
基于深度学习的二维码定位与检测技术
2018-12-22 07:53蔡若君陈浩文叶武剑刘怡俊吕月圆陈穗霞刘峰
现代计算机 2018年33期
蔡若君,陈浩文,叶武剑,刘怡俊,吕月圆,陈穗霞,刘峰
(1.广东工业大学,广州 510006;2.广东迅通科技股份有限公司,广州 510075;3.南京邮电大学图像处理与图像通信重点实验室,南京 210046)
0 引言
二维码是近年来颇受瞩目的一种新的编码方式,可以存储更大量、更多种类的数据类型,广泛应用于购物、交通工具等场景。传统的二维码定位方法,采用图像处理的相关操作,标记找到二维码的三个特征区域以定位出二维码,再以相关的二维码扫描算法加以检测。
然而,传统的定位方法需要运用图像匹配的方法,而ZBar等算法对二维码分辨率、角度的要求较高,这种方法既麻烦,又只能得出粗略的二维码定位加以判断检测,其效果不好且效率低。
深度学习是为了模拟人脑作分析学习的建立的神经网络,在多层神经网络上运用各种算法解决多种问题。卷积神经网络(CNN)为其中重要算法之一,包含了一个由卷积层和子采样层构成的特征抽取器,极大地简化模型复杂度,减少参数。
为了更高效定位二维码,本文采用了基于Mask R-CNN(Region-based CNN)[1]的模型,提出了基于深度学习的二维码定位与检测技术。定位出图中处于不同位置的多个二维码,同时简化前期处理步骤,提高识别速率。
1 相关工作
二维码作为大量信息的简便的载体,其定位与检测技术也是我们应该重点研究的。
传统的定位检测技术是结合图像匹配的二维码扫描算法的方法。方法主要是对二维码图像作图像处理[2],找出二维码的三个特征点以定位二维码,再结合如ZBar的扫描算法,扫描二维码并检测。
Lingling Tong等[3]通过计算分析图像的LBP特征得到二维码的初定区域,根据QR二维码图像中黑白模块数的比接近1:1的特性来准确定位QR二维码位置。
屈德涛[4]等人提出了利用级联AdaBoost[5]分类器训练检测QR码,实现在复杂情况下识别二维码。
相比于传统的检测技术,基于深度学习的定位技术显示出较大的优势。
Girshick[6]等人提出的R-CNN算法是目标识别算法的先例,该算法使用候选框获取目标可能在的位置,并用CNN代替传统的提取特征法,最后用SVM分类器识别。Fast R-CNN[7]改进了Selected Search法选取候选框;Faster R-CNN[8]则在其基础上,提出了RPN网络,对RPN预测的区域计算回归损失。
针对R-CNN系列的两级算法,one-stage的YOLO算法[9]出现。YOLO算法在全连接层即完成了物体分类和物体检测,提高了检测速率;YOLO v2[10]去掉了全连接层,接上BN做下次卷积输入的数据归一化,并提高输入图片的分辨率和多种尺寸的图片进入训练,速率仍有提高,却存在较大的漏检率,检测结果却不够精确。
相比之下,Mask R-CNN增加了预测掩码的分支,更进一步改善了目标检测的准确率,加上起高速率,在对二维码的定位与检测上,保证了其实时性,解决了现阶段不能实时并同时准确检测出多个二维码的问题。
2 基于深度学习的二维码定位与检测技术
本文的实验框架如图1所示,包括了制作数据集、训练网络、测试结果等部分。
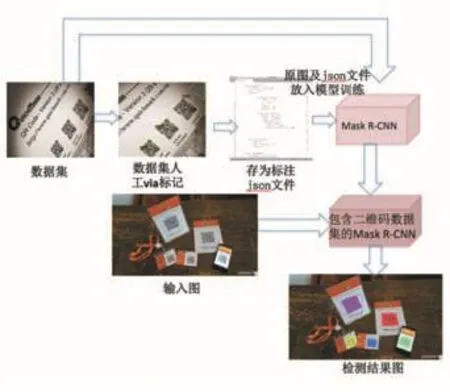
图1 本文提出方法结构图
2.1 训练数据集
以COCO[11]数据集为基础,该数据集包含了91类目标,328000影像和2500000个标签,考虑到其训练好的图像包含了大量自然特征,使用其预训练的权重,用迁移学习的方法,将数据集输入训练模型。
在制作数据集的过程中,从网页上搜索并选取包含二维码的图片,本文采用了VIA工具,对采集到的二维码图片做人工标注,对每个图中二维码以多边形点标注,并记为类“QR Code”,保存最终标签数据集为.json文件,以供训练模型使用。
本数据集包含多种情况、角度下的二维码,如图2所示,其标签信息.json文件如图3所示(其中size代表图片的像素值,regions包含了所有点的x、y坐标值,name表示标注信息为QR_Code)。
训练时,配置模型的输入尺寸为1024×1024以保证训练过程中获得最高的准确率。尽管图像相对较小,模型可以自动地重新调整图片的输入尺寸。本采取的momentum优化算法,设置学习率为0.001,mo⁃mentum为0.9,以获取最佳检测性能。

图2 包含各种大小角度二维码数据集

图3 数据集中某张图片的标注信息
2.2 网络结构
Mask R-CNN[1]利用ResNet-FPN[12](残差网络-特征金字塔网络)提取图片特征,传入两级网络,其一是采用区域建议网络(RPN)读取特征图并生成一个可能目标区域,二级生成可能分类以及生成边界框和掩码。如图4所示。
(1)RPN 网络
RPN使用滑动窗口在卷积过程扫描图像的主干特征图,通过滑动窗口扫描、预测,选了更好的含有目标的区域(anchor),并精调了anchor的位置和尺寸。对于重叠部分,选择最高前景分数的区域,得到最终可能的目标区域,传入下一阶段。
(2)分类边界框及掩码
平行于预测分类和坐标信息,这一阶段添加了一个掩码预测分支。这个分支用FCN(完全卷积网络)[13]对每个ROI(Region Of Interest)作像素级别的预测,生成一个m×m的掩码,可以得到更准确的预测掩码。
对每个掩码,采用ROIAlign层,使用双线性插值来计算每个ROI中的固定取样位置的输入特征的精确值,并聚合结果值,可以保证掩码精确对应到原始输入图像。同时,将矩形框分类和坐标回归并行进行,简化了网络的流程。
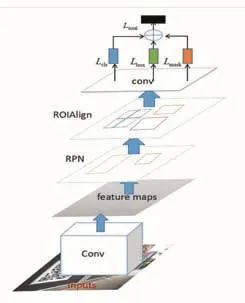
图4 Mask R-CNN结构图
该网络的损失函数如下式所示:
其中,Lcls为分类损失,Lbox为bounding-box回归损失,Lmask为实例分割损失。
2.3 实验结果分析
经过对标记好的二维码数据集训练好以后,将其模型运用到Mask R-CNN中,放入一些含有二维码的图片和不含二维码图片进行检测,可以看到较好的效果。部分图片结果如图:

图5 正面的二维码检测
由图5、6、7、8可以看出,本文所提方法在不同的情况的二维码均能定位检测出。Mask R-CNN在修改了ROIAlign双插值法以及添加mask分支后,其检测更为精确,应用在二维码的定位检测上,可以一次性同时识别出同一图片上的多个二维码,即高速又高效。

图6 有角度的二维码检测

图7 背光下的二维码检测

图8 反光下的二维码检测
3 结语
本文提出一种基于深度学习的二维码定位与检测法,在复杂场景和背光反光等的场景中依旧就较好的检测效果。在实验环境下,本文所提的方法具有较好的定位与检测效果。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
童话世界(2020年32期)2020-12-18
心声歌刊(2020年5期)2020-11-27
导航定位与授时(2020年5期)2020-09-23
中国外汇(2019年20期)2019-11-25
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
海峡姐妹(2018年2期)2018-04-12
人大建设(2018年12期)2018-03-21
人大建设(2017年5期)2017-04-18
