
基于深度学习的物体检测
2018-11-08 02:32张开昕
电子制作 2018年20期
张开昕
(郑州外国语新枫杨学校,河南郑州,450000)
1 概述
■1.1 研究背景与意义
计算机视觉技术在不断地发展与进步,人们希望计算机可以代替人类又快又准地完成一件又一件的工作,深度学习便成了计算机视觉领域越来越火热和成熟的部分之一。欲使计算机可以同人一样能够用视觉获取各种图像信息并理解,硬件上用了各种传感器。而我们希望研究计算机视觉技术最终使其能够分析并处理图像以适应各种环境。那么,在计算机读到图像或视频之后,对目标进行检测便成了接下来的重中之重。
人们希望深度学习能够在某些方面有突破,于是就出现了Google旗下人工智能程序“AlphaGo”,它在2016年3月成功击败了韩国围棋职业九段选手李世石,并取得了4∶1的好成绩。人们希望深度学习能够帮助警察排查路口,于是智能检测违反交通规则并记录车牌号码的系统与智能识别犯罪嫌疑人并联网报警的系统便应运而生。但是这些程序所依附的硬件不便移动,我们还在追求硬件与软件结合的手边运行系统。虽然如此,目标检测研究很多,应用效果突出,但大多实际应用的要求高,实时性差。
■1.2 研究现状
LBP在1994年被T.Ojala和M.Pietikäinen两人提出。LBP具有旋转不变性和灰度不变性等优点提取的是图像的局部纹理特征。用LBP可以区分纹理、人脑特征提取等。原理是根据像素周边8个临近像素的灰度值,和中心灰度值比较,得到八位编码即大于为1小于为0,然后根据这样的编码的特征统计直方图作为输入图片的特征做分类。AlexNet是具有历史意义的一个网络结构,在之前,深度学习已经沉寂了很久。在2012年AlexNet 在ImageNet图像分类竞赛中,top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。R-CNN是将CNN(卷积神经网络)应用到目标检测领域的一个里程碑,由年轻有为的Ross Girshick提出,借助CNN良好的特征提取和分类性能,通过候选区域提取方法实现目标检测问题的转化。但R-CNN占用空间大,容易造成图片中的信息丢失,同时会造成一些计算浪费。Fast R-CNN主要贡献在于对R-CNN进行加速,主要是将深度网络和后面的SVM(支持向量机)分类两个阶段整合到一起,使用一个新的网络直接做分类和回归。它是使用选择性搜索算法,找出所有的候选框,这个也非常耗时。 Faster R-CNN加入了一个提取边缘的神经网络,将RPN(候选区域提取网络)放在最后一个卷积层的后面,RPN直接训练得到候选区域。总的来说,从R-CNN,Fast R-CNN, Faster R-CNN发展来,基于深度学习目标检测的流程变得越来越精简,精度越来越高,速度也越来越快。可以说基于候选区域的R-CNN系列目标检测方法是当前目标检测技术领域最主要的一个分支。Yolo算法采用一个单独的CNN模型实现end-to-end(端到端)的目标检测,首先将输入图片调整到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快。Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。Yolo算法可以在较高的mAP(平均准确率)上达到较快的检测速度,但是相比Faster R-CNN,Yolo的mAP稍低,但是速度更快。所以。Yolo算法算是在速度与准确度上做了折中。Yolo的泛化能力强,在做迁移时,模型鲁棒性高。但Yolo各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,Yolo的表现会不如人意。Yolo对于在物体的宽高比方面泛化率低,就是无法定位不寻常比例的物体。当然Yolo的定位不准确也是很大的问题。
2 目标检测
本文使用自己构建的数据集,主要包括在北京五环路上采集的10000张图片作为训练集,3000张图片作为测试集。
目标检测的一般过程:首先获得需要训练以及测试的数据集,一般以6∶2∶2的比例将所有的数据划分为训练集,验证集以及测试集,接下来对数据做预处理,比如将数据的类别做成网络想要的格式,对于某些任务需要将图像归一化到同一个尺寸。第三步需要对数据做增强,主要方法包括图像的随机裁剪,随机平移,随机的翻转等。第四步是将数据送入网络中,用设计好的方法进行训练以及预测,相关方法在下文详细的进行介绍。
3 目标检测方法
目前基于深度学习的目标检测算法主要包括两种类型,第一种是端到端的算法,这样的算法速度比较快,但是准确率不够高,主要产生的候选框比较多,造成了大量的样本不均衡的现象,如SSD[3],Yolo[4]等。第二种是两步的方法,首先第一步使用某些算法产生候选的框,第二步对候选的框进行分类,以区分真正的物体以及背景等,这样的算法准确率比较高但是速度比较慢,如Fast R-CNN[1],Faster R-CNN[2]等。
■3.1 RFCN
R-FCN是一种分两步进行目标检测的算法,在Faster R-CNN的基础上改进而来,主要包括两步,第一步产生候选的区域,第二步对候选区域进行分类。产生候选区域的算法,遵循Faster R-CNN的设计,同样使用RPN(候选区域提取网络)来提取候选区域,在这一步中我们只需要检测出ROI(感兴趣区域)中是否存在物体即可,不关心物体的真正类别是什么,因此在这一步的训练过程中所使用的类别只有正类以及负类,在分类的同时回归物体框的左下角的坐标以及物体的长和宽。最近的研究表明,越深的网络对于图像分类以及检测来说效果越好,但是网络越深了以后网络越难收敛,同时由于梯度反传的时候由于网络过深可能会造成梯度消失的问题,ResNet的出现同时解决了如上的两个问题,因此本文选择ResNet作为RPN的基础网络,和其他的论文一致,同样使用在ImageNet上训练好的参数对网络进行初始化,删除最后的全连接层,并且讲最后一个卷积换成了1024的1×1的卷积。
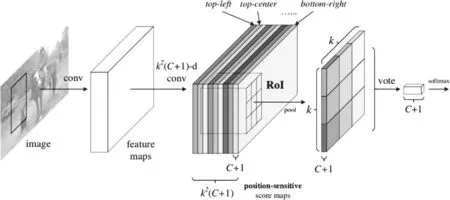
图1
接下来,我们获得了ROI,同时第二个网络的基础网络使用的同样是ResNet101,我们将图片输入ResNet101之后,会在最后的卷积层获得一个不固定大小的特征图,之所以不固定是由于我们使用训练的图像的尺寸本身不固定。然后为了节约计算成本,直接将获得到的ROI映射到特征图上去,这样我们就可以获得ROI的特征图了,但是同样由于ROI的大小是不一致的,因此这里仍然存在着特征图大小不一致的问题。在Faster R-CNN中通过ROI 池化来解决图像尺寸不固定对后续的分类以及定位困难的问题。这样做的缺点是无法生成对位置敏感的特征图,因此检测的效果一直不是非常好,RFCN在最后一个卷积生成特征图的时候,生成了k×k×(C+1)个特征图,其中k表示我们最终想要获得的固定尺寸的特征图的大小,C表示需要预测的物体的类别,之所以加1是因为有背景类的存在,这样对于最终想要获得的特征图我们都有C+1个特征图来表示一块区域,如图1所示,对于第一个C+1个特征图,主要负责预测左上角的位置的特征,即只扣出左上角的一部分作为新的特征图的一部分,以此类推,这样我们可以获得C+1个最终的特征图,然后将C+1个特征图中的每一个进行求和取平均,这样就获得了对于每一类的一个score,最后根据这个score去进行分类就可以获得每一个ROI(感兴趣区域)的类别了,关于候选框的预测,和Fast R CNN一致,在特征图后添加4k×k个卷积核预测候选框。
■3.2 PVANet
RFCN在准确性已经比大部分的网络效果要好了,但是我们在实际的应用中发现,在很多对速度的要求比较高的场景中,RFCN远远达不到我们的要求。比如在自动驾驶的场景中,我们需要实时的对输入的图像进行预测,这样我们才能针对不同的情况作出不同的决策。
之所以比较慢,往往是由于目前的很多网络结构中有着大量的冗余存在。我们在观察中发现,在一些比较浅的卷积层中,当前的卷积层的输出往往是成对出现的,并且每一对的数正好近似于相反数,这样我们就可以利用这一个特点来进行网络的裁剪,本文做的操作是使用CRelu来作为非线性激活函数,也就是说将卷积层的卷积核的数量缩小为原来的一半,然后使用relu进行非线性激活,接下来简单的将激活后的数值去反即可作为当前卷积层的输出,这样整个网络的计算量缩小为原来的一半大小。
另外基础网络的选择中,PVANet使用Inception的结构,之所以选择Inception的结构是因为,一个Inception的模块中包含几个不同的卷积快,而且这几个卷积块所具备的感受野是不同的,这样我们在检测任务中就可以检测出不同大小的物体,小的卷积核所能看到的视野比价小因此可以检测比较小的物体,大的卷积核所能看到的视野比较大,因此可以检测比较大的物体,另外由于最近几年ResNet在图像分类以及目标检测中的优秀的表现,PVANet在Inception结构的基础上添加了捷径(short cut)以增加网络的拟合能力。

图2
整个网络结构如图2所示,输入图像的尺寸是不固定大小的,后面使用一个卷积以及一个池化层将特征图的尺寸迅速缩减到原图大小的1/4,这样可以降低网络的计算量,然后后面是7个带CRelu的卷积以及8个上文中介绍的Inception模块,为了增加网络预测不同大小目标的能力,这里使用多个卷积层的输出作为当前层的特征图来进行ROI池化以及候选框的预测和候选框的分类。最终我们可以获得多个候选框以及对应的类别。
4 实验结果

图3

图4
本文使用的硬件环境是一块Titan X GPU,显存为12GB。软件环境为,Ubuntu16.04系统,修改版caffe。实验的详细配置如下,由于显存的限制,每个batch中只处理两张图像,每一幅图像产生64个候选框。学习率为0.01,正则化参数为0.0001。部分实验结果如图3和图4所示。
5 总结与展望
目标检测在我们的日常生活中的应用越来越多,同时由于硬件技术的进步,使用深度学习解决目标检测任务在我们的生活中也变得越来越普遍。目标检测可以应用到多个领域当中,如自动驾驶,人脸识别,文字检测等。
本文主要介绍了目标检测的背景,意义,当前的研究现状,以及目标检测的多个方法,包括R CNN,FastRCNN,FasterRCNN等方法,最终使用mAP对网络结构进行了评估。
但是,目前目标检测的方法仍然存在着比较多的问题,主要包括:(1)误检的情况多;(2)对于特别大的物体的检测效果仍然不是非常好。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高一使用)(2020年1期)2020-02-20
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
