
基于多模态组合模型的语音情感识别
2019-01-02 09:01陈军,王力,徐计
软件 2019年12期


摘 要: 语音情感识别在人机交互、人工智能(AI)、自然语言处理(NLP)、5G技术等方面扮演着重要的角色。为了克服单模态模型语音情感识别率低和手工调参的缺点,本文首先在Gaurav Sahu的基础模型上增加KNN、CNB和Adaboost单模态模型,提出多模态组合模型C3;然后应用排列组合方法通过计算机实现自动组合,克服Gaurav Sahu手工组合存在的不足;最后用超参数优化方法和交叉验证方法对网络模型进行训练和测试,解决手工调参存在的不足。在IEMOCAP数据集上对本文提出的C3进行实验,实验结果表明,C3比Gaurav Sahu提出的多模态组合模型E2的语音情感识别性能提升1.56%。
关键词: 单模态模型;多模态组合模型;超参数优化;语音情感识别;交叉验证;自动组合
中图分类号: TN912.3 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.12.013
本文著录格式:陈军,王力,徐计. 基于多模态组合模型的语音情感识别[J]. 软件,2019,40(12):5660+214
Speech Emotion Recognition Based on Multi-modal Combination Model
CHEN Jun1, WANG Li1,2, XU Ji2
(1. College of Big Data and Information Engineerin, Guizhou University, Guiyang 550025, Guizhou;
2. College of Information Engineering, Guizhou Institute of Engineering Application Technology, Bijie 551700, Guizhou)
【Abstract】: Speech emotion recognition plays an important role in human-computer interaction, artificial intelligence (AI), natural language processing (NLP), 5G technology and so forth. In order to overcome the shortcomings of low speech emotion recognition rate and manual parameter tuning in single modal model, this paper first proposes a multi-modal combination model C3 by adding KNN, CNB and Adaboost single modal model on the basic models of Gaurav Sahu. Then, the method of permutation and combination is applied to realize automatic combination by computer to overcome the shortcomings of Gaurav Sahu manual combination. Finally, the network model is trained and tested by hyper-parameter optimization method and cross-validation method to solve the shortcomings of manual parameter adjustment. Experiments on IEMOCAP dataset show that the performance of multi-modal combination model C3 is 1.56% better than that of Gaurav Sahu's multi-modal combination model E2.
【Key words】: Single modal model; Multi-modal combination model; Hyper-parameter optimization; Speech emotion recognition; Cross-validation; Automatic combination
0 引言
近年來,在语音识别、自然语言处理等领域,形成了一种从单模态分析到多模态融合的思维[1]。多模态融合的研究方法引起了不同研究领域和众多学者的高度关注。
有关研究者对多模态特征融合进行深层次的研究。Liu[2]等人提出LMF(Low-rank Multimodal Fusion)方法,利用低秩张量进行多模态融合,即对语言(Language)、视觉(Visual)和声学(Acoustic)这三种模态特征进行融合,以提高模型的识别率。Zadeh[3]等人采用TFN(Tensor Fusion Network)方法对情感进行分析。Sharma[4]等人提出一个多模态系统(SVMS),该系统基于面部数据和声学数据对性别进行识别,其实质是将面部特征和声学特征作为两种特征模态。
然而有相关的研究者将多模态特征融合的思想应用在多模态模型组合上,以探索研究不同组合模型的识别性能。Ftoon Abu Shaqra[5] 等人组合三个单模态模型(Simple Model、Gender-based Model和Age-based Model)得到一个组合的分类模型(Compound Model),该组合分类模型将三个单模态模型中每个标签的所有预测概率集中在一起,然后再对语音情感数据进行识别(识别的准确率达到74%)。Ftoon Abu Shaqra的组合模型将语音的性别、年龄和情感这三种元素联系在一起。Gaurav Sahu[6] 提出多模态模型E1(组合RF、XGP和MLP)和E2(组合RF、XGP、MLP、MNB和LR)并对语音情感标签进行识别,其思想是通过随机森林(RF)、极端梯度提升(XGB)、支持向量机(SVM)[7,8]、多项式朴素贝叶斯(MNP)、逻辑回归(LR)、多层感知机(MLP)和长短期记忆网络(LSTM)[9]作为单模态模型,并对七种单模态模型进行人为组合,得到多模态模型E2。Gaurav Sahu首先从音频信号中抽取8种时域信号作为音频特征,其次从文本信息中抽取TF-IDF(Term Frequency-Inverse Document Frequency)[10]作为文本特征,最后再组合音频特征和文本特征作为新的特征。
虽然Gaurav Sahu[6]提出的多模态组合模型E2能够取得比单模态模型较好的语音情感识别效果,但是存在人为组合单模态模型不全面和手工调参量大的缺陷,导致整个模型存在很强的主观性和识别率低。
本文在Gaurav Sahu的单模态模型上增加KNN、CNB和AdaBoost三个单模态模型,通过排列组合对单模态模型的预测概率进行排列组合,有效避免人为组合模型存在的主观性;为有效避免手工调整超参数,采用超参数优化方法和交叉验证方法对网络模型进行训练和测试,选出最优的多模态组合模型C3。
1 相关工作
1.1 数据预处理
(1)音频序列
语音情感信号“happy”和“excited”(“sadness”和“frustration”)的频谱图非常相似,将“happy”和“excited”(“sadness”和“frustration”)融合为“happy”(“sadness”)。除此之外,忽略了“xxx”和“others”的情感标签。融合后的语音情感标签如表1所示。
表1 融合的语音情感标签
Tab.1 Fused speech emotion labels
Before Now
anger anger
happy happy
excited
neutral neutral
surprise surprise
sadness sadness
frustration
fear fear
xxx /
other /
(2)文本序列
文本情感分类中存在一些对分类无意义的符号,需要进行数据预处理,即去掉文本序列中无关的“”、“,”等标点符号,如图1所示。
图1 文本标准化
Fig.1 Texts standardization
1.2 语音情感特征提取
从音频信号中计算出8维的音频特征,从文本信息中计算TF-IDF作为文本特征,具体如下:
(1)信号音高[11,12](Signal Pitch)
在时域中,自相关算法被广泛用于评估语音信号的周期性音高[4]。在本文中,使用短时的自相关算法,因为语音信号的采样长度是有限的。短时自相关形式被定义为:
(1)
(2)
其中,为序列的延迟,为信号的帧数,当接近无穷大,公式(1)变为长时自相关表达式(2)。公式(1)的最大值对应的等于音高。为了得到音高,对输入信号使用center-clipped[4,5]方法,得到:
(3)
其中,CL为门限值,将其设置为绝对输入信号的平均值的45%。接下来,计算的自相关函数,即:
(4)
最后,
(5)
(2)信号能量[6](Signal Energy)
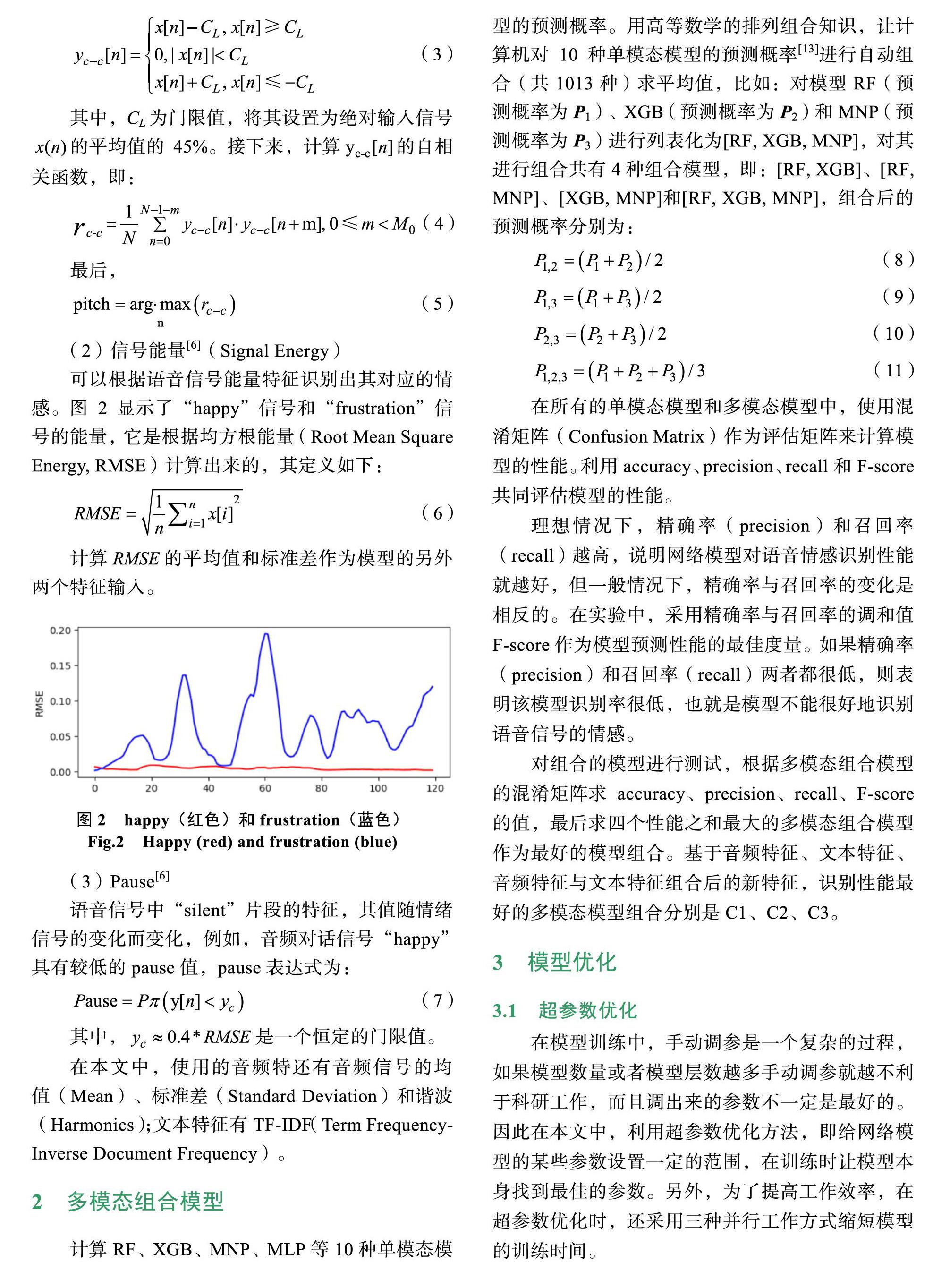
可以根据语音信号能量特征识别出其对应的情感。图2显示了“happy”信號和“frustration”信号的能量,它是根据均方根能量(Root Mean Square Energy, RMSE)计算出来的,其定义如下:
(6)
计算的平均值和标准差作为模型的另外两个特征输入。
图2 happy(红色)和frustration(蓝色)
Fig.2 Happy (red) and frustration (blue)
(3)Pause[6]
语音信号中“silent”片段的特征,其值随情绪信号的变化而变化,例如,音频对话信号“happy”具有较低的pause值,pause表达式为:
(7)
其中,是一个恒定的门限值。
在本文中,使用的音频特还有音频信号的均值(Mean)、标准差(Standard Deviation)和谐波(Harmonics);文本特征有TF-IDF(Term Frequency- Inverse Document Frequency)。
2 多模态组合模型
计算RF、XGB、MNP、MLP等10种单模态模型的预测概率。用高等数学的排列组合知识,让计算机对10种单模态模型的预测概率[13]进行自动组合(共1013种)求平均值,比如:对模型RF(预测概率为P1)、XGB(预测概率为P2)和MNP(预测概率为P3)进行列表化为[RF, XGB, MNP],对其进行组合共有4种组合模型,即:[RF, XGB]、[RF, MNP]、[XGB, MNP]和[RF, XGB, MNP],组合后的预测概率分别为:
(8)
(9)
(10)
(11)
在所有的单模态模型和多模态模型中,使用混淆矩阵(Confusion Matrix)作为评估矩阵来计算模型的性能。利用accuracy、precision、recall和F-score共同评估模型的性能。
理想情况下,精确率(precision)和召回率(recall)越高,说明网络模型对语音情感识别性能就越好,但一般情况下,精确率与召回率的变化是相反的。在实验中,采用精确率与召回率的调和值F-score作为模型预测性能的最佳度量。如果精确率(precision)和召回率(recall)两者都很低,则表明该模型识别率很低,也就是模型不能很好地识别语音信号的情感。
对组合的模型进行测试,根据多模态组合模型的混淆矩阵求accuracy、precision、recall、F-score的值,最后求四个性能之和最大的多模态组合模型作为最好的模型组合。基于音频特征、文本特征、音频特征与文本特征组合后的新特征,识别性能最好的多模态模型组合分别是C1、C2、C3。
3 模型优化
3.1 超参数优化
在模型训练中,手动调参是一个复杂的过程,如果模型数量或者模型层数越多手动调参就越不利于科研工作,而且调出来的参数不一定是最好的。因此在本文中,利用超参数优化方法,即给网络模型的某些参数设置一定的范围,在训练时让模型本身找到最佳的参数。另外,为了提高工作效率,在超参数优化时,还采用三种并行工作方式缩短模型的训练时间。
3.2 交叉验证(Cross Validation)
超参数优化网络模型后,第二次对网络模型训练时最优网络模型很少出现过拟合现象,但在预测模型性能时,对测试数据的拟合程度不是很理想。交叉验证方法可以避免测试数据的过度拟合,在研究工作中,采用K-fold交叉验证(K=10),即将数据分为10个子样本集,其中一个是验证模型的数据,其他子样本用于训练,交叉验证重复10次,每个子样本一次。该方法的优点在于,随机生成的子样本集被重复用于训练和验证,并且每次都验证一次。
4 实验及结果分析
4.1 实验数据
本文采用了IEMOCAP[14](Interactive Emotional Dyadic Motion Capture)数据集,该数据集是在南加州大学萨尔实验室建立的,并且包含来自10位对话者的对话,涉及约12小时的信息(音频、视频以及文本)。它标有10个类别的情感标签,即:愤怒(anger)、高兴(happy)、悲伤(sadness)、中性(neutral)、惊讶(surprise)、恐惧(fear)、沮丧(frustration)、兴奋(excited)、xxx(xxx)和其他(others)。然而,在研究工作中,仅仅利用了六种情感标签。
在计算并获取原始语音数据集IEMCOP的8维音频特征时,如果CPU只有8 GB的内存,那么最好读取1个session数据集,当然如果CPU内存容量超过16 GB,可以一次性获得5个session数据集。对5个session数据集的8个音频特征进行计算时最好是分二到五次计算,然后将计算的特征合并在同一个excel表单中。
4.2 模型部署
使用pycharm平台部署实验。网络模型来自Torch包和sklearn包。在整个实验中,采用RF、XGB、MNB、LR、MLP、SVM、KNN、AdaBoost、CNB和LSTM作为单模态模型。组合十个单模态模型得到1013个多模态模型,再求出1013个模型中四个性能(Accuracy、Precision、Recall和F-score)总和最高的模型组合。增加两个多模态模型E11和E21作为实验对照组,且E1和E11由单模态模型RF、XGB、MLP组合而成;E2和E21由RF、XGB、MLP、MNB、LR组合而成,唯一不同的是E1模型和E2模型没有经过超参数优化、交叉验证、并行处理。
4.3 實验结果
(1)基于音频特征的模型性能
在表2中,基于音频特征的所有单模态模型中,单模态模型XGB的F-score值最高。在使用超参数优化和交叉验证这两种方法后的E11,其F-score值高于先前的E1。四种性能之和最高的组合模型C1,其F-score值(60.98%)高于E1接近9.48%。此外,还可以看到学习模型LSTM(或MLP)的F-score值低于RF、XGB和KNN,更远小于C1。
表2 基于音频特征的模型性能
Tab.2 Performance of models based on audio features
Models Accuracy F_score Precision Recall
RF 55.92 56.92 56.86 57.69
XGB 61.54 59.67 59.35 60.28
SVM 30.27 29.01 30.44 30.35
MNB 22.33 9.67 14.09 18.35
LR 30.52 27.06 30.07 28.85
MLP 34.24 35.04 38.04 35.42
AdaBoost 33.27 30.29 34.09 29.68
KNN 56.58 53.79 52.95 56.10
CNB 26.30 18.46 14.06 26.89
LSTM 38.71 37.05 36.47 39.20
E1 56.60 55.70 57.30 57.30
E11 60.79 59.69 59.25 60.43
C1 59.49 60.98 61.51 61.09
C1:组合RF、XGB、MNB和LR
(2)基于文本特征的模型性能
在表3中,基于文本特征序列训练后的LSTM(或MLP)模型,其F-score值得到提升,特别是LSTM的性能(62.75%)超出所有单模态模型。虽然SVM的Recall值最高,但最终将F-score的值作为模型的真实性能评估。此外,组合模型E21的F-score值不仅高于E2而且低于C2。组合的多模态模型C2(68.01%)的F-score值高于E2(接近3.05%)。
(3)基于音频特征与文本特征组合的模型性能
在表4中,实验中发现单模态模型XGB的
F-score值高于所有的单模态模型。多模态模型E21的F-score值高于E2低于C2。另外,相对于表3而言,LSTM和MLP模型的四种评估值仍然保持在60%-70%中。虽然单模态模型AdaBoost模型的F- score值(37.60%)最低,但与AdaBoost模型组合的多模态模型C3(XGB+MNB+AdaBoost)的F-score值最高,C3的F-score值高于E2约1.56%。
4.4 实验分析
基于音频特征的LSTM模型对情感的识别力最低,而基于文本特征或者音频特征与文本特征组合后的LSTM对情感具有较好的识别效果。在采用超参数优化和交叉验证方法后,基于音频特征(或者文本特征)的单模态模型XGB在所有单模态模型中对语音情感识别具有较好的性能,但是在超参数优化时,XGB模型的参数范围不应太大,否则CPU工作线程的数量将被终止,或者CPU将因内存不足而停止工作。
Gaurav Sahu的多模态模型E1和E2是未经超参数优化和交叉验证,E1、E2与经过超参数调优、交叉验证自动组合的多模态模型E11、E21、C1、C2、C3的性能排序(根据F-score值大小来排序)分析如表5所示。在同等条件下的多模态组合模型中,E1、E2识别性能最低,且基于音频特征与文本特征组合的多模态模型组合C3对语音情感识别率最高(大约72.92%)。
虽然表5中的C1是音频特征中最佳的多模态模型,但是在图3(a)中,观察到“anger”、“happy”和“neutral”的识别率不是很高,特别是多模态模型C1对“sad”的识别能力最低。从图3(b)中可以看到“anger”、“happy”、“neutral”和“sad”的识别力在多模态模型C2中得到明显提升。在图3(c)中,多模态组合模型C3可以较好的识别“anger”、“happy”、“fear”和“surprise”,另外,“sad”的识别能力也得到了极大地提高。
表5 多模态模型性能比较
Tab.5 Performance comparison of multi-modal models
特征序列 识别性能排序/
F-score 综合排序/
F-score
音频特征 E1 文本特征 E2 音频特征与文本特征组合 E2 (a)音频特征,C1 (b)文本特征,C2 (c)音频特征与文本特征的组合,C3 5 总结 针对Gaurav Sahu的语音情感识别模型,存在识别效果低、手工调参量大和手工组合单模态模型的主观性,提出基于多模态组合模型C3对音频特征与文本特征组合的新特征序列进行情感识别,本文提出的多模态组合模型C3经过超参数调优、交叉验证和自动组合后,其性能(72.92%)优于Gaurav Sahu手工组合的多模态组合模型E2。在未来的研究工作中,将对多维特征融合的方法进行研究,进一步提高语音情感的识别率。 参考文献 [1]Soujanya Poria, Erik Cambria, Rajiv Bajpai, er al. A review of affective computing: From unimodal analysis to multimodal fusion. Information Fusion. 2017, 37: 98-125. [2]Z. Liu, Y. Shen, V. B. Lakshminarasimhan, et al. “Efficient low-rank multimodal fusion with modality-specific factors,” arXiv preprintarXiv: 1806.00064, 2018. [3]A. Zadeh, M. Chen, S. Poria, et al. “Tensor fusion network for multimodal sentiment analysis,” arXiv preprintarXiv: 1707.07250, 2017. [4]Sharma, Rajeev, Mohammed Yeasin, et al. “Multi-modal gender classification using support vector machines (SVMs).” U. S. Patent Application No. 10/271, 911. [5]Ftoon Abu Shaqra, Rehab Duwairi, Mahmoud Al-Ayyoub. Recognizing Emotion from Speech Based on Age and Gender Using Hierarchical Models[J]. Procedia Computer Science, 2019, 151. [6]Gaurav Sahu. “Multimodal Speech Emotion Rcogni-tion and Ambiguity Resolution,” 2019. 4. [7]劉梦迪. 基于网络舆情分析的智能手机用户反馈跨文化研究[D]. 清华大学, 2017. [8]V. Vapnik, C. Cortes. Support vector networks. Machine Learning, 1995, 20(3): 273-197. [9]S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, 1997, vol. 9, no. 8, pp. 1735-1780. [10]程一峰. 基于TF-IDF的音频和歌词特征融合模型的音乐情感分析研究[D]. 重庆大学, 2012. [11]M. Sondhi, “New methods of pitch extraction,” IEEE Transactions on audio and electroacoustics, 1968, vol. 16, no. 2, pp. 262-266. [12]Hu, Yakun, Dapeng Wu, et al. “Pitch-based gender identific ation with two-stage classification.” Security and Communication Networks 5.2 (2012): 211-225. [13]Ftoon Abu Shaqra, Rehab Duwairi, Mahmoud Al-Ayyoub. Recognizing Emotion from Speech Based on Age and Gender Using Hierarchical Models[J]. Procedia Computer Science, 2019, 151. [14]Carlos Busso, Murtaza Bulut, Chi-Chun Lee, et al. “Iemocap: Interactive emotional dyadic motion capture database,” Lang uage resources and evaluation, 2008, vol. 42, no. 4, p. 335.
