
数据融合技术在环境监测网络中的应用与思考
2018-10-29 10:33薛惠锋李养养杨伟伟张佳音
中国环境监测 2018年5期
郑 淏,薛惠锋,李养养,杨伟伟,张佳音,王 斐
1.西北工业大学自动化学院,陕西 西安 710072 2.陕西省环境监测中心站,陕西 西安 710054 3.中国环境监测总站,国家环境保护环境监测质量控制重点实验室,北京 100012
近年来,我国的生态环境监测网络快速发展,环境监测实现了从手工到自动、从粗放到精准、从间断到连续的重大转变。目前,我国已建成覆盖338个地级及以上城市的1 436个空气自动监测站,2018年将建成覆盖全部重点流域的2 050个水质自动站。随着自动监测技术和标准的成熟,自动监测网络日趋完善,伴随海量环境监测数据的生产、存储和传输,基于多环境要素的环境质量评价越来越多地被应用于环境管理决策中。
环境监测网络实时产生大量监测数据,解决了传统环境监测方法面对复杂大环境时信息片面和数据失真的问题。然而,面对海量、多源的监测数据,多维度、深层次的分析技术应用还亟待加强,以适应大数据时代下,智慧环保的各类需求。
1 数据融合的原理
1.1 数据融合的概念
随着传感器技术、计算机技术和信息技术的快速发展,20世纪70年代,“数据融合”这一概念首先在军事领域中被提出,即把多个传感器获取的数据信息进行融合处理,得到比单一传感器更加准确和有用的信息数据融合技术。Klein[1]定义数据融合是“多层次、多方面处理自动检测、联系、相关、估计以及来源的信息和数据的组合过程,并且其数据可由一个或多个信息源提供”。罗俊海等[2]结合自动控制相关理论定义数据融合为一种有效的方法,把不同来源和不同时间点的信息自动或半自动地转化成一种形式,这种形式为人类提供有效支持或者做出自动决策。
与军事领域的数据融合相类似,环境监测网络数据融合充分利用不同时间与空间的数据资源,主要有各类传感器系统,如电化学、光敏、生物、激光、压力、温湿度、震动、位移等传感器系统,也包括环境观测信息获取系统,如遥感影像、气象条件、GIS、监测模型、数据库等信息系统以及生物感知、经验判断等,采用计算机技术对一定准则下(如时间序列、空间分布等)获得的环境监测数据进行分析、综合、支配和使用的过程,进而获得与被测对象一致性解释与描述,最终实现科学的决策和估计。多种信息源为数据融合处理提供了必要条件,使系统获得比它的各组成部分更充分的信息[3-5]。
1.2 数据融合的意义
环境监测网络运行主要依托于无线传感器网络(WSNs)技术,而WSNs存在大量传感器节点,且单位传感器节点电池电量、处理能力、存储容量、通信带宽等方面资源有限,网络不间断运行势必会造成潜在的冲突和数据冗余传输,导致部分传感器节点寿命缩短,网络整体性能降低[6-8]。数据融合作为解决WSNs中资源限制的关键技术,通过融合来自不同信息源的数据,去除冗余信息、减小数据传输量,从而达到节省能量、延长监测网络生命周期、提高数据准确性的目的[9]。因此,为增强网络运行效能,延长网络寿命,在数据传输过程中,首先应当减少通信需求,将传感器数据进行融合处理,发送融合后的结果,能有效减少消息数量、避免网络冲突并节约能量[10-11]。
1.3 数据融合的级别
根据对输入信息的抽象或融合输出结果的不同,各国学者和研究机构先后提出了多种数据融合的功能模型,将数据融合分为不同的级别。JDL模型[12-15]源于在军事领域的应用,并基于数据的输入和输出将融合过程分为对象、状态、影响、优化4个递进的抽象层级。Kokar等[16]在JDL模型基础上提出了一个较为完善的数据融合框架,包括数据融合、特征融合、决策融合、关系信息融合,体现了多源数据处理的过程和能力,为数据融合系统的标准化和自动化发展应用明确了方向。根据环境监测WSNs自身特点,数据融合可根据传感器节点处理层次、融合前后的数据信息量、信息抽象层次的不同而划分为不同的型式[17]。
环境监测网络数据融合实现了数据源和数据应用的衔接,其数据源通常具备结构化的数据特征,按照数据获取-传输-应用的处理流程,可将环境监测数据融合分为数据级数据融合、特征级数据融合和决策级数据融合[18-20],数据融合结构见图1。三级模型的综合应用,能够在获取大量现场监测数据的同时,通过数据的预处理减少数据传输带宽要求,降低通信容量,并根据实际需求,调整网络资源开展预测估计和精细处理等。
2 数据融合方法
2.1 数据级融合
数据级融合属于底层融合过程,即在数据采集层上对原始监测数据进行融合分析,通过特征提取和特征选择传输有价值信息。环境监测网络运行所产生的原始数据主要包括:大气、水、土壤、噪声等环境要素和污染源自动和手工监测的结果,各种监测仪器设备运行时所产生的运行记录和仪器参数;各类环境质量监测及污染源监测点位信息;与环境监测数据相关的气象、水文信息和遥感影像等[21-22]。

图1 数据融合结构Fig.1 Structures of Data Fusion
数据级融合在环境监测网络中应用广泛,融合对象通常为结构化数据。如大气环境监测网络每个站点的监测设备能够实时监测PM10、PM2.5、NO2、O3、SO2、CO浓度和站点环境信息,并将全部监测数据和仪器设备运行信息存储在本地数据库中,而各监测站点向数据的应用层(即环境监测主管部门管理系统平台)发送5 min监测数据的算数平均值。发送的数据信息并不是监测设备实时测量所得,而是通过简单的算术平均计算而来,这一过程依靠数量巨大的传感器采集信息,并按照网络功能筛选传输数据,能够消除大量的冗余数据,有效降低数据传输带宽需求,但由于站点较多,地理分布广泛,存在融合计算量大、耗时较长、实时性差的缺点。加权平均[23-25]、卡尔曼滤波[26-27]等是进行原始数据处理、提升网络传输效率的常用方法。
2.1.1 加权平均
加权平均是环境监测数据处理过程中最常见的方法之一,包括算术加权平均、几何加权平均和平方加权平均。在环境监测网络进行数据级融合时,最常用到算术加权平均,即对不同的监测指标和数据信息赋予不同的权重后计算其平均值的方法,计算公式:
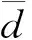
2.1.2 卡尔曼滤波
卡尔曼滤波(KF)主要用于处理数据层中实时动态多传感器数据冗余及失真问题。在实际监测过程中, 常因重复监测、数据传输中断、监测设备维修更换、人为因素造成数据失真,导致数据冗余、数据不完整、数据缺失和不等间隔采样的问题,已有的处理方法是进行简单的剔除、抽样或插值计算等,可以解决一部分数据丢失和数据冗余带来的影响[32-34]。而在对环境监测网络的某些关键节点进行数据分析时,由于特定时间段内样本数据量有限,或数据特征明显等原因,无法对缺失数据进行省略或替代,若数据序列中缺失数据比例较大或连续缺失点较多时, 传统的剔除、抽样等方法就难以取得可靠的结果[35-36]。
针对数据异常问题,为进一步减少过程噪声和测量噪声对监测数据的影响,提高环境监测网络的传输数据精度,基于KF的数据融合方法越来越多地被应用到研究中[37-40]。在颗粒物在线监测过程中,由于持续大流量采样,高速运动的气流会使滤膜受到一定的压力波动,对颗粒物的测量精度造成影响。卢志浩等[41]将颗粒物采样称重过程抽象描述为一个线性离散控制过程,通过KF算法补偿了压力波动对称重模块的影响,剔除了由于称重采集器不稳定和外界因素影响导致的异常数据,有效提高了颗粒物称重准确度。唐晓等[42]基于集合KF方法建立了京津冀区域空气质量资料同化系统,开展臭氧观测资料的同化实验,综合考虑NOx和VOCs排放源、垂直扩散系数以及NO2光解系数的误差,有效减小预报过程中臭氧初始场的误差。
2.2 特征级数据融合
特征级数据融合属于中级融合过程,通常作用于系统的网络层和数据层。在环境监测网络中,从数据层中提取原始信息的目标特征,提取的特征信息应是原始信息的充分表示量或充分统计量,然后按特征信息对多源数据进行分类、聚集和综合,产生特征矢量,采用一些基于特征级融合方法处理这些特征矢量,并进行属性说明。环境监测网络用户端操作平台所显示的信息主要是对网络层输出的数据进行特征级融合之后的结果,这些信息可以是结构化的,如描述生态环境状况和污染排放的数据,包括AQI、WQI、污染物平均浓度、优良天数等,超标倍数、排放总量等;也可以是非结构化的,如地理信息、图片影像及与人群活动相关的环境信息,包括GIS数据、视频监控、遥感影像、设备概况、方法标准以及各类环境质量报告等。目前,随着计算机技术、信息技术的快速发展,为进一步挖掘环境监测网络数据价值,人工智能的方法越来越多地被应用到环境监测网络数据融合过程中。
人工智能是以计算机技术、信息技术为理论基础,结合各领域研究方向,模拟人类思维方式解决问题的技术科学。在环境监测网络数据融合前沿技术研究中,人工神经网络[43-45]、遗传算法[46-47]、支持向量机[48-49]是3类最常用的人工智能方法。
2.2.1 人工神经网络
人工神经网络(ANNs)是一种模仿人脑结构、能够并行处理数据的信息系统(见图2,x1,x2,…,xn为网络的输入向量;wij、wki为各层级间的权值;αi、βk为神经元的阈值;y1,…,ym为网络的输出向量),具有较强的自适应、自组织、自学习能力,在污染物组分研究、数值预测与环境评价中广泛应用[50-52]。

图2 人工神经网络结构Fig.2 Structure of ANNs
同一层级中的神经元无关联,其传递函数是连续可微的非线性函数,通常采用S形的对数或正切函数,如logsig函数和logsig函数。而层与层之间的神经元通过权值(wij、wki)和阈值(αi、βk)连接,阈值的取值范围通常为(-1,1)。
SANTOS等[53]对法国北部Dunkerque城大气颗粒物中重金属的组分进行研究,通过连续3个月对 PM10的采样分析,运用ANNs和主成分分析法构建数据预测模型,较好地估算了颗粒物中铅、镍、锰、钒的平均浓度,并且其模型已经被欧盟采纳作为空气中金属组分评价技术。琚振闯等[54]针对黄河含沙量大、水环境动力学条件复杂等特性以及水质预测工作复杂、模糊、高度非线性的特征,设计了采用L-M数值优化算法的3层BP神经网络,利用黄河内蒙古河段上游3个监测断面监测数据对下游1个断面的COD进行预测,实验结果预测精度较高,能够为地表水水质监测和污染控制提供技术支撑。AMANOLLAHI等[55]利用Landsat-8卫星中的陆地成像仪(OLI)遥感数据对伊朗Zarivar湖水质类别进行评价,分别采用ANNs和线性回评价模型,实测结果表明,ANNs模型估计总悬浮物、总溶解固体、浊度和叶绿素a等平均浓度误差较小,相关性较高。
2.2.2 遗传算法

2.2.3 支持向量机
支持向量机(SVM)属于有监督的学习模型,通常用来进行模式识别、分类以及回归分析,主要通过非线性映射将输入量映射到高维空间,然后在高维空间中利用线性函数进行回归运算,从而得到原空间的回归效果,具有较好的非线性拟合功能和较快的计算速度。郭飞等[59]提出了一种基于改进变精度粗糙集的SVM预测方法,采用熵权值理论对SVM输入变量预处理,并利用2016年沈阳市气象数据对同期AQI进行预测,实验预测准确率77.83%,空报率和漏报率明显下降。王平等[60]将PM10浓度预测过程描述为一个易受排放源、气象数据、地形特征、相关污染物浓度影响的非线性动态系统,并建立了wavelet-SVM 模型对太原市PM10时空分布特点进行分析,实验结果表明,SVM预测模型作为高维非线性学习算法用于PM10浓度时序数据预测精度较高。
2.3 决策级数据融合
决策级数据融合属于高层融合过程,其优点在于对信息传输带宽要求低、通信容量小、抗干扰能力强,涉及态势认识与评估、影响评估、融合过程优化以及最优决策等。在环境监测网络中,决策级数据融合是从具体环境问题的需求出发,充分利用特征融合所提取的监测对象的各类特征信息,采用适当的融合技术进行定性、定量描述或进行管理决策支持的过程,其结果直接为管理、控制、决策提供依据。目前,在环境监测网络决策级数据融合前沿技术研究中,贝叶斯网络[61-62]、专家系统[63-64]、证据理论[65-66]等应用广泛。
2.3.1 贝叶斯网络
贝叶斯网络(BN)是一种概率关系的图像描述,利用定性与定量分析相结合的方法来表达实际应用系统中变量间的不确定关系,目的是使多个管理目标达到最优,适用于解决环境管理中具有不确定性的多目标决策问题,如环境空气质量预报、水环境管理决策等。王勤耕等[67]分析了城市空气环境质量潜势预报、统计预报、数值预报的特征,针对城市大气环境的复杂巨系统特征和不确定性,提出一种基于BN的城市大气污染预报系统,以气象要素、环境特征、污染源资料、污染状态等为输入变量,输出污染物浓度和污染发生概率,兼具多源信息融合、概率预报、高实效性、组网灵活的特点。王明芳等[68]利用BN在不确定性表示、推理方面的优势,结合多传感器数据融合技术,研究了室内空气质量识别评级模型,实验证明模型算法准确直观。
水环境管理决策是典型的动态复杂系统,其不确定性通常表现在自然环境因素(气温、降水等)和自身的水文条件(流速、流态、流量等)具有随机性,生活污水及生产废水的排放规律随经济社会发展波动变化,污染物在水体中的扩散、稀释、分解、沉淀及在物理、化学、生物作用下的降解也存在不确定性变异的特征。运用BN能够针对水环境管理中的不确定问题提供解决思路。卢文喜等[69]将BN引入水资源管理中,以水体硝酸盐浓度下降和周边农民收入增加为目标变量,以政府补偿款范围为决策变量,以作物类型、农药用量、农业收入为状态变量,建立BN模型,为管理决策提供支持。为应对突发水环境污染事件,杨海东等[70]用BN进行突发水污染溯源,推导出污染源强度、位置和排放时刻等未知参数的后验概率密度函数,并结合微分进化和蒙特卡罗模拟方法对后验概率分布进行采样,进而估计出这些未知参数,确定污染源项,为解决突发水污染事件中的追踪溯源难点问题提供了新的思路和方法。
2.3.2 专家系统
专家系统(ES)是一种以专家经验、知识等为基础,根据某一领域一个或多个专家提供的经验和专业知识,提取生成专家规则,通过人机交互界面输入事实信息,并与专家规则进行匹配,通过计算机程序实现推理判断。王欣等[71]归纳分析了东北地区饮用水处理工艺,设计了饮用水处理技术ES,实现了工艺查询、技术更新、水质判定等功能。韩小铮等[72]针对我国环境应急体系技术支撑薄弱、技术指南欠缺等问题,将规则推理(RBR)和案例推理(CBR)的ES应用于环境污染事故应急处理决策,通过CBR式推理得到与现行案例类似的既往案例,同时RBR式推理相关危险化学品MSDS信息和应急处理步骤,为环境污染应急监测提供技术支持。
2.3.3 D-S证据理论
Dempster-Shafer 证据理论(D-S证据理论),最早应用于ES中,是一种多源信息融合方法,具有处理不确定信息的能力。D-S证据理论是对贝叶斯推理方法的推广,主要适用于信息融合、专家系统、情报分析、多属性决策分析等[73-74]。D-S证据理论可用于环境监测网络安全态势评估,网络异常检测,数据异常监测[75-76],以及环境信息融合、网络舆情评估等方面[77]。
3 问题和建议
3.1 面临的问题
环境监测网络数据融合技术近年来发展迅猛,但多数技术仍未应用到管理实际中,主要存在以下问题:
一是数据处理技术不成熟,主要包括:数据缺陷,监测过程受测量噪声影响,或仪器运行不稳定导致数据缺失,现有优化算法只能针对特定区域、特定特征的测量噪声予以识别和剔除,难以满足全网络数据采集优化需求;数据冲突,实际环境的模糊性和不一致性会导致数据冲突(如PM2.5、PM10监测数据倒挂等),现有的算法可以识别但难以分类处理违反常理的结果;网络结构,集中式数据处理流程产生过多的冗余信息,给网络数据传输带来较大压力,对于分布式数据处理使用较少,忽略了单一站点的监测信息。
二是基于数据融合的环境质量评价体系不完善,包括:基础评价指标较少,历史数据不全,导致评价结果往往难以全面、客观、真实的反应环境质量现状,影响监测数据的多元化应用和相关决策支持;标准化程度较低,环境监测网络目前收集并分析的均为相同类别数据,而对图像、影像、人类听觉、视觉、触觉测量等异质信息无法纳入统一的评价体系;充分运用海量监测数据对环境质量趋势研判、重点区域流域环境风险预警和环境污染追因溯源能力仍不足。
三是环境监测数据质量有待提高,主要包括:针对海量监测数据的质控手段较少,难以实时监控并及时修正每个监测站点数据采集过程中的问题;影响监测数据质量的因素较多,仅通过例行检查和飞行检查等手段,难以掌握全部问题;以监测人员为主体的现场质控模式难以满足全网络、大范围的质控管理需求。
3.2 建议
随着环境监测网络结构不断优化、技术不断创新,监测数据多元、复杂、庞大、实时的特征逐渐凸显,环境监测网络也会向分布式处理、多元化分析、智能化决策的方向发展。从数据发展和应用的角度来看,将环境监测网络数据融合充分应用于实际工作的建议如下:
1)提升数据采集效率,提升原始监测数据采集效率和准确度,按实际需求对环境信息进行识别分类和预测评价,规避单一传感器或站点故障产生的误差,实时记录仪器运行参数,自动识别失真数据,提高监测数据质量。
2)优化监测网络结构,将监测数据由集中式存储转为分布式存储,提升网络可靠性和信息处理效率,增设区域数据传输节点,加强单一站点和固定区域的监测数据使用率。
3)推进监测数据公开,建设环境监测大数据平台,统一方法标准和数据格式,实现各级各类监测数据互联互通,通过终端软件、新媒体等形式发布环境质量信息并收集个人感官数据,真实、准确、全面、客观评价环境质量。
4)强化数据综合分析,培养数据分析人才,着力提升监测数据综合集成、深度挖掘、智能分析、模型应用等方面能力。
5)提升决策支持能力,依托各类数据分析模型、算法,建立统一的环境质量综合评价指标体系,充分运用BN、ES、证据理论等决策方法,为环境管理决策提供可量化、可追溯的方案。
6)保障监测数据质量,通过分析现有的监测数据,归纳总结影响监测数据或导致数据失真的数据特征,降低检查成本,提升质控效率。
4 结论
按照环境监测网络的信息处理流程,归纳了数据、特征、决策3层数据融合级别。数据级融合适用于环境监测网络原始数据处理,实现冗余数据剔除、特征提取、网络优化等功能。加权平均法使用广泛,能有效降低数据传输量,节约网络资源,并体现各个监测指标的权重。KF在环境监测中尚处于研究阶段,主要用于识别并剔除异常数据,解决数据缺失和信息失真等问题。特征级数据融合结合人工智能技术可进行复杂条件下的环境质量评价和污染物浓度预测。ANNs络属于深度学习模型,适用于大数据分析,但模型训练依赖大量样本数据。SVM基于统计学习理论,在污染物浓度预测研究中具有良好的泛化能力,但预测结果精确度受输入变量的影响较大。GA具有高效启发式搜索、并行计算等特点,可用于函数组合优化,提升系统运行效率;决策级数据融合的协同应用创新能够实现环境监测数据的多元化应用,反映环境质量和污染状况以及生态系统格局、结构、功能、胁迫等状况。BN和D-S证据理论适用于环境污染应急管理决策、污染源清单调查和环境风险防控等。ES结合知识库和推理机,在环境监测领域的应用不断扩大。
数据融合技术在环境监测领域中应用并取得了很多成果,但仍没有一种融合方法能满足环境监测网络的全部需求。因此,充分考虑环境监测网络结构、监测数据特征和环境管理需求的数据融合技术具有很大的研究空间。针对实际应用不断优化网络结构,合理分配数据资源,多领域技术交叉协同,才能助力实现科学监测、智慧环保的目标。
猜你喜欢
今日农业(2021年19期)2022-01-12
中老年保健(2021年11期)2021-08-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
现代出版(2020年3期)2020-06-20
电子制作(2019年19期)2019-11-23
铁道通信信号(2019年11期)2019-05-21
中国资源综合利用(2017年4期)2018-01-22
中国资源综合利用(2017年4期)2018-01-22
中国环境监测(2017年6期)2018-01-15
振动工程学报(2015年1期)2015-03-01
