
基于随机森林的风力发电预测
2018-12-06 06:17:28中国矿业大学吴东剑张龙港朱大君高鹏超
电子世界 2018年22期
中国矿业大学 吴东剑 张龙港 朱大君 高鹏超
1.背景
随着科技的进步,社会的发展,对电力的需求会越来越大,工厂、家庭等方方面面都需要电力的供应,对电力的需求是一沉不变的么?显然不是的,像家庭用电,在每天的波动中,晚上是绝对的用电高峰期,而白天和夜里则相对较少。如果按照每月负荷来考虑,某些地方在夏天会达到用电高峰期,但是在另一些地方,冬天所带来的灯具照明时间的增加,会使用电量高于夏天的用电量。工厂用电则与家庭用电完全不同。根据实际工厂的生产制度不同,三班倒、二班倒和全天不停工生产的日负荷波动是不相同的。同样的,月负荷会根据生产不同的产品、不同的经营策略都有所不同。既然所需要的电力供应在不同的时间段是不同的,那么我们就需要对电网内所提供的电力供应进行调整,使其满足实时电力需求。火力发电作为现阶段我国的主要供电手段,其发电量无法快速根据需求进行调整。因此,调节的重任就落在了可再生能源的头上,可再生能源又叫做清洁能源,主要生产是靠着风机(风能)、和轮机(水电站)来实现的。
2.国内外现状
2015 年上半年能源局统计数据:2015 年上半年风力发电后无用电量为 175 亿千瓦时,电能无用率为15.2%,其中甘肃(无用电量为 31亿千瓦时、电能无用率达到 31%)、新疆(无用电量达到了29.7 亿千瓦时、电能无用率为 28.82%)、蒙西(无用电量 33 亿千瓦时、电能无用率 20%)、吉林(无用电量 22.9亿千瓦时、电能无用率 43%)等地区。因此需要一种切实有效的方法来防止可再生能源发电的浪费,实现与电力需求的匹配。
在国外也是相同的情况,早在19世纪末,丹麦人就首先研制了风力发电机。而在1891年,丹麦就建成了世界第一座风力发电站。现在丹麦已拥有风力发电机3000多座,年发电100亿度。但是风力发电量与负荷量不匹配问题依然大量存在。
发电量大带来的不仅仅是能源充足,更多的是机械损耗和浪费能源地区不匹配带来的能源浪费。中国弃风率最大的吉林省,半年弃风达22.9亿千瓦时,这些能源如果输送到电力缺乏的地区将带来巨大的收益。同时,生产这些电力所造成的风机老化、磨损导致的经济损失,我们不能忽略不计。因此,必须使用一种方法来预测接下来的地区负荷情况,若负荷降低。在基础发电(火力发电)基本不变的情况下,使可再生能源(风能,海洋能)发电设备停运,这可以降低设备运转所产生的磨损,减少维护费用,同时减少能源浪费。当负荷过大,或者与本地区的电网相连的其他区域发生电力供应不足的情况下,我们可以使更多的可再生能源发电设备运行,甚至满负荷运行,在电力系统能承受的负荷下,最大程度的满足地区电力需要和实现电力的区域性匹配。
3.方法介绍
我们所采用的方法就是负荷预测。负荷预测是根据系统的运行方式、决策方式、本身条件与对社会的影响等诸多因数,在满足一定精度要求的条件下,确定未来某特定时刻的负荷数据,其中负荷是指电力需求量或用电量。由于电力负荷是一个非周期,规律不明显的变化数值,因此,传统的预测方法对负荷预测效果不佳。目前短期负荷预测理论已趋于成熟,可分为经典预测方法、传统预测方法与智能预测方法三类。传统预测方法对于波动性大,规律不明显干扰大的地区不适用。但其结构原理简单,易于实现。在智能预测方法里,人工神经网络算得上是一大热门,它具有很强的自主学习能力,能模仿人的思考方式,对于非结构、非精确性具有极强的适应能力,能够拟合非线性曲线,得出接近于实际情况的模型结构。但是基础的数学模型依赖于主观经验,泛化误差大,由于它需要不断的学习,它的收敛速度很慢,要达到实际可用的状态需要进行大量的计算和学习。
本文将基于随机森林回归算法对某个区域的负荷进行预测,从而对可再生能源的出力情况给出建议。随机森林回归算法具有精度高、收敛速度快、调节参数少和不会产生过度拟合的问题。最后实验结果表明,该方法可有效的预测地区负荷波动情况,准确度较高。
4.风力发电
为什么要集中对风力发电进行预测。众所周知,风电作为清洁能源中最大的出力部分,在电网供电系统中具有重要作用。风力发电有他独特的有利因素:首先是政策支持,我国现如今需要将传统的火力发电等污染型发电方式转换为清洁的发电方式,风力发电是最成熟、可靠的一种,国家会对风力发电进行大量扶持和帮助,在未来风力发电装机容量会大幅度上升。其次是发展潜力大,风在自然界中广泛存在,不会消失和停止,经过建造的风力发电设施可以出力很长时间,实际的产生价值远大于本身建造成本。最后就是互联网+,随着科技和社会的发展,通过网络实现对设备的控制变得越来越流行,由于风力发电常常位于偏远或者人烟稀少的地区,以往对于发电机组的控制是很复杂的,从最近互联网产业发展以来,对风力发电的控制变得很容易和精确。如果电力供应不足,可以使更多的风机转动,当供应富余时,可以使部分风机停止转动,减少发电量同时减少机械磨损。要想实现精准、可靠、高效的发电-用电匹配,就要进行负荷的预测。
5.决策树,随机森林原理
随机森林算法是Leo Breiman结合bagging集成学习和随机属性子空间理论提出的监督学习算法。算法通过bootsrap重采样方法对原始样本进行采样,每个样本大小与原始样本相同;为每个bootsrap样本建立CATR决策树模型;最后,将多个CATR决策树组合为随机森林,森林中每个决策树的投票结果是最终的预测结果。
5.1 CATR决策树
1970年末到1980年初,Quinlan提出了ID3决策树算法,后来改进了ID3决策树算法,提出了C4.5决策树算法。1984年,Breiman和其他统计学家提出了CATR决策树算法。CATR是一种二元递归分割技术,每个非叶节点被划分为两个叶节点。三种算法都使用自顶向下的贪心方法来构造决策树,但不同的是属性选择度量。在每个决策树的生长过程中,选择某一属性作为分裂节点,根据属性选择度量选择最优属性,这就决定了节点属性分裂的条件。其中,ID3决策树算法采用信息增益作为属性选择度量,C4.5决策树算法选择增益率作为属性选择度量,CATR决策树算法使用gini index作为属性选择度量,CATR决策树算法使用gini index作为属性选择度量。采用最小二乘偏差作为回归树的属性度量。
5.2 随机森林算法
随机森林回归是由很多回归决策树模型组成的组合分类模型,且参数集是独立同分布的随机向量,在给定自变量 X 下,每个决策树回归模型都会有一个预测结果。它的基本思想与流程如图1所示:

图1
首先,利用 Bootstrap 抽样从原始训练集抽取 k 个样本,这 k 个样本的样本容量都与原始训练集一样,如上图1所示。然后,对这些样本分别建立 k 个决策树模型,得到 k 个回归结果;最后,对这 k 个结果取均值,得到最终预测结果,具体的结构图如图2所示:
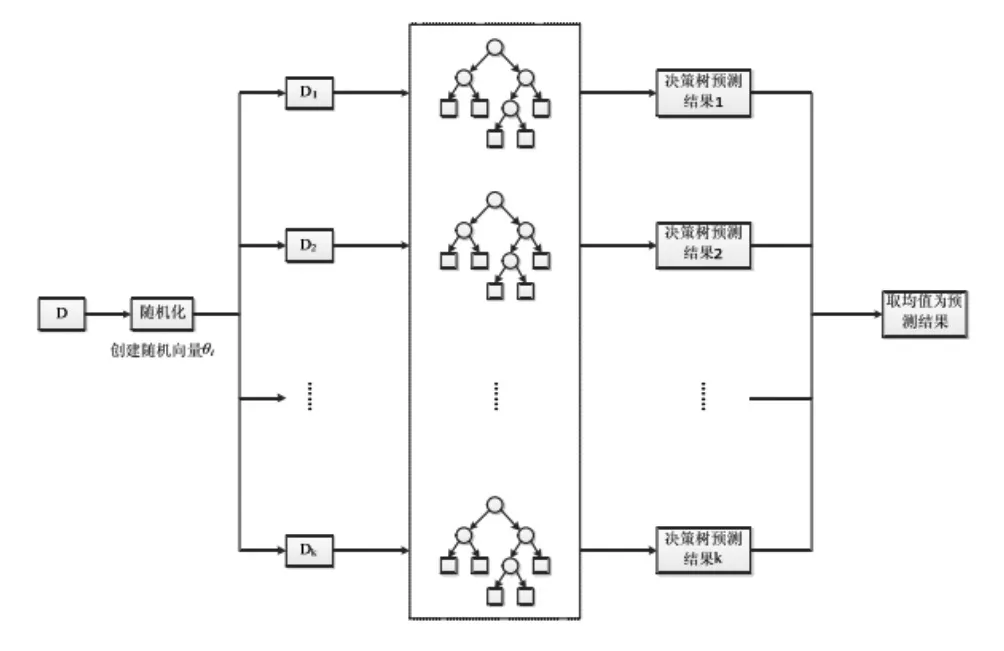
图2
随机森林算法的基本数学流程如下:
(1)首先利用bootstrap 重抽样的方法采取训练集并随机产生k 个训练集θ1,θ2,…,θk这每个训练集可以生成对应的决策树也即是随机森林中树的个数。
(2)已知样本的维数为M,在节点分裂的过程中,就从M 维特征中随机抽取 m 个特征作为此节点的分裂特征集,m 值根据样本量的大小设定,在不进行其他改进方法下,一般 m 的值在整个随机森林形成过程中维持不变,在 R 语言中的 Random forest 包中就是M 的大小确定。
(3)对每个决策树都不进行剪枝处理,使其得到最大程度的生长。
(4)当有一个新的数据X=x,单棵决策树T()的预测可以通过叶节点的观测值取平均获得。假如一个观测值Xi属于叶节点且不为0,则权重向量为:

(5)在给定自变量 X=x下,单棵决策树的预测值就通过因变量预测值加权平均得到。单棵决策树的预测值由下式得到:



因此,在给定X=x的条件下,所有因变量观测值的加权和就是所得的预测均值。权重随自变量X=x的变化而变化,且当给定下 Y的条件分布与X=x下Y的条件分布越相似,其权重越大。
6.在随机森林回归算法上进行短期负荷预测实际应用分析
在电力系统中,进行负荷预测时,我们主要是根据已经有的一些数据,去建立相应的模型,进而对负荷进行预测,从而进一步描述其发展规律。作为现代社会中的一种新型算法,随机森林回归算法在于支持向量机等算法在各方面进行比较时,对于不同的研究者来说,每个人的观点都是不一样的,一般在用这两种算法进行负荷预测时,主要是从精度与性能两方面进行比较。从算法的性质上来说,这两种算法都是智能的,所以,在对二者的结果进行分析时,除了对应选择的特征量不同进行比较是,还应对所选取的样本量大小进行一定的分析,较大或较小时,对预测的准确程度进行分析。在本篇文章中,所用数据为2016年1月到2017年12月的样本集。
本篇文章中,所用的数据全部来源于山东省某地区所提供的电力负荷信息,电力负荷数据包括发电类型,同时还有每个月的具体发电量,以及各种不同的负荷的用电比例。
6.1 负荷预测结果的评估标准
(1)平均绝对误差
回归预测所预测的是负荷的具体值,当我们对一个模型的效果进行评估时,一般来说,我们常常通过与实际值之间的差值来评判好坏。在预测类的文章中,常用平均绝对误差(MAPE)进行分析与评估。平均绝对误差是所有单个观测值与算术平均值的偏差的绝对值的平均。与平均误差相比,平均绝对误差由于离差被绝对值化,不会出现正负相抵消的情况,因而,平均绝对误差能更好地反映预测值误差的实际情况。
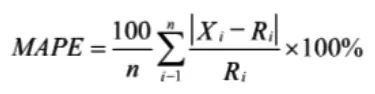
在对具体的模型进行分析时,平均绝对误差越小,说明我们所使用的算法及模型的准确率越高,预测的结果也就越好。其中:Ri是实际的负荷值,Xi是利用模型得到的预测值,n是预测的数量。
(2)单个变量分析
在本篇文章中,对单个变量进行分析,来判定在单个变量的情况下,预测效果的不同,根据p的值,其实并不能说明预测结果究竟是怎样的, 只是可以从统计学的角度上来说明结果差距的大小。
P值的大小对于二者之间的预测差异率有着很大的指导意义,一般来说,P 值越大,说明存在的差异就越小,相反的,P值越小,差异越大。而当P小于某一个确定值时,二者间就可以看成是完全不同的,这个值一般取0.05。
6.2 实际数据分析
从前文中,通过对变量以及一些相关性的分析,我们可以得到,对于电力负荷来讲,很多因素对于负荷的预测都有着很大的影响,最典型的就是温度、湿度以及季节的不同。本部分将在这些因素的基础上,进行电力负荷的预测,另外处于严谨以及全面性的考虑,我们选取的数据横跨四个季节两年,基本上可以满足预测的要求。
在进行预测时,我们根据随机森林回归算法进行了模型的建立,并且进行了仿真程序的编写,并在调试后进行检验,在误差允许的范围内,我们发现,该仿真程序基本可以正常预测电力负荷,具体程序如下:


在将我们所取得的两年的真实数据代入到程序中进行运行以后,我们变可以得到具体的预测结果。如图3所示:

图3
对预测所得图形进行分析,我们可以得出,样本中采集了24个月的风力发电数据,并且数据分为训练集和测试集,比例为0.7:0.3。建立回归随机森林模型后,通过上图我们可以发现,树木数量对于随机训练结果存在影响,随着树木数量增加,正确率有所上升,但是当树木数量超过40时,正确率就基本保持不变了。并且通过最终的分析计算,我们可以得出该模型用于预测本文中的电力负荷时,回归正确率为0.81。
7.综述
由上述分析可以得知,采用随机森林的预测模型可以对某地区短期负荷进行比较准确和有效的预测,得出的结果可以帮助当地供电站对风力发电机组的运行状态进行调整,以便于实现更精确的电力供需匹配和降低机械损耗。
猜你喜欢
中学生数理化·八年级物理人教版(2023年6期)2023-05-25 11:59:36
环球时报(2022-06-15)2022-06-15 15:21:32
科学大众(2021年9期)2021-07-16 07:02:50
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
下一代英才(酷炫少年)(2017年3期)2017-06-15 13:00:06
学与玩(2017年4期)2017-02-16 07:05:40
山东工业技术(2016年15期)2016-12-01 05:31:27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
