
基于MSVM算法的Android恶意应用检测研究
2018-11-30 01:46郭平
计算机应用与软件 2018年11期
郭 平
(广东交通职业技术学院 广东 广州 510650)
0 引 言
随着科技不断发展进步,智能化终端设备普及率越来越高,逐渐深入到日常生活中的方方面面,为大众带来了实实在在的便利。Android由于其开源性的强大优势,已普遍应用在各种手持设备和操作系统中。但也正是由于其开源优势大大降低了开发成本,大批恶意应用不断涌现,严重威胁用户使用安全。360互联网安全中心发布的《2017年中国手机安全状况报告》中指出,Android平台2017全年截获新增恶意程序样本累计1 403.3万个,每天平均新增3.8万个恶意程序样本[1]。Android平台提供了几种应对恶意软件威胁的方法:沙箱、访问控制、签名机制、权限机制等,但是这些机制都把注意力集中在申请权限上,对于不具备相关专业知识的用户就会盲目的赋予未知应用程序权限,无法避免恶意软件威胁。目前大多数的检测手段主要是动态分析以及静态分析,但效果极其有限。后来,有人提出采用机器学习算法进行恶意软件检测分类,在检测效果上确实有了显著的改善。由于基于Android的恶意样本存在较高难度和准确性不足的缺点,因此适合样本数量少、准确率高、花费小的支持向量机(SVM)算法被广泛应用[2-4]。
本文在SVM算法基础上提出采用多核模糊SVM算法进行恶意软件分类,主要通过恶意软件特征值提取对恶意软件进行分类检测,最后和一般支持向量机的结果进行比对。
1 技术介绍
1.1 Android进程注入与HOOK技术
进程注入指的是将自行实现的程序文件注入到目标文件中,即通过程序操作使其在指定的进程中被装载。具体的注入过程大致如下:
(1) attach上目标函数;
(2) 让目标进程的执行流程跳转到mmap函数来分配内存空间;
(3) 加载注入so;
(4) 让目标进程跳转到注入so中的代码执行。
通常来说,hook技术可与进程注入融合,进而实现自定义。hook技术可调用系统函数,即通过控制目标来实现自定义行为。当目标函数被调用时,实际上调用的是自定义的函数,在该函数中可以解析原函数的参数获得数据,实现行为拦截。
1.2 Android进程间通信机制
Android是基于Linux来开发的,并且Linux内部集成了丰富的内核和通信机制,例如跟踪、信号、报文队列等,但Android并没有上述的一种通信机制,只采用了Binder机制。
Binder是与COM和CORBA极为相似的分布式组件架构,Binder的实质功能是提供远程过程调用(RPC)。该机制的通信模式采用客户端-服务器的形式,包括四部分组件:Client、Binder Driver、Server和Server Manager,其基本通信架构如图1所示。
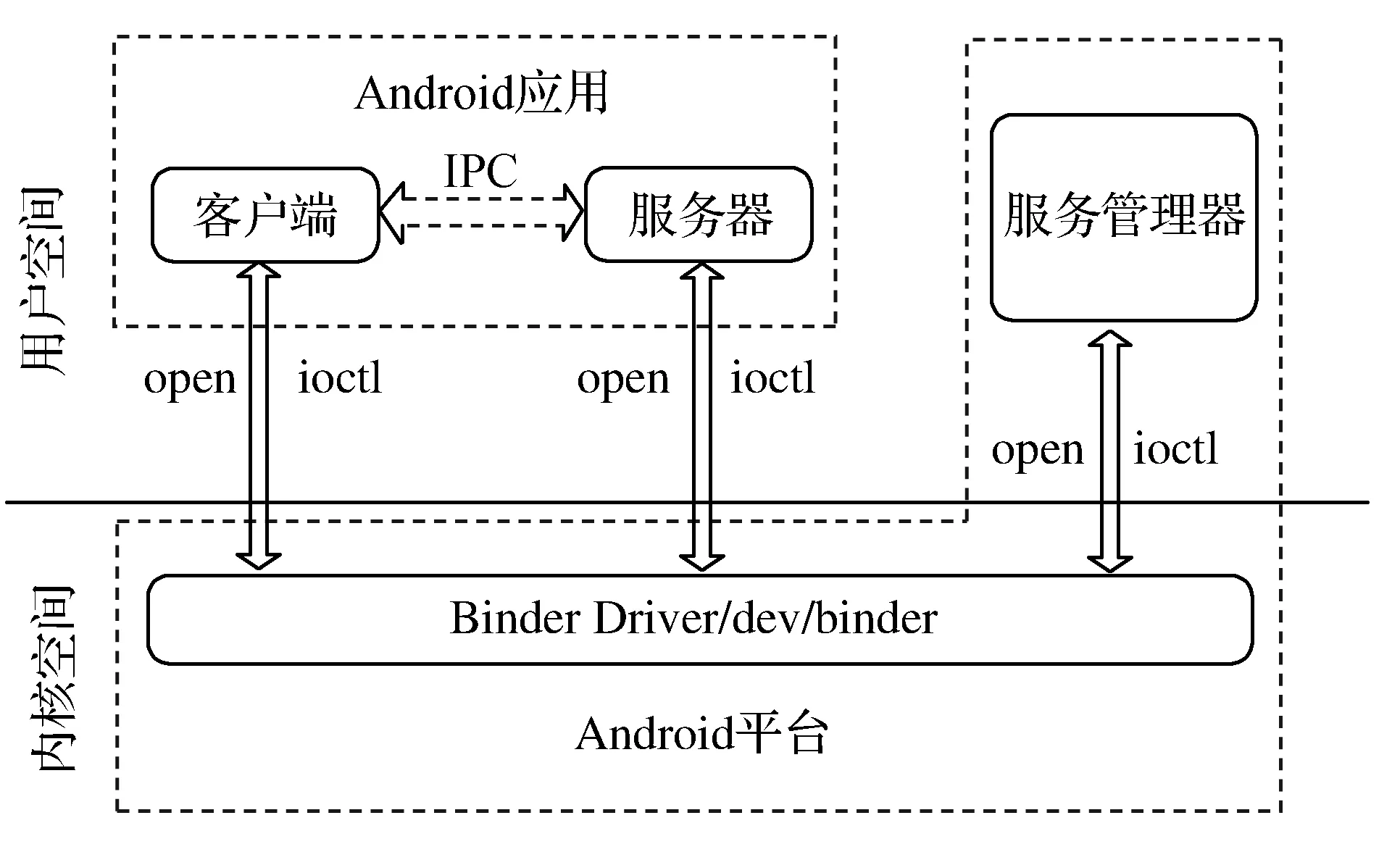
图1 Binder机制基本通信架构
Server:它定义实现了各种方法(服务),并且继承了Binder的对象。
Binder Driver:当一个新的Binder对象被创建的时候,Binder驱动器则会创建mRemote对象。
Client:通过获取Binder驱动的mRemote对象就可以调用相应的Binder对象的服务。
Server Manager:用来管理Server,并向Client提供查询Server接口的能力。Binder机制的基本通信过程即服务器定义服务,客户端通过获取服务器的对象引用的方式就可以调用服务器定义的各种服务。应用程序调用系统函数执行敏感行为的过程,就是使用Binder机制进行进程间通信的过程。
2 特征值
2.1 Android 恶意应用特征
目前恶意软件的种类很多且改变很多,给检测工作带来了相当大的困难。虽然不同的恶意应用程序一直出现,但在安装方式、功能触发和恶意负载方面都具有以下典型特征:
(1) 恶意应用通常会以非常热门应用的方式来包装,从而吸引客户下载,而主要的方式有应用更新、重打包、偷渡下载等方式。
(2) 安装完毕后,应用会诱导客户误点击运行,从而秘密地进行窃听行为。
(3) 恶意负载包括远程控制、特权提升、吸取话费、窃取隐私和自我保护等。
2.2 特征值选取
目前流行的提取方式有Smali hook、Binder IPC 注入、ROM定制、Zygote注入和虚拟机自省(VMI)。本文使用IPC注入方法来对恶意应用进行特征提取,并用ioctl()函数进行通信,此函数可通过解析BINDER_WRITE_READ来实现拦截。在拦截到应用行为后,即可输出拦截日志,形成特征向量,并将该向量作为分类器的输入,获得检测效果。
Smali hook:在对监控模块进行插入前,需要对APK编译后的代码进行修改。
Binder IPC注入:利用Android进程间通信机制binder注入关键函数ioctl(),以此获取进程敏感行为调用的信息。
ROM定制:插入监控模块后,对内核模块重新编译。
Zygote注入:利用zygote进程创建新进程,注入并监控应用程序框架层的API调用。
虚拟机自省:基于hypervisor的虚拟化解决方案,从Android虚拟器外部监控系统及应用程序的状态。
在系统对恶意行为进行拦截并形成拦截日志后,输出拦截特征,构造对应样本的特征向量,并作为分类器的输入。
分类工作的一个很关键步骤是构造特征向量,在对已有方案的应用存在的不足作出了描述,本文将采取系统函数及其组合来对应用行为进行描述。具体地,该种方式具备以下优势:与静态的检测方法相比,抗代码混淆和加密能力更为突出;与采取CPU使用率和网络流量等系统数据作为特征向量相比,瞬时攻击可被识别,能检测出更多的恶意应用;与底层系统描述行为相比,该种方式更为细致,范围也更加广阔。
系统函数和权限有着非常紧密的对应关系,根据官方文档,当前可申请的权限达137项,另外,部分对应权限的分类和敏感权限的界定如表1所示。

表1 部分敏感权限列表
由于敏感权限与敏感API之间存在着映射关系,因此从敏感权限中去发掘敏感API,并参考存在Android应用行为的研究,可更加改善确定拦截的行为。
通常敏感行为可大致分为两种,单一组合和行为组合。首先单一组合指的是可通过系统函数来描述的行为,而行为组合指的是用多个系统函数进行描述的行为,一般来说,后转更具有威胁性。比如,将获取联系人信息看似一个系统函数,那么一些良性的应用就会调用它,如果只是获取该应用所需的信息来完成某个功能,这种行为并不过敏,但如果获取完毕后进行了联网,则这个行为很有可能泄露用户隐私,因此该组合比单一的获取联系人的信息更为敏感。通过上述类似原理,本文自定义了需要拦截的一系列行为组合,它们的共同特征都是需要获取用户隐私信息,并通过与外网连接等手段将信息泄露出去,除此之外,后台发送短信也是一种非常敏感的行为[6]。本方案最终定义需要记录的敏感行为和敏感行为组合,共计 17项作为特征值来构造特征向量,均在表2中列出。

表2 需要记录的敏感行为
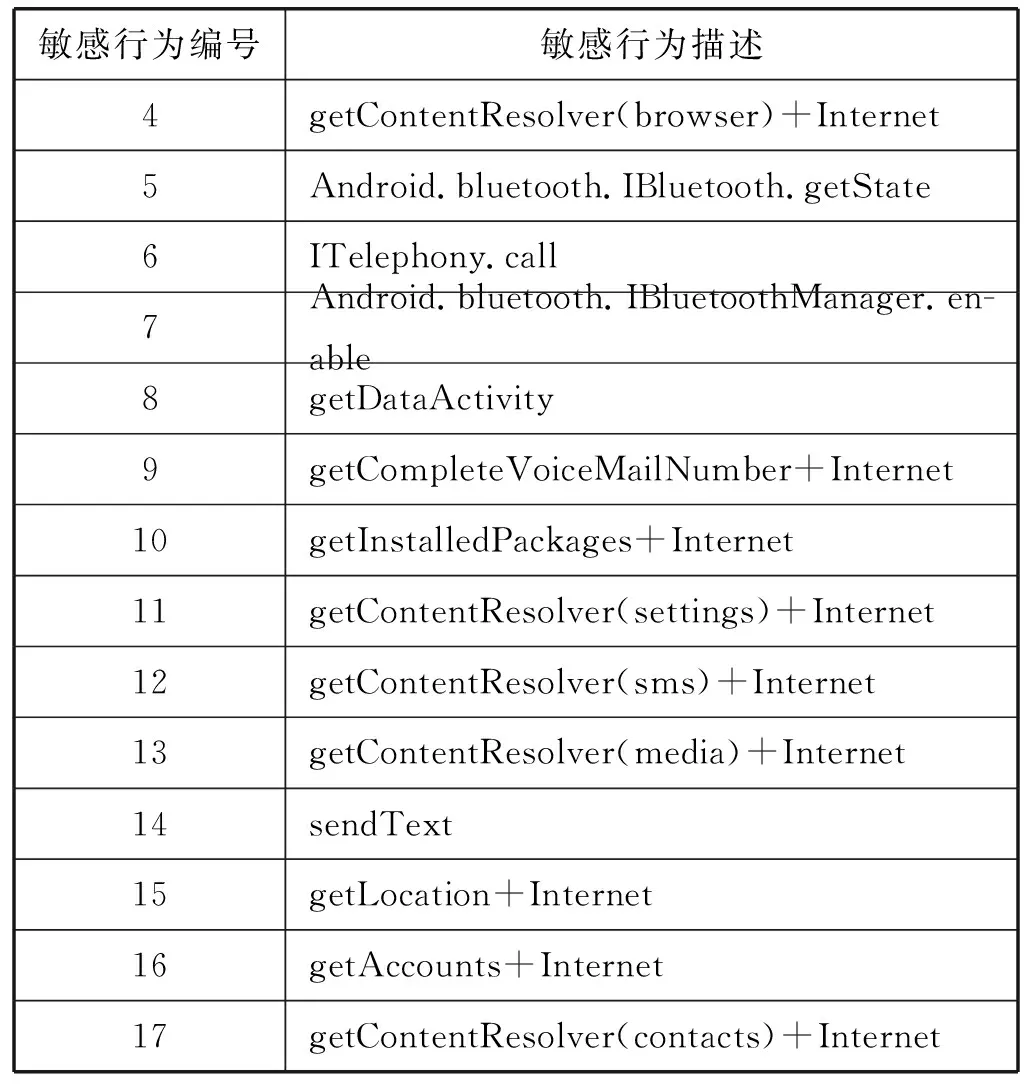
续表2
3 多核模糊支持向量机(MSVM)算法
3.1 算法流程
Android恶意应用的可变性和模糊性是很多分类算法所不能很好处理的。综合已有的这些实际问题,支持向量机(SVM)在针对小样本、高维度的确定性分类问题上,表现出特别的优势,并且其分类算法有严格的统计学论据,在编程逻辑上是透明的,这使得该算法更容易切入实际分类需求[9]。
Android恶意应用具有非线性、样本分布不平坦、噪声大等问题,支持向量机虽然在解决小样本数据上表现出许多特有的优势,但对于Android恶意应用的模糊性等问题,仍存在如下的缺陷[10]:
(1) 所有的训练点在支持向量机下被视为同等地位,具有局限性,在实际应用中,会尽可能维持支持向量的作用,弱化非支持向量的租用。
基于此,本文采用Lin等提出的模糊支持向量机FSVM(Fuzzy support vector machine)作为分类的基本方法,以减小非重要样本对SVM分类器学习的干扰[7]。
(2) SVM在解决非线性分类或回归问题过程中,核函数的选取非常重要。传统的SVM或者FSVM都是基于单个核函数的。对于Android恶意应用分类工作,由于分类样本间的差异化,如何选择一个合适的核函数是非常棘手的任务,一般要通过大量反复的实验来完成。这样操作对于智能分类来说,显然并不科学。
基于此,本文将在FSVM的基础上引入多个核函数映射,利用不同核函数之间的互补性特性来更加准确地适应Android恶意应用模糊、噪声大、样本差异不显著的特点。我们提出一种基于多核的FSVM算法用于Android恶意应用分类,来更有效地模拟Android恶意应用数据模糊性等实际问题。此算法决策树中的模糊核权重主要借助于样本无监督自学习来确定,能根据实际Android恶意应用数据的模糊性,形成一种更合适的分类算法。
MSVM算法分类流程如图2所示。

图2 MSVM分类流程图
3.2 MSVM算法的构造
SVM是基于统计学习理论的机器学习方法,从它的提出开始,就受到数据分类领域的广泛关注和欢迎。SVM拥有严整统计学理论基础作为支撑,在解决小样本、高维度和非线性模式识别中具有很大的优势,与其他类经验风险最小化算法相比,它的泛化能力更强,在减少训练和识别时间上有很重要的实际意义。
支持向量机分类器的数学模型原理图如图3所示。
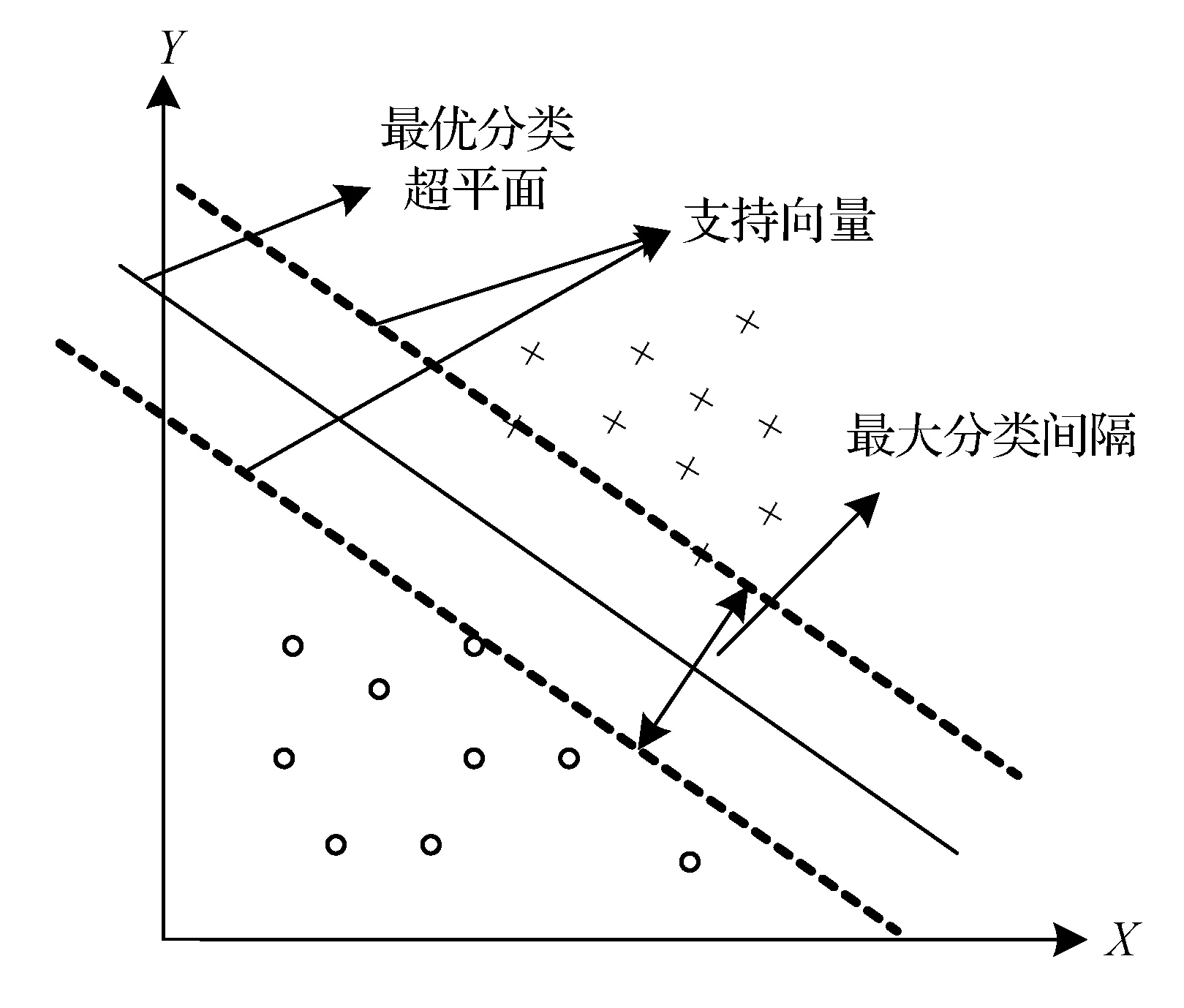
图3 支持向量机分类模型图
定义1设X是一个非空集合,则称
F={〈x,uF(xi)〉|x∈X,i=1,2,…,l}
(1)
式中:F为模糊集,uF(xi)为模糊隶属度矩阵中,样本集x中第i个样本属于模糊集F的隶属度,uF(xi)取值范围在[0,1]之间。
在对FSVM分类器进行训练前,首先对数据执行预处理,计算得到合适的隶属度函数后,将获得每一个数据样本xi的隶属度uF(xi)矩阵。隶属度函数uF(xi),本文根据数据去类标无监督自学习的方式得到。
模糊隶属度uF{xi}是指训练集{xl,yl,uF(x)}隶属某一类的程度,而εi是对错分程度的度量,因此用uF(xi)·εi(i=1,2,…,l)衡量对于重要程度不同的变量错分程度。由此得到最优分类超平面的目标函数的最优结构:
(2)
s.t.yi[ω·φ(xi)+b]-1+εi≥0
(3)
εi≥0,i=1,2,…,l
式中:惩罚因子C为常量,ω表示线性分类函数的权系数,ε=(ε1,ε2,…,εl)T,φ(xi)表示将xi从多维特征空间映射到高维特征空间。相应的最优分类超平面的判别函数式为:
(4)
式中:K(xi,x)是核函数,是将高维空间的复杂运算转换为低维空间的简单函数运算。
模糊因子uF(xi)的确定是决定FSVM性能的关键所在,当uF(xi)的值比较小时,该样本点对支持向量机的训练作用将大为降低,从而降低了它对训练SVM分类器过程的影响。
3.3 分类算法中模糊隶属度函数的确定
模糊C均值聚类FCM (Fuzzy C-Means)算法是比较有效的一种模糊聚类方法。在很多应用当中,它较之其他硬聚类算法更为灵活。
模糊隶属度函数的确定采用FCM算法ui矩阵的无监督、不断自学习的方法,这是算法的关键。
FCM算法给定聚类数目C=2,以及样本空间X,其中X包含N个l=17维的样本xi,i为样本序列号,FCM算法输出隶属度值uic,即样本xi属于第c类的可能性。于是我们需要最小化以下目标函数:
(5)

(6)
式中:m为模糊化程度,其值大于1;d(·,·)是欧氏距离;vc是第c个类的中心;U=[uic]i=1..N,c=1..C是一个N×C隶属度矩阵,其元素由uic组成;V=[v1,v2,…,vC]是一个l×C矩阵,其列向量对应C个聚类中心。我们可以通过拉格朗日乘数法求解约束优化问题,得:
(7)
可以用迭代更新隶属度(固定聚类中心)和更新各类中心点(固定隶属度)去解决问题,由式(7)求偏导并设为0可导出以下式子:
(8)
(9)
在这,没有将式(6)中的非负约束加入到拉格朗日乘数法中是因为上述的公式结果已经蕴涵uic≥0,∀i,c。此外,当m值接近1时候,FCM算法退化成为k-means(k-means 与c-means在不同的文献中都有表述,为同一算法)算法。据此,通过无监督的学习,得到uic。
FCM算法的实现步骤如下:

Step1Procedure FCM(DataX, NumberC);
Step2初始化隶属度矩阵U(0);
Step3重复计算第4、5步,
循环条件:‖U(t)-U(t-1)‖<ε;
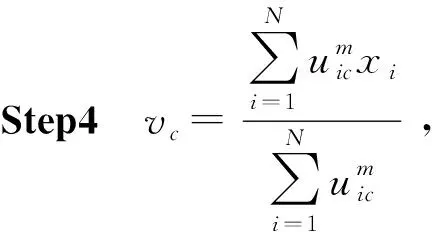
更新U(t)=[uic];
Step6ReturnU(t);
Step7End Procedure。
3.4 MSVM分类算法实现步骤
在上节中,式(4)的决策树只能对应于某些特定核函数的组合,但不能对应于混合的核函数组合。
应用分类中,组合多核函数的模糊支持向量机算法,其决策树和算法调整如下:
(10)
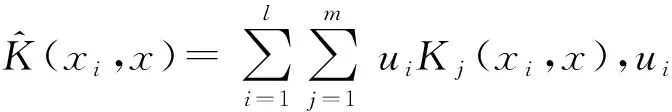

(11)
引理1Mercer核的非负线性组合仍为Mercer核。

以定理2为理论逻辑基础,可以利用现有常用‘linear’、‘poly’、‘rbf’、‘erbf’核函数构造新的模糊多核核函数,使其能够适用于样本集的训练学习。
MSVM算法分类步骤如下:
Step1将特征矩阵里的数据进行归一化处理。
Step2按照式(9),构建分类数据的模糊集。
Step3根据式(8) 和式(9)计算样本点模糊隶属度。
Step4根据式(11)选择不同的核函数进行组合。
Step5根据式(10)的决策树,运用数据对MSVM算法进行训练,然后进行样本测试。
4 实验结果
本实验中使用到的良性应用样本均搜集自第三方应用市场,恶意应用样本从各个安全论坛的病毒样本区搜集。使用到良性应用 150 个,恶意应用 150 个。
据训练数据集得到的用于测试的MSVM经过训练,算法中′linear′、′poly′、′rbf′、′erbf′等4个核函数的权值及参数值如表3所示[8]。

表3 采用数据集训练得到的MSVM参数
其中权值为上述核函数线性组合的权重,参数为对应核函数的调节因子。
为了评估MSVM算法的分类性能,Kappa系数的计算被引入进来,进行系统健壮性的评估。Kappa系数(κ)是两种或者两种以上精度之间的一致情况的静态测量方法,其计算公式如下:
κ=(Po-Pe)/(1-Pe)
(12)
式中:Po是总的一致可能性,Pe是估计的一致可能性。这样计算就明显比单纯的统计准确率要健壮。对Kappa系数值的意义说明如下:Kappa计算得数是-1~1,但我们一般取Kappa在 0~1 之间的数值,并分成5个档次来区别不同层级的一致性:0.0~0.20代表极低的一致性,0.21~0.40代表一般的一致性,0.41~0.60 代表中等的一致性,0.61~0.80代表高度的一致性,0.81~1代表几乎完全的一致性。本文实验分类结果的平均Kappa系数值是0.74。
在本次实验中,实验对数据特征值进行了标准化,得到300个样本,17维度的特征向量作为分类器的输入数据。进行交叉检验,数据集4/5为训练样本,1/5为测试样本。表4详细地给出了应用此分类器的结果及Kappa系数值的比较。分类准确率从80.11%到85.50%不等,平均的分类准确率是83.01%,实验结果表明本文提出的分类器能达到比较理想的分类结果。表4中平均的Kappa系数值是0.74。最后得出平均的分类准确率为83.01%。实验结果表明本文实验提出的MSVM分类算法准确率是比较稳定的。

表4 MSVM的分类结果与Kappa系数
5 结 语
基于目前普遍存在的Android恶意软件检测问题,本文在以往分类方法的基础上提出了采用多核模糊支持向量机算法对恶意软件进行检测分类,通过交叉验证法进行实验来评估检测效果。实验结果表明采用多核模糊支持向量机算法对恶意软件进行分类的方法是可行的,且在分类准确度上优于一般支持向量机算法,能够更好地对恶意软件进行检测分类。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
领导决策信息(2018年16期)2018-09-27
电子技术与软件工程(2017年14期)2017-09-08
数学学习与研究(2017年3期)2017-03-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
科技视界(2015年24期)2015-08-22
