
基于行为的网络社团发现
2018-10-31 07:31:22仇英俊张树壮吴志刚
智能计算机与应用 2018年6期
仇英俊, 罗 浩, 张树壮, 吴志刚
(北京邮电大学 网络技术研究院, 北京 100876)
引言
理解网络中主机的行为模式,对其规律和特性进行利用,对于提高网络的运行效率、维护网络安全具有重要的意义。当网络中主机数量规模比较小时,可以通过分析流量内容实现对主机的细致观测。但随着网络中主机数量的增加和网络应用类型的多样化,在大规模网络中分别对每台主机来提供观测已经不再切合当下实际状况,对网络的测量和监管已然成为一个富含挑战性的研究课题。近年来,从网络社团的角度来研究网络中主机的行为模式受到研究者们关注。
计算机网络可以抽象为网或者图系统,是复杂网络的一个特例。在复杂网络中,社团根据节点之间的连通性可定义为由一组内部之间联系紧密而与外部连接稀疏的集群节点组成[1]。发现并探讨复杂网络系统中的社团对于理解整个系统的构成、演化等方面则将发挥基础性的优势推动作用。对于计算机网络而言,社团通常被认为是由一组有着共同目标或处在同一环境中的主机组成[2],即网络中的主机会因为访问相同的网站或使用相同的网络应用而形成网络社团。相比于逐台主机的监测方法,了解网络中社团的属性及行为模式相当于对原始数据进行“压缩”[3],此时只要观察一个社团中的少量的主机或流量,就可以确定同社团中其它成员的属性及行为,因此可以更加快速、有效地了解网络整体的运行情况。研究计算机网络中的社团可以用于未知流量检测[4- 5]、网络流量分析[6- 7]、僵尸网络检测[8- 9]、网络应用识别[10]等方面,可以为网络管理员进行网络资源配置、病毒防护等工作提供重要依据,对于维护网络安全也有着重大影响与研究价值。
在当前的研究中,网络社团并没有一个统一明确的描述,但根据各自的研究目标,网络社团可以从2种角度给出定义。一种是根据主机通信行为的相似程度进行定义,另一种是从通信关系的紧密程度予以定义。因此网络社团发现方法可以分为2类,分别是基于主机行为聚类的方法和基于拓扑划分的方法。其中,考虑到一般情况下将无法事先确定网络中社团数量及社团的规模,因此基于主机行为模式的无监督或半监督聚类方法被提出来[11-13]。这类方法首先从主机通信时产生的流量中提取出特征,包括端口号、负载信息等统计值,然后使用聚类算法找出流量行为相似的主机集群。但该类方法的不足就在于容易受到加密技术和混淆技术的影响而得到不准确的聚类结果[12]。另一类方法是根据主机之间的连通性,将主机之间的通信关系用图来表示,然后使用图分割的方式找出连接紧密的主机集群[6, 14-16]。这类方法仅仅讨论了拓扑信息,而当固有的拓扑结构中存在多种类型流量时,却无法得出更加细致的社团划分,例如一个CDN节点上缓存了多个网站的内容,所有访问这个节点的主机会被笼统地看作是一个聚类,而不能因访问的网站不同而被区分。
这2类方法发现的网络社团仅能说明社团中的成员主机在通信关系或流量行为单一的某个方面存在相似性。随着网络应用种类的多样化,每一台主机都会同时参与多种应用,仅通过单一角度得到的网络社团并不能全面反映网络中主机当前所处的状态及网络资源的使用情况,因此本文所研究网络社团同时结合通信关系和流量行为特征2方面因素,同一网络社团内的主机既在通信关系上具有联系,又在通信行为模式上呈现出相似性。为此,本文研发提出了一种新的网络社团发现方法,将网络中的通信节点按照通信关系划分成不同的子网。然后,为了发现通信关系相同但通信行为不同的情况(例如攻击),本文又使用聚类的方法,进一步区分同一子网内的传输行为不同的网络流。综合上述2个步骤就可以实现更加准确的网络社团发现。本文的贡献在于:
(1)重新定义了网络社团,即社团中主机具有通信关系相似及通信行为相似2方面特性。同时社团中包括了服务端和客户端,而不是仅仅将访问共同目标的客户端集合称为社团,有利于网络的测量与分析。
(2)用
(3)提出一种新的网络社团发现方法。这种方法结合网络关系及流量聚类2方面,可以得到更加精确的网络社团发现结果,例如发现同时承载多种服务的IP、区分访问同一
在此基础上,本文将按如下方式进行组织。首先研究了不同种类的网络社团发现方法,其次论述了本文提出的网络社团发现方法的设计与实现,包括网络拓扑划分和网络流聚类2方面,然后展示、及评估了网络社团发现结果,并对典型社团进行分析,以说明本方法的实用价值。最后是本文的结论及未来的工作。
1 相关工作
区分不同的行为模式的主机集群对网络安全的影响的分析研究课题正日渐受到研究人员的广泛关注。在进行网络通信过程中,使用相同网络应用的主机所产生的流量在行为特征上会表现出相近的模式,运用这些模式就可以定量地表示主机的通信行为,并以此达成主机分类的目的。而分析可知,网络中应用和主机的数量是无法事先确定的,因此无监督和半监督聚类方法常常用来区分不同行为模式的主机。Terzi等人[17]在分布式计算环境中,提取出端口、目标IP和负载等相关特征来描述源IP地址的通信行为,并对源IP地址进行聚类,以发现僵尸网络。Wei等人[13]从网络流量数据中识别出活跃主机,并从这些主机的报文头部中选取了相关特征,使用层次聚类算法构建主机树状图,找出行为相似的主机集群。Jakalan等人[10]设计算法找出网络中重要的IP节点,提取了15个通信模式特征,使用dbscan聚类算法得到主机集群,再通过比较不同集群中主机的特征值来分析聚类结果。Shadi等人[18]将TB级流量数据中的IP,按传输的数据量和所属的地址块汇聚到一个树形结构中,用于查找企业网络中流量最大的IP地址块。Dewaele等人[11]提出了描述主机通信模式的9个特征,而且使用最小生成树的无监督聚类方法来区分不同类型的主机。Iliofotou等人[12]提出了一种基于标签传播的IP地址分类方法,该方法只需要知道IP之间的连通关系和少数IP主机的应用程序使用情况,就可以对所有IP进行分类。
由于网络中主机间表现出的通信行为与社会网络中的社会行为类似,故而社会网络中的社团发现方法也被运用在计算机网络中,其中二部图模型即可用于描绘网络中主机的通信关系。在网络的二部图模型中,主机被分为完全独立的2个集合,这2个集合之间的连线表示了主机间的通信关系。二部图一个集合中的主机会根据对另一集合中主机的访问情况,而被分成不同的网络社团。Xu等人[6, 16]通过分析主机间通信关系,提出一种新方法来研究网络中社团行为相似的主机。该方法先根据主机所处的网段,将整个网络分为2部分,构建二部图,然后使用单模投影的方法,统计同一网段下主机对网段外主机的访问情况,构建相似矩阵,最后对主机使用谱聚类的方法,将同网段下的主机分成行为模式互不相同的若干集群。类似地,Jakalan等人[14- 15]使用边界路由上获取的NetFlow数据集构建二部图。为了描述管理域内IP在社会关系上的相似性,研究中进一步对二部图应用了单模投影,同时构建相似矩阵,最后设计算法对相似矩阵进行迭代,得到最终的网络社团划分结果。
上述方法均是将主机(或IP)作为一个整体进行操作,一个主机(或IP)会被划分至唯一的网络社团当中。而事实上,一个客户端可以同时使用多种网络应用,一个服务器也可能同时提供多种服务,这就使得一个主机(或IP)可以同时属于多个网络社团。为了更好地分析网络中社团存在情况,本文设计给出了一种网络社团定义及发现方法。该方法将主机同时提供不同服务或者参与不同应用的情况考虑进来,可以更清楚地表示通信关系。在对通信关系图做出分割后,又根据通信行为特征对主机进行聚类,最终可以得到有意义的网络社团发现结果。
2 网络社团发现方法
与已有的研究类似,本文拟将研究的网络社团在本质上也是由网络中节点(主机或IP)构成的集合。但本文在此基础上深入细化了网络社团的定义,社团中的节点要同时具有2方面特性,对此可做如下阐述:
(1) 存在服务提供节点(也称为领袖节点)且其它成员节点与领袖节点具有相似性的通信关系。
(2) 成员主机与领袖节点在通信行为模式上具有相似性。
同时满足这2个条件的主机集合,研究将其称为网络社团,下文将简称为社团。比如服务器A、B提供不同的服务,有客户端1~7与2个服务器按照图1中连线的方式进行通信,线的形状用于不同的通信行为。根据上面对社团的描述,可以将图中的节点划分成3个社团,即{A,1,2}、{A,3,4,5}和{B,4,5,6,7},其中A和B作为领袖节点决定了社团的类型,1~7作为成员节点为了获取某种网络服务而与领袖节点通信。{1,2,3,4,5}虽然都与A发生过通信,但是由于{1,2}与{3,4,5}在通信行为模式上存在不同,则仍然分属于不同社团。通信行为模式不同,究其原因可能在于服务器A同时提供多种服务,也可能是部分客户端{1,2}或{3,4,5}都以非常规方式访问服务器。本文研发提出的方法就是为了找出网络中满足上述2个条件的社团结构。

图1 社团示意图
本文提出的方法分成2部分。研究中,就是根据通信节点之间的通信关系,将网络关系图划分成多个子网。一个子网由一个领袖节点(通常是服务节点)和多个成员节点(通常是客户节点)及节点之间连线(网络流)组成。一个子网中可能存在一种或多种网络服务或应用,因此要根据网络流的统计特征,将同一子网中的节点进一步划分,找出在连接性和流量特征都相似的主机集合,即为最终的社团发现结果。对此,将展开如下研究论述。
2.1 基于通信关系的网络拓扑划分
一个网络社团通常是由一个服务节点及多个客户节点共同组成。如果能先找出网络中的服务节点,那么服务节点及其邻接节点就会组建构成一个子网,有利于后续研究中的社团发现。
一段时间内的网络关系可以用图来表示,在许多研究[2-4, 6, 14-16]中都是将IP作为实体,在图中用节点进行表示。如果2个IP之间出现了数据传输现象,那么就用一条边将这2个IP代表的节点连起来。分析发现,短时间内主机与IP对应关系基本不会发生改变,因此IP的行为即代表对应主机的行为。这种表示方式也存在一定的局限性。首先,将无法从拓扑结构上判断出一个IP是服务器还是客户端。比如图2所示的结构,其中1号节点既可能表示一个服务器接受许多客户端的访问,也可能是一个客户端同时使用多种网络服务而与多台主机通信。其次,是无法从拓扑结构上判断一个服务器提供几种服务以及每种服务所对应的客户端都有哪些。
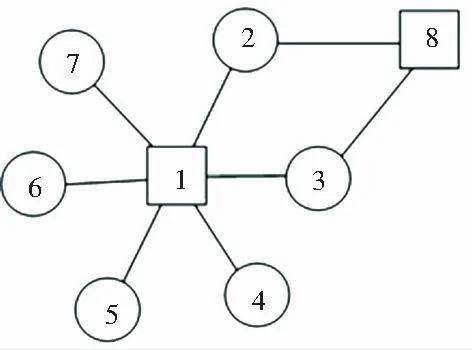
图2 通信关系
对于绝大多数的网络服务或应用,网络服务需要开放固定端口来响应许多客户端发出的请求,端口的使用情况对于准确判断一个服务提供的服务种类及数量将颇有助益。因此本文将
(1)可以准确地区分出服务节点与客户节点。客户端在与服务器进行通信时,通常会使用多个端口,而服务器通常只用固定的端口,这种端口上的差异就可以使得服务节点获得较大的度数,从而可以清晰地识别出一个节点的身份。即使是一个IP同时访问多个服务器,服务节点度数较大的现象也不会发生改变。
(2)可以识别出同一IP承载多种服务情况。同一IP会为不同的服务类型而开放不同的端口,因此
服务节点和客户节点组成了网络中常见的结构——C/S型结构。在这种结构中通常有一个服务节点与多个客户节点。短时间内,每个客户节点只与服务节点进行通信,而不与其它的客户节点直接通信。因此在邻接节点的数量上,服务节点和客户节点存在明显差异,即对于某一网络服务或应用,服务节点的邻接节点多,客户节点的邻接节点少。定义邻接矩阵A,其中每个元素的数学表述如下:
(1)
对于节点i,这里定义集合的数学表示如下:
Pi={p|Aip=1}
(2)
Qi={q|Apq=1,p∈Pi,q∉Pi,q≠i}
(3)
研究推得,|Pi|与|Qi|分别表示集合Pi和Qi中元素个数。如图2所示,对于所有节点i=1,2,3,4,5,6,7,8来说,各自的Pi与Qi可参见表1。

表1 各节点的Pi与Qi
由表1可以看出,C/S结构中对于核心节点有|Pi|>|Qi|,而边缘节点|Pi|<|Qi|,因此对于任意节点,该节点的|Pi|与|Qi|的大小关系,可以反映其在网络中所处的位置或身份。为了验证这一论点,文中使用某企业边界路由上采集的NetFlow日志,以
基于上述设计,就可以将网络中的通信节点(用
算法1网络划分
输入:节点列表nodes
输出:节点所属子网编号列表C
1: 初始化C中所有元素值为-1,c=0
2: Foriin nodes:
3: ifC[i]!= -1:
4: continue
5: 计算Pi及Qi
6: if |Pi|+|Qi|>2 and |Pi|>|Qi|:
7:C[i] =c
8: forjinPi:
9:C[j] =c
10:c+=1
11:returnC
其中,变量c是待分配的子网编号,变量C记录了每个节点所属的子网编号,如果一个节点已经被分配过一个子网编号则跳过。如果节点i的|Pi|+|Qi|值非常小(不大于2),则说明节点i及其邻接节点构成的子网也很小,不足以构成一个有影响力的社团,可以被忽略。
2.2 网络流聚类
在大部分情况下,使用2.1节中的方法得到的节点划分结果可以描述网络中的社团存在情况,但是由于某些恶意行为是依托固有的通信关系,通过发送恶意报文来实现的,比如DDos攻击、蠕虫、木马等等。因此本文接下来会通过聚类方法,将同一子网内的通信流量按照传输数据的统计特征进一步区分,以得到最终的社团发现结果。综上研究过程后可以得知,社团内成员无论在通信关系上,还是在通信行为模式上都有着极高的相似性。
2.2.1 网络流聚合及特征提取
经过网络拓扑划分后,具有密切通信关系的节点会被划分到同一子网中。大部分情况下,在短时间内一对IP之间只会围绕一种网络服务进行通信,因此可以将同一子网中节点之间的网络流,按照IP对进行聚合来提取通信行为特征。这样就不仅避免了个别离群的网络流对社团划分结果的影响,而且可大幅降低用于聚类的实例数量,同时也减少了聚类运算的时间。
网络流通常用五元组表示,即:<源IP,目的IP,源端口,目的端口,网络协议号>。NetFlow日志中以五元组为标识,记录了每一条网络流的统计信息,比如各方向的包数、字节数等。在聚合过程中,会将每一对通信IP之间的所有网络流进行组合,进而提取出一个特征向量用于描述这一对IP之间的通信行为。其中包括的内容可解析如下。
(1)源IP地址使用的不重复端口数量。
(2)目的IP地址使用的不重复端口数量。
(3)协议号的平均值。
(4)上/下行流包数最小值/中位数/最大值。
(5)上/下行流平均包长最小值/中位数/最大值。
总地来说,特征1,2反映了一对通信IP地址端口的使用情况。特征3用于反映一对通信IP地址传输层协议的使用情况。本文只研究协议号为6(TCP)及17(UDP)的网络流。特征4反映一对IP传输报文数的分布情况,特征5反映了一对IP传输报文长度的分布情况。此番特征提取后,一个子网内IP对之间的通信行为模式就做到了精准的定量化描述。
2.2.2 预处理及聚类
为了统一每个维度的权重,在聚类前要对同一子网内的实例(即IP对)特征值进行归一化。本文将使用最大最小值缩放将特征缩放到[0,1]。假如一个子网中有N对发生通信的IP对(即聚类的实例),缩放运算可写作如下形式:
(4)
其中,i表示待聚类的实例序号;Fik表示第i个实例的第k个特征值,k=1,2,…,15;Fk表示待聚类所有实例的第k维所有特征值构成的数列;max(Fk),min(Fk)表示对Fk求最大、最小值;fik是归一化后的特征值。
至此,本文将使用dbscan聚类算法[19]来处理每个子网中的所有的实例。dbscan是一个基于密度的聚类算法,不需要指定聚类的数量。在缺失先验知识的情况下,一个子网中的网络流的种类数及每个种类中流的数量是不确定的,所以非常适合用dbscan来进行聚类。dbscan算法将归一化后的特征向量矩阵作为输入,矩阵的每一行表示一对IP间的网络流,每一列表示一个特征维度。算法会输出一个标签数组,数组中每个元素与矩阵的每行一一对应。标签用来指出对应向量所表示的网络流所属的类别。标签相同的网络流所涉及的全部IP即是本方法最终的网络社团发现结果。
3 实验
3.1 数据集
为了获取实验数据集,研究中从某企业网的边界路由采集了2周的网络流日志。经过数据清洗和筛选后,得到的数据集包含约3千万条网络流,遍历内网IP节点209个,外网IP节点54 147个。在采集过程中,研究在局域网内模拟了DDoS攻击行为以验证本方法的实用性。数据存储上类似于NetFlow的格式并导出为可读的文本形式用于本文的仿真实验。本次研究需要的数据字段包括:源IP、目的IP、源端口、目的端口、网络协议号、流上行包数、流下行包数、流上行字节数、流下行字节数。
3.2 实验结果
3.2.1 模块度
本文通过计算模块度[1]来评价划分结果。模块度由于计算简单而且能较好地反映全局划分结果的优劣,因而获得了广泛使用。图3即展示了某天1 h的数据得到的结果,其中包括214 735条网络流,16 145个IP地址。每隔5 min做一次社团发现操作。得到的划分结果模块度在0.8以上。这就说明本文提出的通过比较|Pi|和|Qi|的大小来判断节点i的身份,并据此对网络进行划分的方法是简单且有效的。
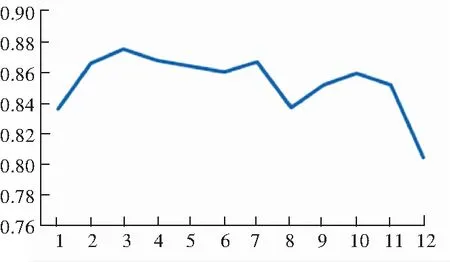
图3 不同时段的模块度
3.2.2 社团数
各时段子网数量及社团数量如图4所示。图4中社团数目要大于子网数,这是由于某些子网内,网络流在通信行为模式上的不同导致主机被划分到了不同社团中,比如DDos攻击中的恶意用户和正常用户,虽然在通信关系上相同,但是却会因通信行为特性的不同而被归类至不同的社团中。

图4 不同时段的子网数与社团数
为了说明本方法的有效性,研究又使用Xu的方法[6]对同样的数据进行社团发现。由于Xu的方法在社团发现的过程中对二部图使用了单模投影,则使得每次只能得到网络某一侧的社团存在情况。继而,研究又对企业网内部与外部的IP分别使用文献[6]中的社团发现算法,得到的结果可详见图4。结果显示对于同样的数据集来说,本方法发现的社团在数量上相比于Xu的方法要超出许多。在对结果辅以考察分析后,研究中又发现得知,Xu的方法并不能对通信关系相同但通信行为特性不同的情况做出区分(比如DDos攻击情况),而且Xu的方法发现的社团中并没有服务节点(领袖节点),因此不能直观地反映社团的属性。本方法在发现网络社团时,还旁及兼顾了通信关系和通信行为特性,而且保留了社团中的领袖节点,这些设计均有利于更加准确地发现社团及研究社团的属性,而这也是本方法相比于已有研究的优势所在。
4 结束语
本文提出一种网络社团定义方法并在此基础上研发了一种新的网络社团发现方法。本方法在建立通信关系图时考虑了端口的使用情况,以
猜你喜欢
计算机时代(2023年1期)2023-01-30 04:08:22
科学家(2021年24期)2021-04-25 13:25:34
中国新通信(2019年21期)2019-03-30 04:01:30
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
网络安全和信息化(2017年6期)2017-11-23 08:36:18
网络安全和信息化(2016年2期)2016-11-26 06:42:30
电脑迷(2015年6期)2015-05-30 08:52:42
职业·中旬(2015年4期)2015-05-30 05:54:49
