
基于决策树的网络舆情类型识别模型研究
2018-10-31 07:31:22覃玉冰邓春林张昊宇
智能计算机与应用 2018年6期
覃玉冰, 邓春林, 杨 柳, 肖 望, 张昊宇
(1 湘潭大学 数学与计算科学学院, 湖南 湘潭 411105; 2 湘潭大学 公共管理学院, 湖南 湘潭 411105)
引言
2017年10月18日,在第十九次全国代表大会上,习近平总书记作重要报告,其中8次提到互联网相关内容,25处提到网络信息相关内容,指出了互联网建设管理在过去5年取得的历史成就,强调了互联网在未来将发挥着更大作用。互联网的发展为舆论的传播提供了新的方式,“网络舆情”这一舆论的网络概念也随即产生,并引发各界关注。微博、论坛以及各种搜索引擎等都成为了大众发表观点和表诉立场的公共平台,由于网络的匿名性,网络舆情既可能真实地反映社会各个层面的舆情态势,也可能成为一些谣言舆论散播蔓延的工具。因此精确识别处于潜伏期的网络舆情事件的类型,为相关部门提供更具针对性的策略性调控建议已迫在眉睫。
近年来,国内已经有许多学者相继推出了对网络舆情类型的系列研究成果。郝其宏[1]通过对历史网络群体性事件的归纳梳理将其进行了类型的划分。黄敏等[2]通过聚类分析将城乡结合部群体性突发事件求得了事件结果归类。杜鹏[3]基于事件过程的角度对网络舆情进行了聚类分析,并在分类的基础上展开事件内涵和特征的讨论。袁野等[4]通过分析网络舆情反转现象,利用聚类分析和判别分析构建了反转网络舆情的分类和预测模型。连芷萱等[5]通过多维聚类划分了舆情事件的类型,并运用多项logistic回归探究了网络舆情事件类型与舆情特征之间的关系。刘晓亮[6]构建了涉军网络舆情监测指标体系,为网络舆情监测分析工作提供了借鉴。陈新杰等[7]基于网络舆情传播关系,研究了网络舆情监测指标构建的基本原则,阐述了网络舆情发展演变过程,进而建立四维指标体系。洪亮等[8]通过构建政府治理网络舆情的系统动力学模型对“东方之星沉船事件”进行了仿真研究。梅松[9]探析了政府网络舆情应对机制体系化的治理思路,并提出了应对体系的基本框架。袁野等[10]构建了网络舆情热点事件分类模型,并将网络舆情热点事件分为4类。郭韧等[11]运用了可拓聚类理论和方法对网络舆情的演化趋势进行建模并预测。宋莎莎等[12]以某地区旱灾为例,结合模糊层次分析法和聚类分析对突发事件进行分级研究。
综上分析可见,很多学者的研究思路都是先通过聚类分析将网络舆情进行分类,然后利用传统的预测方法对事件的类型做出预测。然而,随着机器学习方法的兴起,众学者的研究方法并不能够很好地适应前沿的探索研究。为此,本文在现有研究成果的基础上将模型实现了改进,使用机器学习方法中的决策树分类方法将含有聚类分析结果的数据集作为训练集,构建网络舆情类型自动识别模型,期望能较为精确地识别处于潜伏期的网络舆情的类别,为下一步调控举措的出台与实施发挥有益的基础协助作用。
1 网络舆情指标体系的构建
首先,研究从中国网络舆情的实际情况出发,结合网络舆情自身特点、作用机理以及演化规律,参考现有的评估网络舆情的相关指标体系,在遵循全面性、科学性、实用性、灵活性以及划分明确性原则的基础上,利用层次分析法构建出最小完备指标集,将评估网络舆情的指标体系划分为传播扩散、发布主体、内容要素以及舆情受众4个一级指标,并在一级指标的基础上继续深入,建立了二级指标,研究建立的准确评估网络舆情的指标体系如图1 所示。

图1 网络舆情评估指标体系
结合图1中所建立的网络舆情评估的指标体系,这里对网络舆情评估指标体系的4个一级指标给出阐释说明,可详述如下。
(1)发布主体。发布主体是网络舆情中的发布者,即将自己所了解的一些事件信息通过文字、图片以及视频等形式在网络上进行公开发布。发布主体传递的事件相关信息中往往带有一定的感情色彩,再加之发布主体的身份信息以及其在网络上的影响力和引导能力,网民的态度倾向较有可能被发布主体所左右。因此,研究中就将主体身份和影响力作为发布主体的二级指标。
(2)传播扩散。信息的传播扩散是网络舆情形成的必要环节。发布主体将自己所了解的事件信息发布在网络上,通过微博、论坛以及各种搜索引擎等将信息传播和扩散出去,使传播扩散的地理范围越来越广,信息热度急剧上升,最终形成网络舆情。因此,研究中就将持续时间和地理范围作为传播扩散的二级指标。
(3)内容要素。内容要素是反映网络舆情基本情况的重要指标。网络舆情的主题内容和内容倾向是整个网络舆情的研究重点,是监测评估整个网络舆情的核心所在。因此,研究中就将主题内容和主题内容倾向作为内容要素的二级指标。
(4)舆情受众。舆情受众是网络舆情的参与者和互动者。一方面,舆情受众的独立个体因为受教育程度、社会地位、生活坏境以及思想水平的差异,表现出对网络舆情事件的不同看法。另一方面,每一个网络舆情事件对舆情受众的影响程度以及舆情受众对此的关注程度也千差万别。因此,研究中就将态度倾向、百度搜索指数以及网民年龄分布作为舆情受众的二级指标。
2 网络舆情的分类与识别模型构建
下面将研究构建网络舆情的分类与识别模型。首先使用聚类分析对历史网络舆情事件进行分类,并针对每个类型的网络舆情事件,制定提出可借鉴的应对策略,然后利用决策树构建网络舆情事件类型识别模型,识别正在发生的处于潜伏期的网络舆情事件的类型,以便未来能够采用该类型关联的应对策略,有效干预和控制网络舆情的发展状况及走势。
2.1 分类模型的构建
在分类方法中,K-means聚类[13]计算速度快,处理大数据集时仍然能够保持高效率性和可伸缩性,故本文研究选取了K-means聚类分析方法来对历史网络舆情事件进行分类。
2.1.1 样本观测值的确定
设v1,v2,...,vp为p个进行分类的特征指标,则n个样本的数据结构可见表1。其中,xij表示第i个样本的第j个指标值。
表1聚类样本观测值
Tab.1Observedvalueofclustersample

编号v1v2v3...vp1x11x12x13...x1p2x21x22x23...x2p..................nxn1xn2xn3...xnp
2.1.2 基于最小化平方误差的分类模型
(1)观测值点与种子间的欧氏距离。设有v1,v2,...,vp共p个指标变量参与聚类,通过K-means聚类将网络舆情事件分为k类,首先需在这p个变量所形成的p维空间中随机选择k个不同的点,这些点称为种子。然后采用欧氏距离计算每个观测值点与这k个种子之间的距离,欧式距离的计算公式为:
(1)
其中,dim为第i个样本到第m个种子的欧氏距离;xij表示第i个样本的第j个指标的观测值;zmj表示第m个种子的在第j个指标上的取值,实际上就是下文提到的第m类的质心的第j个分量。根据上面确定的聚类样本观测值可知,i的取值范围为[1,n],m的取值范围为[1,k],j的取值范围为[1,p]。
(2)求出类别质心作为新种子。按照观测值点距离这k个种子中的哪一个最近就将该观测值归为哪一类的原则把所有观测值分为k类,并求出每一类的质心,作为k个新种子。假设现已将类别划分为(C1,C2,...,Ck),则质心的计算公式为:
(2)
其中,μCj为类别Cj的质心,实际上是类别Cj的均值向量;xi为属于类别Cj的第i个样本;xip为属于类别Cj的第i个样本的第j个指标的观测值;Nj为属于类别Cj的样本数量。
(3)最小化平方误差实现最优分类。把所有观测值重新按照距离这k个种子的远近分为k类,如此下去,直到种子的位置基本不变、即平方误差达到最小为止。平方误差E的计算公式为:
(3)
2.2 自动识别模型的构建
通过前面构建的分类模型,可以将历史网络舆情事件进行分类,并将这些类型已知的舆情事件作为训练样本集,利用机器学习方法中的决策树分类方法,构建网络舆情类型自动识别模型。该识别模型可以根据正在发生的网络舆情事件的各特征指标观测值,自动识别这些网络舆情的类型,以便相关部门能够更有针对性地施加干预和引导舆情。
在本文中,研究采用结构简单、容易理解的CART算法[14]来构建网络舆情类型自动识别模型。CART算法能够处理自变量中同时含离散型变量和连续型变量的情况,由于上面构造的评估网络舆情的指标体系中既有定性变量、也有定量变量,故选择CART算法构建网络舆情类型识别模型是合理的。
CART决策树又称分类与回归树,是一种良好有效的非参数分类和回归方法。本文中,决策树的终节点是分类变量,所以本文构造的是分类决策树模型。分类树涉及2个基本思想,设计研发要点可总述如下。
(1)划分自变量空间建树。研究初始,即需解决特征值的选取。特征值的选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树学习的效率。CART决策树用基尼指数选择最优特征,同时确定该特征的最优二值切分点。假设有n个类,样本点属于第k个类的概率为pk,则概率分布的基尼指数定义为:
(4)
(2)用验证数据集剪枝。在剪枝方面,CART决策树是根据验证数据集,在完全生长的树上剪去分枝实现的,该算法通过删除节点的分支而剪去树节点,最下面未被剪枝的节点将成为树叶。
3 实证分析
下面研究将对前文构建的分类模型和识别模型进行实证分析。
3.1 样本的选取与赋值
本文数据中选取的事件来源于中国社会蓝皮书中的《中国互联网舆情分析报告》,选取2013~2016连续4年的《中国互联网舆情分析报告》中列出的80个热点网络舆情事件。采用K-means聚类方法进行聚类分析,划分网络舆情事件的类别,再根据分类结果,将这80个事件作为训练集,训练决策树模型,并使用混淆矩阵和十折交叉验证[13]2种不同的验证方法对构建的网络舆情类型识别模型进行评价,最后利用构建的自动识别模型对2017年的《中国互联网舆情分析报告》中所列出的15个热点网络舆情事件进行类型识别。
本文建立的指标体系中,大部分末级指标都是定性指标,其观测值仅代表不同的类别,无大小顺序之分,故采用编制序号的方式对所有定性指标的各个水平进行赋值,赋值依据可详见表2。

表2 赋值依据
结合上述赋值依据,并通过设计开放式问卷量化主观数据,同时利用百度指数中显示的趋势研究、搜索指数以及地域分布、人群属性等量化客观数据,由此将运算得到选取的80个热门网络舆情事件的各个指标的观测值。
3.2 分类模型的实证分析
3.2.1 分类过程及结果
对收集的2013~2016年间最受网民关注的80个网络舆情热点事件进行K-means聚类,将这些热点事件分为5个类别,聚类质量如图2所示。

图2 样本事件聚类质量显示图
从样本事件聚类质量图中可以看出,凝聚和分离的轮廓测量位于聚类质量的良好区间内,这说明使用K-means聚类对这80个事件进行聚类,其效果是良好的,即本文的聚类结果是可靠的。
将80个样本进行K-means聚类、归为5类后,每一类中样本的占比扇形图则如图3所示。

图3 样本事件聚类大小扇形图
从图3中可以看出,在聚类结果中,第五类包含的事件数最多,占所有事件的30%,而第一类包含的事件数最少,仅占所有事件的13.8%。
在使用K-means聚类算法对80个热点事件进行聚类时,预测变量重要性排在前四的指标分别为影响力、主题内容倾向、态度倾向以及主体身份。每一类对应的这4个指标中最高占比的水平及其比值可见表3。
表3每一类对应的重要指标中最高占比的水平及其比值
Tab.3Thehighestproportionoftheimportantindicatorsofeachcategoryandtheirratio

第一类第二类第三类第四类第五类影响力意见领袖(100.0%)普通网民(100.0%)普通网民(78.6%)意见领袖(100.0%)意见领袖(100.0%)主题内容倾向负面(90.9%)负面(94.7%)负面(85.7%)正面(100.0%)负面(95.8%)态度倾向支持(63.6%)反对(78.9%)反对(57.1%)支持(91.7%)反对(100.0%)主体身份当事人(63.6%)围观者(47.4%)知情人(100.0%)当事人(50.0%)知情人(95.8%)
研究中将聚类后的每一类对应的4个重要指标中最高占比的水平及其比值与该类对应的事件进行整理,最终得到每个类别的事件对应的主要特征。限于篇幅,此处将整理后的结果略去。
3.2.2 分类结果分析及应对策略
研究中,通过对具体案例和每一类对应的4个重要指标中最高占比的水平及其比值进行进一步的分析,发现国内5类网络舆情事件在行动导向、目的以及影响上存在着明显的区别,因此,即将网络舆情事件分为5种类型。为获得简洁论述效果,这里仅对其中的第三、第四类事件进行解析探讨,研究推得重点细则可见如下。
(1)舆论炒作型。该类事件最大的特征就是发布主体中的主体身份是知情人,影响力为普通网民。也就是说,这类事件的相关信息是通过知情人散布的,并且消息在普通网民间不断传播,从而形成了具有较大影响力的网络舆情热点事件,经过这种不断的传播炒作,最终形成了对公众影响较大的负面事件。
针对该类事件,相关部门应该对刻意进行炒作的机构或者个人酌判相应的惩罚,因其行为已经对整个社会造成了严重的后果。相关部门也应该对网络上的各种不实传言给予相应的回应,并说明事实的真相。
(2)积极正面型。其主体身份大部分为当事人,影响力为意见领袖;内容要素中主体内容倾向都是正面的;舆情受众中态度倾向大多为支持。一般来说,这类事件都是一些由权威部门发布的积极正面的事件,此类事件是能够让网民感受到国家的繁荣发展、世界的美好格局等积极内容的事件,对此大部分网民也持支持肯定的态度。
对于这类事件,相关部门应该做好宣传工作,抓住发生此类事件的机会,藉此事件大力弘扬和宣传与事件相关的一些正面积极的人生观、价值观以及世界观等。
3.3 识别模型的实证分析
3.3.1 训练决策树
为了能够利用研究得到的分类结果自动识别正在发生的网络舆情事件的类型,设计中使用前文已经划定分类了的80个事件的观测值作为训练集,构造决策树自动识别模型。构建的决策树如图4所示。

图4 自动识别网络舆情事件类型决策树
Fig.4Automaticallyidentifynetworkpublicopinioneventtypedecisiontree
从图4中可以看出,整个决策树进行了4次分叉,分叉的变量分别为“影响力”、“主体身份”以及“主题内容倾向”。从构建的决策树可以看出,根节点处80个事件中每个类别的比为0.14∶0.20∶0.21∶0.15∶0.30,其中第五类事件的个数最多。在根节点,选中“影响力”为拆分变量,当影响力为普通网民时,走向左侧节点,并继续进行判断,在该节点处,当主体身份为当事人和围观者时,走向左侧,并做出决策—该事件为第二种类型,当主体身份为知情人时,走向右侧,并做出决策—该事件为第三种类型;在根节点,当影响力为意见领袖时,走向右边节点,并继续做判断,在该节点处,当主题内容倾向为正面时,走向右侧,并做出决策—该事件为第四种类型,当主题内容倾向为负面和中性时,走向左侧节点,并继续做判断,当主体身份为当事人和围观者时,走向左侧,并做出决策—该事件为第一种类型,当主体身份为知情人时,走向右侧,并做出决策—该事件为第五种类型。
3.3.2 合理性验证
在评估决策树识别网络舆情事件类型的准确率时,将主要从混淆矩阵和十折交叉验证2个角度来评定度量。具体阐析如下。
(1)混淆矩阵。混淆矩阵又称作误差矩阵,是剖析分类决策树识别不同类元组的一种有用工具。本文构造决策树类型识别模型时产生的混淆矩阵可参见表4。
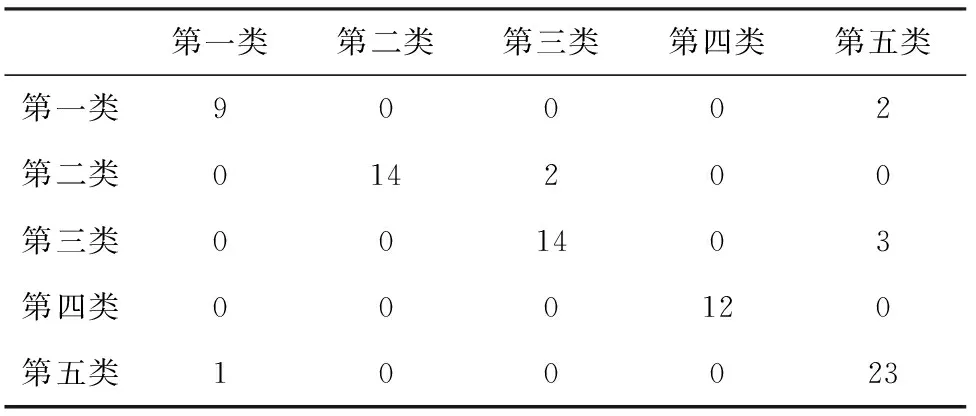
表4 决策树类型识别模型的混淆矩阵
在混淆矩阵中,行是真实类,列是预测类。从表4的数据中可以看出,80个事件中有1个事件是本来属于第五类,但决策树模型将其分到了第一类;有2个事件是本来属于第一类,但决策树模型将其分到了第五类;有3个事件是本来属于第三类,但决策树模型将其分到了第五类;有2个事件是本来属于第二类,但决策树模型将其分到了第三类。
通过混淆矩阵,可算出决策树识别网络舆情事件类型的准确率,计算公式为:
(5)
其中,Ttotal为混淆矩阵中所有元素之和,Tdiagonal为混淆矩阵中斜对角元素之和。
在本文中,决策树模型分类准确率为91.579%,这说明本文构建的决策树分类模型的识别效果很好。
(2)十折交叉验证。在决策树类型识别模型中,因变量有5个水平(1=第一类,2=第二类,3=第三类,4=第四类,5=第五类),相应地分别包含11、16、17、12、24个样本,为了达到最佳的交叉验证效果,先把5种类型的每一种都随机分为10份,然后再将每一份进行汇总,如此就将样本均衡地分为了10份。
依次选择样本中的9份作为训练集,剩下的一份作为测试集。用训练出来的模型对测试集进行分类,并统计分类结果,求出每次实验的误判率,最后将这10次实验的误判率取平均值,由此得到最终的误判率。
十折交叉验证得到的用分类树对网络舆情事件类型进行识别的平均误判率为12.866%,这也说明使用决策树构建的网络舆情事件类型自动识别模型的识别效果很好。
3.3.3 实例识别
利用上面构建的网络舆情事件类型识别模型,对2017年中国社会蓝皮书中《中国互联网舆情分析报告》所列出的20个热点网络舆情事件的类型进行识别,并将识别结果与事件的具体情况进行对比,讨论发现本文研究推证的结果与实际情况基本一致。文中,仅以其中的“十九大召开”事件为例进行具体分析。2017年10月18日至24日,中国共产党第十九次全国代表大会在北京召开。这次大会的主题是不忘初心,牢记使命,高举中国特色社会主义伟大旗帜,决胜全面建成小康社会,夺取新时代中国特色社会主义伟大胜利,为实现中华民族伟大复兴的中国梦不懈奋斗。党的十九大是在全面建成小康社会关键阶段、中国特色社会主义发展关键时期召开的一次非常重要的大会,对鼓舞和动员全党全国各族人民继续推进全面建成小康社会、坚持和发展中国特色社会主义具有重大意义。分析可知,该事件属于第四类——积极正面型事件,与通过本文所构建的模型进行识别的结果一致,从而验证了本文提出方法的可行性和应用有效性。
4 结束语
2018年4月20日,在全国网络安全和信息化工作会议上,习近平总书记出席会议并发表重要讲话,提出领导干部要不断提高对互联网规律的把握能力、对网络舆论的引导能力、对信息化发展的驾驭能力、对网络安全的保障能力。由此可见,网络舆情的正确引导是十分关键的一步。
本文首先用层次分析法将网络舆情评估指标体系划分成为4个维度:传播扩散、发布主体、内容要素以及舆情受众,并对每个维度划分具体的二级指标,该指标体系高度符合中国的实际情况,然后将K-means聚类分析和决策树分类方法结合起来构建网络舆情事件类型自动识别模型,可以识别正在发生的网络舆情事件的类型,以便相关部门能够对网络舆情的发展状况提供及时、有效的干预及调控。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子测试(2017年15期)2017-12-18 07:19:27
中国民政(2016年16期)2016-09-19 02:16:48
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
智能系统学报(2015年4期)2015-12-27 09:38:39
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
电子设计工程(2015年6期)2015-02-27 12:04:53
