期)2017-01-20 08:22:24
非公有制企业党建(2016年9期)2016-05-25 00:37:08
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
继续教育研究(2014年1期)2014-02-27 16:10:08
