
道路场景中基于视频的多目标检测
2019-01-02 09:01李明明,雷菊阳*,赵从健
软件 2019年12期
李明明,雷菊阳*,赵从健

摘 要: 针对复杂道路场景的目标检测难以实现在移动设备上的实时目标检测问题,采用了MobileNet-SSD的目标检测框架,设计了一种用于视频的多目标检测组合网络框架LSTM-SSD。利用视频连续帧的信息时序关联,有效的提高检测的置信度,减少单一图像检测中存在的不稳定问题。通过与VGG-SSD\MobileNet-SSD两种检测网络模型的对比,实验表明,设计的检测网络模型在应对多目标、模糊、遮挡等干扰状况下,均能获得较好的检测效果。该模型的设计,可对无人驾驶实现实时目标检测提供依据和参考。
关键词: 视频多目标检测;SSD;时间维度特征;道路场景
中图分类号: TP391.41 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.12.031
本文著录格式:李明明,雷菊阳,赵从健. 道路场景中基于视频的多目标检测[J]. 软件,2019,40(12):140145
Multi-target Detection Under Road Scenes Based on Video
LI Ming-ming, LEI Ju-yang*, ZHAO Cong-jian
(College of Mechanical and Automotive Engineering, Shanghai University of Engineering Science, Shanghai 201620, China)
【Abstract】: Aiming at the problem that it is difficult for mobile devices to realize real-time target detection of complex road scenes. based on MobileNet-SSD target detection framework, an LSTM-SSD combined model algorithm for multi-target detection of video is designed. The algorithm takes advantage of the temporal feature of the video to effectively improve the confidence of detection and reduce the instability problem in image detection. Compared with the two detection network models of VGG-SSD\MobileNet-SSD, the results show that the designed detection network model can obtain better detection results under multi-objective, fuzzy, occlusion and other interference conditions. The construction of the model can provide basis and reference for real-time target detection by driverless vehicles.
【Key words】: Video multi-target detection; SSD; Temporal feature; Road scenes
0 引言
无人驾驶是未来发展的重要方向,基于视觉的道路场景的目标检测是无人驾驶的主要研究课题[1]。在车辆行驶过程中,如何快速、准确的检测到车辆前方的行人、车辆、车道线、红绿灯、提示牌等目标物体,对无人驾驶系统提前制定驾驶方案具有重要的研究意义。
近几年来,将深度学习应用到目标检测方面取得了非常好的检测效果。各专家学者提出了许多模型来解决视频目标检测速度慢、精确度低的问题。Chen X[2]等提出了一种用于实时检测的时间单发检测器,开发的TSSD-OTA在检测和跟踪方面实现了快速和整体竞争性能。Liu[3]等具有时间感知特征映射的移动视频目标检测,快速的单图像目标检测模型与卷积长短期记忆(LSTM)层相结合,创造了混合的循环卷积体系结构。华夏[4]等提出了采用自适应感知SSD框架来实现多目标检测,将单图像检测框架与卷积长短时记忆网络结合起来,实现了网络帧级间的时序信息关联,可专用于复杂大交通场景的多目标检测。Chen K[5]等通过尺度时间格子优化视频目标检测,提出了一个集成检测的统一框架,将对象检测器应用于基于对象运动和比例稀疏且自适应的选择关键帧,依赖于时间和空间连接来生成中间帧的检测结果。尽管SSD目标检测算法在图片的检测方面取得了高的准确度,也具有较好的实时性,但是在小目标、遮挡、拍摄模糊的场景检测效果不佳。因此,该检测算法仍需不断改进,来满足道路交通中目标检测的实时性要求。
本文主要针对城市道路场景下的车辆、行人检测的特点,将传统的SSD算法进行改进:(1)将单框检测的结果与长短时神经网络(LSTM)预测的结果融合,生成了混合网络体系结构,实现了视频帧间的信息时序关联,提高检测准确度。(2)SSD基础网络特征提取部分采用轻量级网络模型MobileNet,降低计算量,提高检测速度。(3)将最终的检测识别结果反馈到预测网络模型中,作为下一帧图像的输入數据,提高检测精度。实验结果表明,改进后的组合模型在面对多目标、光照变化、模糊、遮挡等不利于检测的条件下,能够取得较结果。该模型的设计,可对无人驾驶实现实时目标检测提供依据
和参考。
1 目标检测模型
1.1 SSD快速目标检测
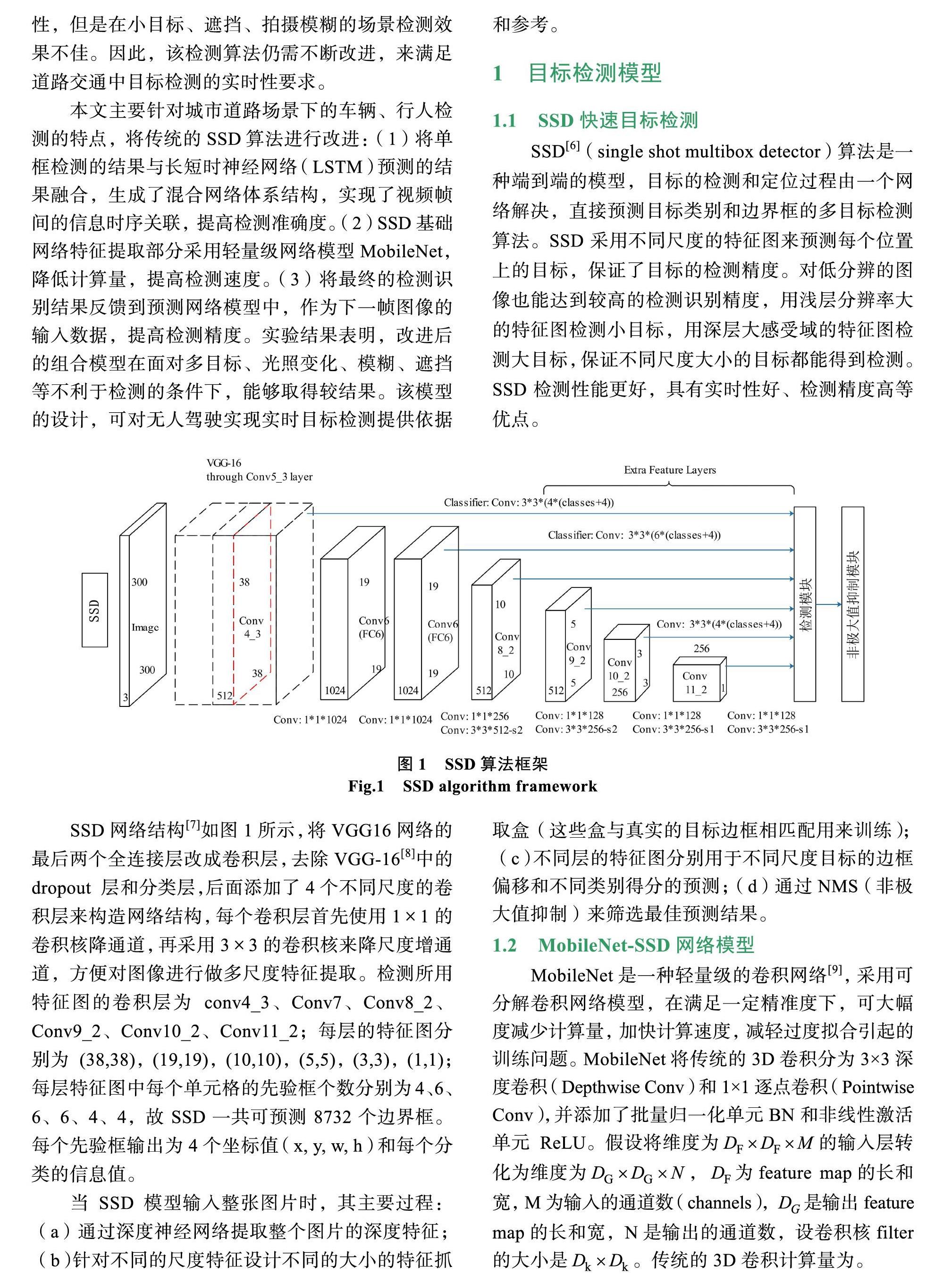
SSD[6](single shot multibox detector)算法是一种端到端的模型,目标的检测和定位过程由一个网络解决,直接预测目标类别和边界框的多目标检测算法。SSD采用不同尺度的特征图来预测每个位置上的目标,保证了目标的检测精度。对低分辨的图像也能达到较高的检测识别精度,用浅层分辨率大的特征图检测小目标,用深层大感受域的特征图检测大目标,保证不同尺度大小的目标都能得到检测。SSD检测性能更好,具有实时性好、检测精度高等优点。
图1 SSD算法框架
Fig.1 SSD algorithm framework
SSD网络结构[7]如图1所示,将VGG16网络的最后两个全连接层改成卷积层,去除VGG-16[8]中的dropout 层和分类层,后面添加了4个不同尺度的卷积层来构造网络结构,每个卷积层首先使用1×1的卷积核降通道,再采用3×3的卷积核来降尺度增通道,方便对图像进行做多尺度特征提取。检测所用特征图的卷积层为 conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2;每层的特征图分别为 (38,38),(19,19),(10,10),(5,5),(3,3),(1,1);每层特征图中每个单元格的先验框个数分别为4、6、6、6、4、4,故SSD一共可预测8732个边界框。每个先验框输出为4个坐标值(x, y, w, h)和每个分类的信息值。
当SSD模型输入整张图片时,其主要过程: (a)通过深度神经网络提取整个图片的深度特征;(b)针对不同的尺度特征设计不同的大小的特征抓
取盒(这些盒与真实的目标边框相匹配用来训练);(c)不同层的特征图分别用于不同尺度目标的边框偏移和不同类别得分的预测;(d)通过NMS(非极大值抑制)来筛选最佳预测结果。
1.2 MobileNet-SSD网络模型
MobileNet是一种轻量级的卷积网络[9],采用可分解卷积网络模型,在满足一定精准度下,可大幅度减少计算量,加快计算速度,减轻过度拟合引起的训练问题。MobileNet将传统的3D卷积分为3×3深度卷积(Depthwise Conv)和1×1逐点卷积(Pointwise Conv),并添加了批量归一化单元BN和非线性激活单元ReLU。假设将维度为的输入层转化为维度为,为feature map的长和宽,M为输入的通道数(channels),是输出feature map的长和宽,N是输出的通道数,设卷积核filter的大小是。传统的3D卷积计算量为。
(1)
MobileNet卷积神经网络的计算量:
(2)
通过比较上式可得,MobileNet网络计算量仅为传统卷积网络的倍,计算成本大幅度降低。
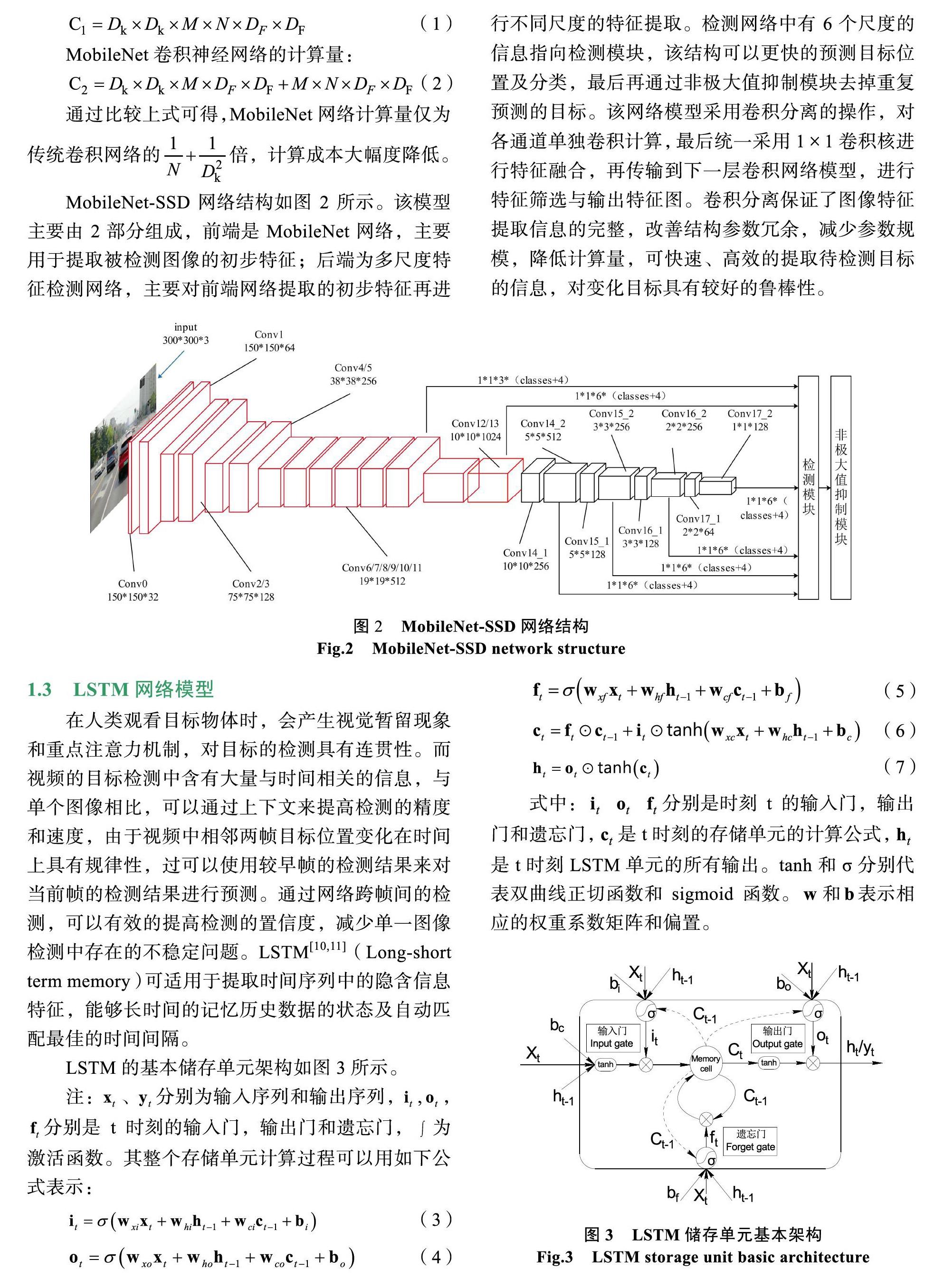
MobileNet-SSD网络结构如图2所示。该模型主要由2部分组成,前端是MobileNet网络,主要用于提取被检测图像的初步特征;后端为多尺度特征检测网络,主要对前端网络提取的初步特征再进
行不同尺度的特征提取。检测网络中有6个尺度的信息指向检测模块,该结构可以更快的预测目标位置及分类,最后再通过非极大值抑制模块去掉重复预测的目标。该网络模型采用卷积分离的操作,对各通道单独卷积计算,最后统一采用1×1卷积核进行特征融合,再传输到下一层卷积网络模型,进行特征筛选与输出特征图。卷积分离保证了图像特征提取信息的完整,改善结构参数冗余,减少参数规模,降低计算量,可快速、高效的提取待检测目标的信息,对变化目标具有较好的鲁棒性。
图2 MobileNet-SSD网络结构
Fig.2 MobileNet-SSD network structure
1.3 LSTM网络模型
在人类观看目标物体时,会产生视觉暂留现象和重点注意力机制,对目标的检测具有连贯性。而视频的目标检测中含有大量与时间相关的信息,与单个图像相比,可以通过上下文来提高检测的精度和速度,由于视频中相邻两帧目标位置变化在时间上具有规律性,过可以使用较早帧的检测结果来对当前帧的检测结果进行预测。通过网络跨帧间的检测,可以有效的提高检测的置信度,减少单一图像检测中存在的不稳定问题。LSTM[10,11](Long-short term memory)可适用于提取时间序列中的隐含信息特征,能够长时间的记忆历史数据的状态及自动匹配最佳的时间间隔。
LSTM的基本储存单元架构如图3所示。
注:、分别为输入序列和输出序列,,,分别是t时刻的输入门,输出门和遗忘门,∫为激活函数。其整个存储单元计算过程可以用如下公式表示:
(3)
(4)
(5)
(6)
(7)
式中: 分别是时刻t的输入门,输出门和遗忘门,是t时刻的存储单元的计算公式,是t时刻LSTM单元的所有输出。tanh和σ分别代表双曲线正切函数和sigmoid函数。和表示相应的权重系数矩阵和偏置。
图3 LSTM储存单元基本架构
Fig.3 LSTM storage unit basic architecture
2 针对视频目标检测改进方法
复杂的道路交通场景中的遮挡、阴影、光照变化等干扰现象,在目标检测过程中容易出现目标信息损失,造成检測目标漏检,错检。智能驾驶中的目标检测要求具有更加快速的检测速度和更准确的检测精度,以便于在当前环境状态下,给驾驶人员或者汽车内部系统提供及时有效的外界信息,从而做到准确的判断。
现阶段,目标检测算法对于图像检测具有很高的检测精度,也可以应对一定程度的干扰信息,但
是对于大面积的目标遮挡等强干扰情况,难以准确检测到目标。另一方面,车载摄像头拍摄的视频具有信息高度冗余,包含了上下帧的时序性和检测场景、目标的相似性,如果充分利用好视频上下帧之间的信息冗余,可以达到提高检测精度,计算速度及解决拍摄中运动目标存在运动模糊、失焦、遮挡、变形等问题。本文利用视频帧间的信息时序关联,从视频前面的检测结果中获取有用的先验信息来预测少量的候选区域,再与当前帧的目标检测结果相融合,实现了利用视频中上下文信息,提高检测精度,降低计算成本。
图4 算法改进后的整体框架
Fig.4 Improved detection algorithm overall framework
将采集到的视频数据视为由多帧图像组成的序列,,检测结果为 ,式中表示视频中对应图像帧的检测结果,中为检测到的各个目标的识别置信度和检测框的位置信息。考虑到视频检测在时域上的连续性,通过构造m层具有时序预测能力的LSTM网络模型来实现预测检测功能,得到。即当前对应帧的检测结果可以由初步检测结果和预测结果进行融合得到。
算法流程具体如下:
(a)将要检测的视频输入网络模型,对视频进行单帧分解,每帧图像输入到SSD模型进行检测,得到初步的检测结果;
(b)采用LSTM网络获得当前帧的预测检测结果,采用信息融合,将初步的检测结果和预测结果结合起来,得到最终的检测识别结果;
(c)得到的最终测结果产生的特征图及检测结果输入到LSTM网络,对下一帧的图像进行预测,再传入SSD的检测指导。
3 实验与分析
3.1 数据准备
文中主要采用实验室构建的KITTI[12](Karlsruhe Institute of Technology and Toyota Technological Institute)数据集,该数据集包含从城市,乡村和高速路等场景采集的真实图像数据,并标记,如车辆类型,是否截断,遮挡,位置和旋转角度等重要信息。本文主要实现道路场景的目标检测,数据集构建方式为从车载摄像头拍摄采样的行人检测标准数据集及车辆检测标准数据集中KITTI 挑选主要包含行人以及车辆的图像样本,同时采集了部分骑行电动车和交通灯的图像对样本进行扩充。将图像尺寸统一并进行人工标记,数据库包括训练集中有
4000张正样本图(即包含检测目标的图像),2000张负样本图(即不包含检测目标的背景图像);测试集中有800张正样本图像和400张负样本图像。绝大部分正样本图像中都包括多个检测目标,而行人目标部分存在遮挡较大的情况,称为困难样本。
由于采集到的视频背景单一,相邻帧图片差异性小,在进行训练目标检测模型时,数据多样性较差,存在大量的冗余,需对数据进行扩充。数据增强使用的手段有水平翻转、随机缩放、随机裁剪,及两者之间互相组合使用。本文对自行采集的图像数据进行水平翻转、缩放以及随机裁剪来补充数据。经过数据增强后可加大训练样本数,提升网络的训练性能,增加算法网络的鲁棒性。
3.2 性能评价指标
在检测单一目标时,对于目标的判别遵循着两种结果的四种可能[13-14]。以检测到汽车为例,检测到的结果有True Car、True N?car、False Car、False N?car 4 种。(1)True Car:待检测目标是汽车,且模型正确地检测为汽车;(2)True N?car:待检测目标不是汽车,且模型检测不是汽车;(3)False Car:把不是汽车的目标误检为汽车;(4)False N?car:把是汽车的目标没有检测为汽车。
在目标检测评价中;一般采用精确率P(Pre cision)、召回率R(Recall)、精度均值AP(Average Precision)来评价算法的优劣,精确率为模型对检测目标正样本的检测能力,即检测正确的汽车占检测出汽车的比例;召回率是衡量模型对检测目标正样本的覆盖能力,即从检测正确的汽车占验证集中所有汽车的比例。精度均值AP为模型对正样本检测准确程度对正样本覆盖能力的权衡能力,即PR曲线的面积,PR曲线横轴为Recall,纵轴为Precision。计算公式如下所示:
(8)
(9)
(10)
在多目标检测中,采用平均精度mAP(mean average precision)来评估目标检测模型在数据集上的所有类别性能好坏,mAP为各个类别AP的平均值,mAP越高,表示模型在全部类别中的综合检测性能越高[15]。采用每秒帧检测数(frames per second,FPS)来评估检测效率。
3.3 参数训练
将训练数据集中的4000张图片导入了MobileNet-SSD检测网络模型,实现端对端的训练,训练过程为:(1)把训练数据集输入网络模型并向前传播,提取图像特征;(2)不同层级的特征图在选取不同大小、不同纵横比的默认框;(3)计算每个目标默认框的坐标位置偏移量和类别得分;(4)根据默认框和坐标位置偏移计算最终边界框,根据类别得分计算默认框的损失函数,并将两者结合得到损失函数;(5)损失函数反向传播,进而调整网络各层权值。对于LSTM网络模型,采用随机梯度下降(带动量项)优化方法训练模型,选择10帧序列作为网络的输入,动量项参数为0.9,训练中 batch 大小设置为32,学习率设置为0.003。
3.4 检测性能对比
為验证所设计的LSTM-SSD组合网络模型的检测精确度,与VGG-SSD模型和MobileNet-SSD[16]的检测结果进行了比较,其中FPS代表算法运行的速度,帧率。
表1 不同检测结果比较
Tab.1 Comparison of different test results
方法 精度均值AP/% mAP/% FPS/(frame?s–1)
Car Person Motorcycle Traffic_light
VGG-SSD 73.42 82.36 70.23 83.34 77.34 15.39
MobileNet-SSD 68.19 76.23 64.17 75.26 70.96 37.15
LSTM-SSD 76.28 84.54 75.68 81.65 79.54 21.46
由表1可知,MobileNet-SSD模型相比于VGG- SSD模型,在检测速度上有了大幅度提升,单个目标的检测准确度略有降低。本文模型与其他算法相比,各类目标识别的精度均值AP提高了1%~6%不等,平均精度mAP提高了约2%~8%不等;在目标检测识别速率比不上MobileNet-SSD检测算法,但是FPS也能达到21帧/s,基本能够满足实时性的要求。因此,本文模型在满足检测精度的基础上,也能达到较快的检测速度。
图5为检测到的视频序列部分帧,第一、二行分别表示传统的检测方法和本文算法对应帧的部分检测结果,结合图5可知,当图中的检测目标数目
图5 检测结果示例
Fig.5 Example of model detection results
较少时,被检测到的准确率较高; 当检测目标数目较多时,较大的目标能够被检测出来,较小的检测出来的准确率稍微低一些; 还有极少部分目标没被检测出来,当检测目标加入时间维度特征,目标可以检测出来,并且也会提高检测目标的置信度。第三行表示本文算法检测的视频序列,随着检测时间的累积,提取到更多时间序列中的隐含信息特征,使得目标检测结果的置信度在不断提高,在多目标、小目标、模糊、遮挡等干扰状况下,也能获得较好的检测效果。从实验结果可以得出,本文采用的LSTM-SSD组合模型的检测方法,在具有时间序列的数据集在目标检测识别率上要优于传统的检测方法,具有较好的稳定性与精确性。
4 结论
(1)面对复杂道路场景中难以在移动设备上实现实时目标检测的问题,采用了MobileNet-SSD检测框架,设计了一种用于视频的多目标检测组合网络框架LSTM-SSD, 利用视频连续帧的信息时序关联,有效的提高检测的置信度,减少单一图像检测中存在的不稳定问题。
(2)通过不同检测网络模型的对比,设计的检测网络框架在应对多目标、模糊、遮挡等干扰状况下,均能获得较好的检测效果。该模型的设计,可对无人驾驶实现实时目标检测提供依据和参考。
(3)本文目标检测算法的处理效率和精度与实际工程需求仍有差距,且对小目标检测识别效果较差,会出现漏检现象,后期要继续研究如何降低计算机的运算量和检测实时性,提高对低分辨率和小目标检测识别效果,进而达到实际工程的要求。
参考文献
[1]王科俊, 赵彦东, 邢向磊. 深度学习在无人驾驶汽车领域应用的研究进展[J]. 智能系统学报, 2018, 13(1): 55-69.
[2]Chen X, Yu J, Wu Z. Temporally Identity-Aware SSD with Attentional LSTM[J]. IEEE Transactions on Cybernetics, 2018.
[3]Liu M, Zhu M. Mobile Video Object Detection with Temporally- Aware Feature Maps[J]. 2017.
[4]华夏, 王新晴, 王东, et al. 基于改进SSD的交通大场景多目标检测[J]. 光学学报, 2018, 38(12): 221-231.
[5]Chen K, Wang J, Yang S, et al. Optimizing Video Object Detection via a Scale-Time Lattice[J]. 2018.
[6]Liu Wei, et al. SSD: single shot multibox detector[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2016: 21-37.
[7]邢浩強, 杜志岐, 苏波. 基于改进SSD的行人检测方法[J]. 计算机工程, 2018, 44(11): 234-239+244.
[8]Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
[9]Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. 2017.
[10]Zhao Z, Chen W, Wu X, et al. LSTM network: a deep learning approach for short-term traffic forecast[J]. Iet Intelligent Transport Systems, 2017, 11(2): 68-75.
[11]B Liu,J Cheng. A Long Short-term Traffic Flow Prediction Method Optimized by Cluster Computing[J].
[12]Geiger A, Lenz P, Stiller C, et al. Vision meets robotics: The KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[13]黎洲, 黄妙华. 基于YOLO_v2模型的车辆实时检测[J]. 中国机械工程, 2018(1): 1869-1874.
[14]张明军, 俞文静, 袁志, et al. 视频中目标检测算法研究[J]. 软件, 2016, 37(4): 40-45.
[15]冯小雨, 梅卫, 胡大帅. 基于改进 Faster R-CNN 的空中目标检测[J]. 光学学报, 2018, 38(6): 0615004.
[16]郑冬, 李向群, 许新征. 基于轻量化SSD的车辆及行人检测网络[J]. 南京师大学报(自然科学版), 2019, 42(01): 73-81.
