
感兴趣视觉特征耦合种子繁衍的图像检索算法
2018-12-22 08:05韩建敏李国伟王振飞
计算机工程与设计 2018年12期
韩建敏,李国伟,王振飞
(1.河南经贸职业学院 计算机工程学院,河南 郑州 450000;2.中原工学院 计算机学院,河南 郑州 450000;3.郑州大学 信息工程学院,河南 郑州 450001)
0 引 言
传统的基于文本的检索存在主观性与长耗时缺点,对此,出现了基于内容的图像检索(content based image retrieval,CBIR)[1]。但是,CBIR的主要问题是存在底层特征和高层语义概念之间的语义鸿沟[2,3]。
随着人们对图像检索的关注,出现了较多的方法,如符祥等[4]利用兴趣点的局部灰度值,获取局部Zernike。其次,通过得到的Zernike矩,测量兴趣点之间的Euclidean距离,寻找出最优匹配点。根据特征点的空间离散度进行相似度量。但是此技术没有将人机交互的相关反馈应用于算法中,致使该方法捕抓的特征并不一定符合用户的感兴趣特征,易导致语义鸿沟。刘保东等[5]设计了利用多特征和相关反馈的图像检索技术。该技术定义一种自适应阈值的SIFT特征算子,有效提取SIFT特征。引入AP簇类技术对SIFT特征进行簇类,将簇类的中心当作视觉单词,利用得到的视觉单词建立一个词典。再将之前获得的SIFT特征映射到词典中,利用VW直方图来表示图像。然后,测量不同直方图间的相似性,完成图像检索任务。但是,其采用的特征是属于全局特征,缺乏空间信息,特征之间关联性不强。Mania等[6]利用粒子在空间中的运动来搜索未知的未知,基于标签的相关图和不相关图调节特征矢量的权重值,可以改善检索精度。但该方法中只计算了相关图和不相关图的全局信息,没有根据局部信息准确对图像完成相关辨别,检索率不高。
对此,为了解决检索过程中的语义鸿沟现象,进一步提高检索性能,本文提出了基于自适应约束的种子繁衍机制ACSM的交互式图像检索,从用户对整个数据的交互信息有效地传播成对约束。利用ACSM从查询图像提取用户感兴趣的区域(ROI),然后通过测量图像与ROI之间的相似度来获得初始检索结果。然后,在整个数据库中,利用ACSM机制,对用户的相关反馈进行检索排序,从而显著地提高了检索性能。最后,测试了所提算法的检索精度。
1 基于自适应约束的种子繁衍机制
给定一对监督约束“链接”M和“非链接”C,执行一个核映射φ,将样本X={x1,x2,…,xn}映射到一个嵌入式内核特征空间F中,其中φ=[φ1,φ2,…,φn]=[φ(x1),φ(x2),…,φ(xn)]表示X到F的变换。根据成对的假设来嵌入样本[8],即两个链接的样本被映射得很近,而两个非链接的样本则被映射得很远。同时样本也根据平滑性假设来嵌入,使两个样本也变得类似于成对的样本那样接近或远离。
将目标函数中的自适应约束嵌入到视觉特征分布和监督约束的样本中,根据整体的数据分布使得“链接”自适应地接近,并且“非链接”自适应地变远。根据文献[9]描述,目标函数的核映射定义如下
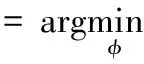
(1)
其中,tr(·)和·分别为踪迹和内积运算;λ、α和β为权重参数;归一化图Laplacian算子L=I-D-1/2WD-1/2,其具有X的关联矩阵W,度矩阵D=[dij]nn、dii=∑jwij;EM=∑(i,j)∈M(ei-ej)(ei-ej)T、EC=∑(i,j)∈C(ei-ej)(ei-ej)T,ei是n×n单位矩阵I的第i列;当tr(φ,EMφ)和tr(φ,ECφ)满足自适应约束条件时,tr(φ,Lφ)进行全局平滑作用;A=λL+αEM-βEC是一个广义Laplacian算子,EM和EC为约束信息。
为了完善模型(1)的应用,受到标签传播(label propagation,LP)的启发[10],LP是将种子标签从标记样本传播至未标签样本,本文在内核学习中引入了种子学习和传播,先学习一个种子核映射φl,再把它扩散到未知的子模块φu以降低计算复杂度。将内核映射φ分解为φl和φu,分别对应于监督样本和非监督样本,并将受限拉普拉斯分成下列计算
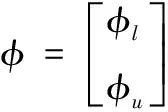
(2)
根据式(2)描述,式(1)可演变为
tr(φ,Aφ)
(3)
φl、φu的是根据将式(3)设置等于零的偏导数推导得到的,φu计算如下
(4)
此外,根据φl的形式可得到φ的表达式
(5)
其中,Il是与约束样本相关的单位矩阵。通过用φ的内积定义Mercer核[11]k(xi,xj)=φi,φj,所生成的核矩阵K表示如下
(6)
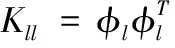
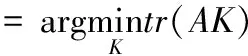
(7)
利用分解约束Laplacian算子将式(2)中A和式(6)中K求解,得到了如下种子核矩阵Kll所表示的目标函数
(8)
根据式(8),本文可通过解决以下的种子内核学习问题来学习种子内核矩阵Kll,表示为
(9)
Kll(i,i)=1, ∀xi∈X
然后,通过式(6)将Kll传播至K中。本文采用自对偶嵌入优化来执行式(9)中的种子学习,将这种判别性的核矩阵学习算法称作为自适应种子繁衍机制,其过程如下:
输入:X-样本集;M-必需连接约束;C-非链接约束。
输出:经学习的判别性核矩阵K*。
步骤1 形成拉普拉斯算子图,L,以及监督信息的矩阵EM和EC;
步骤2 计算约束Laplacian算子A:A=λL+αEM-βEC,并且将其分成4个子矩阵;
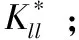
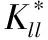
2 本文图像检索算法
感兴趣视觉特征耦合种子繁衍机制的图像检索算法的过程主要包含了4部分,其结构如图1所示。第1部分的交互式前景提取,旨在利用简单的用户交互来分割查询图像中的前景目标,并提取前景目标的ROI特征,利用ACSM保存的交互信息的统计特性。在第2部分中,对数据库中的图像分割,然后,提取局部特征,并存储于数据库。在第3部分中,测量了第1部分和第2部分之间的相似性,并将它们与查询图像前景对象的距离进行排序。由于颜色直方图(color histogram,CH)能有效表示图像的统计分布,所以我们使用CH作为图像检索的特征。利用RGB彩色空间是用来计算CH。在4部分,利用ACSM改进第3部分中的初始检索结果。从相关反馈中进行主动学习完成对图像再排序。
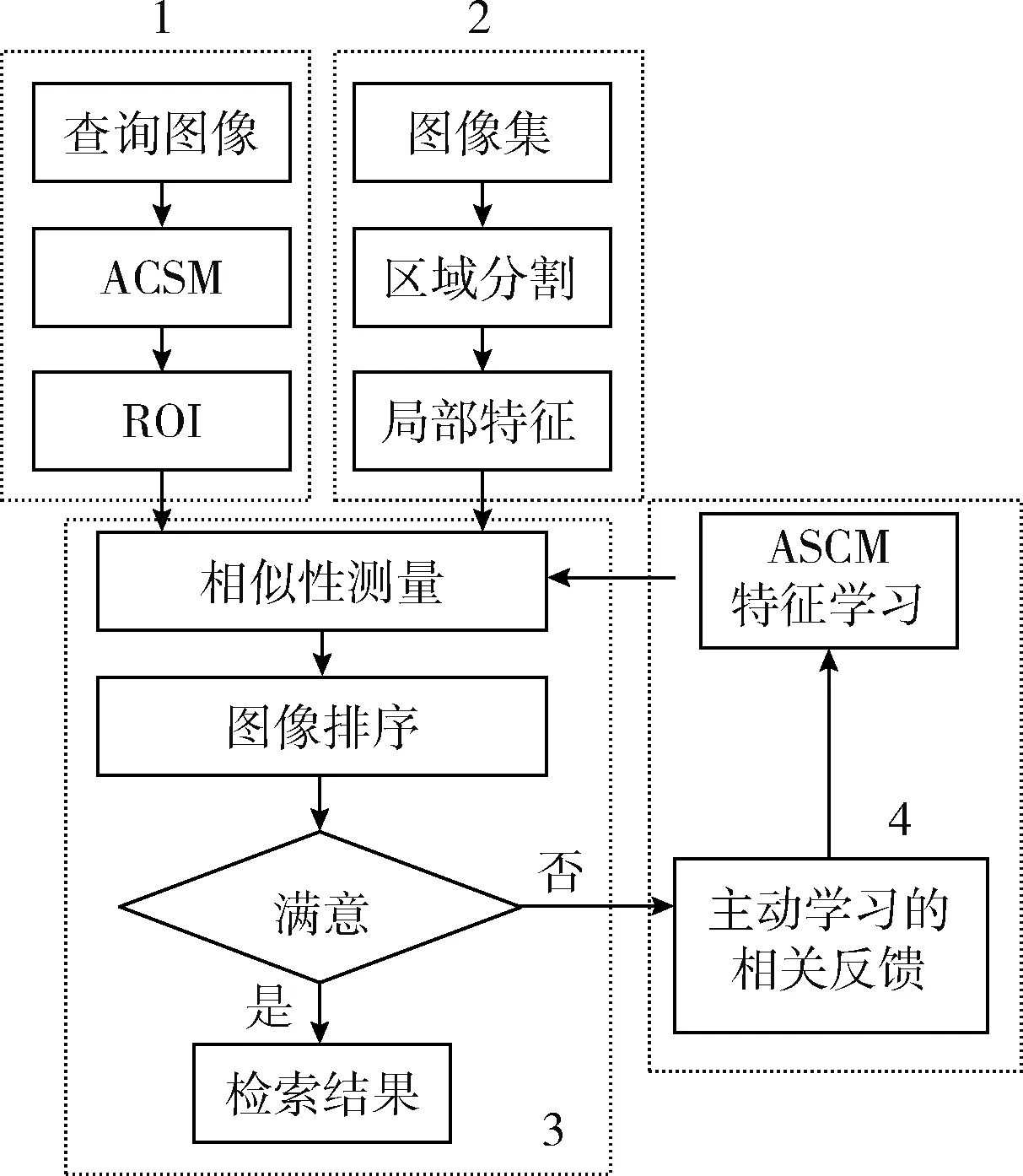
图1 本文算法的检索过程
2.1 ROI提取
给定一个图像,利用ACSM从查询图像提取用户ROI,通过测量图像与ROI间的相似度来获得初始检索结果。然后,利用ACSM在整个数据库中根据用户的相关反馈进行排序。对于ROI提取,均值平移分割(mean-shift segmentation,MSS)[12]由于具有良好的不连续性滤波特性,可以显著减少基本图像实体的数目,同时保留对象边界的显著特征。因此,本文采用MSS从查询图像中生成超像素,然后从超像素中提取出特征。颜色直方图能有效地代表色彩的统计分布,因此,其是一个很好的描述符来表示图像里的区域统计特性。所以,通过颜色直方图作为前景提取的特征。为了简单起见,在RGB色彩空间中计算CH。首先,将每个色彩通道平均量化为4组,然后计算大小为16×16×16=4096的特征空间里的每个超像素的颜色直方图。此外,采用巴氏系数wij来计算两个超像素间的相似性[13],两个超像素xi和xj之间的wij计算公式定义如下
(10)
其中,H(x)是一个超像素x的归一化颜色直方图;M代表维数。
在ROI提取中,符合前景标记的超像素为前景种子,而符合背景标记的超像素则为背景种子。从背景中提取前景目标时,需要将不确定的超像素确定为其属于前景还是背景,因为只有一小部分的前景和背景超像素是由用户指定的,因此,想要准确地从背景中提取出前景目标,仍然是一个具有挑战性的问题。为了能有效地捕获前景/背景种子中的全局判别性结构,将ACSM运用到所有的查询图像像素上。首先,通过式(9)学习种子核矩阵,在前景/背景种子中生成对约束。如果两个种子有相同的标记,则它们属于必须链接约束,反之,如果两个种子有不同的标记,则它们属于非链接约束。然后,在式(6)通过将种子核矩阵传播获得查询图像的完整核矩阵。为了实现前景提取,在已学习的完整核矩阵上进行全局k-均值计算[14],将前景/背景的一个标签指派给不确定的部分。
ROI提取,如图2所示。

图2 ROI提取
2.2 基于ACSM的图像排序
在获取前景目标之后,引入Euclidean距离测量ROI与数据库中局部特征间的相似性,Euclidean距离的大小反应了两个像素间的相似性[15],其越小表示其差异越小。Euclidean距离定义如下
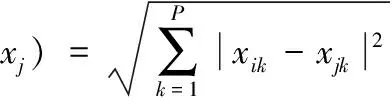
(11)
其中,xi,xj分别为ROI与数据库的局部特征;P为查询图像数量。
在测量Euclidean距离之后,基于相似性对图像进行排序。如果检索性能非尽如人意,用户可以为检索结果提供相关反馈(相关/不相关)以用于图像再排序(图1中的第4部分)。因此,可从相关的反馈中生成图像的成对约束,从查询和相关图像中生成必须链接对,而从查询和非相关图像中生成非链接对。然后,在成对约束和图像上执行ACSM,将用户的相关性反馈传播至整个数据库并且学习全局判别性结构用于图像再排序。通过下文描述的主动学习部分中的学习特征来衡量图像之间的相似性,以便排序。ACSM对相关反馈下的低层图像特征与高层语义的相关性的学习是非常有效的。
2.3 主动学习
主动学习主要是通过主动选择策略选取信息量较多的成对约束,用尽可能少的约束信息来尽量多地提高簇类效果。常用的方法是将无标签的数据构成一个样本池,在根据选择策略进行估计,从而选择低置信度的数据完成标签。本文选择最近边界策略(recent frontier policy,RFP),定义如下
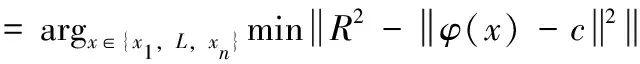
(12)
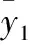
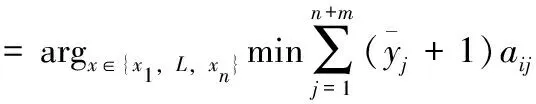
(13)
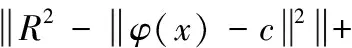
(14)
式中:α∈[0,1]为调整因子。由于不同样本数量与分类SVM球面半径不相等,导致其计算较为复杂。为了便于计算,将初始样本计算获得的无监督SVM模型的R进行归一化。当数据获得值小于阈值时,说明数据是聚类代表样本点,对优化模型最有价值,选取作为标签样本。
基于ACSM机制的图像检索算法描述如下:
输入:查询图像和图像数据库。
输出:图像检索结果。
步骤1 从用户互动中生成区域级别的成对约束,并根据“1基于自适应约束的种子繁衍机制”的过程执行ACSM;
步骤2 执行全局k-均值算法以从查询中提取ROI;
步骤3 对图像排序并且选择相关/不相关的检索结果;
步骤4 从相关反馈中生成图像的成对约束,并再次执行ACSM;
步骤5 对图像排序以输出最后检索结果。
3 实验结果与分析
3.1 实验准备
为测试本文算法性能,选择在Corel图像集中测试。Corel图像集由10类图像组成[16]:非洲、海滩、建筑、公车、恐龙、象、花卉、马、山川与食物,每类含100幅,共1000幅,如图3所示。测试环境为:Intel i3 8核CPU,3.50 GHz,8 GB RAM,64位WIN8系统。借助Matlab2012作为测试软件。为达到最优的性能,通过多次实验得到了本文算法的参数:α=0.26,β=0.25,λ=0.21。为突显本文算法的优异性,选取当前流行的检索技术视为对照组:文献[4]、文献[5]和文献[6],为便于记录,依次记为A算法、B算法、C算法。

图3 Corel图像库
3.2 性能评价
为评估算法检索性能,选择常用的3种评价指标:查准率(Precision)、召回率(Recall)和F值。F值为Precision和Recall的加权评价值[17],其函数表示如下
(15)
(16)
(17)
其中,Tp为正确识别伪造数量;Fp为误判为伪造数量;FN为漏检的伪造数量,η为常数,通常取1[18]。
3.3 实验结果
为评估算法的性能,在Corel中,分别通过A算法、B算法、C算法与本文算法进行测验,实验中给定一幅查询图像,利用不同的算法返回得到16幅最相似图像。图4为查询图像(query image,QI)。图5~图8分别是本文算法、C算法、B算法、A算法返回的图像。从图5~图8中得知,本文算法返回的结果均含有大象,与QI相似性最高;图6中返回的结果中出现了一匹马,与QI中的对象(大象)不相关,见图中最后一张;图7中返回的结果中出现了马和恐龙2幅图像,与QI中的对象(大象)不相关,见图最后两张;图8中返回的结果中出现了马和恐龙3幅图像,与QI中的对象(大象)不相关,见图中最后3张。

图4 查询图像

图5 本文算法检索结果

图6 C算法检索结果

图7 B算法检索结果

图8 A算法检索结果
根据图5~图8结果得出,提出算法取得了优良的效果,得到的返回图像与查询图像相似度高。主要是本文引入用户交互和主动学习的相关反馈,根据种子核映射,定义了ACSM算子,以提取用户ROI特征。再利用Euclidean距离测量查询图像与数据库图像的相似度,利用测量的相似度来获得初始检索结果。最后,利用ACSM机制从用户的相关反馈中主动学习来排序,使其能有效从ROI与相关反馈中学习图像的低层特征和高层语义之间的关联,提高图像检索精度。A算法中由于没有将人机交互的反馈机制在检索算法使用,导致该算法获取的相似区并不一定符合用户的兴趣区域,出现了语义鸿沟。B算法中其采用的特征是属于全局特征,缺乏空间信息,特征之间关联性不强。C算法中计算了相关图和不相关图的全局信息,没有根据局部信息准确对图像完成相关辨别,检索率还有待提高。
为定量评估算法性能,利用评价指标Precision、Recall和F值衡量。图9为在Corel中不同类图像的评价Precision统计,从图9中看出,对不同种类图像,提出算法的Precision取得了良好表现。

图9 不同类别图像的平均Precision
图10为不同检索方法得到的P-R曲线与F值。图10(a)为P-R曲线,图10(b)为F值。根据图10中看出,本文算法的P-R曲线走势平稳,相对性能优于其它3个对比算法,综合表现最优。F值综合了P和R的结果,反映了整体指标,从图10(b)中看出,本文算法F表现最佳,说明其综合检索性能最优。
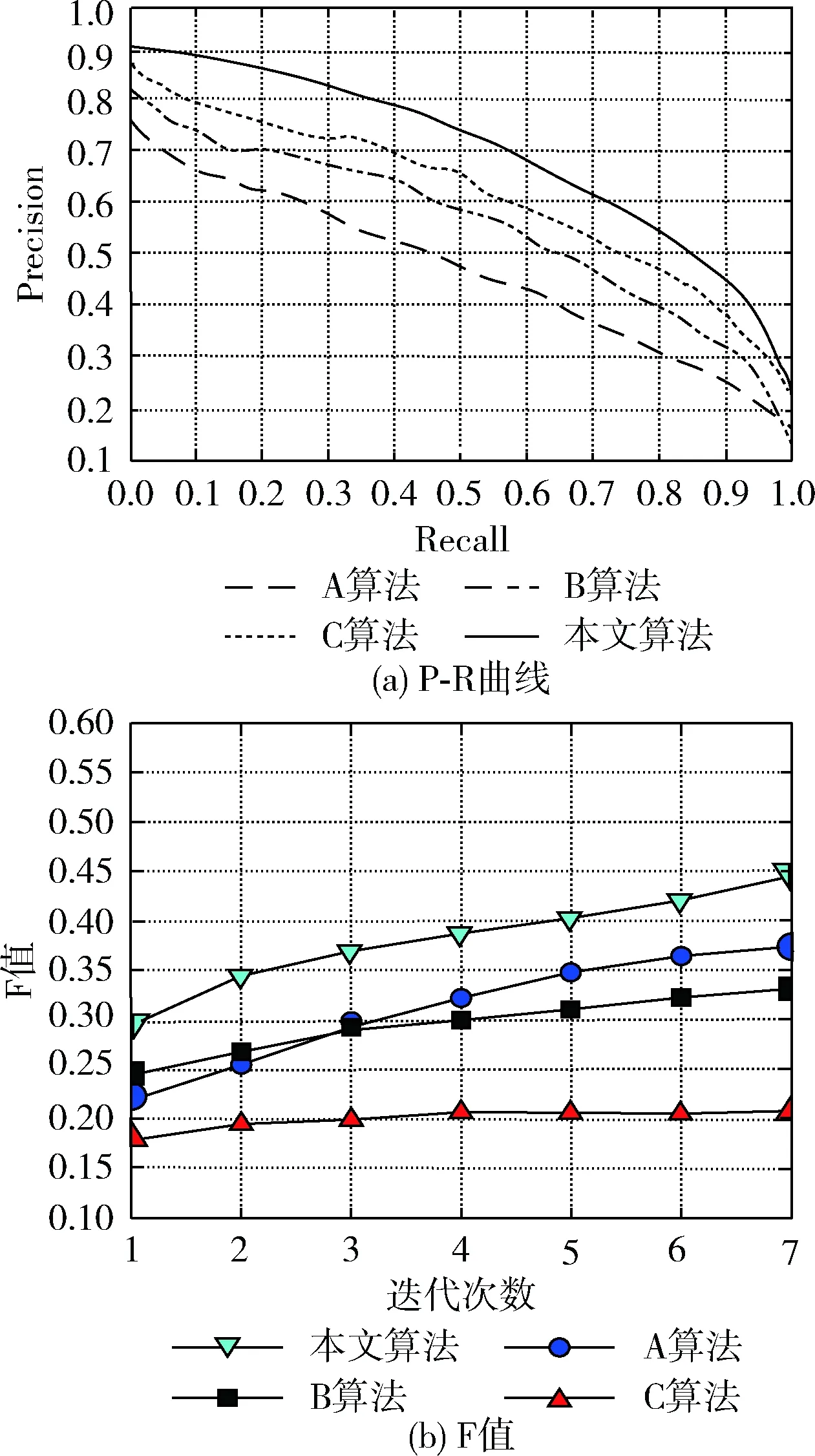
图10 不同算法的定量评价
4 结束语
为减少检索中的语义鸿沟现象,提高图像检索性能,通过自适应传输监督信息的全局特征空间进行判别学习,设计了感兴趣视觉特征耦合种子繁衍机制的图像检索算法。为了提高查询图像中用户兴趣的捕获和表示能力,采用区域分割的局部特征代替全局特征。定义了一种ACSM算子,提取图像的ROI,从用户对整个数据的交互信息有效地传播成对约束。ACSM能够有效地从用户的互动中学习图像的底层特征与高层语义概念之间的相关性。其在整个数据库中根据用户的相关反馈进行检索结果排序,并有效学习给定特征与约束的全局判别结构,从而显著地提高了检索性能。实验结果表明提出的算法检索性能优异,有效降低了语义鸿沟现象。
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
小学阅读指南·低年级版(2017年1期)2017-03-13
专利代理(2016年1期)2016-05-17
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
