
基于Spark的水库群多目标调度粒子群并行化算法
2018-10-29 10:19:08马川惠
西安理工大学学报 2018年3期
马川惠,李 瑛,黄 强,李 凤
(1.西安理工大学省部共建西北旱区生态水利国家重点实验室,陕西西安 710048;2.西安理工大学计算机科学与工程学院,陕西西安 710048)
传统的水库多目标调度模型求解是以单目标优化模型为基础,多采用目标约束法、主次目标法、目标加权法、理想点法等为主要求解方法。1985年,Yeh[1]在水库多目标分析过程中,采用ε-约束法得到了兼顾发电和供水两个目标的折中解。1987年,董子敖和阎建生[2]提出了一种把多水库多目标的复杂优化问题经过多次分层后,转化为相对简单的子问题来求解的多目标多层次优化方法,为解决大规模水库群优化调度的“维数灾”难题提供了新途径。1997年,黄强和沈晋[3]提出了水库群多目标调度模型的求解方法,对解决复杂水库群联合优化调度问题具有实际参考价值。上述方法其本质上还是单目标优化方法,不足之处是计算工作量大、计算速度慢、存在“维数灾”等,不利于工程实际应用。
目前,智能优化算法在水库群多目标调度模型求解中正处于快速发展阶段,如遗传算法、蚁群算法、粒子群算法等已经取得了显著成果,具有并行计算特性,对解决复杂水库群多目标调度模型具有很大优势。1985年,Schaffer[4]提出第一个设计多目标进化算法——向量评价遗传算法。2000年,由Deb等[5]对非支配排序遗传算法(NSGA)进行了针对性改进,提出了基于快速分类的非支配排序遗传算法(NSGA-Ⅱ)。2006年,Kim等[6]针对Han River流域的4座水库2个目标调度问题,利用NSGA-Ⅱ算法进行求解,获得了令人满意的效果。2007年,Reddy和Kumar[7]提出一种用于求解水库群多目标调度问题的多目标差分进化算法,取得了比NSGA-Ⅱ更好的优化效果。2007年,Li Chen等[8]提出了一种用于确定以用水和发电为目标的综合利用水库调度图的基于宏进化的多目标遗传算法。2016年,杨延伟[9]针对基于实数编码的遗传算法(RAGA)在实际水库调度应用中易于早熟的缺点,提出一种改进的RAGA。2017年,张翔宇等[10]针对NSGA-Ⅱ算法在进化过程中存在的不足,利用拟随机Halton序列及自适应调整的方法加以改进。
2006年,马细霞等[11]以某综合利用水库优化调度为实例进行研究,表明基于粒子群优化算法的调度模型适用于年内水库优化调度规则的确定。2007年,杨俊杰等[12]提出一种新的基于自适应网格技术的多目标粒子群优化算法,为求解大规模多目标优化问题提供了一种有效手段。2008年,Alexandre和Darrell[13]建立了基于多目标粒子群算法的水库群优化调度模型,并指出该模型的缺点,如对算法参数的选择较为敏感等。2017年,张忠波等[14]把下山搜索策略引入到粒子群智能算法中,函数测试证明该方法改进了算法的鲁棒性,提高了算法求解效率。
但是,随着水库群优化调度的规模和数据急剧增大,各智能算法存在搜索时间长、易陷入局部最优解等问题。为了提高智能算法的运行效率,本文建立了水库群多目标优化模型,提出了基于Spark框架的粒子群并行化算法,旨在弥补智能算法的缺陷,提高求解模型的速度,对更好地解决水库群多目标调度问题具有重要的理论意义和应用价值。
1 水库群多目标优化模型建立及求解
1.1 模型建立
本文以发源于祁连山的黑河为研究对象,黑河流域水资源短缺,综合利用矛盾突出,为了充分开发利用水资源,已修建了众多水库,如何科学、合理调度水库群,发挥水资源综合利用效益,已成为亟待解决的问题。黑河流域水库群调度具有多目标的特点,既要兼顾上游发电目标、又要满足中游农业灌溉目标,同时还要考虑下游生态用水目标。因此,本文以灌溉缺水量最小、生态缺水量最小、发电量最大为目标,建立目标函数:
minf(f1,f2,-f3)
(1)
式中,f1、f2、f3分别为灌溉缺水量、生态缺水量、发电量。
目标1 灌溉缺水量最小
(2)
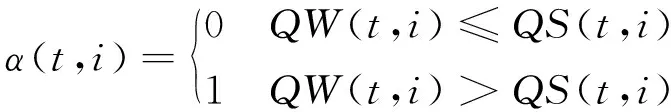
(3)
式中,T为总时段数;I为总取水口数;α(t,i)为第t个时段第i个取水口的灌溉系数;QW(t,i)和QS(t,i)分别为第t个时段第i个取水口的灌溉需水量和供水量。
目标2 生态缺水量最小
(4)
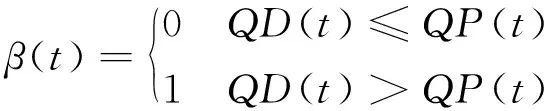
(5)
式中,β(t)为第t时段的生态系数;QD(t)和QP(t)分别为第t时段的生态需水量和供水量。
目标3 发电量最大
(6)
N(t,m)=k(m)Q(t,m)H(t,m)
(7)
式中,M为电站个数;N(t,m)为第t个时段第m电站的出力;Δt为最小计算时段;k(m)为第m电站出力系数;Q(t,m)为第t个时段第m电站的发电流量;H(t,m)为第t个时段第m站的发电水头。
上述目标函数应满足的约束条件为:
约束1 水量平衡约束
V(t+1,m)=V(t,m)+(QO(t,m)-QI(t,m))Δt
(8)
约束2 流量连续约束
QI(t,m+1)=QO(t,m)+q(t,m+1)
(9)
约束3 蓄水位约束
Zmin(t,m)≤Z(t,m)≤Zmax(t,m)
(10)
约束4 库容约束
Vmin(t,m)≤V(t,m)≤Vmax(t,m)
(11)
约束5 下泄流量约束
QOmin(t,m)≤QO(t,m)≤QOmax(t,m)
(12)
约束6 出力约束
Nmin(m)≤N(t,m)≤Nmax(m)
(13)
约束7 边界条件约束
Z(1,m)=Zc,Z(T+1,m)=Ze
(14)
约束8 控制断面流量约束
QS(t,i)≥QW(t,i),QP(t)≥QD(t)
(15)
式中,V(t+1,m)、V(t,m)分别为第t+1时段初(第t时段末)、第t个时段初第m电站的库容;QO(t,m)、QI(t,m)分别为第t个时段第m电站的出库流量、入库流量;q(t,m+1)为第t个时段第m电站与第m+1电站之间的区间入流;Zmin(t,m)、Zmax(t,m)分别为第t个时段第m电站的最低、最高水位;Z(t,m)为第t个时段第m电站的水位;Vmin(t,m)、Vmax(t,m)分别为第t个时段第m电站的最小、最大库容;V(t,m)为第t个时段第m电站的库容;QOmin(t,m)、QOmax(t,m)分别为第t个时段第m电站的最小、最大出库流量;QO(t,m)为第t个时段第m电站的出库流量;Nmin(m)、Nmax(m)分别为第m电站的最小出力、装机容量;Zc、Ze分别为起调水位和调度期末蓄水位。
式(1)~(15)是本文建立的水库群多目标优化调度模型,该模型具有多目标、多维、非线性、动态等特点,模型输入资料涉及社会、经济、水文、气象、生态、水利工程、水资源综合利用等方面,数据量庞大、关系复杂。因此,寻求求解模型的算法、处理庞大的数据量与保证计算速度成为难点。本文采用基于Spark框架的粒子群并行化算法求解该模型,旨在克服“维数灾”,提高计算速度。
1.2 模型求解
水库群多目标优化调度模型的求解可用主次目标、目标加权、理想点等方法,把多目标模型转化为单目标模型,对单目标优化模型采用动态规划、遗传算法、蚁群算法等进行求解。但这些方法计算工作量大、速度慢,存在“维数灾”。本文利用粒子群算法(PSO)对多目标优化模型进行整体一次求解。该算法是从随机解出发,通过迭代寻找最优解,它通过适应度来评价解的品质,通过追随当前搜索到的最优值来寻找全局最优。粒子群算法是一种成熟的算法,其具体步骤见文献[15]。
2 基于Spark平台的粒子群算法并行化
2.1 Spark平台
Spark支持的大规模并行分布处理算法实现了基于内存的分布式计算,基于弹性分布式数据集(RDD)成功构建起了一体化、多元化的大数据处理体系。使用Spark SQL、Spark Streaming、MLlib、GraphX等工具,可以解决大数据批处理、流处理、图处理、机器学习、即席查询与关系查询等关键技术问题,只需一个框架就可满足各种使用场景的需求。2003年以来,Spark逐渐获得了学术界与工业界的认可,成为大数据处理技术的研究热点、新一代大数据处理平台的首选。RDD是Spark并行处理的基础,所有Spark的操作都围绕RDD进行。应用RDD可以进行并行数据集之间的互相转换、缓存等操作。基于Spark进行并行化编程时,要将输入数据分解成一个个批处理片段,然后再将这些数据段都转换成Spark中的RDD,即将数据封装在RDD中,通过进行RDD的并行操作,实现数据处理的并行执行。因此,基于Spark平台并行计算模型编程实现粒子群算法的基本步骤为:把粒子群封装为RDD,并将其初始化为大小规模均等的多个小种群;再对这些小种群粒子群进行并行处理,构建可行解[16-20]。
2.2 基于Scala语言的粒子群并行编程方法
Scala语言是具有面向对象和函数式编程特性的多范式编程语言,是Spark主要支持的高级计算机语言,面向分布式并行程序设计;Spark中大多数代码都是通过Scala语言编写的。
本文运用Scala并行编程方法实现了并行PSO算法在水库群优化调度中的应用,具体流程图见图1。

图1 并行PSO算法流程图Fig.1 Parallel PSO algorithm process
3 应用实例
3.1 黑河水库群多目标调度实例
黑河是我国西部地区较大的一条内陆河,发源于祁连山与大通山之间,流经青海、甘肃、内蒙三省区,流域面积约为14.29万km2,干流河长821 km[21]。莺落峡以上为干流上游,地处山区,分东西两岔,河道比降大,水量较为充沛,不仅是黑河流域的主要产流区,也是该流域的梯级水电开发基地。莺落峡至正义峡之间为中游,地势相对平坦,光热资源丰富,沿岸分布多个灌区,是该流域的主要用水区。正义峡以下为下游,降水稀少,蒸发强烈,生态系统脆弱,是该流域的主要生态耗水区。黑河干流上游主要有8座梯级水电站水库,分别是黄藏寺(在建)、宝瓶河、三道湾、二龙山、大孤山、小孤山、龙首二级和龙首一级。本研究采用资料包括气象、水文、水利枢纽、河渠机井、中游灌区、生态需水、分水方案及相关社会经济等方面的海量数据。
采用基于Spark并行计算框架的粒子群算法,求解水库群多目标优化调度模型,获得了较满意的结果:中游灌区灌溉保证率为50.5%,居民生活和工业生产供水保证率为95.1%;狼心山断面多年平均下泄生态水量满足多年平均应下泄水量的要求;黑河上游8座梯级水电站多年平均发电总量为21.85亿kW·h,比设计值减少3.8%。说明黑河流域水库群多目标调度牺牲了发电效益,满足了供水和生态效益,符合“以水定电”的调度策略和黑河流域的实际状况。
3.2 计算性能比较
系统性能测试在64位单机Windows 7操作系统、8 GB内存的环境下运行。为了对比分析,本文分别采用基于串行和并行化的粒子群算法求解水库群多目标优化模型,且逐步增加了输入的数据条数来测试这个程序的性能,测试结果如图2所示。其中,串行粒子群算法应用Visual Basic语言编程,并行化粒子群算法用Scala语言编程。
数据条数从2 052增加至20 520,增至原来的10倍,在单机条件下,串行运行时间从26.90 min增加至364.60 min,并行运行时间从3.08 min增加至53.20 min,并行比串行运行速度有了很大提升,提升速度约6~8倍。
为了测试单机与多机的运行速度,本文分别在Ubuntu Linux操作系统环境下,采用单机和10台联想服务器并行计算,且逐步增加程序运行的数据条数(从2 052增加至20 520),得到了更加理想的结果,如图3所示。

图2 单机串行与单机并行程序运行时间比较图Fig.2 Run time comparison between single machine serial and single machine parallel program

图3 单机与多机并行程序运行时间比较图Fig.3 Run time comparison between single machine and multi-machine parallel program
与上一步所得的单机并行运行时间进行比较,多机并行运行时间在数据条数增加的过程中,从0.80 min增加至8.27 min,多机并行比单机并行计算速度有了大幅提升,约提升了4~7倍,且随着输入数据条数的增加,速度提升优势明显,体现出Spark平台处理大量数据的优势。
4 结 语
随着社会经济的发展,在江河修建的水库数量和规模越来越大,水库群调度所需资料、数据量庞大,关系复杂。由于水库群之间的水力联系更加复杂化和调度规模更加庞大,进一步加剧了水库调度问题求解的复杂性,应用常规技术进行优化调度计算难度较大、速度慢,且存在“维数灾”等。此外,水库运行积累的数据也呈现出指数增长的趋势,形成了海量数据源。因此,水库群多目标调度对海量数据处理有着强烈的需求;同时,需要并行计算技术为水库群调度及其优化计算提供强大的计算能力。
本文以黑河流域的水资源调度问题为背景,建立了水库群多目标优化模型,提出了基于Spark框架求解模型的粒子群并行化算法。实例表明,将粒子群算法与Spark并行计算框架结合使用,满足了当前水库群调度多目标的需求,提高了程序的运行速度,说明基于Spark框架求解模型的粒子群并行化算法具有很好的性能。研究旨在弥补智能算法的缺陷,提高求解模型的速度,对水库群多目标优化调度的并行编程发展与应用具有重要的参考价值。
猜你喜欢
中学生数理化·中考版(2021年12期)2021-12-31 03:24:42
加油站服务指南(2021年4期)2021-07-21 02:29:22
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30
建材发展导向(2019年5期)2019-09-09 09:23:00
中国生殖健康(2019年8期)2019-01-07 01:18:20
人生十六七(2015年6期)2015-02-28 13:08:38
发明与创新(2015年33期)2015-02-27 10:40:10
西南军医(2015年5期)2015-01-23 01:25:07
江苏卫生事业管理(2013年5期)2013-03-11 17:02:03
上海理工大学学报(2012年3期)2012-03-20 13:54:43
