
基于大数据平台的电力负荷预测
2018-10-24 04:39刘南艳贺敏赵建文
现代电子技术 2018年20期
刘南艳 贺敏 赵建文
摘 要: 电力行业是大数据应用的重要领域之一,电力系统每时每刻都在产生大规模、种类繁多的电力数据,面对海量数据,该如何将它们高效的处理和存储,并进行有效开发利用十分关键。因此,研究基于Hadoop云计算平台海量数据下的电力负荷预测方法,并在MapReduce编程框架的基础下,将K?Means算法进行改良和优化。实验结果表明,提出的方法是可行的,数据处理时间大大缩短,算法精度也能满足负荷预测的要求。
关键词: 大数据; Hadoop; 云计算; Mapreduce; 电力系统; 电力负荷预测
中图分类号: TN915.853?34; TP391 文献标识码: A 文章编号: 1004?373X(2018)20?0153?04
Abstract: Electric power industry is one of the most important fields of big data application. The power system is producing a great variety of large?scale electric power data all the time, and how to effectively process, store, develop and utilize the massive data is very important. Therefore, a power load prediction method based on massive data is researched using the Hadoop cloud computing platform. The K?Means algorithm is improved and optimized on the basics of the Mapreduce programming framework. The experimental results show that, the proposed method is feasible, has greatly?reduced data processing time, and its algorithm accuracy can meet the load prediction requirement.
Keywords: big data; Hadoop; cloud computing; Mapreduce; power system; power load prediction
0 引 言
随着电网建设速度的加快、规模的不断扩大、要求的不断提高,电网系统需要具有强大的数据分析和数据处理能力,这样才能保证电网的安全运行[1?2]。但是当前电力系统对数据的分析和处理所采用的是集中式的计算平台,这样的平台在面对海量数据时,如按常规系统10 000个遥测点,采样间隔3~4 s计算,每年能产生1.03 TB的数据,就会出现数据的储存和计算问题,并且它的扩展性能比较差[3]。本文采用Hadoop云计算平台,通过搭建完全分布式集群,在多个节点上对数据进行计算和处理,可以极大地提升数据处理效率。
多年来,电力负荷预测的方法不断出现,例如时间序列法、趋势外推法、神经网络、线性回归、小波分析法等。但这些方法仍然存在局限性。神经网络法很难避免在训练过程中的学习不足且收敛过慢[4];时间序列法对历史数据准确性要求高,短期电力负荷预测时对天气因素不敏感,难以解决因气象条件、区域等因素造成的短期负荷预测不准确问题。
本文采用某地区的电力负荷数据作为基础。将K?Means聚类算法与云计算平台的MapReduce框架结合对电力负荷进行研究。此方案首先将大量的数据进行标记并产生键值对,然后分配多个节点并同时对数据进行处理和分析,最后将结果合并,这个过程大大提升了数据处理的效率。
1 基于Hadoop平台的K?Means聚类算法
1.1 传统的K?Means聚类算法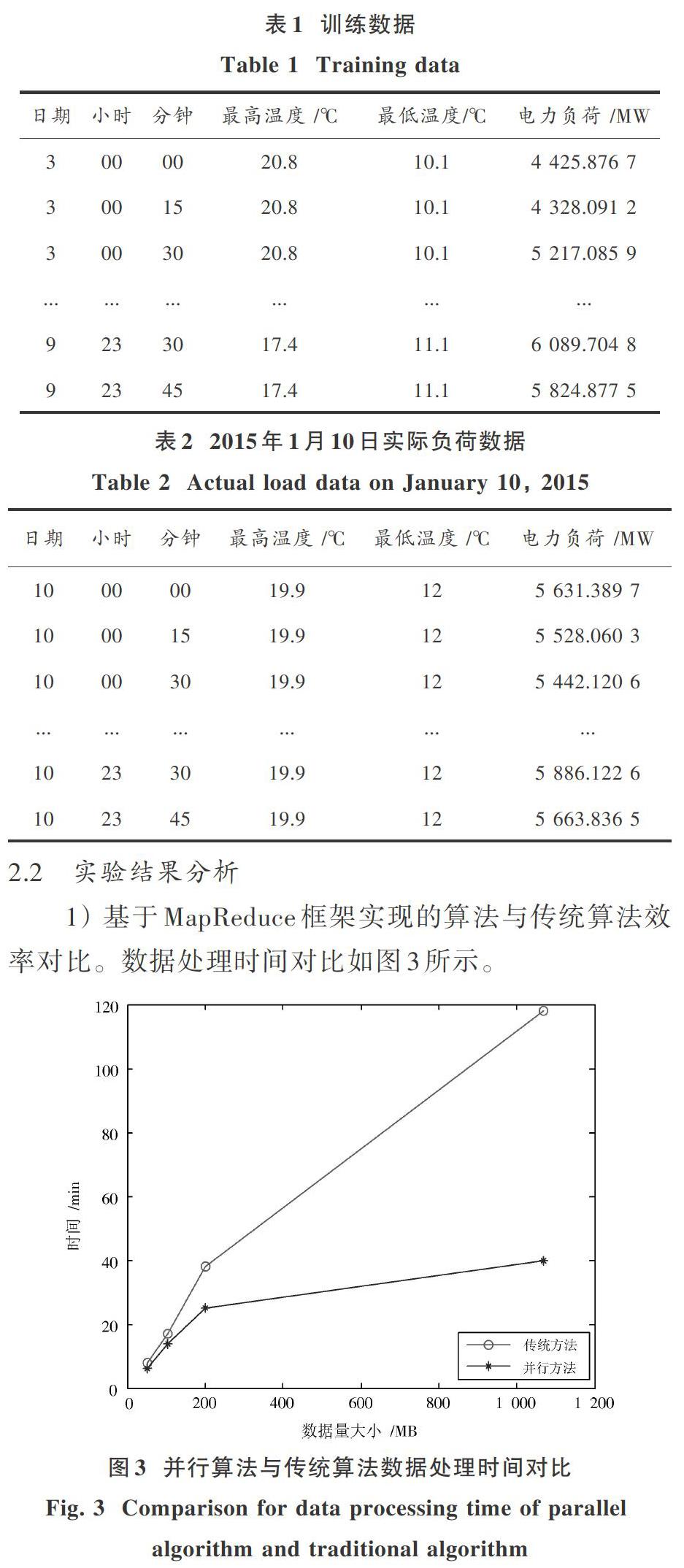
传统K均值算法(K?Means Algorithm)的基本流程为:作为一种基于划分的聚类算法,K?Means算法首先从原始目标集合中选取K个点作为初始的K个簇的中心;随后再将每个点指派到离该点最近的簇中心;最后,当所有的点都被划归到一个簇后,对簇中心进行更新;不断重复这样的过程直到簇中心收敛或者其他收敛条件满足(通常为迭代次数)。
有两个方面问题需要考虑:一是距离度量,也就是如何衡量两个数据点之间的距离;二是簇中心的表示问题。在首次迭代中通常随机抽取K个原始数据点作为最初的K个簇中心,而后续的迭代通常通过取属于一个簇的所有点的平均值作为新的簇中心。例如将6个点分为2个簇过程如图1所示。
通过对传统K?Means算法的研究可以发现,在面对少量数据时,该算法可以高效精准的完成预测;而面对海量的数据时,需要进行距离度量的数据集会变得非常大,从而影响簇中心的判断,数据处理效率低[5]。此时将K?Means算法与Hadoop平台的MapReduce编程框架相结合来实现研究。
1.2 基于Hadoop平台的K?Means聚类算法设计实现
1.2.1 MapReduce并行编程模型
MapReduce利用函数式编程中映射(map)和规约(reduce)的思想,将所有的输入/输出数据都以(key,value)键值对的形式来表示。本文一次MapReduce计算的完成由三个阶段构成:Map阶段、Shuffle阶段和Reduce阶段[6]。并行编程模型如图2所示。
1) Map阶段。函数从输入流中读取一组数据,随后对该数据进行过滤和转换,生成一组中间键值对(key,value)[7],然后将生成的结果传入MapReduce系统框架中。
2) Shuffle阶段。在Shuffle阶段,MapReduce系统框架整理全部的中间结果键值对并进行合并,相同的键值对会归为同一类。
3) Reduce阶段。Reduce函数首先将合并后的键值通过算法进行处理,找到簇中心点,将该结果传递到分布式文件系统HDFS中,进行下一次迭代直到簇中心不再变化或者迭代次数已到[8]。
1.2.2 基于MapReduce框架的K?Means聚类算法
K?Means算法在MapReduce框架上实现主要分成2个步骤。
1) 将原始数据导入,并在数据集合中随机选取K个点作为初始簇中心。同时需先定义一个类,该类保存一个簇的基本信息。定义之后需要随机抽取K个点作为初始的簇中心。选取过程为,初始化簇中心集合为空,然后扫描整个数据集。当前簇中心集合大小小于K,则将扫描到的点加入到簇中心集合中,否则以[1K+1]的概率替换掉簇中心集合中的一点。
2) 把存储在本地的数据集合在Map节点上使用以上方法生成聚类集合,然后在Reduce阶段生成新的全局聚类中心。
① Map方法的实现。Map方法需要将每个传入的数据进行处理,并找到离其最近的簇中心,同时将簇中的id作为键,该数据点作为值发射出去,表示这个数据点属于id所在的簇。
② Reduce的实现。此过程是将多次迭代逐步逼近最终聚类中心的过程,同时重复此过程直到所求的聚类中心不再发生变化为止。
2 负荷预测实验及结果分析
2.1 实验数据
本实验数据来源于地区1从2009年1月1日—2015年1月10日的电力负荷数据(每15 min一个采样点,每日96点,量纲为MW),以及2012年1月1日—2015年1月17日的气象因素数据(日最高温度、日最低温度、日平均温度、日相对湿度以及日降雨量)。选取2015年1月3日—2015年1月9日作为训练数据,如表1所示。
在对该地区进行电力负荷预测时,考虑了地区温度等天气因素。通过最终实验结果来分析温度等因素对电力负荷预测造成的影响,同时对后续的研究提供参考。2015年1月10日实际负荷数所如表2所示。
2.2 实验结果分析
1) 基于MapReduce框架实现的算法与传统算法效率对比。数据处理时间对比如图3所示。
从图3可以看出,当数据量较小时,传统方法与基于MapReduce框架实现的并行方法在数据处理时间上相差不大,并行方法速率只是略快于传统方法。然而随着数据集的不断扩大,并行方法在速率上明显快于传统方法。原因在于基于MapReduce框架实现的并行算法在处理数据时将大量数据分散给集群上的各个节点,多个节点同时对数据进行分析、计算和存储,从而提高效率。
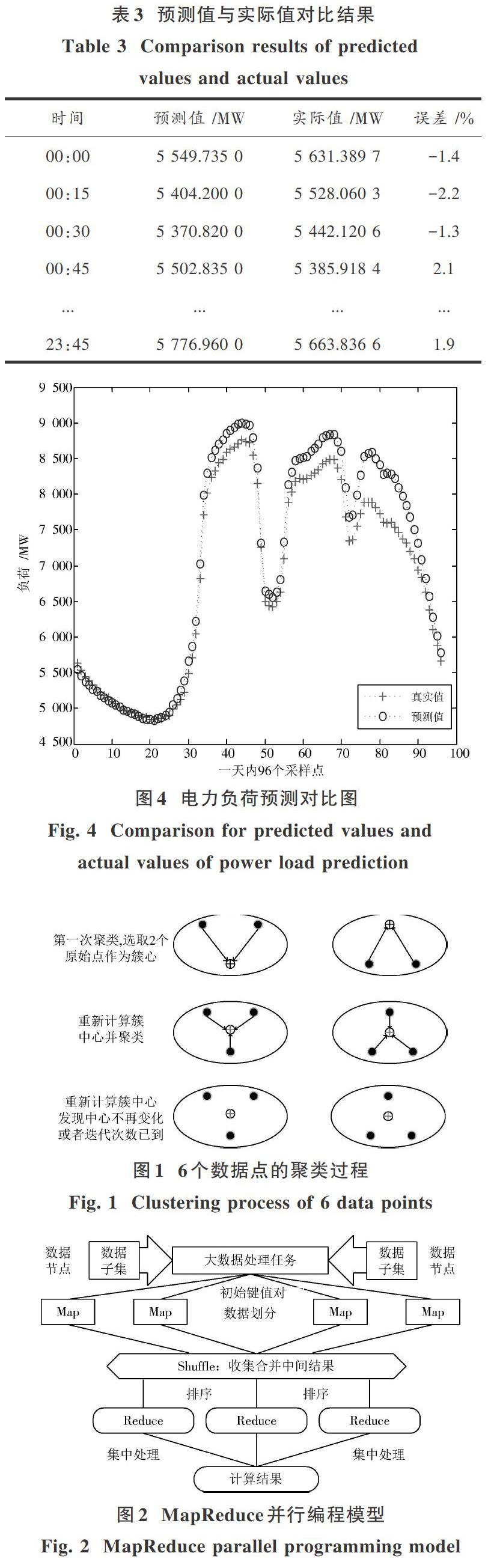
2) 预测实验结果。在应用MapReduce框架实现的算法得到1月10日电力负荷的预测值与实际值进行对比,并计算出误差。结果如表3所示,电力负荷数据精度基本满足电力负荷预测的要求。
通过图4可以看出,预测值与实际值相差不大,误差率基本上能保持在2.2%左右,在可以接受的范围之内。同时图4的趋势对比也比较平稳,展现了电力负荷在0~24时的变化趋势,符合1月10日负荷的变化情况。证明了基于MapReduce框架实现的K?Means聚类算法是可行的。
3 结 论
本文针对当前电力负荷数据量不断增长,大量数据的处理过程效率不高,耗费时间太长,以及电力负荷预测精度较低,得到的结果不能很好的计算和存储,研究了大数据在电力负荷预测方面的问题。通过在Hadoop平臺上搭建集群,将K?Means聚类算法在基于MapReduce框架上实现,提出了基于MapReduce编程框架的并行算法。由实验结果可得,集群的数据处理能够解决当前海量电力负荷数据的问题,提出的并行算法精度也能满足负荷预测的要求。
注:本文通讯作者为贺敏。
参考文献
[1] 刘鹏.云计算[M].2版.北京:电子工业出版社,2011.
LIU Peng. Cloud computing [M]. 2nd ed. Beijing: Publishing House of Electronics Industry, 2011.
[2] 李海龙.电力云数据分析平台数据挖掘算法的研究与应用[D].北京:华北电力大学,2014.
LI Hailong. Research on data mining algorithm in the electric power cloud data analysis platform [D]. Beijing: North China Electric Power University, 2014.
[3] PANDEY A S, SINGH D, SINHA S K. Intelligent hybrid wavelet models for short?term load forecasting [J]. IEEE transactions on power systems, 2010, 25(3): 1266?1273.
[4] 张素香,赵丙镇,王风雨,等.海量数据下的电力负荷短期预测[J].中国电机工程学报,2015,35(1):37?42.
ZHANG Suxiang, ZHAO Bingzhen, WANG Fengyu, et al. Short?term power load forecasting based on big data [J]. Proceedings of the CSEE, 2015, 35(1): 37?42.
[5] 孟祥萍,周来,王晖,等.基于Hadoop云平台的智能电网MapReduce数据计算技术研究[J].电测与仪表,2015,52(10):66?72.
MENG Xiangping, ZHOU Lai, WANG Hui, et al. Research on data computing technologies of MapReduce for smart grid based on Hadoop cloud platform [J]. Electrical measurement & instrumentation, 2015, 52(10): 66?72.
[6] 杨佳驹.基于MapReduce和深度学习的负荷分析与预测[D].南京:东南大学,2016.
YANG Jiaju. Load analysis and prediction based on MapReduce and depth learning [D]. Nanjing: Southeast University, 2016.
[7] 岳阳,张晓佳,高一丹.基于Hadoop的电力大数据技术体系研究[J].电力与能源,2015,36(1):16?20.
YUE Yang, ZHANG Xiaojia, GAO Yidan. Technology system of electric power big data based on Hadoop [J]. Power & energy, 2015, 36(1): 16?20.
[8] 党倩,崔亮,张华峰.基于MapReduce模型的智能电网数据平台研究[J].电力信息化,2012,10(5):96?100.
DANG Qian, CUI Liang, ZHANG Huafeng. Research on smart grid data platform based on MapReduce model [J]. Electric power information technology, 2012, 10(5): 96?100.
[9] 金鑫,李龙威,季佳男,等.基于大数据和优化神经网络短期电力负荷预测[J].通信学报,2016,37(z1):36?42.
JIN Xin, LI Longwei, JI Jianan, et al. Short?term power load forecasting based on big data and optimization neural network [J]. Journal on communications, 2016, 37(S1): 36?42.
[10] 高曦莹,张冶,扬爽,等.典型电力用户用电负荷特性分类技术的研究[J].沈阳工程学院学报(自然科学版),2013,9(4):323?325.
GAO Xiying, ZHANG Ye, YANG Shuang, et al. Technology research on typical electric power load characteristic classification [J]. Journal of Shenyang Institute of Engineering (Natural science), 2013, 9(4): 323?325.
[11] HONG W C. Chaotic particle swarm optimization algorithm in a support vector regression electric load forecasting model [J]. Energy conversion & management, 2009, 50(1): 105?117.
猜你喜欢
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
科技视界(2016年21期)2016-10-17
科技视界(2016年21期)2016-10-17
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
