
高效Prewitt边缘检测算法的NEON实现
2018-11-14 10:27:44王誉博
小型微型计算机系统 2018年11期
王 誉 博
(浙江大学 超大规模集成电路设计研究所,杭州 310027)
1 引 言
边缘检测能够在保留图像重要结构的基础上极大地减少图像的数据量[1],被广泛使用于轮廓检测,模式识别[2],区域分割[3],图像增强[3]等应用场景中.由于边缘检测的运算数据量极大,必须采取相应的方案进行改进与加速.近些年来,相关领域的专家学者都围绕加快边缘检测开展了大量的工作.在有一个CPU(Intel Core2 CPU 6600 @ 2.40 GHz,2 GB RAM)和GPU(NVIDIA GeForce 8800 GTX,768 MB global memory(not overclocked))的平台上,Luo等人用利用Opencv对分辨率为512x512的图像进行边缘检测处理,花费的时间达8.28ms[4].Ogawa等人搭建了一个拥有CPU(Intel Xeon E5540,频率2.0GHz,内存6GB)和GPU(Tesla C1060,240个核心,频率1.3GHz)的平台,利用该平台对一张分辨率为10240x10240的图片进行边缘检测处理需要444.29ms[5].通过利用CPU+GPU的平台可以有效对图像进行实时边缘处理.而随着嵌入式系统的高速发展,在边缘检测方面,如何使嵌入式系统拥有与CPU+GPU平台相当的运算能力成为了极大的挑战.基于此,本文在利用Prewitt算子来实现边缘检测的基础上,提出了一种基于NEON协处理器的边缘检测算法.通过实验证明,在Xilinx的Zedboard平台上,本算法在仅利用ARM CortexTM-A9中的一个核心(频率666MHz)的情况下就取得了和CPU+GPU平台相当的运算速度.
2 系统结构
本系统是基于Xilinx公司的Zedboard开发板完成.Zedboard上集成了一颗双核心的ARM CortexTM-A9处理器(包含NEON协处理器),512MB的DDR3和可编程门阵列等.
系统的整体结构如图1所示,主要包括:IMX219摄像头模块、MIPI信号处理模块、ARM A9软件处理模块、HDMI发射器以及DELL显示器.A9处理器通过I2C协议配置IMX219摄像头模块,使之输出图像数据.MIPI信号处理模块获取IMX219输出的MIPI信号,并将获取到的RAW8格式的图像数据转换成RGB格式的数据并通过AXI协议将图像信息存入到DDR3中.A9处理器从DDR3中获取图像信息并执行Prewitt运算,在完成运算之后将数据回写至DDR3中.A9是一颗双核心的CPU,本文仅使用了其中的一个核心.

图1 系统框图
HDMI发射器通过AXI协议获取DDR3中经过A9处理后的图像信息,并将之转换成TMDS信号发送给DELL显示器.最后能够在DELL显示器上看到相应的图像.
3 NEON协处理器简介
NEON技术是ARM Cortex-A系列处理器的128位SIMD(Single Instruction Multiple Data,单指令多数据)架构扩展,相比于SISD(Single Instruction Single Data,单指令单数据)架构,SIMD的一条指令就可以同时完成多个相同的运算,从而极大地提高运算效率.
NEON协处理器支持的数据类型包括32-bit单精度浮点数,8、16、32和64-bit无符号/有符号整形.NEON协处理器拥有的寄存器有三类:32个单字寄存器(s0-s31)、32个双字寄存器(d0-d31)和16个四字寄存器(q0-q15),这些寄存器并不是完全独立的,具体的映射关系如图2所示.以q0为例,q0可以拆分成d0和d1,d0则可以拆分成s0和s1.
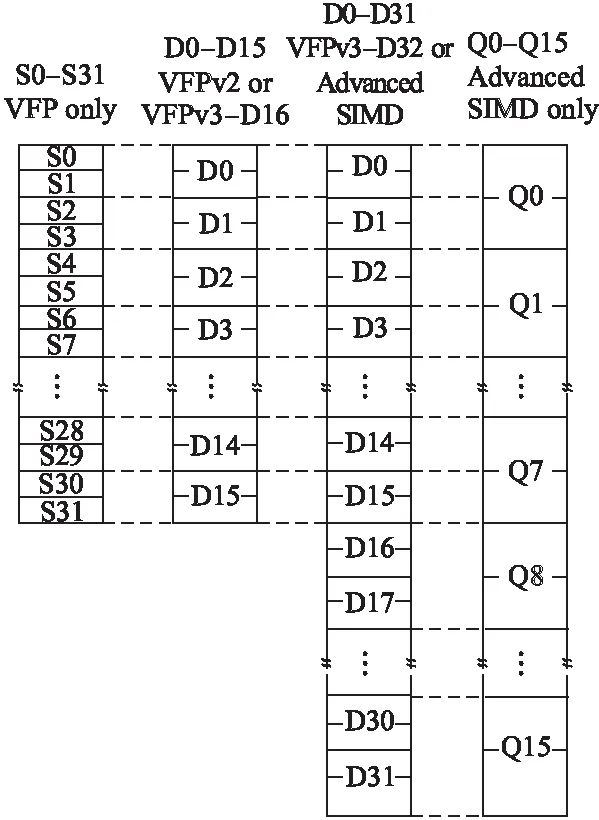
图2 NEON寄存器组*http://infocenter.arm.com/help/topic/com.arm.doc.dht0002a/DHT0002A_introducing_neon.pdf
3 Prewitt算法
3.1 Prewitt算法原理
图像中物体边界处的灰度变化往往十分剧烈,边缘检测的任务就是找到图像上灰度变化剧烈的点.经典的边缘检测算法有很多,如:Reberts算子,Prewitt算子,Sobel算子,Laplacian算子,Canny算子等.本文采用Prewitt算法来完成边缘检测的工作.
Prewitt算法借助式(1)X方向的Prewitt算子和式(2)Y方向的Prewitt算子来完成计算.对于单个像素点而言,在计算时需要获取该像素点周围八个点的灰度值,再结合式(1)和式(2)即可算出X方向和Y方向的梯度值,式(3)和式(4)即为计算公式.最后用式(5)即可以计算出该像素点的最终梯度值.
(1)
(2)
Dx(i,j)= (G(i-1,j+1)+G(i,j+1)+G(i+1,j+1))-
(G(i-1,j-1)+G(i,j-1)+G(i+1,j-1))
(3)
Dy(i,j)= (G(i-1,j-1)+G(i-1,j)+G(i-1,j+1))-
(G(i+1,j-1)+G(i+,j)+G(i+1,j+1))
(4)
(5)
通过分析常规Prewitt算法的计算过程,制约Prewitt算法运算速度的主要瓶颈有以下两点:
1)为了计算一个点X方向与Y方向的梯度值,需要额外读取该像素点周围八个点的像素值,并且需要计算这八个点的灰度值.在这一过程中存在数据的重复读取和冗余计算.
以图3为例,在计算点(2,2)和点(2,3)的Prewitt算子结果时都需要读取点(1,2)、(1,3)、(3,2)、(3,3)的像素值并且计算这些点的灰度值.

图3 部分图像数据
2)Prewitt算子的计算过程中也存在一定程度的冗余计算.以图3为例,当计算点(2,2)的梯度值时,需要计算点(3,2)与点(3,3)的灰度和,而在计算点(2,3)的梯度值时同样需要计算点(3,2)与点(3,3)的灰度和.同样的道理,在计算点(2,2)和点(3,2)的梯度值时,都需要计算一次点(2,1)和点(3,1)的灰度和.
3.2 改进的Prewitt算法
为解决上一小节中提出的两点缺陷,本文提出一种高效的Prewitt边缘检测算法.传统的Prewitt算法以像素点为计算单位,本文算法以像素块为单位进行Prewitt计算.这样可以大幅度减少冗余的计算和冗余的数据读取.考虑到CPU和NEON协处理器的资源数量,本文以4x6个像素点作为一个像素块进行Prewitt算子计算,以下为本文算法的计算流程:
1)灰度计算.首先从内存中获取6x8个像素点的RGB数据,并用式(6)完成灰度值的计算,并将结果存放在NEON寄存器q7到q12中.图4中(1,1)等点即代表一个像素点的灰度值.
G=(R×38+G×75+B×15)/128
(6)
2)X方向一阶梯度计算.图4给出了计算X方向梯度的计算流程,总共分为三个步骤:
①加法计算.计算q7+q8+q9,并将结果存放在q3中,同理可得q4、q5和q6.以图4中一个值[3,1]为例,其值为步骤1中(2,1),(3,1),(4,1)的和.
②转置操作.改变q3到q6这四个寄存器中值所处的位置,为之后的减法运算提供支持.此步骤不改变寄存器中值的大小,只改变这些值存储的位置.
③减法运算.计算减法过程,并将运算结果存储在寄存器d0到d5中.以图4中一个值{2,2}为例,其值是[2,3]与[2,1]的差.其余点的计算方式也是如此.
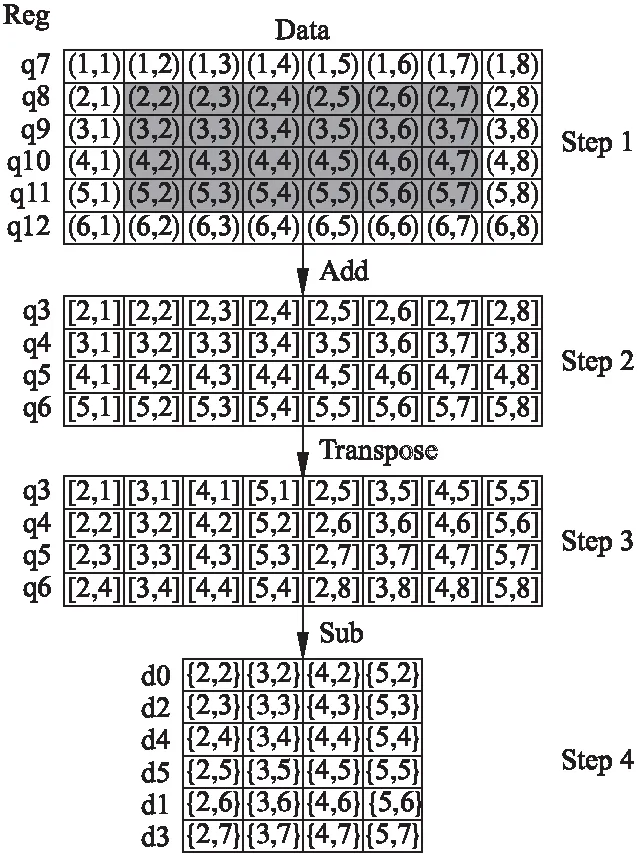
图4 X方向梯度计算流程
3)Y方向的一阶梯度计算.Y方向一阶梯度计算过程和X方向的计算过程大体一致,先是做减法运算,然后做转置操作,最后做加法运算.
4)开方运算.首先用式(7)计算出X方向梯度与Y方向梯度的平方和,然后用式(8)来完成开方这一过程,从而最终获得Prewitt运算结果.
(7)
(8)
表1给出了本文算法和原始算法之间运算量的对比.根据表1计算可得,原始算法每次只能计算1个像素点的Prewitt值,完成该过程需要读取8个像素点的数据,同时需要执行27次加减法,26次乘法,1次开方运算.采用本文算法则可以一次性计算出24个像素点的Prewitt值,完成该过程需要读取48个像素点的数据,执行38次加减法,30次乘法,6次开方运算.因此对于平均每个像素点而言,采用本文算法后数据读取量为原始算法的25%,加减法数为原始算法的5.9%,乘法数量为原始算法的4.8%,开方数量为原始算法的25%.以上数据表明采用本文算法之后能够大幅度减少运算量以及数据读取量.
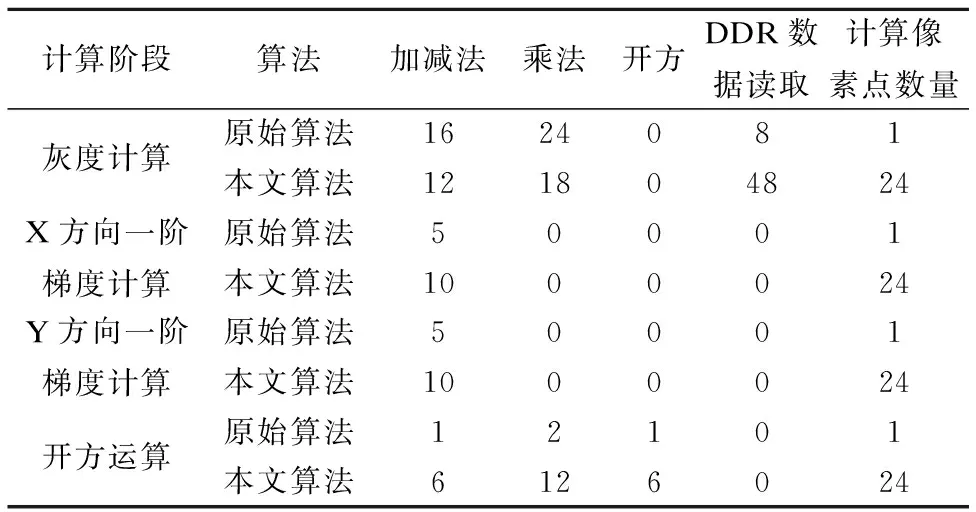
表1 运算量对比
4 实验结果与分析
本文以Xilinx公司生产的Zedboard开发板为设计平台,采用Vivado设计套件(版本2016.2)完成相关IP的设计和软件代码的编写,最终完成了平台的设计与搭建.在完成综合之后,从表2中可以看到各个资源的使用情况,其中LUT(Look-Up-Table,显示查找表)占用了3.59%,LUTRAM(由LUT构建的分布式RAM)占用0.97%,FF(Flip Flop,触发器)占用了2.02%,BRAM(块RAM,容量比LUTRAM大)占用了1.43%,IO(输入输出,用于与外部外设通信)占用了16%,BUFG(用于管理时钟,确保时钟到达各个单元的延迟和抖动最小)占用了3.13%.

表2 片上资源占用情况
搭建完整个系统并且运行相应代码之后,在显示器上即可显示经过边缘检测之后的图像.图5(a)为摄像头获取的原始图像,图5(b)为原始Prewitt算法计算后得到的图像,图5(c)为经过本文边缘检测算法计算后得到的图像.可以表明利用本文算法获取的边缘检测结果和用原始算法计算得到的结果完全一致.此外,为了验证本文边缘检测的质量,本文将数据源从摄像头换为普通的图像(图5(d)所示),从而得到通过本文边缘检测算法计算后的图像(图5(f)所示).同时利用MATLAB对图5(d)进行边缘检测,得到图5(e).通过对比图5(e)和图5(f)的细节部分,可以表明利用本文算法计算得到的边缘检测结果的质量和MATLAB计算得到的结果一致.

图5 实验结果
为验证本文提出的算法的计算效率,本文对不同分辨率的视频进行实时边缘检测.表3表明,采用NEON协处理器后可以有效提高运算速度,而采用本文算法之后可以进一步提高运算速度.
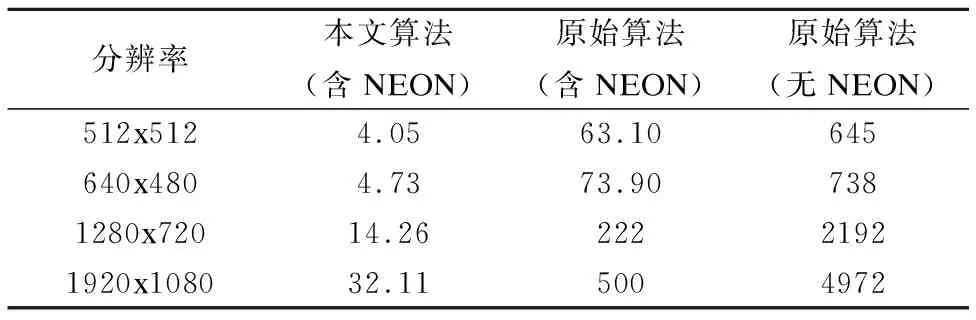
表3 运行时间比较(ms)
为进一步验证本文提出的算法与CPU+GPU运行平台之间的差距,本文在表4中列出了一些CPU+GPU平台进行边缘检测的时间.通过对比表3和表4的数据可以表明,通过本文算法可以使得嵌入式平台取得和CPU+GPU平台相当的运算速度.

表4 CPU+GPU平台下的运行时间(ms)
5 结 论
本文提出了一种基于NEON协处理器的高效Prewitt边缘检测算法.在经过合理的算法设计和优化之后,本文大幅度提高了嵌入式系统计算Prewitt的计算效率,使得嵌入式平台也能够实时进行图像的边缘检测.在与其他主频更高、功耗更高的CPU+GPU平台比较之后可以表明,通过本文算法可以使得嵌入式平台取得和CPU+GPU平台相当的运算速度.
猜你喜欢
数学物理学报(2021年2期)2021-06-09 08:54:26
应用数学(2020年2期)2020-06-24 06:02:44
计算机应用(2020年5期)2020-06-07 07:06:44
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54
电脑知识与技术(2018年35期)2018-02-27 13:29:44
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
自动化学报(2017年11期)2017-04-04 02:52:44
数学物理学报(2016年3期)2016-12-01 05:36:27
电视技术(2014年11期)2014-12-02 02:43:28
网络安全与数据管理(2011年24期)2011-08-08 02:31:52
