
精准扶贫项目与农村居民收入增长
——基于倾向得分匹配模型的分析
2018-11-15 05:50侯一蕾温亚利
统计与信息论坛 2018年11期
赵 正,侯一蕾,温亚利
(北京林业大学 经济管理学院,北京 100083)
一、引言
中国的扶贫实践始于20世纪80年代中期,时至今日已经使六亿多人成功脱贫,成为第一个实现联合国千年发展目标使贫困人口比例减半的国家。但是,当前中国的扶贫工作仍然存在贫困居民底数不清、扶贫措施针对性不强、扶贫资金和项目指向不明等一系列问题。2013年11月,习近平总书记在湖南湘西考察时提出了“精准扶贫”的重要思想,即针对不同贫困区域环境、不同贫困农户状况,运用科学有效程序对扶贫对象实施精确识别、精确帮扶、精确管理的治贫方式。也就是说,精准扶贫的对象是真正的贫困农户。另一方面,习近平总书记在2015年10月再次强调,实施精准扶贫方略需要坚持“分类施策”的原则,即“因人因地施策,因贫困原因施策,因贫困类型施策”。因此,设计科学合理的精准扶贫模式就成为提升农户参与积极性和扶贫政策实施效果的保证。基于此,本研究以典型地区贫困农户作为研究对象,从主要的精准扶贫模式出发,就精准扶贫项目与农村居民收入增长之间的关联及影响关系进行深入探讨。
二、文献综述
关于精准扶贫的研究始于2013年,但目前已有的研究成果比较丰富,涵盖了精准扶贫的模式选择、问题研究及对策分析等方面的内容。
就精准扶贫的模式选择而言。有研究认为扶贫模式的选择需要考虑不同地区的贫困特点和致贫原因。有研究认为中国西南石漠化地区精准扶贫取得成效的关键,是在科学规划和精准识别的前提下建立农业产业化的扶贫发展模式[1];还有研究指出,中国川藏地区的贫困问题受到生态、经济、社会以及制度等因素的约束,其扶贫模式应当更多地考虑提升公共服务、加大资金投入以及创新机制等方面的内容[2]。另一方面,有研究认为有效的扶贫模式应当是将改善贫困状况和增强发展能力相结合的模式,精准扶贫工作应当注重农户的教育培训环节[3];也有研究指出,有效的精准扶贫模式需要一方面瞄准对象、精确识别,另一方面对症下药、联动帮扶[4]。
就精准扶贫存在的问题而言。有学者从农户自身角度出发,认为中国农户贫困的主要原因是自身发展能力的缺乏,具体体现在对借贷等精准扶贫措施的积极性不高等方面[5],还有学者提出中国精准扶贫精准度不高的原因之一是农户在参与扶贫项目时存在信息不对称的问题[6];其次,从扶贫政策角度考虑,有学者指出中国的农村社会正在不断发生分化,当前的扶贫措施需要更多地考虑扶贫政策与社区发展之间的关系[7];还有学者更加详细地提出,中国的精准扶贫工作存在需求、资金、市场等方面的排斥性因素,都不利于扶贫工作的有效开展[8]。以上研究表明,农户自身存在的问题与扶贫政策的缺陷,都会导致精准扶贫的实践与政策相背离。
就精准扶贫的路径与对策分析而言。已有研究普遍强调了建立和强化精准扶贫机制的重要性,即更加关注区域和人口的实际需要以及扶贫资金的投向和效果,提高扶贫的精准度[9];还有学者认为农户的参与是提高扶贫转化率的根本之策,也是发现和解决贫困问题、提升精准扶贫绩效的重要手段[10];有研究进一步提出了提高精准扶贫有效性的方式方法,即一方面制定和实施有效的财政、金融政策,另一方面加强对贫困农户的技能培训,提升生计水平,从两方面努力来达到脱贫的目的[11]。
从相关研究所存在的问题出发,本研究认为:一方面,由于精准扶贫对于大部分地区农户而言仍然是一个比较新的话题,目前中国只有少数试点地区开展了相关的精准扶贫项目,参与项目的农户人数也较少,因此用于此类研究的样本数量较小,在观察研究过程中存在的小样本偏差,将会引致偏倚的结论,从而降低研究结果的可信度;另一方面,Heckman曾经指出,样本选择性偏差和受访者的先验经验、个体特征等因素同样会影响研究结果[12]。也就是说,农户精准扶贫项目参与情况会受到多种因素的影响,而非仅仅由项目本身的好坏所决定,已有研究并未对此加以重点关注。本研究旨在通过引入倾向得分匹配法(PSM)解决这一系列问题。
基于已有研究成果和“实事求是,因地制宜,分类指导”的基本原则,本研究认为,充分提升农户的参与积极性是精准扶贫工作实施的重点,设计合理的精准扶贫实施方式,则是提升农户参与积极性的保证。结合秦岭地区精准扶贫工作开展的实际情况,本研究以贫困补贴模式、合作社模式、生态旅游模式以及整村推进模式为例进行分析,旨在全面把握当地精准扶贫的基本情况,同时对不同模式下农户收入的增减情况进行估算与对比,进而得出最适宜的扶贫模式,为相关政策的制定提供依据。
三、研究区域和指标设计
陕西省是中国生态脆弱、水土流失严重的省份之一,也是贫困问题较为突出的区域。本研究课题组于2016年对秦岭地区农户的精准扶贫项目参与意愿进行了实地调研,共涉及陕西省佛坪县、城固县、洋县、太白县、眉县、周至县6县的11个行政村。本研究在选取样本农户时依据典型抽样和随机抽样相结合的原则,选择调查农户共计600户,剔除由于常年在外打工而得到的无效问卷、有明显失真的问卷、数据信息缺失严重以及完全对本次研究相关变量无法满足的问卷,最终的有效问卷为561份,调查问卷有效率达93.50%(表1)。
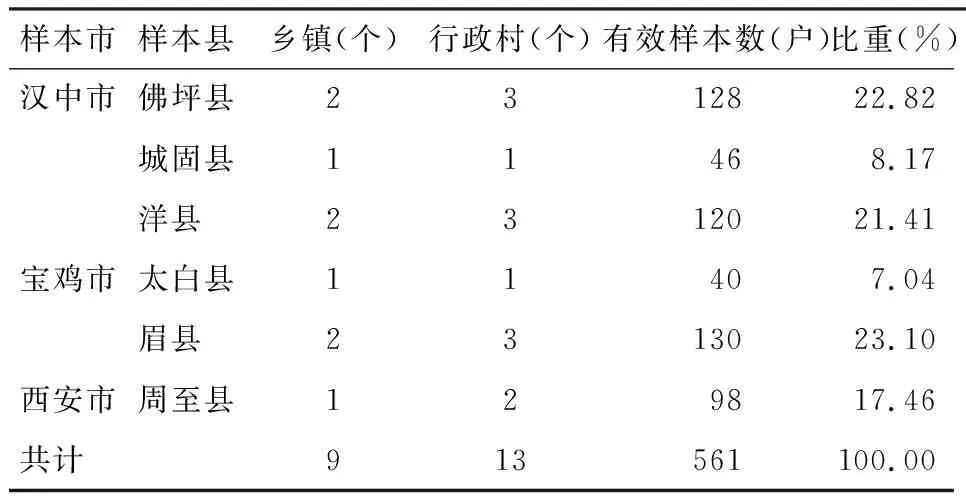
表1 研究区域和问卷发放情况
就问卷调查的具体内容而言,首先对农户在2014—2016年的收入情况进行了调查,与收入相关的调查问题包括了农户在贫困补贴、合作社、生态旅游以及整村推进四种精准扶贫模式下的家庭月收入额。其次,还对以下3个方面的内容进行了调查:(1)农户的个人特征,包括农户的性别、年龄、受教育程度以及农户身份等;(2)农户的精准扶贫项目参与情况,以2016年农户的项目参与情况作为区别实验组与对照组的分类变量,同时对2014和2015年农户的项目参与情况进行调查,以此来降低数据的内生性问题;(3)考虑到可能存在的不可观测因素和交叉影响因素的作用,以及解释变量与被解释变量间可能存在的非线性关系,本研究通过对个别变量的交叉和平方化处理构建了6个虚拟变量。具体的变量设置及描述统计情况如表2所示。
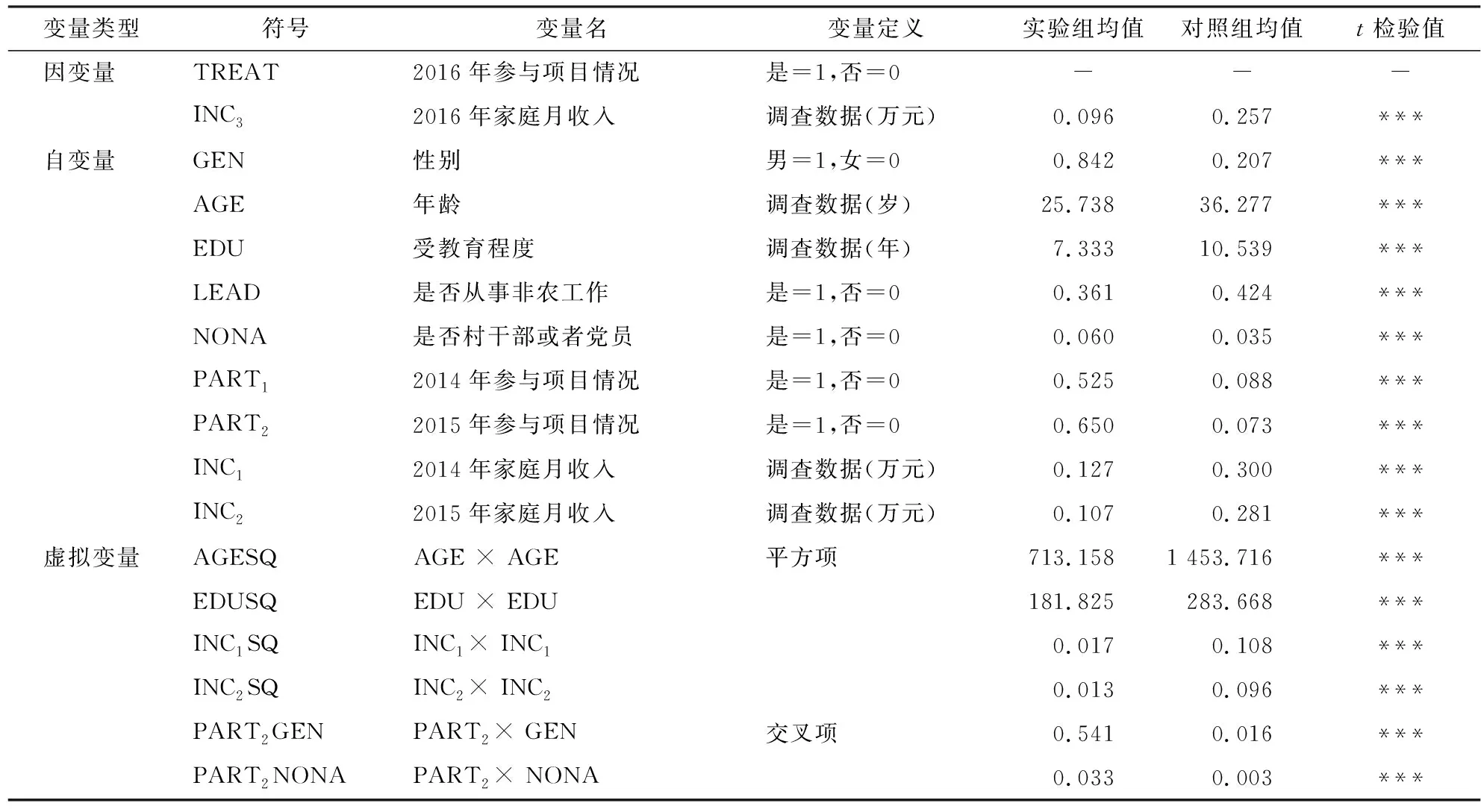
表2 变量及其取值
由表2可知,实验组农户各年的收入情况均低于对照组,且各组各变量的t检验结果显示其组间差异非常显著(P<0.01)。比较各变量可知,实验组农户的年龄略小、受教育程度略低,这类农户普遍具有更多的闲暇时间;同时,实验组农户的村干部或党员任职要优于对照组,即实验组农户对于精准扶贫政策的接触频率及认知程度相对较高。由此可以推断:参与精准扶贫项目理论上应当促进农户收入水平的提升,因此导致其收入较低的因素很有可能是内生性的。描述统计部分只对农户的收入进行了简单对比,并未体现农户收入与其精准扶贫项目参与情况之间可能存在的因果关系。因此,本研究拟对真实情况进行进一步的估计。
四、倾向得分匹配模型设计
在精准扶贫项目参与对农户收入的影响分析中,实地调研所得到的数据主要是非实验数据或观测数据,而不是随机对照实验数据。原因在于:从数据获取的角度考虑,对大量受访者进行调查,然后随机分配到参与组和非参与组的实验设计并不容易实现;反之,农户参与和未参与精准扶贫项目的行为和结果很容易通过观察得到。但是,利用观察数据直接进行研究将很容易得出非常偏倚的结论。比如:用参与项目的农户中收入状况最差的10%样本,与未参与项目的农户中收入状况最好的10%样本进行对比,将会得出“精准扶贫项目对农户收入产生负面影响”的错误结论。因此,本研究拟通过引进倾向性得分匹配法来尝试解决这一问题。
倾向得分匹配法(PSM)是使用非实验数据或观测数据进行干预效应分析的统计方法,可以有效降低调查样本的选择性偏差和内生性干扰等问题。倾向得分匹配的理论框架是“反事实推断模型”,即假定任何因果分析的研究对象都有两种条件下的结果:被观测到的和未被观测到的结果。对于处在干预状态和控制状态的样本而言,“反事实”分别表示处于相应状态下的潜在结果。倾向得分匹配法可以解决“反事实”无法观测的问题。该方法首先将可能存在选择性偏差和内生性干扰的混淆变量纳入到回归模型中,通过计算得出其倾向得分,即实验组样本的条件概率;进而以倾向得分为基础,计算与每个实验组样本个体最为匹配的对照组样本个体,从而达到组间的平衡。
具体来说,首先对原始数据进行归纳与整合,得到两个组别的样本数据,实验组表示该组农户有参与精准扶贫项目,对照组则表示该组农户没有参与精准扶贫项目。令因变量Y1和Y0分别表示实验组和对照组农户收入,二值变量D表示农户是否参与项目(D=1则代表该农户在实验组,D=0则代表该农户在对照组)。本研究的目的在于探讨已经参与精准扶贫项目的农户与假设其未曾参与的情况相比,其收入状况是否会更好。当样本农户属于试验组时,事实E(Y1|D=1)可观测,而反事实E(Y0|D=1)无法观测;同理,当样本农户属于对照组时,事实E(Y0|D=0)可观测,而反事实E(Y1|D=0)无法观测,这种研究思路称为“反事实因果分析”[13]。同时,由于个体农户的参与情况存在差异,因此本研究重点关注实验组中事实E(Y1|D=1)与反事实E(Y0|D=1)之间的样本均值差,即平均参与效应(ATT):
ATT=α[E(Y1|D=1)-E(Y0|D=1)]+(1-α)[E(Y1|D=0)-E(Y0|D=0)]
其中,α为实验组样本农户比重,(1-α)为对照组的样本农户比例。考虑到各组样本的随机分配方式以及反事实无法观测的困难,本研究引入非混淆假设E(Y1|D=0)=E(Y1|D=1)和E(Y0|D=0)=E(Y0|D=1)对平均参与效应(ATT)的表达式进行简化[14],得到:
ATT=E(Y1|D=1)-E(Y0|D=0)
本研究用倾向得分(Propensity Score)作为对多个混淆变量x的代替进行估计,它表示“个体在一组既定的协变量下,接受某种参与(Treatment)的可能性”[15]。令P(x)表示实验组中变量x的倾向得分,即P(x)=P(D=1|x),则平均参与效应(ATT)可以进一步改写为:
ATT=E(Y1|D=1,P(x))-E(Y0|D=0,
P(x))
由于本研究的参与变量D为二值变量(0,1),因此采用logit模型对倾向得分值进行估计。对倾向得分值进行估计的目的在于,将多维协变量x转换为一维变量P(x),从而降低匹配的复杂程度。当前比较常用的倾向得分匹配方式有4种,即最邻近匹配法(Nearest Neighbor Matching Method)、核匹配法(Kernel Matching Method)、分层匹配法(Stratification Method)和半径匹配法(Radius Matching Method)。本研究拟采用最邻近匹配法,对与实验组样本的倾向得分最为接近的实验组样本进行一对一匹配,数据的整理和分析采用Stata软件完成。
五、实证结果分析
(一)倾向得分的Logit模型估计结果
本研究的因变量类型为二分类变量,自变量包括二分类变量、连续变量和有序多分类变量,因此采用二分类Logit回归模型进行分析,来探讨二分类因变量与自变量之间的关系。同时,还计算了各影响因素变量的边际变化对农户参与精准扶贫项目的概率的影响。计算结果如表3所示。
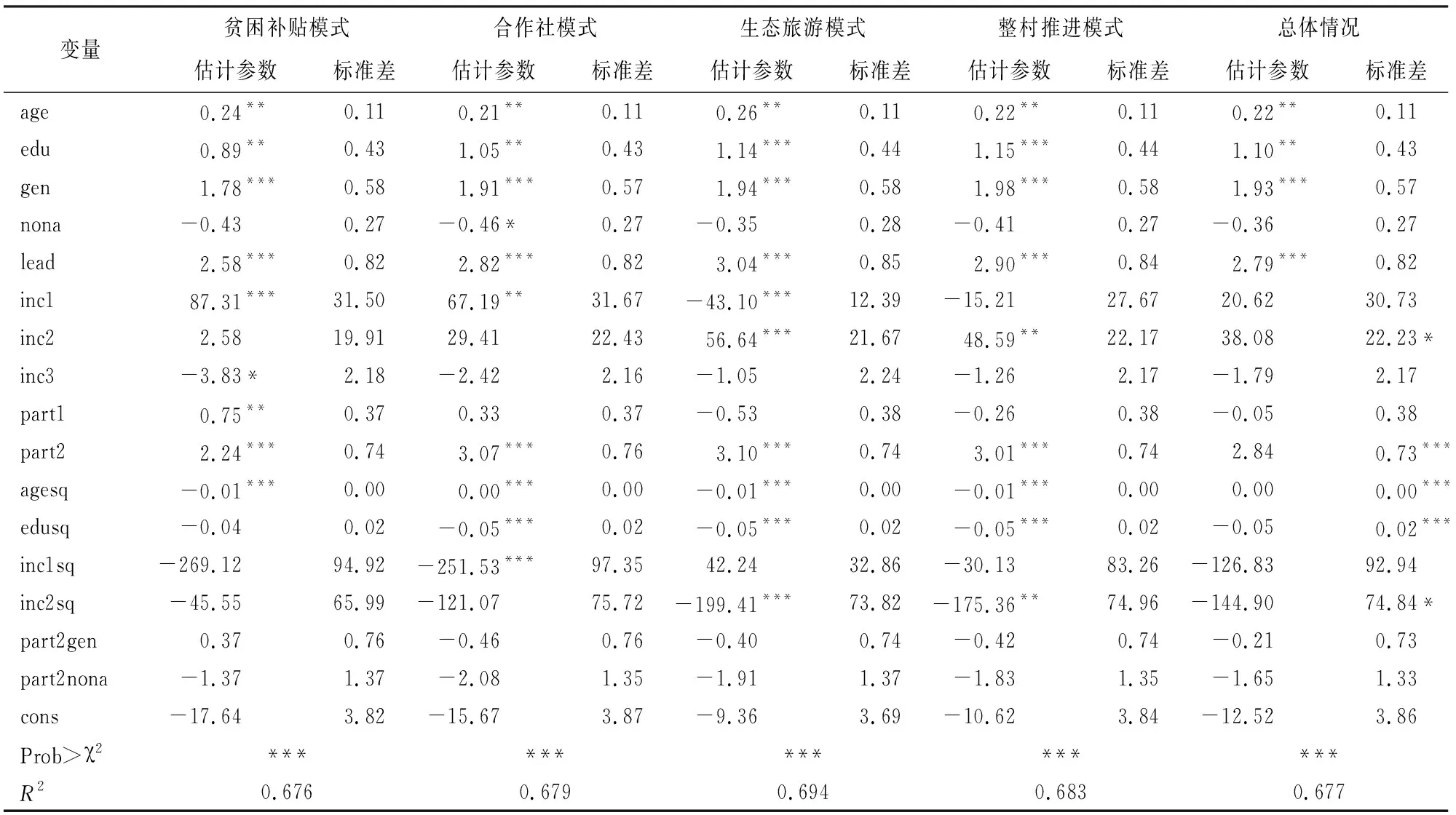
表3 不同扶贫模式下倾向得分的logit估计结果
注:***、**、*分别表示1%、5%和10%显著性水平。
由表2可知,年龄和教育因素会显著提升农户参与精准扶贫项目的概率,农户的年龄越大、受教育程度越高,农户参与精准扶贫项目的概率就越高;类似地,具有村干部或党员身份的农户参与精准扶贫项目概率要显著高于普通农户;相反,从事非农工作的农户参与精准扶贫项目的概率要低于传统农户。此外,就2016年的情况而言,农户的收入水平越高,其参与精准扶贫项目的概率就越低。可能的原因是,随着收入水平的提升,农户通过参与扶贫项目来继续提高收入的主观意愿就会逐渐降低。本研究认为,这是由于农户对于精准扶贫重要功能的认知不够充分,他们并不理解“精准扶贫”和“收入提升”之间的因果联系。为了体现和验证精准扶贫项目对于农户收入的真实作用程度和方向,需要进行倾向得分匹配分析。
(二)倾向得分匹配的估计结果
采用相邻样本匹配的方法进行倾向值得分匹配,试验组的可匹配情况如表4所示。由表4可见,按照本研究设定的匹配规则,试验组仅有8位受访农户未能匹配到合适的对照组样本。
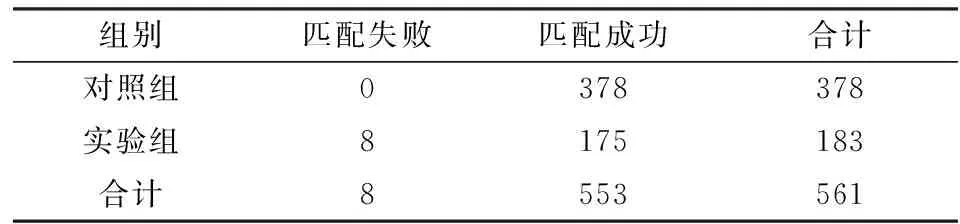
表4 倾向得分匹配的可匹配情况
由表5所示的倾向得分匹配结果可知:总体上,匹配前的农户收入呈现“实验组<对照组”的特点,且二者差值小于0,表明参与了精准扶贫项目的农户,其收入值反而更低了;匹配后的农户收入呈现“实验组>对照组”的特点且ATT>0,表明参与精准扶贫项目确实可以提升农户收入。就不同模式对农户收入的提升作用而言,生态旅游模式的作用最为显著,合作社和贫困补贴模式次之,整村推进模式的作用相对较小;就不同模式下收入的绝对值而言,贫困补贴和合作社模式下的农户收入较高,生态旅游和整村推进模式下的农户收入较低。
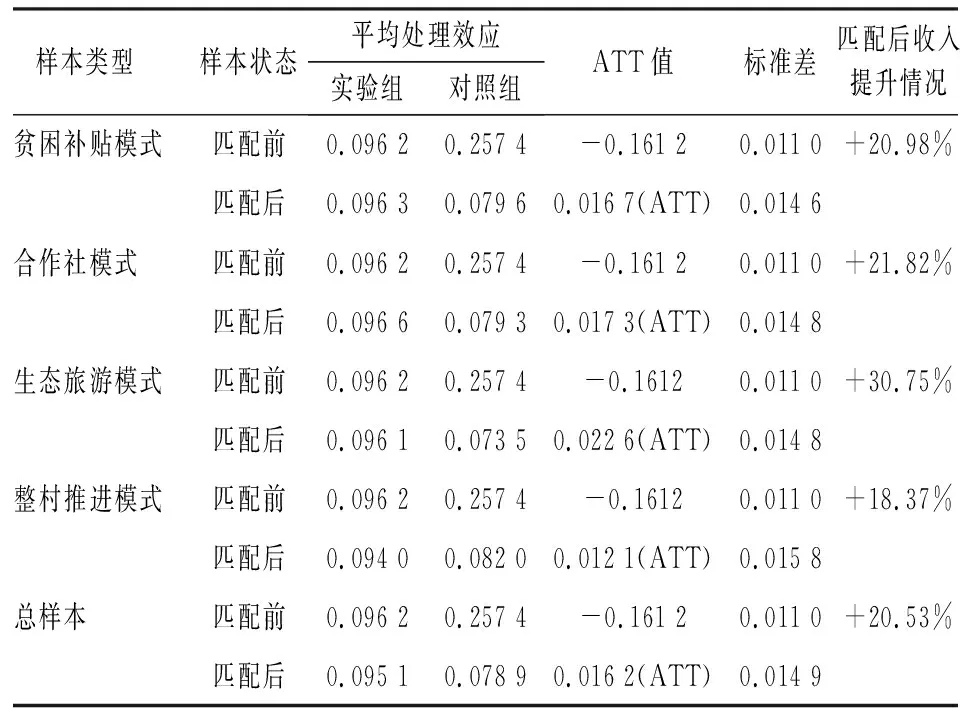
表5 倾向得分匹配的估计结果
注:***、**、*分别表示1%、5%和10%显著性水平。
以上倾向得分匹配的结果充分证明:当前农户对精准扶贫项目的参与存在着选择性偏差和内生性干扰,忽视这些问题将会导致精准扶贫政策的作用被低估甚至误判。倾向得分匹配方法降低了此类干扰对真实研究结果的影响,表明在农户参与精准扶贫项目后,其收入水平会获得不同程度的提升。
(三)倾向得分匹配的平衡性检验
在倾向得分匹配估计的基础上,本研究拟对结果的可靠性进行平衡性检验,目的在于验证匹配后实验组与对照组的匹配变量不存在显著的组间差异。以总体收入为例进行检验,结果如表6所示。可知,logit回归的伪R2由匹配前的0.673下降到了匹配后的0.068,表明倾向值匹配后混淆变量对于处理效应所提供的新信息大幅减少到0.1以下;同时,总体组间均值差异为10.1%,可以认为平衡性假设得到了满足。

表6 倾向得分匹配前后的相关指标对比
注:***、**、*分别表示1%、5%和10%显著性水平。
此外,本研究通过对实验组和对照组各变量进行标准偏误(SB)和t检验计算来反映偏差的减少情况,结果如表7所示。其中,变量的标准偏误是实验组与对照组的样本均值之差与样本方差平均值的平方根之比。已有研究对具体评判的标准阙值并未达成一致,但是一般而言,标准偏误越小则表示匹配的效果越好[16-17]。
从总体上看,各变量的标准偏误在倾向得分匹配处理后得到了极大的改善,突出体现在其绝对值的大幅降低上。具体来说:(1)计算得到的标准偏误的绝对值基本都小于20%,可认为倾向得分匹配的估计结果是可靠的[18];(2)与匹配前相比,除“是否从事非农工作”这一变量的标准偏误增加之外,其他所有变量标准偏误的绝对值均呈现出较很大幅度的降低;(3)在进行倾向得分匹配后,绝大部分变量的t检验统计量不再显著。因此,认为该倾向得分匹配的结果是可靠的,该方法在很大程度上消除了实验组与对照组样本之间的个体差异,表明倾向得分匹配后的结果更加符合实际情况。与此同时,匹配标准偏误绝对值的大幅降低也表明,农户问卷调查由于受到样本个体生存背景、主观情感以及对调查问题的认知程度等因素的影响,导致调查的误差相对较大,还需要设计更加合理的调查内容及形式以提升农户回答问题的真实性和可靠性。
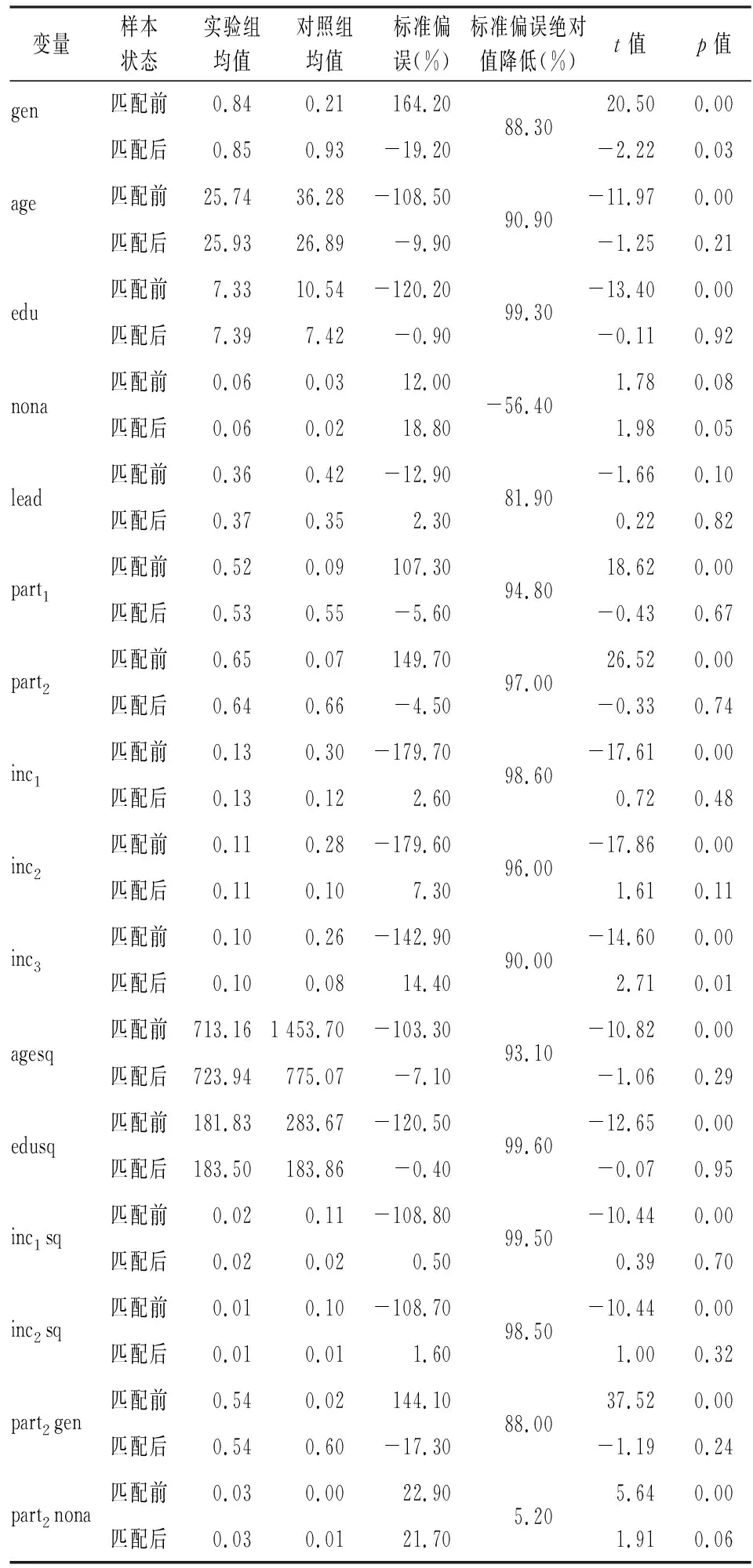
表7 倾向得分匹配结果的平衡性检验结果
六、结论与讨论
综上所述,本研究采用倾向性匹配得分法(PSM)分析了农户参与精准扶贫项目对其收入的影响,并对研究结果的平衡性进行了检验。研究发现:(1)在进行倾向得分匹配前,农户收入呈现“实验组<对照组”的特点,而经过倾向得分匹配后,农户收入呈现“实验组>对照组”的特点,表明在参与精准扶贫项目后农户的收入水平会获得提升。(2)就不同模式对收入的提升作用而言,生态旅游模式的作用最为显著,合作社和贫困补贴模式次之,整村推进模式的作用相对较小;就不同模式下收入的绝对值而言,贫困补贴模式和合作社模式下的农户收入仍然最大,生态旅游模式和整村推进模式下的农户收入相对较小。(3)倾向得分匹配法的计算和验证结果显示,当前农户对精准扶贫项目的参与存在着选择性偏差和内生性干扰,这些因素共同导致了精准扶贫政策的作用被低估甚至误判。
基于以上研究结论,本研究认为精准扶贫项目的顺利实施离不开农户的关注和参与,在日后的工作中,需要重点提升农户对精准扶贫相关政策的了解程度,使其明晰精准扶贫项目的实施机理和最终目的,让农户意识到整体精准扶贫项目实施与个人收入提升之间的因果联系,进而深化农户感知,提升其参与精准扶贫项目的主动性。换句话说,只有充分发挥公众的作用,才能提高精准扶贫项目实施的效率,为精准扶贫工作的进一步开展创造条件。此外,从方法层面考虑,倾向性得分匹配法被证实可以有效降低调查样本的选择性偏差和内生性干扰等问题,该方法可以在实验组和对照组交集很小的情况下消除组别之间的干扰因素,揭示研究对象之间的真实因果关系。在下一步的研究中,还可以在研究方法的综合使用方面做进一步拓展,如,使用不同的匹配方法进行估计,并比对不同的计算结果分析,选择最合适的方法进行研究;增加衡量个体特征变量的个数,使研究的结论更加全面。
猜你喜欢
今日农业(2022年13期)2022-09-15
今日农业(2021年8期)2021-07-28
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·高一版(2021年2期)2021-03-19
河北理科教学研究(2020年2期)2020-09-11
领导决策信息(2018年16期)2018-09-27
中国粮食经济(2018年11期)2018-01-23
中国粮食经济(2018年7期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
新高考·高二数学(2014年7期)2014-09-18
