
缅甸植物多样性数据集
2018-11-17 07:18:20何延彪庄会富王雨华
中国科学数据(中英文网络版) 2018年1期
何延彪,庄会富,王雨华*
1.中国科学院昆明植物研究所,科技信息中心,昆明 650201
数据库(集)基本信息简介

数据库(集)名称 缅甸植物多样性数据集数据作者 何延彪、庄会富、王雨华数据通信作者 王雨华(wangyuhua@mail.kib.ac.cn)数据时间范围 1800~2017年地理区域 缅甸及周边区域数据量 2 GB,合计总数据量45.73万条数据格式 结构化文本数据数据服务系统网址 http://210.72.88.243 http://www.sciencedb.cn/dataSet/handle/499基金项目 国家科技基础性工作专项(2013FY112600)数据库(集)组成缅甸生物多样性数据集由 8部分整合而成,参考的数据源分别是(1)BHL:Biodiversity Heritage Library—缅甸植物,数据量2 921 736条;(2)中国植物物种信息—缅甸植物,数据量2 013 806条;(3)中国种子植物—缅甸植物,数据量15 842条;(4)Smithsonian Institution—缅甸植物,数据量 14 473条;(5)GBIF:Global Biodiversity Information Facility—缅甸植物,数据量141 764条;(6)云南植物志—缅甸植物,数据量153 396条;(7)eFloras中的FOC,英文版《中国植物志》的缅甸植物,数据量5 254条;(8)Tropicos—缅甸植物,数据量14 589条。以记载缅甸有分布为原则对上述数据源进行清洗和整合,完成缅甸植物多样性数据集,共有45.73万条数据。
引 言
缅甸联邦共和国(简称缅甸)地处东南亚,是全球重要的生物多样性热点地区,也是全球生物多样性保护和研究的热点地区之一[1]。关于缅甸生物多样性的研究由来已久,形成了大量文献资料、科学数据记载[2],但因平台多、信息分散,迄今为止,缅甸还没有一部科学完整的植物名录和相关科学数据集,这给生物多样性保护和资源的可持续利用带来了巨大障碍。随着国家“一带一路”发展倡议和中国科学院“走出去”战略的持续推进,中缅双方在植物科学领域开展了广泛的合作。近年来成立的中国科学院东南亚生物多样性研究中心,为实现缅甸在环境保护、植物资源可持续利用等方面提供科技支持。为支撑该研究中心开展植物学相关工作,中国科学院昆明植物研究所信息化团队通过数据集成和分析,将分散在世界各信息平台关于缅甸生物多样的数据进行了系统的信息整合。收集了全球各大信息服务平台中关于缅甸植物多样性的数据,主要包括标本记录、历史文献记载、周边区域已完成的植物志等多源信息,通过数据清洗、集成,结合物种区系分布,深度整合形成了缅甸植物多样性数据集,将为后续的缅甸植物多样性保护、研究和资源可持续利用提供数据支撑。
1 数据采集和处理方法
1.1 数据源的筛选
作为植物多样性最为丰富的地区之一,缅甸向来是国际上植物学的研究热点区域。基于植物区系与植物分布的地域分布连续性原则,项目组广泛收集了缅甸及其临近国家和地区的植物志、标本记录和相关记载,如《中国植物志》[3]《Flora of China》[4]《云南植物志》[5]等,以已发表资料中记录的“缅甸有分布”,为缅甸植物基础名录的确认依据。整合的资料有中国植物物种信息数据库、iFlora信息平台和中国种子植物数据库(光盘版);Smithsonian Institution发布的缅甸植物名录;eFloras中缅甸相关记载;GBIF(Global Biodiversity Information Facility)、BHL(biodiversity heritage library)等平台上缅甸相关的植物多样性数据[6-12]。
1.2 基础数据清洗与整合
中国植物物种信息数据库内容涵盖了中英文版本的中国植物志和云南植物志,通过数据库后台项目组整合得到了1.1万条物种记录。
Smithsonian Institution—缅甸植物名录等信息平台的科技资料具有很高的参考价值,利用网络蜘蛛技术来抓取该目标站点数据,通过提取数据索引URL列表、下载网页数据、解析网页数据等流程获取了1.1万条缅甸植物名称信息。
GBIF:全球生物多样性信息基础设施,是由世界各国政府资助的开放数据研究基础设施,旨在为任何人提供任何有关地球上所有类型生命的数据。从GBIF站点下载的缅甸植物数据,是带格式的文本数据,通过专用的导入工具直接导入数据库。在导入缅甸数据集时,使用的是PLSQL Developer数据库客户端附带的文本导入器,完成了12余万条信息的整合。详细的数据源信息参见表1。

表1 数据集参考的主要信息源
1.3 提取拉丁学名索引,构建缅甸植物参考名录
从结构化文本、半结构化的HTML格式等解析出来的相关缅甸数据,会存在一些异常值、特殊标记等,需要进一步对数据进行清洗处理。对于不确定的异常数据,挑出来由人工核对。从中国植物物种信息数据库、Smithsonian Institution–缅甸植物名录、GBIF中提取有关于缅甸的物种数据,形成 3个子集。对子集的数据进行合并,合并的依据是拉丁名字段(包括属名、种加词、种下等级加词)。如果是同一个拉丁名,则合并,合并之后标记来源。如果在原子集没有对应的拉丁名,则作为新的拉丁名,并标识从而完成了GBIF、中国植物志、云南植物志、Smithsonian Institution—缅甸植物名录等多源资料的聚合,形成相对全面的缅甸植物参考名录。
1.4 集成关联数据,构建缅甸植物多样性数据集
数据集成关联数据主要包括:
(1)以拉丁名为数据集主键
以上述缅甸植物参考名录为索引,以简化的物种Latin名称为主键,关联BHL历史文献数据、GBIF地理数据、植物志物种描述数据、物种经济利用等数据,从而构建信息全面的生物多样性数据集。
(2)对不同分类系统,拉丁名为异名数据的集成
针对数据源中存在不同分类系统,拉丁名为异名的数据情况,本数据集做了如下处理:
建立正名与异名对应关系数据库,主要来自于中国植物物种信息、eFloras.org中正名与异名对应关系数据,这样可以解决数据集中使用异名的问题。
在数据关联处理过程中,一个物种使用拉丁异名来实现连接时,与拉丁正名的对应关系,转换为通过拉丁正名来实现连接。
本数据集是从物种层次集成,通过拉丁正名—异名对应关系来处理不同的数据集集成问题,所以对于使用不同分类系统的数据集在物种层次影响不大。
本次收集到的拉丁正名—异名关系数据只涵盖了部分数据,今后还将收集全面正名—异名关系数据,如集成来源于species2000、EOL、UBIO的正名异名关系数据,可以大幅提高物种数据的集成度(通过拉丁正名或者异名来关联集成不同数据源的数据)。
(3)拉丁名规范化处理(包括拉丁正名和拉丁异名)
数据集集成的关键点在于各子数据集的拉丁名遵守同一规范。因不同的子集会有不同的拉丁名格式,有的子集里面的拉丁名属名与种加词之间可能有2个空格,有的是一个;有的带有作者名,有的不带作者名,并且作者名还完全有可能不同,可能是简写的,也可能是全拼的。此次集成采取的是简化Latin名称的办法,只保留拉丁属名、种加词和种下等级加词,最大可能保障关联与匹配的准确性。
整合完成的缅甸生物多样性数据集包含物种名录信息1.5万条,物种描述信息1.7万条,生物多样性GBIF基础数据14.17万条,其他BHL文献信息近30万条,数据量约2 GB。数据集成框架如图1。
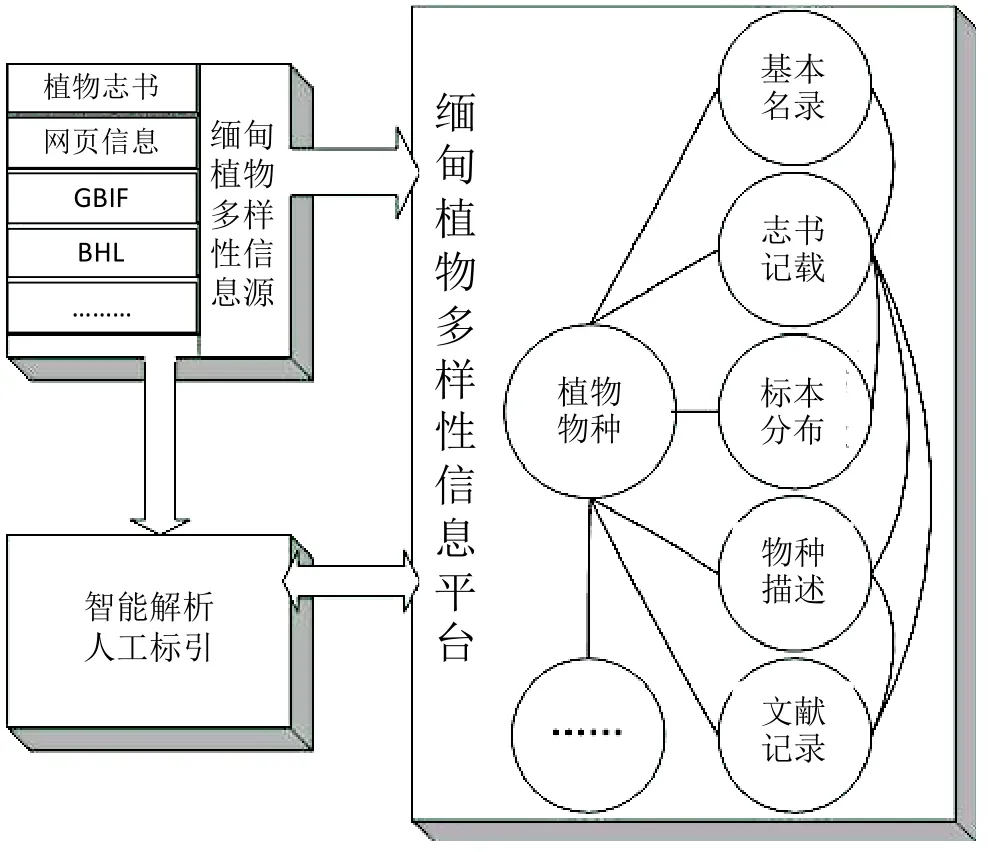
图1 缅甸植物多样性科学数据集成框架图
1.5 信息服务平台的开发
为方便科研人员查询和下载基础科学数据,项目组完成了“缅甸植物多样性信息平台”站点的开发,站点以一种简单、易用、快速的方式,提供智能搜索服务(图 2)。解决了多个数据合并后存在的数据字段及类型众多、用户难以选择搜索类型的问题,增加了数据使用的易用性。同时,随着数据用户的反馈,以及新知识的不断出现,也有利于本数据集的及时更新。信息平台提供了统一的搜索窗口,程序根据用户输入智能判断可能的类型,并给出提示列表和搜索结果。平台支持数据检索、浏览和数据下载导出服务(需注册)。对于 BHL、GBIF和eFloras等外部数据,平台仅提供数据链接,详细数据用户需到各平台自行查询。
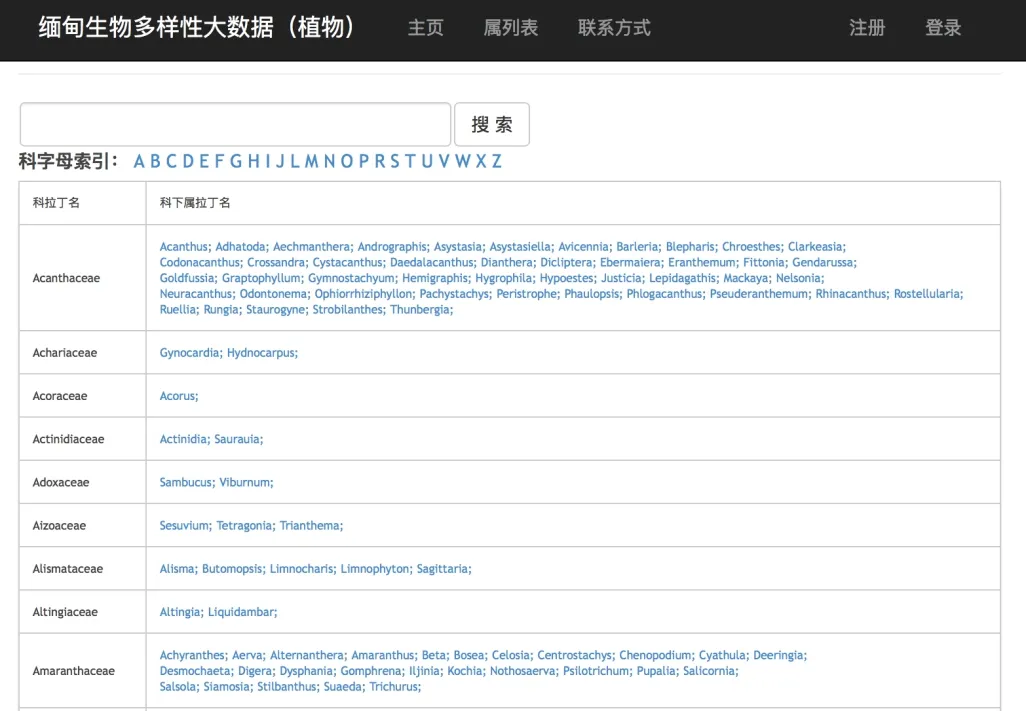
图2 缅甸植物多样性信息平台主页
2 数据样本描述
以检索“大百合Cardiocrinum giganteum”为例,结果页面给出聚合的数据源列表,包括中国植物志、Flora of China、中国种子植物光盘,以及BHL、GBIF的相关数据链接。点击可直接跳转至详细数据页面。典型的数据其整合情况为:物种分类等级信息,包括物种的科属种等分类登记的中文名和拉丁学名,以及信息的来源出处;物种的英文描述主要来源于Flora of China;物种的中文描述,包括生境、海拔、国内外分布、是否引种栽培、标本情况等,详细数据样例参见图3。
3 数据质量控制和评估
本数据集是一个基于已发布数据源集成的应用,所以数据质量控制,主要基于探查数据内容、结构和异常[2]方面着手。重点探查的过程如下:
(1)数据异常,探查解析后的数据是否存在特殊标记,如HTML标记;
(2)字段解析,探查解析后的字段是否与原数据源相一致,最大程度上避免在解析后数据字段丢失的情况。
(3)随机抽查,发现可能的数据问题。
对于异常数据,字段解析错误的数据进行了全面排查(通过排查程序和人工查验方式),在最终集成的数据集中删除了异常和解析错误数据。集成后的数据集,与原始数据源的数据保持较高的一致。同时为保护数据版权,所有外部数据,在平台上仅提供索引和链接,均采用链接的方式提供给用户。
通过随机抽样统计,数据质量水平被评估为较高。通过清洗、标准化、集成整合后的数据能够实现较高的关联度,各个数据与源数据源一致性均在95%以上。

图3 物种信息详细页面展示
4 数据价值
近年来,生物多样性科学数据迅速积累,科研工作者面临的最大问题在于如何快速、精准地获取整合数据。海量数据分散在类型单一、离散、数据存储异构、标准规范不统一的信息平台中。与人们需要的多类型、多维度高度集成的数据需求不相符,所以如何聚合多源科学数据,并以此为基础构建满足科研需求的信息服务,将是以后科学数据库研究人员的工作重点。通过开展专业数据库和互联网信息数据的聚合,集成整合形成了缅甸植物多样性基础数据,如历史文献数据(BHL数据),地理分布数据(GBIF数据、中国种子植物数据),多种类型的物种描述数据(eFloras.org物种信息、中国植物物种信息数据库中的中国植物志、云南植物志数据),经济利用和保护等级名录数据(中国植物物种信息数据库中收录的相关数据)等,从而形成缅甸植物多样性大数据,可以初步展现缅甸植物物种多样性信息,可以有效支撑科研人员在缅甸开展植物学采集、考查、研究、资源开发利用等研究工作。
目前,国内还很少有针对热点地区的生物多样性综合科学数据集和信息服务平台。本数据集的构建、多数据源的集成等方法,可以为构建其他区域性或大尺度的生物多样性数据集提供参考。
5 数据使用方法和建议
本数据集和信息平台服务网址为http://210.72.88.243,在Science Data Bank中的相关链接地址为http://www.sciencedb.cn/dataSet/handle/499。相关页面与功能参考图3。整合数据的下载见“资源下载”栏目,网址为 http://210.72.88.243/Data/DataBaseList。信息平台后续将完善数据分析功能,旨在构建功能完善的缅甸植物多样性信息服务平台。
猜你喜欢
派出所工作(2022年3期)2022-04-14 07:37:18
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
中外玩具制造(2018年12期)2018-12-11 07:37:26
卫拉特研究(2018年0期)2018-07-22 05:47:52
计算机与生活(2018年3期)2018-03-12 08:38:11
文体用品与科技(2017年5期)2017-05-17 05:31:10
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
