
基于话单数据的移动通信用户画像研究①
2018-11-14 11:37张海旭胡访宇赵家辉
计算机系统应用 2018年11期
张海旭,胡访宇,赵家辉
1(中国科学技术大学 信息科学技术学院,合肥 230027)
2(安徽省公安厅 科技信息化处,合肥 230061)
1 引言
随着我国移动通信市场的迅速发展,手机已成为人们日常生活中不可或缺的一部分.用户在使用手机的过程中产生了大量的个人历史数据,这些数据可以概括为以下几种: 1)位置信息,通过全球定位装置(Global Positioning System,GPS)、手机信号塔等方式获取的地理位置信息; 2)使用信息,记录了用户在何时使用了手机做了什么; 3)社交信息,隐含在话单数据,GPS以及通讯录等数据里.这些历史数据隐含了与用户相关的个性化信息,反映了用户的生活习惯和社交模式.这些数据为研究用户属性和特征提供了新的渠道.
话单数据是运营商计费所产生的.话单数据有被动产生、覆盖范围广、成本低、分析周期短等优点,已经在了解人们的移动模式[1],理解人类行为动力学特征[2,3],感知用户所在地区的地理环境、生活方式、交通状况和发展水平等[4,5]方面广泛地使用.例如Etienne Thuillier等[6]使用话单数据,根据用户每天与预设区域的关系,将用户划分为6类,在此基础上,对用户进行以一周时间为周期的聚类分析,发现了12种类型的周活动模式.杨喜平、方志祥[7]等利用移动电话位置数据,理解人类时空聚散模式.Schneider等[8]借鉴复杂网络中模体的概念,发现人们日常生活中存在的17中网络结构,然后使用模体来概括来自不同国家人们的时空移动模式.Jiang等[9]以新加坡为例,演示了如何使用手机通话详细记录(CDR)数据,其中包含数百万匿名用户,以提取可与基于活动的方法相媲美的个人移动网络.
手机话单数据中含有丰富的时空信息和社交信息,目前基于话单数据的研究多集中在分析数据中的时空信息.本文同时利用话单数所包含的时空信息和社交信息,提取用户特征,发现特征相似的用户群体和为用户创建个性化词云名片,完成对用户画像.文本研究,为理解用户特征提供新的视角,为生产生活的提高、相关政策的制定提供了参考.
2 数据集与研究方法
2.1 实验数据集
本文手机通话数据由合作单位某运营商提供,为保护用户隐私,用户号码已作匿名化处理.数据分为两部分: 手机通话话单数据,由10 000名用户在2013年6月一个月期间通话产生的话单数据,数据格式如表1所示; 基站小区位置信息数据,14 549个基站小区的GPS坐标、行政划分、道路等信息,数据格式如表2所示.其中手机用户选取条件如下:
1) 用户号码注册于一个匿名的高科技工业区注册;
2) 用户在2013年6月1日~6月30日一个月内的通话总时长大于100分钟.

表1 话单数据格式
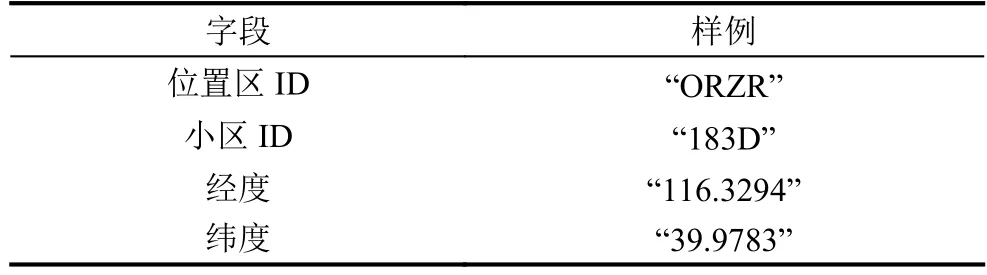
表2 通信小区信息格式
2.2 研究方法
本文同时利用话单数所包含的时空信息和社交信息,从用户日常移动模式和社交生活两个方面来刻画用户特征.在提取特征时,提出衡量用户移动随机程度的移动方向熵特征和衡量用户社交集中程度的社交熵特征.对用户一个月内的特征进行分析,然后使用KMEANS聚类算法[10]用户进行聚类分析,完成用户群体划分.接着时间窗口设为一周,利用每周内特征的均值与均方差,给用户打上标签,完成对用户个性化特征的刻画,构建用户词云名片.
(1) 用户特征定义
为了描述用户的移动模式,本文从移动强度、活动范围、移动随机程度以及出行的随机性等角度提出定义用户移动模式的特征; 从用户社交圈的规模、主动程度、社交上的精力以及会交往集中程度等角度提出定义用户社交生活的特征.
与朋友发生的相互通话是一个人社交生活中的重要表现形式.通过对用户的通话时长、联系人数量、主叫比率和社交熵进行提取,以得到反映用户的社交能力的特征.
定义1.移动距离特征定义为在一定时间内用户移动轨迹的长度,是用户移动强度的体现,公式为:
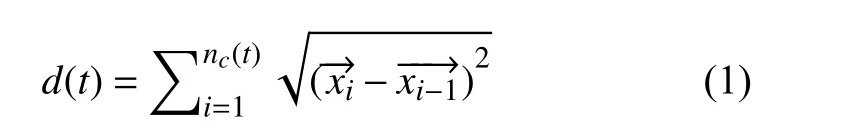
定义2.回旋半径特征定义为在一定时间内用户通话发生时刻所在地点偏离移动轨迹重心距离的标准差,可以表示用户的移动范围,公式为:

定义3.访问点个数特征定义为用户的所有发起通话地点的个数,可以反映用户活动的规律,公式为:

定义4.将以东西方向为横坐标轴,南北方向为纵坐标轴组成的坐标系均分成12个方向区间计算出用户每次出行方向,然后统计用户出行方向位于各方向区间的概率计算其信息熵作为用户的移动方向熵特征,反映用户出行方向的随机性,公式为:
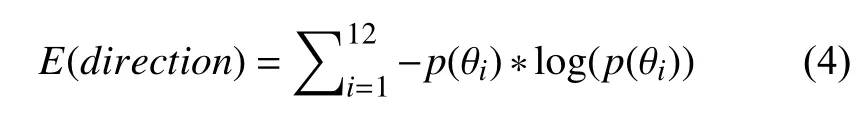
定义5.通话时长特征定义为指用户在一段时间内所有通话时间的总和,可以反映用户在“电话社交”中的活跃程度,公式为:

定义6.联系人数量特征定义为所有和用户发生通话行为的人数总和,可以体现用户社交圈的规模,公式为:

定义7.主叫比率特征定义为在一定时间内用户主叫通话次数与总的通话次数的比率,可以体现用户在社交中的主动程度,公式为:

定义8.在一段时间内用户与n个用户发生总共N次通话,其中与n个用户的通话次数分别为计算熵值作为用户的社交熵特征.社交熵特征可以反映社会交往集中程度,公式为:
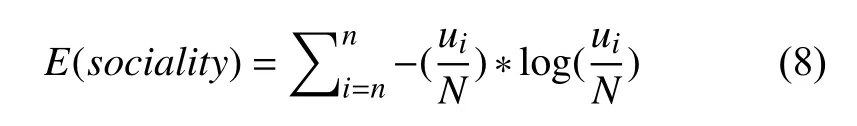
(2) 特征相关性分析
为了从整体上了解用户,将时间窗口T设定为一个月,计算用户在一个月时间内,在移动模式和社交生活两方面的特征向量FT,FT的定义如下:
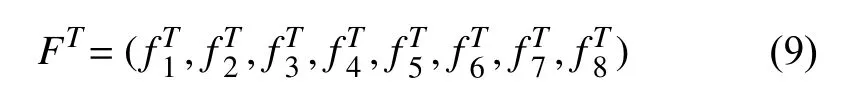
为了进一步了解代表移动模式和社交生活的特征,为了消除特征之间的差异性,对每一维特征进行zscore标准化:

通过计算标准化后特征之间的相关系数,分析本文提取特征之间的相关性.
(3) 用户群体发现
本文选择使用多特征对用户进行聚类,根据话单数据发现移动模式和社交模式类似的用户群体.首先将代表用户将时间窗口T设为一个月,提取用户一个月内的八个特征.考虑到本文提取的八个特征间可能存在一定的相关性并且可能存在冗余和噪声,本文对八个特征进行主成分分析,提取主要特征成分.选择保留90%以上的方差信息,来确定主成分的个数.在此基础上根据提取的主成分使用K-MEANS聚类算法对用户进行聚类,发现用户群体.因为K-MEANS聚类算法是一种简单、快速的算法,并且当处理大数据集时,也可保持伸缩性和高效性,所有选择它作为本文的距离算法.
(4) 用户词云名片生成
词云图一种基于信息文本词频的可视化形式,是对文本信息中出现频率较高的“关键词”予以视觉化的展现.词云图可以将重点内容突出,过滤掉的低频低质的内容,使得浏览者只要一眼扫过便可领略主旨.词云图被广泛的使用在艺术、新闻学、社交网络等不同的领域.生成词云图的方法有很多,如Wordle、WordItOut还有Python库wordcould,本文采用WordItOut工具,为用户生成词云名片.
本文借助词云图方式为用户制作词云名片,使用户特点被清晰地呈现.构建用户词云名片,关键是要找到用户与众不同的特点,利用一定的规则生成用户标签.本文根据用户特征值的均值和均方差,将特征值位处于整体分布两端的用户打上标签,为生成词云名片提供数据.然后将用户的标签数据送入WordItOut工具,为用户生成个性化的词云名片.
3 实验和分析
3.1 数据预处理
由于CDR数据需要关联了小区的位置信息才能用于对用户定位,而二者主要通过位置区ID和小区ID建立起关联.统计发现,数据集中的小区ID已经具有唯一性,故删除了CDR数据中小区ID缺失或未被包含在小区信息数据集里的记录,最终共得到9514位用户的2380 598条话单数据.
3.2 特征提取
将时间窗口T设为一个月,提取用户一个月内的八个特征.用户移动模式特征的概率密度分布如图1所示,用户社交生活特征的概率密度分布如图2所示.移动距离、回旋半径、通话时长和联系人数量特征值主要集中在一定范围内,超过一定值后,概率会迅速下降且出现重尾现象,特征值较大的用户稀疏的存在.主叫比率和社交熵概率密度函数服从正态分布.访问点个数的峰值处于较小数值段,概率密度函数在达到峰值前增长较快,达到峰值后下降比较缓慢.和访问点个数特征的概率密度函数相反,用户的移动方向熵的峰值处于较大的数值段,在达到峰值前增长缓慢,达到峰值后下降很快,说明存在少量出行方向随机性很强的用户.
3.3 特征相关性分析
为了进一步了解代表移动模式和社交生活的特征,计算标准化后特征之间的相关系数,结果如表3所示.由表3可知,特征间存在6对显著相关(0.5
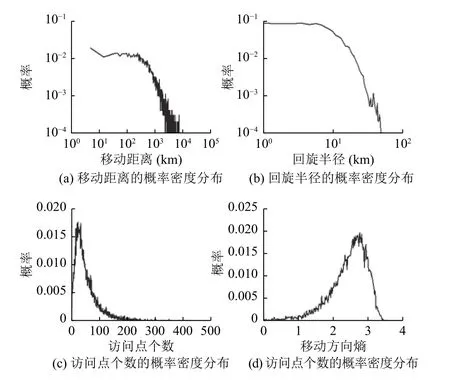
图1 四种移动模式特征的概率密度分布
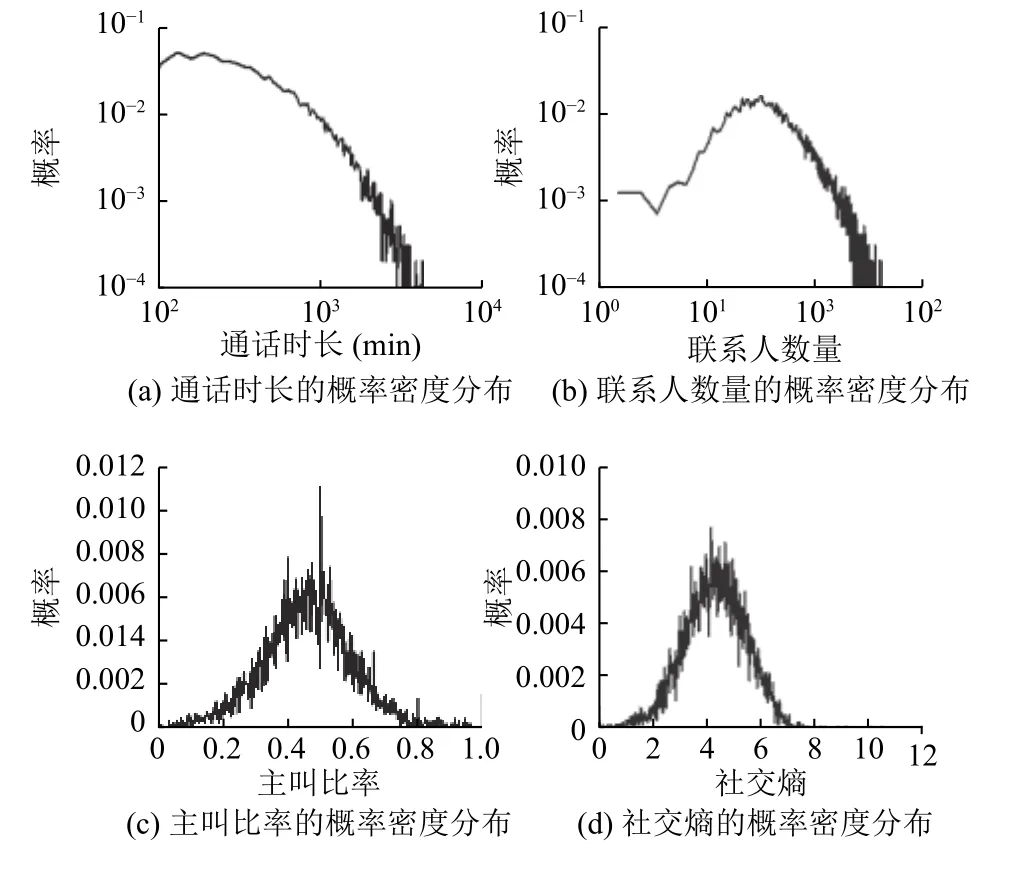
图2 四种社交生活特征的概率密度分布
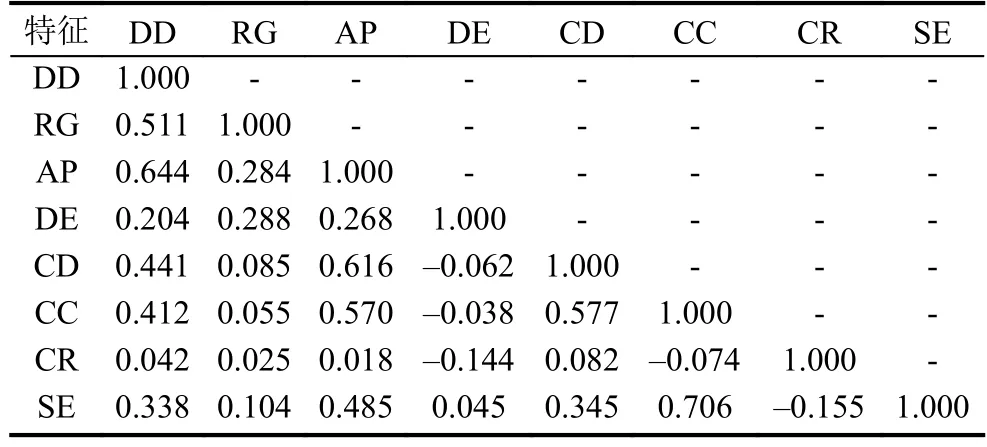
表3 不同特征之间的相关性
(1)移动距离和回旋半径(r=0.551)、移动距离和访问点个数(r=0.644)存在显著的相关性.这个不难理解,用户移动距离越大,可能伴随着活动范围越大、发生通话的地点越多.
(2)访问点个数和通话时长(r=0.616)、访问点个数和联系人数量(r=0.570)存在显著的相关性.因为本实验中的社交信息是由话单数据体现,所以通话时间长、联系人比较多的用户记录的话单数据越详细,导致他们的访问点数目也比较多.
(3)联系人数量和通话时长(r=0.577)、联系人数量和社交熵(r=0.706)存在显著的相关性.用户联系人数量越多,总的通话时长也有很大概率越大,同样由于社交熵的定义,用户的社交熵也很大概率越大.
3.4 用户群体发现
将时间窗口T设为一个月,提取用户一个月内的八个特征.对用户特征值进行主成分分析,选择保留90%以上的方差信息,保留了六个主成分.对保留的特征主成分使用K-MEANS聚类算法对用户进行群体划分,参考轮廓系数,通过测试和调整,最终确定k=4.将每一类的聚类中心点作图如图3(a)所示.为了对聚类结果有清楚的认识,使用每一类用户的原始八个特征对聚类结果进行展示.计算每一类用户的原特征的平均值,将每一类用户的特征平均值作图如图3(b)所示.
从图3(a)中可以看到用户在特征主成分上被很好地分离开了,尤其是在占主导作用的前3个主成分方面.接下来根据图3(b)对用户群体发现结果进行解释说明.
Cluster 1共有4735人,占比为49.8%.这部分用户最多,他们的日常移动模式特征和社交生活特征值均在平均值上下0.5左右,反映了数据集中大部分用户的移动模式和社交生活的特点.
Cluster 2共有2227人,占比为23.4%.他们日常移动模式特征值均是四类用户中最小的,在社交生活特征方面,在通话时长特征与大部分用户相仿的前提下,社交熵特征和联系人数量特征值比大部分用户小,主叫比率特征值却最大,说明这类用户日常移动性较差,社交圈相对集中,并且通话多数都是主动.
Cluster 3共有2119人,占比为22.3%.在日常移动模式特征方面,回旋半径特征和大部分用户相同,访问点个数特征和移动距离特征比大部分用户大,移动方向熵特征却比大部分用户小; 在社交生活特征方面,四种特征值都比大部分用户大.这代表这类用户的活动范围虽然和大部分用户差不多,但但移动距离更大,活动地点更多并且移动更有规律,平时通话时间长,联系人多,社交圈也比较广,与朋友联系一般为主动联系.
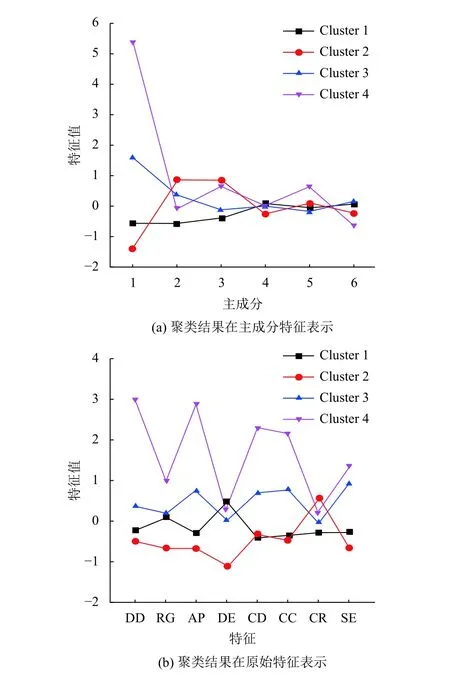
图3 用户聚类结果
Cluster 4共有433人,占比为4.5%.这类用户最少,他们除了移动方向熵特征、主叫比率特征外的其他特征都远大于其他用户,他们活动范围广,移动距离长,访问点多,通话时间长,社交圈也广,是数据集中最活跃的那一部分群体.
3.5 用户词云名片生成
构建用户词云名片的关键是制订规则发现用户与众不同的特点并生成标签数据.本文标签制订规则如表4所示,首先计算每一维特征整体均值mean和均方差std.将特征值fT落在区间外的用户按照表4所示规则添加标签.
人们的工作生活多数以星期作为周期,因此将时间窗口T设为一个星期,这样样可以获得更多的用户标签,以对用户进行更详细的分析.计算用户的特征向量fT,然后根据表4所示规则计算用户标签,最后将每位用户获得的标签分别送入WordItOut工具,就生成了用户的词云名片.
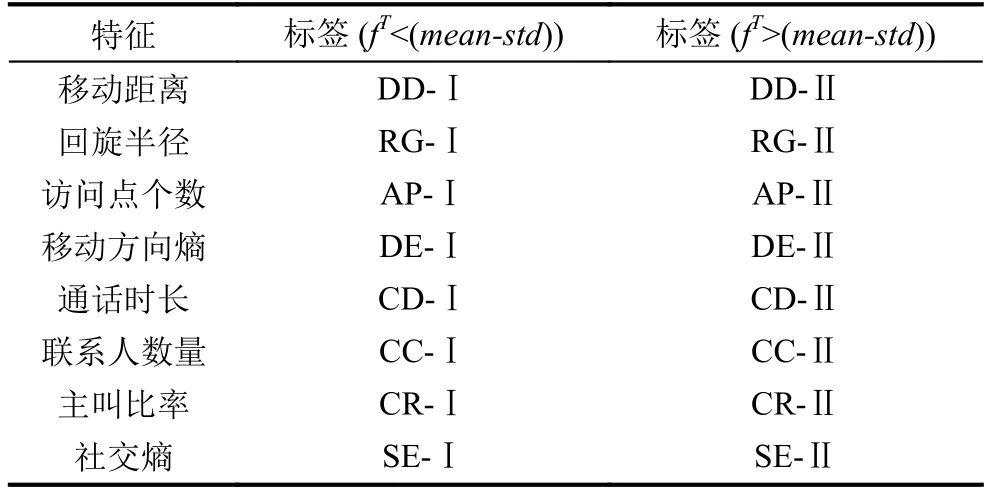
表4 标签制订规则
取实验中两名用户的用户词云名片展示如图4,可以发现用户1的词云名片中DD-Ⅱ、AP-Ⅱ、CD-Ⅱ和CC-Ⅱ比较突出,它们表示用户1的移动距离特征、访问点个数特征、通话时长特征和联系人数量特征位于区间中,其它特征处于正常水平.这表明用户1移动距离大,访问地点多,同时通话时间长,联系人比较多.基于此可以推测用户1可能是在较大城市区域内从事联系交流工作的室外工作者;而用户2的词云名片中DE-Ⅰ、CR-Ⅱ和AP-Ⅰ比较突出,它们表示用户2的移动方向熵特征和访问点个数特征位于区间中,主叫比率特征位于区间中,其它特征处于正常水平.这表明用户2活动地点少且移动具有规律性,通话多为主叫,基于此用户2可能是喜欢宅在某些地点,用电话处理日常生活的人.

图4 用户词云名片
4 总结
本文利用用户话单数据提取出多个反映用户时空信息和社交信息的特征,在真实的数据上通过对特征的综合分析,完成了对移动通信用户的画像研究.基于用户的多方面特征,发现了四类移动模式和社交生活相似性的用户群体,创建了用户词云名片的使得用户个体的特点可以被清晰地呈现.以本文研究为基础,移动通信运营商可以针对用户特点制订相应的套餐并向用户推荐,其他利益相关企业可以针对用户特点推荐相关的商品,实现精准营销; 在城市治理方面,可以通过对用户的移动性和行为模式的分析,识别非法营运车辆的从业人员.
由于话单数据是由通话事件触发采样的,因此用户移动行为、社交行为只有在通话行为发生的情况下才能被记录,所以本文结果具有一定的局限性.受实验话单数据获取途径的限制,不能在更大数据集下对本文提出的方法和分析结果进行进一步地研究.今后的工作将主要从两个方向进行展开: 第一,挖掘话单数据中隐含更多的特征,从多角度对用户间的差异性进行表达; 第二,获得信息更加丰富的实验数据,增加数据种类,通过多种数据对比、融合来刻画用户画像.
猜你喜欢
好日子(2022年6期)2022-08-17
保健医苑(2022年5期)2022-06-10
今日农业(2021年5期)2021-11-27
奥秘(2021年6期)2021-09-10
大飞机(2021年4期)2021-07-19
现代交际(2019年15期)2019-10-21
中华诗词(2018年5期)2018-11-22
中外文摘(2017年17期)2017-10-10
家人(2016年11期)2016-12-01
中外会展(2009年9期)2009-11-02
