
一种基于多视图协同学习的App分类方法
2018-12-03 02:37,,
浙江工业大学学报 2018年6期
,,
(浙江工业大学 计算机科学与技术学院, 浙江 杭州 310023)
随着智能手机的普及,出现大量的App(移动应用程序),对它们进行语义分析并合理分类是实现许多智能服务的前提,如检索和推荐、安全分析、用户画像和精准广告等[1-3]。虽然部分App下载平台(如App store,Google play)已经对其拥有的App进行了分类,但下载平台提供的分类具有平台信息封闭和类别体系独立的局限性,并不一定能满足所有应用场景的分类需求。因此,有必要设计一种不依赖下载平台的App分类方法,仅基于App的名称就可以将其在预定义的类别体系中进行分类。然而,由于App的名称通常很短,只包含少量几个词,且这些词经常不能反映其所属类别的语义。
针对这一挑战,现有工作主要借鉴短文本分类领域的研究成果,通过外部信息(如搜索引擎和维基百科、WordNet等外部知识库)对短文本进行扩展,然后对扩展后的长文本进行语义分析,在此基础上实现对App的分类。然而,现有基于短文本扩展的App分类方法仍存在以下不足:首先,现有方法需要大量有标注的训练样本来训练分类器,然而由于App数量巨大,对其进行手工标注代价太大,特别是需要定制应用场景独有的分类体系的时候;其次,现有方法大多采用单一视图对App进行描述(如关键词、潜在主题等),单一视图通常只能描述问题在某一方面的特征,导致分类器泛化能力较弱。针对以上不足,笔者提出了一种基于多视图协同学习的App分类方法:首先,利用互联网知识对App名称进行扩展,得到描述App的长文本;然后,基于两种不同的视图来表示App长文本,一个是词频分布视图(用于描述App长文本中包含的与类别相关的关键词的分布),另一个是是主题分布视图(用于描述App长文本所代表的隐含主题);最后,采用协同学习算法来训练分类器,在训练过程中,基于两个视图对App长文本表示能力的差异来充分利用无标注样本提高分类器性能。
1 研究背景
现有App分类方法大多考虑多种与App相关的信息。例如,Berardi等[4]采集App在下载平台中的各类元数据(如文字描述、下载平台分类和用户评价等),并从中提取特征训练App分类器。Chen等[5]考虑多种App相关信息(如名称、开发商和申请权限等),基于在线多核回归计算App间的类型相似度。Radosavljevic等[6]同时考虑App的安装顺序和App的文字描述,采用嵌入技术对App进行分类。Zhu等[7]从App文字描述和用户使用App的习惯中分别提取特征来构建App分类器。
仅基于App名称的App分类问题与短文本分类问题比较类似。短文本在现实世界中非常常见,如检索词、短消息和聊天记录等。由于短文本内容少、特征不明显,传统基于向量空间模型的方法效果不理想。针对短文本分类面临的特征稀疏问题,现有方法作了不同的尝试,主要分为两类。
第一类方法基于聚类技术将将短文本合并成长文本,然后用传统的方法(如主题模型)来处理。例如,每条微博除了博文之外,还可根据它们的话题标签、发表用户、定位信息和发表时间戳等信息聚类在一起成为长文本。其中,Abel等[8]将用户名和关键词并入微博正文进行主题建模,对比仅使用微博正文,实验效果提升明显。Mehrotra等[9]采用元数据聚类方式,在推特文本中扩充主题标签、时间戳等特征以解决样本特征少的问题。然而,此类方法需要根据任务需求特别设计,对数据的要求比较高,必须保证每条数据都有这些额外的元数据信息。
第二类方法利用搜索引擎或者外部知识库(如维基百科、外部词典等)对短文本进行特征扩展或在语义层进行表达。例如,Meng等[10]提出了一种通过搜索引擎扩展短文本的方法,该方法搜索待分类的短文本,并以搜索引擎结果页面中选取的一定数量的文本作为背景知识来扩展短文本的特征。Mizzaro等[11]在维基百科中搜索短文本包含的词,并利用维基百科及相关链接树得到与主题相关的信息来扩充短文本的特征。Zhou等[12]通过分析维基百科中的链接提取同义词和语义关系来构建知识库,并应用于问答检索任务,在维基百科词库的帮助下,实验性能相比传统方法有明显提升。Li等[13]利用维基百科,基于相似性计算来识别短文本中的概念,并对概念本身进行信息拓展以扩充短文本特征。Liu等[14]提出了一种基于维基百科和word2vec扩展短文本特征的方法,通过维基百科获取与文本主题相关的额外语料,利用word2vec来计算语义关联度,进而提取短文本特征来解决短文本特征稀疏性问题。然而,现有方法大多采用单一视图来对短文本进行描述(如关键词、潜在主题等),单一视图只能描述短文本在某一方面的特征,导致模型泛化能力较弱。
此外,由于对App训练样本的类型进行手工标注代价太大,特别是需要定制应用场景独有的分类体系的时候,而有标注训练样本过少会严重影响模型的泛化能力。半监督学习技术[15]是解决标注样本不足的有效手段,基于分歧的半监督学习是最有效的一种半监督学习技术[16]。协同学习Co-Training[17]是一个经典的基于分歧的半监督学习算法,其思想为:分别训练两个分类器,每次迭代中每个分类器分别从无标注样本中挑选出标记置信度最高的若干样本加入另一个分类器的训练集,并更新分类器。基于分歧的半监督学习能有效工作的关键是分类器的差异性[18]。为保证分类器的差异性,一些算法利用不同的特征视图训练分类器(如Co-Training),一些算法利用相同的特征视图不同的模型训练分类器(如Tri-Training[19],Co-Forest[20])。App分类和短文本分类研究领域鲜有工作考虑标注样本不足的问题。在长文本分析研究领域,Wan[21]利用中文和经过翻译之后的英文作为两个特征视图进行协同学习,在语义情感分类上取得了有效结果。陈立玮等[22]基于词法特征、句法特征和n-gram特征进行视图切分,然后采用协同学习技术,利用无标注样本来提高网络文本数据关系抽取的性能。
2 分类模型
2.1 模型概述
如图1所示,笔者提出的方法包括两个步骤。
首先,利用互联网知识对App名称进行扩展,具体方法为:1) 筛选出一些介绍App的优质网站(如Google play,Apple store等);2) 使用网络爬虫抓取筛选出的网站中指定HTML标签下的文本;3) 汇总抓取到的文本形成描述该App的长文本。
然后,基于笔者提出的方法训练App分类模型,具体方法为:1) 从词频视图和主题视图两个角度为每个App长文本提取词频分布特征和主题分布特征;2) 采用协同学习算法Co-Training对词频分布特征和主题分布特征进行融合,并训练App分类模型。
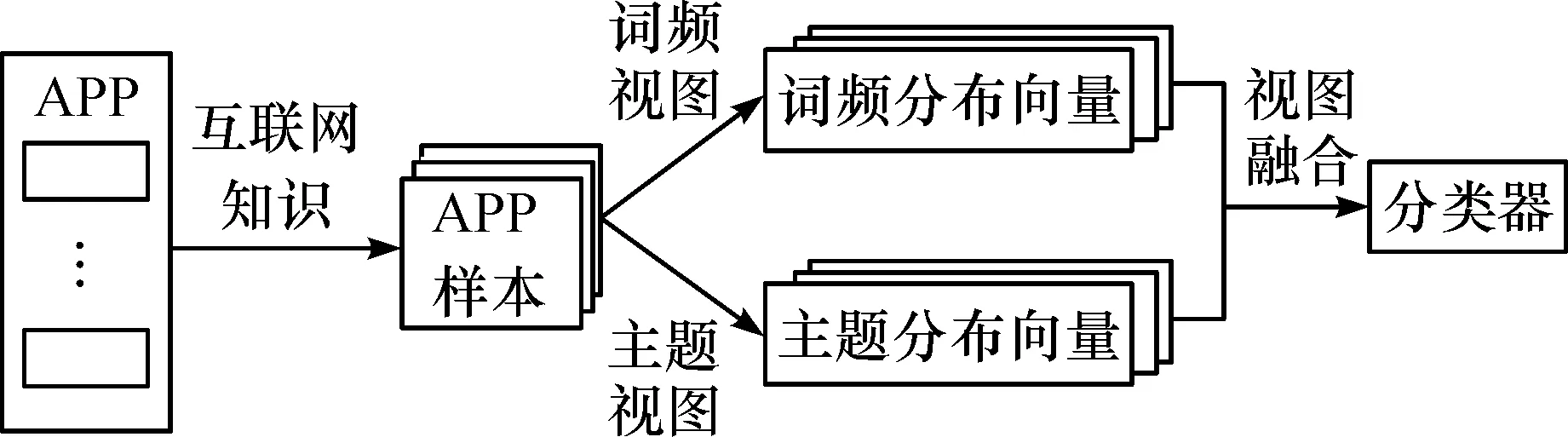
图1 App分类方法流程图Fig.1 The image of App classification method flow
2.2 词频视图
词频视图主要对词频分布特征进行提取,包括关键词提取、关键词扩充和词频向量生成三个步骤。
2.2.1 关键词提取
首先,对所有App长文本进行预处理(包括分词、去除停用词等),并将预处理后得到的词去重汇总,得到词典W。然后,基于TF-IDF计算W中每个词对于每个App类型的权重。词wi对于App类型cj的权重计算方法为
(1)
式中:n(i,j)为wi在cj对应的所有App长文本中出现的次数;C为App类型的集合。最后,根据权重选择一些词作为关键词。由于关键词数量对应词频向量的大小,过多的关键词会导致词频向量维度过高,且权重越低的关键词对描述App类型的能力越弱,因此为每个App类型取权重最高的N个词作为其关键词,则最后得到N×|C|个关键词(称为原始关键词集)。
2.2.2 关键词扩充
由于近义词现象的存在,实际App长文本中可能会采用与关键词不同但语义相似的词来描述该App(如“玩游戏”和“打游戏”),特别是N取值较小的情况下,因此仅基于原始关键词集可能会产生覆盖能力不足的问题。
针对此问题,笔者采用词嵌入技术word2vec来对原始关键词集进行扩充,word2vec以无监督的方式对语料库进行学习,并将其中每个词表示为一个紧凑、低维的向量[23]。与传统的稀疏、高维的one-hot词向量表示方法不同,word2vec词向量可以反映词之间的语义相似性,即语义相似词的词向量也具有较高的相似度。
基于word2vec的关键词扩充步骤如下:首先,汇总所有预处理后的App长文本构造语料库(包括有App类型标注的和无App类型标注的);然后,采用word2vec工具对语料库进行分析,得到每个词的向量表示;最后,采用词向量的余弦相似度计算词之间的语义相似度,并为原始关键词集中的每个关键词挑选与其语义相似度最高的K个词用于扩充原始关键词集,则扩充后得到N×|C|×(K+1)个关键词(称为扩充关键词集)。
2.2.3 词频向量生成
对每个App长文本,基于向量空间模型计算该长文本对应的词频向量vw,其中vw的第i个分量代表扩充关键词集中第i个关键词在该App长文本中的权重,同样基于TF-IDF计算。关键词wi对App长文本dj的权重计算方法为
(2)
式中:m(i,j)为wi在dj中出现的次数;D为App长文本的集合。则这个N×|C|×(K+1)维的词频向量即为词频分布特征。
2.3 主题视图
词频分布特征可对关键词与App类型间的关联进行建模,但没有考虑关键词背后的隐含语义。例如,在词频向量中,“游戏”“玩”“有趣”等关键词会被视为完全不同的特征分量,但这些关键词表达了类似的隐含语义,可认为它们都在描述“游戏”这个潜在主题。
针对此问题,笔者采用LDA(Latent dirichlet allocation)主题模型[24]对App长文本背后隐含的主题进行估计,并生成主题分布特征。图2展示了LDA模型,其中:T为潜在主题的数量;|D|为App长文本的数量;|W|为D中出现过的词的数量;θ为一个|D|×T的矩阵(代表每个App长文本的主题分布);φ为一个T×|W|的矩阵(代表每个主题上的词分布);ɑ和β为Dirichlet分布的超参数。LDA模型的生成过程为:首先,根据ɑ生成θ,根据β生成φ;然后,根据θd生成App长文本d的主题z(θd为d的主题分布向量),并根据φz生成词w(φz为主题z的词分布向量)。
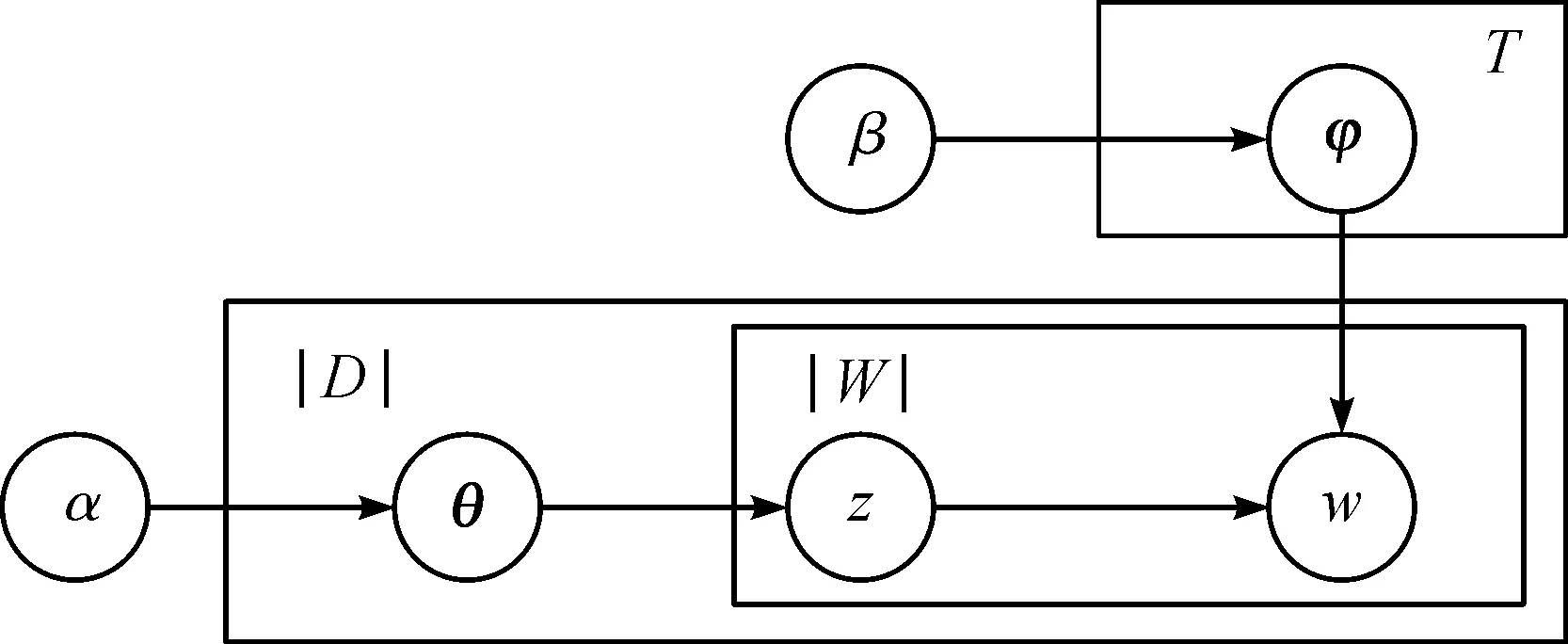
图2 LDA模型Fig.2 The image of LDA model
训练LDA模型的目的即为估计θ和φ。给定主题数量T,笔者采用Gibbs采样对LDA模型进行训练。完成后,每个App长文本可基于θ被表示成一个T维的主题分布向量,即为主题分布特征。
2.4 视图融合
在构建词频视图和主题视图的基础上,通过融合这两个视图来构建App分类器,包括协同学习和分类器融合两个步骤。
2.4.1 协同学习
由于一般情况下,有类型标注的App样本较少,而无类型标注的App样本较多,因此笔者采用半监督学习方法综合利用有标注样本和无标注样本来训练App分类器。
协同学习算法Co-Training是一种基于分歧的半监督学习方法,它要求分类问题能够被两个独立、充分的视图描述,即基于其中任一视图训练的分类器都可以单独完成分类任务。Co-Training能够有效利用无标注样本改善分类器性能的最重要前提是两个视图具有差异性,即存在某些样本,它们被基于其中一个视图训练的分类器错误地分类,但被基于另外一个视图训练的分类器正确地分类。
笔者根据App分类问题的特点设计的词频视图和主题视图可满足Co-Training的要求:首先,单独基于词频视图或主题视图均可训练App分类器;其次,词频视图和主题视图从两个不同的角度来描述App分类问题,因此它们在理论上具有差异性,例如,词频视图在区分主要关键词出现次数较多的App长文本方面具有优势,而主题视图在区分主要关键词出现次数较少的App长文本方面具有优势。
基于Co-Training进行App分类器训练的算法伪代码为
输入:有标注App长文本样本集,L
无标注App长文本样本集,U
迭代次数, max_count
输出:词频视图基分类器,WC
主题视图基分类器,TC
1) The current iterationi=0
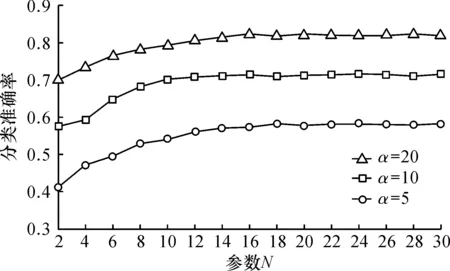
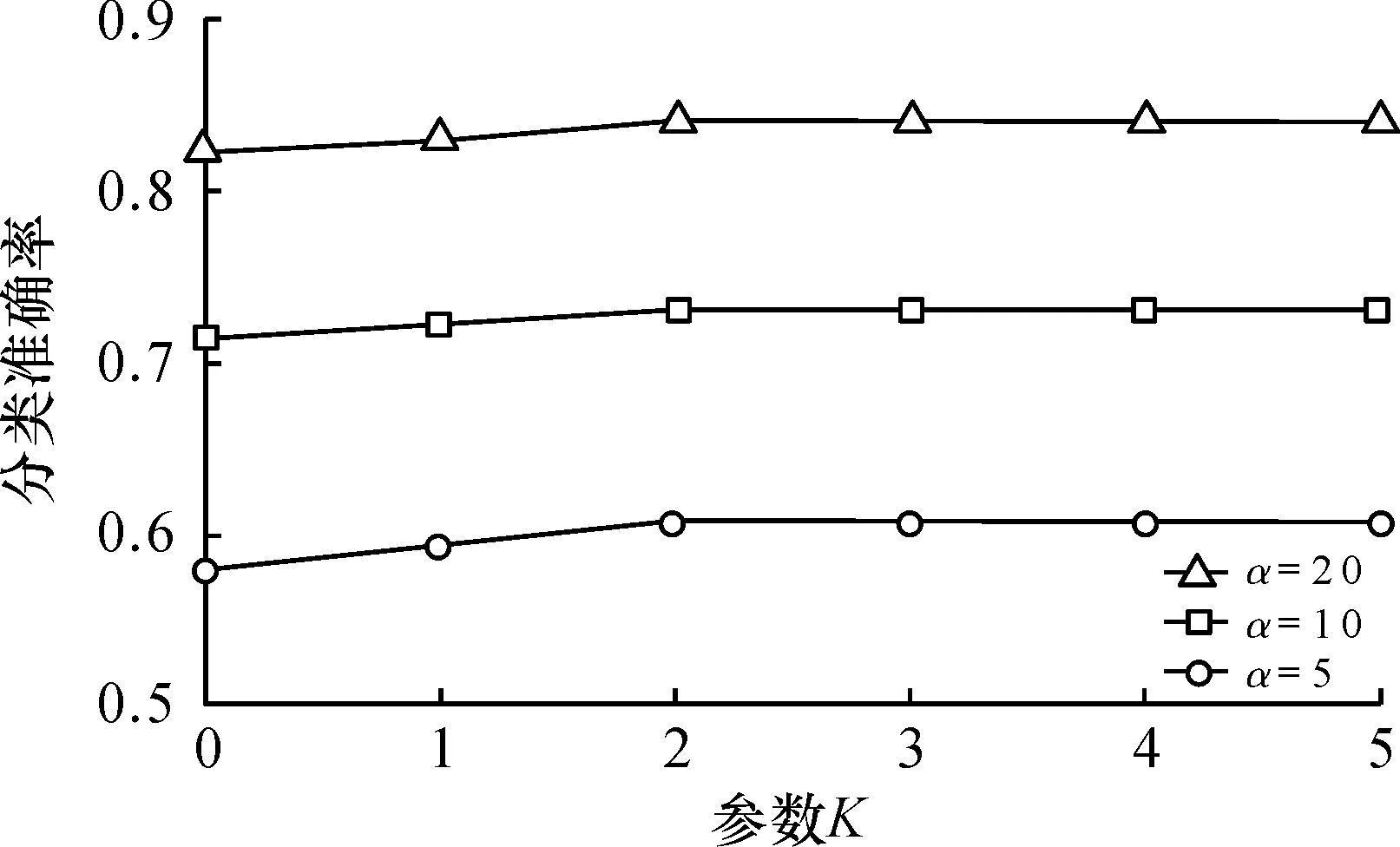
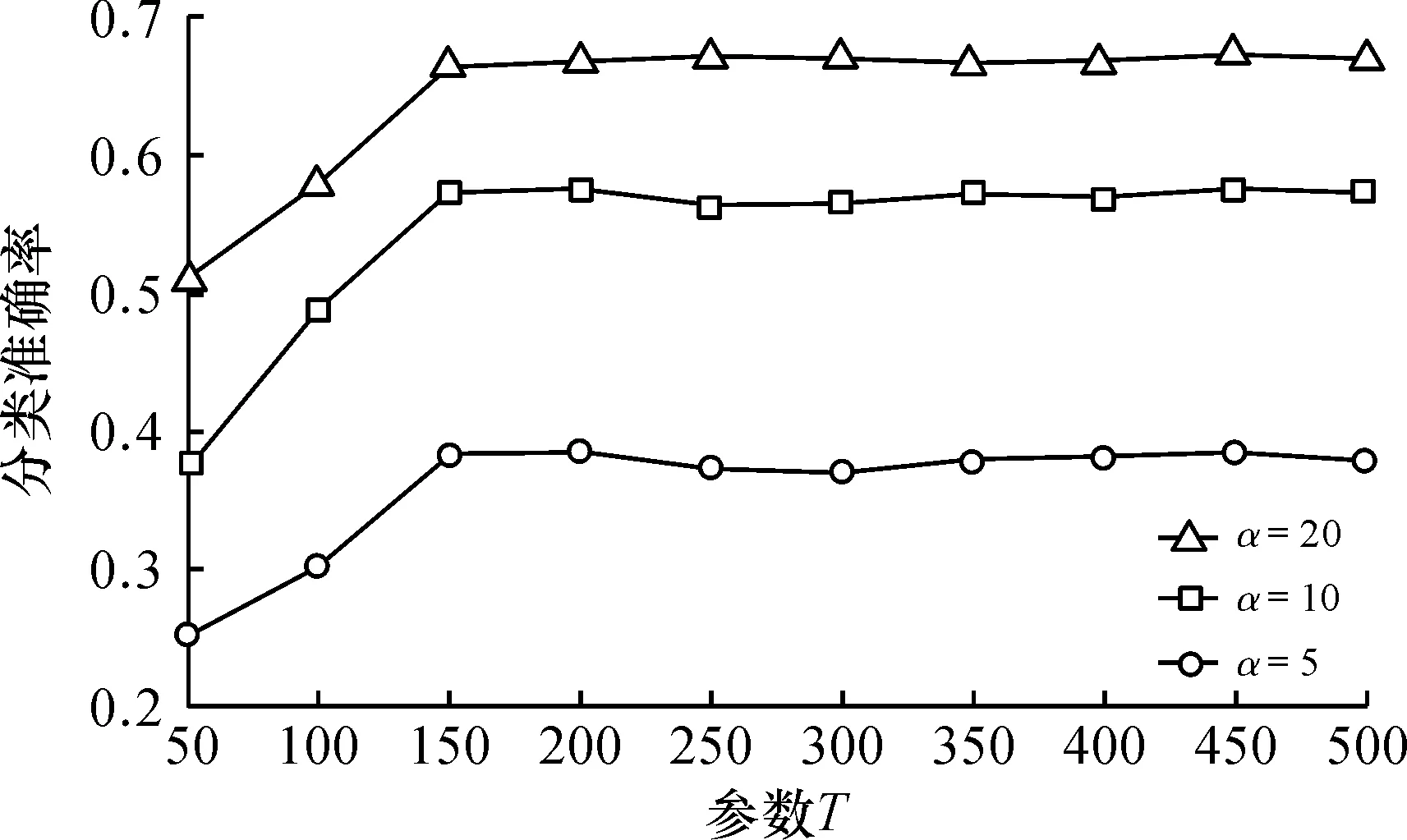
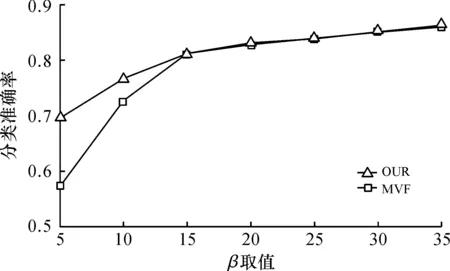
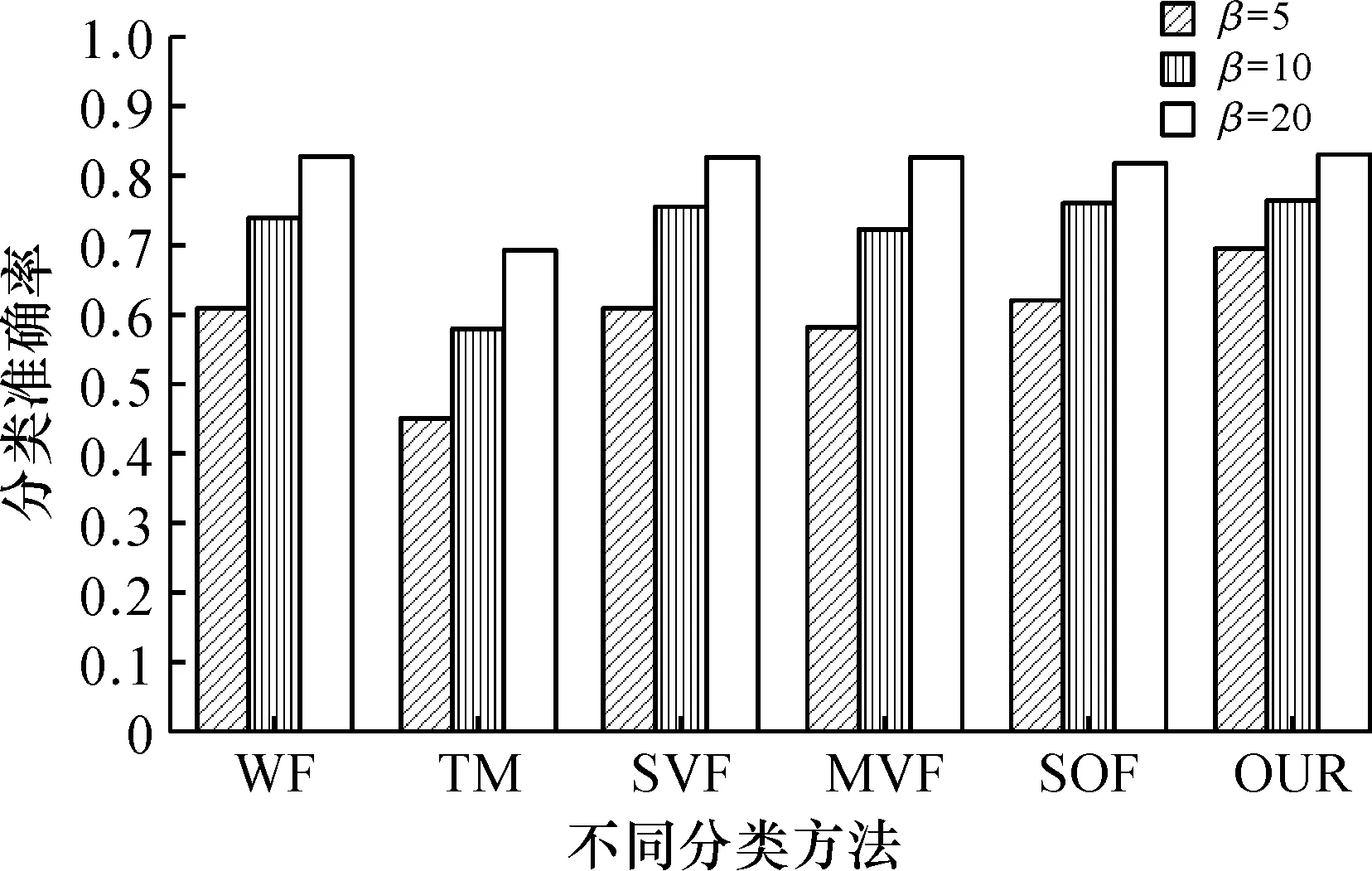
2) whilei 3)WC← Train based onLand the word frequency view 4)TC← Train based onLand the latent topic view 5) ApplyWCandTCto each sample inU, respectively 6) for each App categorycjdo 7) Pick the sample inUthatWCmostly confidently classifies ascj, and add it toL 8) for each App categorycjdo 9) Pick the sample inUthatTCmostly confidently classifies ascj, and add it toL 10)i++ 在每一次迭代过程中,算法在现有的有标注样本集上分别基于词频视图和主题视图训练两个基分类器3)~4)。然后,分别采用这两个基分类器对无标注样本进行分类5),并为每个App类型挑选分类置信度最高的一个无标注样本来扩充有标注样本集6)~9)。最后,进入下一轮迭代,并用扩充后的有标注样本集来重新训练基分类器。 2.4.2 分类器融合 Co-Training算法结束后,可以得到两个基分类器WC和TC。由于WC和TC可能会对同一样本给出不同的分类结果,因此需要设计一种机制来融合它们的分类结果。对一个样本Xi,使用WC会得到一个分类置信度向量PWC(Xi)= 然而,由于WC和TC是基于不同视图训练得到的,它们在性能上可能存在差异,更复杂的情况是还有可能WC和TC在不同的App类型上存在不同的性能差异,因此应该根据基分类器的实际性能调整它们的权重。针对此问题,笔者借鉴Stacking的思想[25]对WC和TC进行融合。如图3所示,即以基分类器的输出作为新的样本,训练一个元分类器MC。其中,基分类器在样本Xi上的输出为P(Xi)= 图3 基于Stacking的基分类器融合Fig.3 Base classifier fusion by Stacking 从Android手机应用市场AppBrain上采集了981 个热门App的名称,根据AppBrain的分类体系,将这些App分成如下11 个类别:社交类(83 个App)、地图类(72 个App)、音乐类(84 个App)、新闻类(101 个App)、摄影类(113 个App)、购物类(106 个App)、通讯类(95 个App)、教育类(91 个App)、金融类(88 个App)、食品类(57 个App)、健康类(91 个App)。为扩展App名称,筛选出了50 个网站,通过解析每个网站中特定的HTML标签,形成每个App的长文本。 实验中用到两种评测策略:α折交叉验证和β标注验证。α折交叉验证指在每种类型的App样本中随机挑选α%作为训练样本,而剩余的(100-α)%作为测试样本。β标注验证指在每种类型的App样本中随机挑选β%作为有标注样本,而剩余的(100-β)%作为无标注样本,其中训练样本包括所有的标注样本和无标注样本,而测试样本仅包括所有的无标注样本。这两种评测策略均在不同采样条件下重复10 次求平均分类准确率。 在所有实验中,采用随机森林作为分类算法。 笔者提出的方法中,有3 个关键参数需要调试,即关键词数量N、扩充词数量K、主题数量T。在该实验中,笔者采用α折交叉验证作为评测策略。 3.2.1 参数N和K的调试 在该实验中,采用词频视图基分类器调试参数N(指定为每个App类型取的原始关键词的数量)和K(指定为每个原始关键词扩充的相似词的数量)。 首先,固定K=0,评测在不同α取值条件下参数N对分类准确率的影响,结果如图4所示。可以看出:当N较小的时候,分类准确率随N的增大而明显提升;当N增大到一定程度,分类准确率的提升幅度逐渐趋于稳定。由于更大的N意味着更高的计算复杂度,因此取N=20。 图4 参数N对分类准确率的影响Fig.4 Effect of parameter N on classification accuracy 然后,固定N=20,评测在不同α取值条件下参数K对分类准确率的影响,结果如图5所示。可以看出:除K=1时相对K=0时分类准确率有少量提升,总体上K对分类准确率的影响不明显。因此取K=1。 图5 参数K对分类准确率的影响Fig.5 Effect of parameter K on classification accuracy 3.2.2 参数T的调试 在该实验中,采用主题视图基分类器调试参数T(指定潜在主题的数量)。评测在不同α取值条件下参数T对分类准确率的影响,结果如图6所示。可以看出:当T从50增大到150左右,分类准确率显著提升,这说明需要一定数量的潜在主题才能有效表示不同App的潜在语义;而当继续增大T时,分类准确率提升幅度不明显,甚至某些时候还出现了下降的情形,这说明潜在主题数量过大时有可能产生噪声。因此,取T=150 。 图6 参数T对分类准确率的影响Fig.6 Effect of parameter T on classification accuracy 为评测笔者提出的方法(称为OUR)在利用无标注样本改进分类器性能方面的能力,将其与一种多视图融合的方法(称为MVF)进行比较。MVF采用与笔者类似的方法(仅不包含协同学习的步骤):首先,基于词频视图计算词频分布向量,基于主题视图计算主题分布向量;然后,基于Stacking方法融合词频视图基分类器和主题分布基分类器。在该实验中,采用β标注验证作为评测策略,结果如图7所示。可以看出:在β取值较小的时候,OUR的分类准确率明显优于MVF,这说明在有标注样本数量极度有限的情况下,OUR可有效地利用无标注样本改进分类器性能;此外,当β取值增大到一定程度,OUR和MVF的分类准确率几乎没有差异(当β>30,OUR和MVF的分类准确率均大于0.85),这说明协同学习仅在有标注样本数量极度有限的情况下使用才有必要。 图7 有标注样本比例对分类准确率的影响Fig.7 Effect of train set ratio on classification accuracy 将笔者提出的方法(称为OUR)与如下5 种现有App分类方法进行对比,分别为 1) WF(基于词频向量空间模型的方法):基于TF-IDF计算每个App类型文本出现频率最高的N个关键词,然后基于关键词构建向量空间模型并训练分类器。 2) TM(基于主题模型的方法):基于LDA计算每个App长文本对应的主题分布向量,然后基于主题分布向量训练分类器。 3) SVF(单视图融合的方法):基于词频视图计算词频分布向量,基于主题视图计算主题分布向量,然后拼接词频分布向量和主题分布向量形成一个长向量并训练分类器。 4) MVF(多视图融合的方法):见3.3节。 5) SCF(单视图协同学习的方法):基于词频视图计算词频分布向量,基于主题视图计算主题分布向量,拼接词频分布向量和主题分布向量形成一个长向量,然后采用不同的机器学习算法构建基分类器,最后采用协同学习和Stacking方法融合基分类器。 在该实验中,采用β标注验证作为评测策略(β=5)。其中,WF,TM,SVF和MVF不用到无标注样本,结果如图8所示,可以看出:1) WF性能始终优于TM,这说明从特定网站抓取的App长文本包含的关键词大多与App类型有较强的关联;2) SVF性能比MVF略好,这说明在不进行协同学习的情况下,特征层融合方法比模型层融合方法性能要好,原因可能是模型层融合针对不同视图特征单独建立分类器,忽略了不同视图特征间的潜在关联;3) SVF性能始终优于WF和TM,这说明词频特征和主题特征能提供互补的信息,对App分类均有贡献;4) SCF性能始终优于SVF和MVF,这说明协同学习可有效地利用无标注样本来提高分类器性能;5) OUR性能优于SVF,特别是β取值较小时(β=5和β=10),这说明多视图融合方法比单视图融合方法更适合App分类任务,也证明了笔者基于词频和主题的多视图划分策略是有效的。 图8 不同方法的分类准确率比较Fig.8 Comparison of classification accuracy on different approaches 为实现仅基于App名称的App分类方法,笔者提出了一种基于多视图协同学习的App分类方法。利用互联网知识将App名称短文本扩展成App描述长文本,从词频视图和主题视图两个角度对样本特征进行提取表达,利用协同学习训练方法对基分类器进行构建,并引入Stacking方法将基分类器输出结果进行融合,使两种视图模型之间互相学习以提高模型最终泛化能力。与传统的单视图分类方法进行实验对比,证明了其具有更高的有效性。在训练集比率不同的条件下与多种传统的算法模型进行横向对比,结果表明笔者提出的App分类方法具有更好的效果。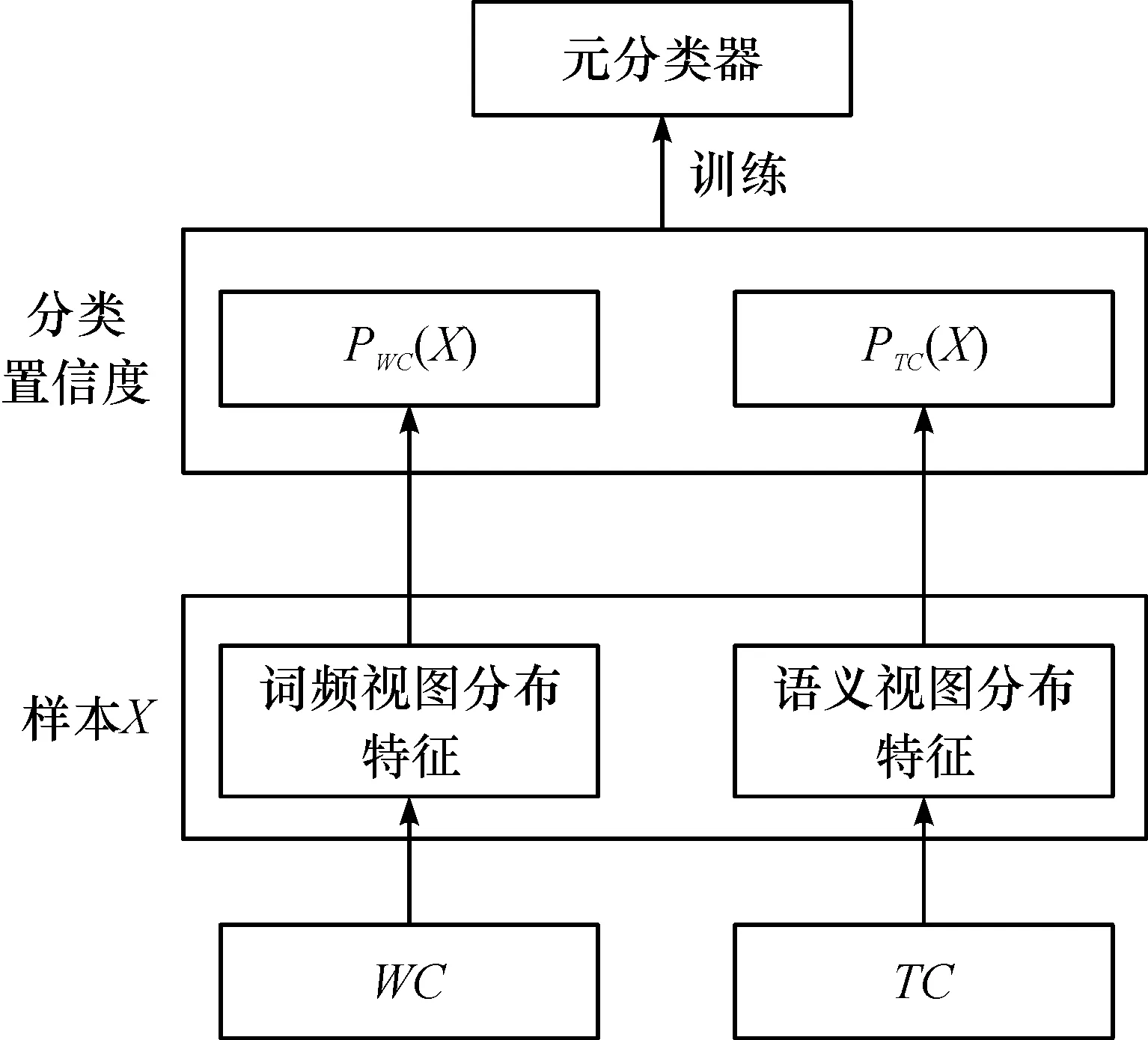
3 实验结果与分析
3.1 实验设置
3.2 参数调试实验
3.3 有标注样本数量的影响
3.4 对比实验
4 结 论
猜你喜欢
内江科技(2021年8期)2021-09-13
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
亚太教育(2018年5期)2018-12-01
非公有制企业党建(2017年10期)2017-11-03
电子技术与软件工程(2017年14期)2017-09-08
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
电脑知识与技术(2016年13期)2016-06-29
读者·校园版(2015年7期)2015-05-14
