
基于卷积神经网络的图像验证码识别①
2018-11-14 11:36顾乃杰张孝慈林传文
计算机系统应用 2018年11期
秦 波,顾乃杰,张孝慈,林传文
(中国科学技术大学 计算机科学与技术学院 网络计算与高效算法实验室,合肥 230027)
(安徽省计算与通信软件重点实验室,合肥 230027)
(中国科学技术大学 先进技术研究院,合肥 230027)
1 引言
验证码(Completely Automated Public Turing test to tell Computers and Humans Apart,CAPTCHA)是一种用于区分人类行为与机器行为的算法.作为互联网行业通用的基础安全策略,验证码担负着保护网络账号安全体系的第一道防御,用以验证和防范机器程序的恶意行为,如何提升验证码的安全性并防止自动破解程序,已经成为一个至关重要的问题.
作为深度神经网络的一种,卷积神经网络(Convolutionional Neural Networks,CNN)在图像识别领域内表现出优异的性能[1],且大大优于传统的机器学习方法.较传统方法而言,CNN的主要优势在于卷积层提取的图像特征具有很强的表达能力,避免了传统识别技术存在的数据预处理、人工设计特征等问题.在具备足够的标注样本的情况下,只需要定义一个合适的网络模型,就能够取得远高于传统方法所取得的识别效果.
本文设计了一种基于卷积神经网络的图像验证码识别方法,对传统的卷积神经网络训练中存在的模型复杂、输出层参数冗余等问题进行了改进.本文通过卷积层级联、残差学习、全局池化和分组卷积等技术手段,在保证网络识别精度的前提下,压缩了模型规模.
2 相关工作
鉴于验证码在互联网的广泛应用,国内外学者对验证码的设计和识别进行了广泛的研究.Zhang和Wang[2]利用传统图像处理方法并结合KNN算法进行验证码识别研究.李兴国等人[3]提出一种滴水算法分割验证码.Lu等人[4]分别提出了不同的字符分割算法并结合SVM分类算法及BP神经网络进行字符识别.Yan等人[5]分析并研究了现有微软验证码的缺陷,并设计了虚拟问答及基于情感方法对验证码进行识别.Mori和Malik[6]利用形状上下文方法对验证码进行了识别研究.
深度神经网络在科学研究中被广泛使用,Yann LeCun等人[7]提出了基于CNN的文字识别系统LeNet-5.Hinton等人[8]提出的深度置信网络(Deep Belief Network,DBN)可以更快地训练深度网络.在图像应用中,CNN采用随机梯度下降(Stochastic Gradient Decent,SGD)和GPU (Graphics Processing Unit)加快了深度网络的训练速率.IDSIA实验室[9]针对手写中文汉字识别提出一种多列CNN模型,通过训练多个CNN网络并对结果进行简单的平均集成实现并行训练.Zhong等人[10]提出一种HCCR-GoogLeNet模型,利用GoogLeNet的网络结构并引入手写汉字的多尺度多方向特征,完成脱机手写中文汉字识别.范望等人[11]构造出卷积神经网络用于汉字验证码识别.针对不分割的验证码识别,Google研究人员[12]采用概率模型和卷积神经网络开发了一种无需字符分割的街道门牌识别系统,对门牌准确率高达90%.Yann LeCun等人[13]采用空间位移神经网络(SDNN)和隐马尔科夫模型(HMM)对带有粘连的手写字符进行识别.Shi等人[14]利用CNN和R N N结合思想,提出一种卷积循环神经网络(CRNN)完成验证码的整体识别.
3 网络模型设计
本文提出的卷积神经网络模型主要由以下模块组成: 级联卷积层、残差层以及分类池化层,如图1所示,下面对这些结构进行具体介绍.

图1 本文网络结构
3.1 级联卷积层

图2 级联卷积层
(1) 参数量
假设图2中所有数据有C个通道,下面将比较3个 3 ×3卷积核和1个卷积核的参数量.
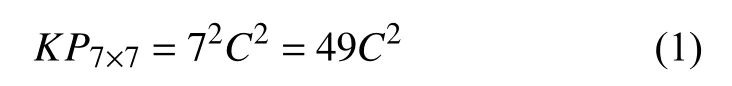
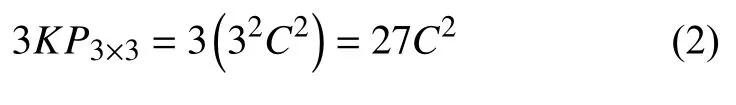
由公式(1)和(2)可知,两者的参数量倍数为:

(2) 感受野
感受野(Receptive Field)计算方法如下:
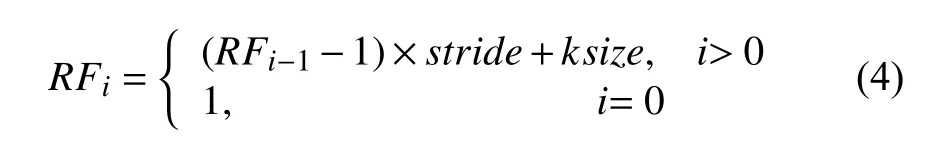
3.2 残差层
随着网络深度的增加,网络出现无法收敛、性能退化等问题[16].主要原因在于经典卷积神经网络参数梯度值等于所有前层参数梯度的乘积,当浅层的参数梯度值过小就容易产生梯度消失的问题,从而影响到网络的表现性能.研究显示,残差结构[17]不仅能够解决网络深度深而性能退化的问题,而且也解决了梯度消失的问题.
下面将对残差层进行分析.为了不失一般性,从第l层到第L层的前向过程可表示为:
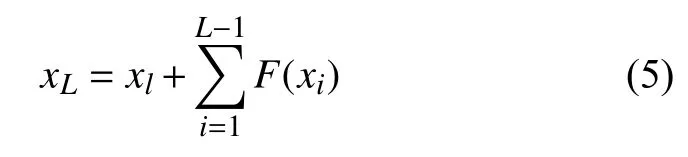

可以看出,网络参数学习过程实际上等价于对前面层的参数梯度的求和过程,即从是线性叠加的过程,因而允许网络深度增加,而不会出现梯度消失的问题.
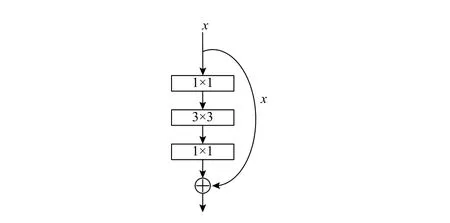
图3 残差模块
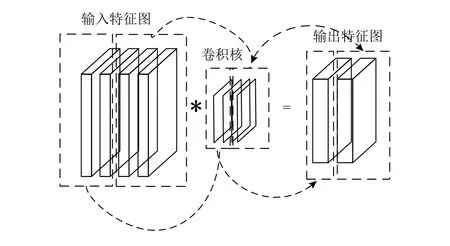
图4 卷积分组
假如输入特征图个数为N,该层的卷积核(kernel)个数为M,计算下一层特征图是利用M个kernel和N个输入特征图.引入group后,计算下一层特征图则利用M/group个kernel和N/group个输入特征图.
3.3 分类池化层
传统的卷积神经网络中,卷积层和池化层等用于特征提取,随后利用一到多个全连接层将学习到的特征空间隐式地映射到样本标记空间,最后在输出层由softmax激活函数完成目标分类任务.全连接层的弊端在于参数过多,容易出现过拟合等情况.本文使用分类池化层来替代全连接层[18](图5).这里分类池化层实际上是全局平均池化层(图6),其没有需要优化的参数,从而可以避免出现过拟合情况.同时其对空间信息求和,因而对空间变换更加健壮.
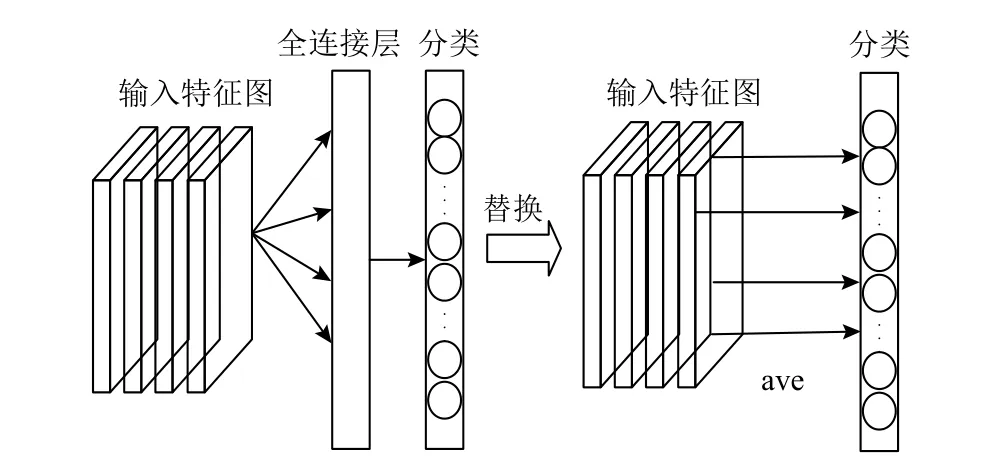
图5 分类池化层
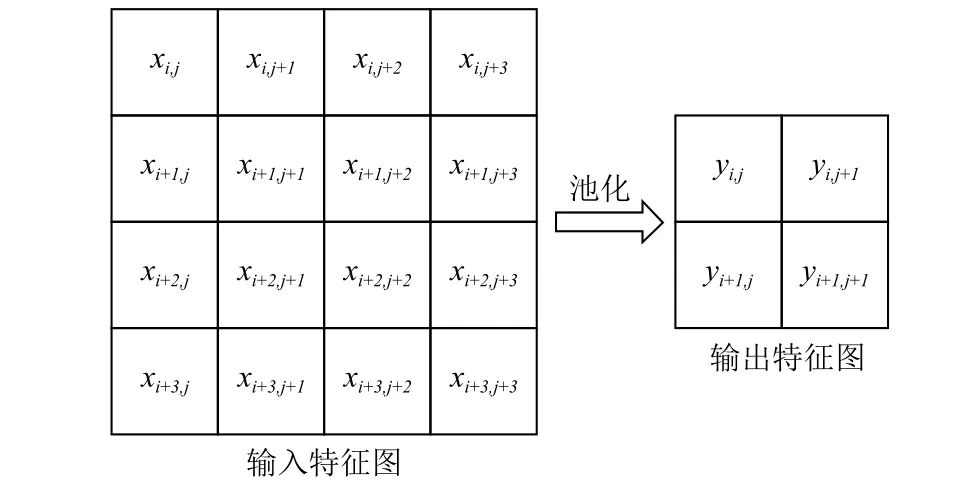
图6 全局平均池化层
图6显示是全局平均池化层,输出特征图的计算方法如下:

3.4 网络结构
本文结构的具体网络参数见表1.其中Conv1_x和Pool1是级联卷积层,Conv2_x至Conv5_x是残差层,Pool2是分类池化层.
4 实验与分析
4.1 平台介绍
本文在深度学习框架Caffe的基础上,实现了基于卷积神经网络的图像验证码识别方法.
实验平台使用Intel XeonE5-2620 v2 2.1 GHZ CPU,126 GB 内存,以及 NVIDIA Tesla K40m GPU.其中Tesla K40m GPU单精度峰值4.29 Tflops,显存为12 GB GDDR5,显存带宽为288 Gbytes/sec.
4.2 数据集介绍
本文实验数据以铁路购票网站验证码和正方教务系统验证码为例.
(1) 购票网站验证码
购票网站验证码共收集109 900张,包含图形302类,训练图片数112 599张; 包含中文词组302类,训练图片数39 931张.对于验证码识别之前,首先需要对验证码进行预处理操作,分割成单独子图和中文汉字或词组.具体购票网站验证码如图7所示.
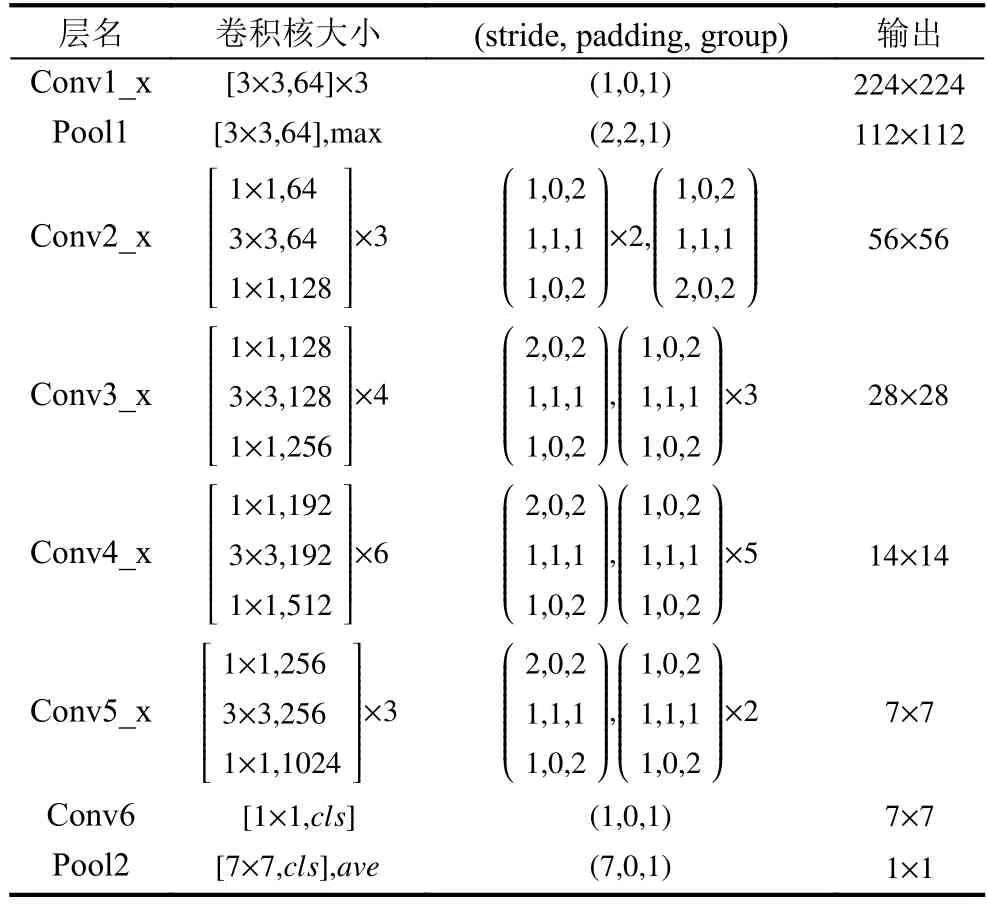
表1 网络参数

图7 购票网站验证码
(2) 正方教务系统验证码
正方教务系统验证码由字母和数字构成,共包含33类,训练验证码数5950张.对于验证码识别之前,需要对验证码进行预处理,包含去噪以及分割等步骤.该验证码如图8所示.

图8 正方教务系统验证码
4.3 铁路购票验证码实验
铁路购票网站验证码包含图形验证码和中文验证码.
(1) 图形验证码
对于图形分割部分,由于验证码中八张子图尺寸与位置均固定,故考虑直接设置分割点实现分割.同时,对于图片数较少的类别,采取数据增强方式来扩充训练数据集,主要包括图像缩放、旋转和颜色变换等.
对于图形识别部分,图形验证码共302类,训练集图片82 599张,测试集图片30 000张.实验参数如下:训练mini-batch大小设置为32,训练最大迭代为250 000次.训练过程中前100 000次迭代的学习率为0.01,后面每隔40 000次学习率衰减1/10,梯度更新方法为Momentum,值设置为0.9.本文测试传统卷积神经网络模型,包含AlexNet[1],GoogLeNet[19]以及ResNet50[17],并与本文方法进行比较,实验结果如表2.
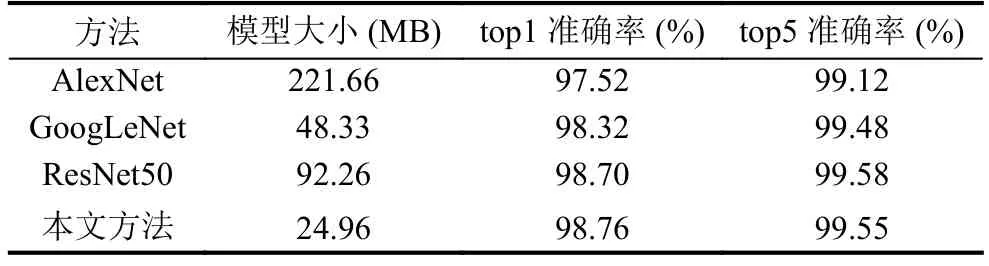
表2 模型在图形验证码上的准确率和模型大小
(2) 中文验证码
对于字符分割部分,本文利用垂直投影算法分割出单个词组,而并非是中文字符.该方法好处是尽可能避免切分单字带来的误差.下面是中文词组分割的算法.
算法1 基于中文词组分割算法
1) 从验证码中截取出中文汉字部分ChiWords;
2) 对ChiWords进行灰度化、二值化处理,得到BChiWords;
3) 从BChiWords中依次统计出每列黑色像素点个数BNP;
4) 设置阈值T1,T2.如果BNP小于阈值T1,则说明此位置有可能是分割点,记连续分割点的起止位置s和t.如果时,保存s和t.
5) 根据结果切分中文词组,并获取下一张验证码,返回第1)步.
6) 直至终止条件满足,结束.
对于字符识别部分,中文验证码包含中文词组302类,训练集图片数27 982张,测试集图片11 949张.基于字符分割识别实验,本文利用开源Tesseract软件实验和基于AlexNet模型的中文识别实验,实验记为SplitAlexNet; 基于词组分割识别实验,主要考虑AlexNet,GoogLeNet,ResNet50和本文方法.实验结果见表3.

表3 模型在中文验证码上的准确率和模型大小
(3) 整体验证码
实验数据为购票网站验证码,测试验证码988张,与上述实验使用的数据集不同.
整体验证码识别过程: 首先对验证码预处理,然后对中文词组和子图识别.中文词组识别结果与词组标注结果进行比对,如果词组识别无误,将符合词组的子图识别结果下标与标签文件进行比较(图9).实验结果见表4.

图9 整体识别过程

表4 模型在整体验证码上的准确率和模型大小
从表2可知,本文方法参数量最少,大小为24.96 MB.且在测试集的top1准确率最高,比AlexNet,GoogLeNet,ResNet50分别高1.24%,0.44%,0.06%.
表3的结果显示,基于字符分割识别的方法,词组识别准确率较低,其中较好的模型是SplitAlexNet,其top1准确率达到75.20%; 基于中文词组识别的方法,本文方法准确率达到99.14%,高于传统的AlexNet,GoogLeNet,ResNet50神经网络模型准确率.与此同时本文方法参数量最少,分别比传统神经网络参数量降低9.40倍,23.25倍,1.26倍和3.32倍.
从表4可知,本文提出的整体验证码识别准确率要比其它网络模型高,且模型更小.
4.4 正方教务系统验证码实验
该验证码训练集图片4630张,测试集图片1320张.本文测试传统的卷积神经网络模型,包含AlexNet,GoogLeNet,ResNet50,并与本文方法进行对比.
实验参数如下: 训练mini-batch大小设置为32,训练最大迭代30 000次.训练过程中前8 000次学习率为0.001,后面每隔6 000次学习率衰减1/10,梯度更新方法为Momentum,值设置为0.9.
通过表5和表6可知,准确率方面,本文方法的准确率不低于传统神经网络模型; 模型大小方面,本文方法参数量比AlexNet,GoogLeNet和ResNet50要少.
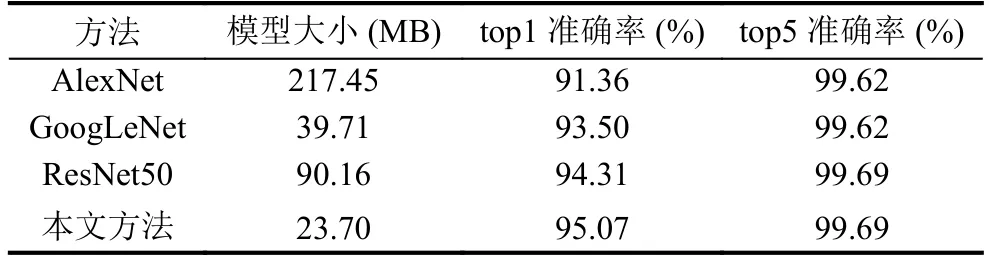
表5 模型在字符上的准确率及模型大小

表6 模型在正方验证码上的准确率及模型大小
4.5 实验分析
本文重点考虑在不影响模型准确率的前提下,进一步减少模型的参数量,即模型规模.通过上述实验可以看到,本文网络结构是基准模型中参数量最少的,同时验证码的识别效果比其它网络要好.接下来将具体分析原因.
一是模型参数量缩减方面.本文利用级联卷积层减少了网络参数,增加了网络的非线性.同时在残差层调整卷积分组个数,利用全连接层替换.这几个方面的改进能够很明显地看出网络规模变小.
本文调整卷积分组的个数,一方面使得卷积层计算加快,模型参数量减少,同时也影响识别的准确率,下面将实验说明卷积分组对网络结构准确率的影响.
(1) 卷积分组实验
卷积分组不仅能够降低网络的规模,同时卷积分组个数也影响着网络的识别率.本文将对分组个数进行实验,考虑在不同的分组下,本文方法的准确率变化情况.
为了说明卷积分组对实验准确率的影响,将在图形验证码和中文验证码上进行实验分析.通过表7和表8容易看出,对于不同数据集最优的group选择也不同.

表7 卷积分组对图形验证码准确率影响

表8 卷积分组对中文验证码准确率影响
(2) 特征图可视化
通过特征图可视化能够更好地理解网络的特征学习过程,下图是利用本文方法识别的最后层可视化结果.
图10显示的是本文方法在最后层特征图的激活程度.可以看出无论是中文词组还是图形验证码,相同类别的图片在最后层的激活程度相似,而不同类别之间的激活程度却迥然不同.

图10 最后层特征图可视化结果
5 总结
本文利用卷积层级联、残差学习、全局池化、卷积分组等方法,提出了一种基于卷积神经网络的验证码识别方法.实验表明该方法较传统网络模型具有参数量少的特点,而且有着更高的识别准确率.此外,本文还讨论了卷积分组对准确率的影响,并通过实验选出性能最优的卷积分组.接下来的工作将继续优化网络模型结构,同时也将根据本文的实验结果分析如何提升验证码的安全性.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
小学生导刊(低年级)(2017年1期)2017-06-12
高中生学习·高三版(2014年3期)2014-04-29
