
依赖弱化与冲突协作检测的数据质量保证算法
2018-10-24 02:27谢天年郝敬彬
计算机工程与设计 2018年10期
谢天年,郝敬彬
(1.玉林师范学院 外语学院,广西 玉林 537000;2.中国矿业大学 计算机科学与技术学院,江苏 徐州 221001)
0 引 言
在网络大数据通信中,数据的依赖关系[1]及其程度严重制约数据质量[2]的提升。同时,数据冲突[3]的动态演变[4]使得检测难度加大,导致数据质量下降,上述问题受到学术界和工业届的广泛关注。
文献[5]基于秩2校正规则的修正拟牛顿算法拟合多输出支持向量回归算法的模型参数,保证了模型迭代的全局收敛性。文献[6]研究了零开销系统软错误缓解中的数据依赖性和触发器不对称性。文献[7]提出了基于等价类的分布式环境多个函数依赖冲突检测的方法。文献[8]提出了一种可以克服金融数据依赖性的流水线市场数据处理体系结构。文献[9]研究了对数据质量的感知真理估计和移动群智剩余分享的设计方法。文献[10]基于时间戳,研究了群智系统数据质量评价的不确定性传播机制。T. Zhu等基于状态转换图及其关系矩阵,提出了交通状态预测和冲突检测机制[11]。文献[12]提出了一种基于实体属性和数据冲突的事实查找算法。
然而,现有的大数据网络系统难以实时捕捉数据依赖关系,对于数据冲突的检测与捕捉,也难以实现,从而使得数据质量难以得到保证。因此,通过上述的讨论与分析,本文从弱化网络大数据依赖关系,数据冲突的扩散与检测出发,提出了一种实时、可靠和有效地数据质量保证算法。
1 网络大数据依赖弱化机制
高密度覆盖的移动网络所采集的数据存在较高的冗余度,对于数据质量产生正负两方面的影响。因此,本节基于机会多维网描述网络大数据依赖关系。为了保持网的多维度与网络大数据的依赖关系的一致性,对移动网络的高性能服务系统的数据处理问题转换为机会多维网的映射出入度置换问题。
机会多维网中的每个节点表示一个网络大数据集合文件。该文件用于描述网络大数据流的基本信息及其数据依赖关系。网中每个节点的数据具有多维性,这些数据集合可在同一网的每个节点,甚至不同网的不同节点之间实现无缝数据转交。这种跨平台数据转交是网络大数据依赖性的抽象描述,如图1所示。
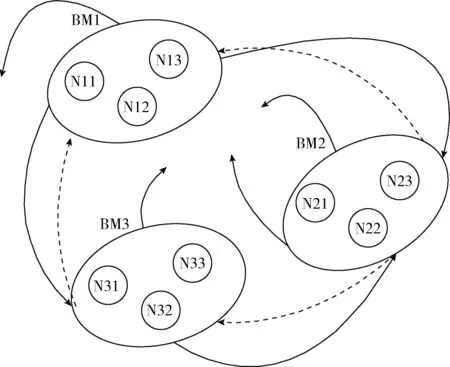
图1 机会多维网大数据架构
图1中,每个节点的大数据集合的描述包括以下基本元素:数据、数据类型、机会权重、维度和维度转换等。其中,机会权重和维度转换捕捉网中所有大数据的数据信息及其依赖关系。图1给出了3个异构机会多维网BM1,BM2和BM3。BM1网包含了节点N11,N12和N13,同理,BM2网包含了节点N21,N22和N23,BM3网包含了节点N31,N32和N33。图中实线箭头表示机会驱动权重趋势,虚线箭头表示可逆机会多维网融合。图2给出了BM1与BM2的节点内部以及不同网之间的映射关系和依赖趋势。
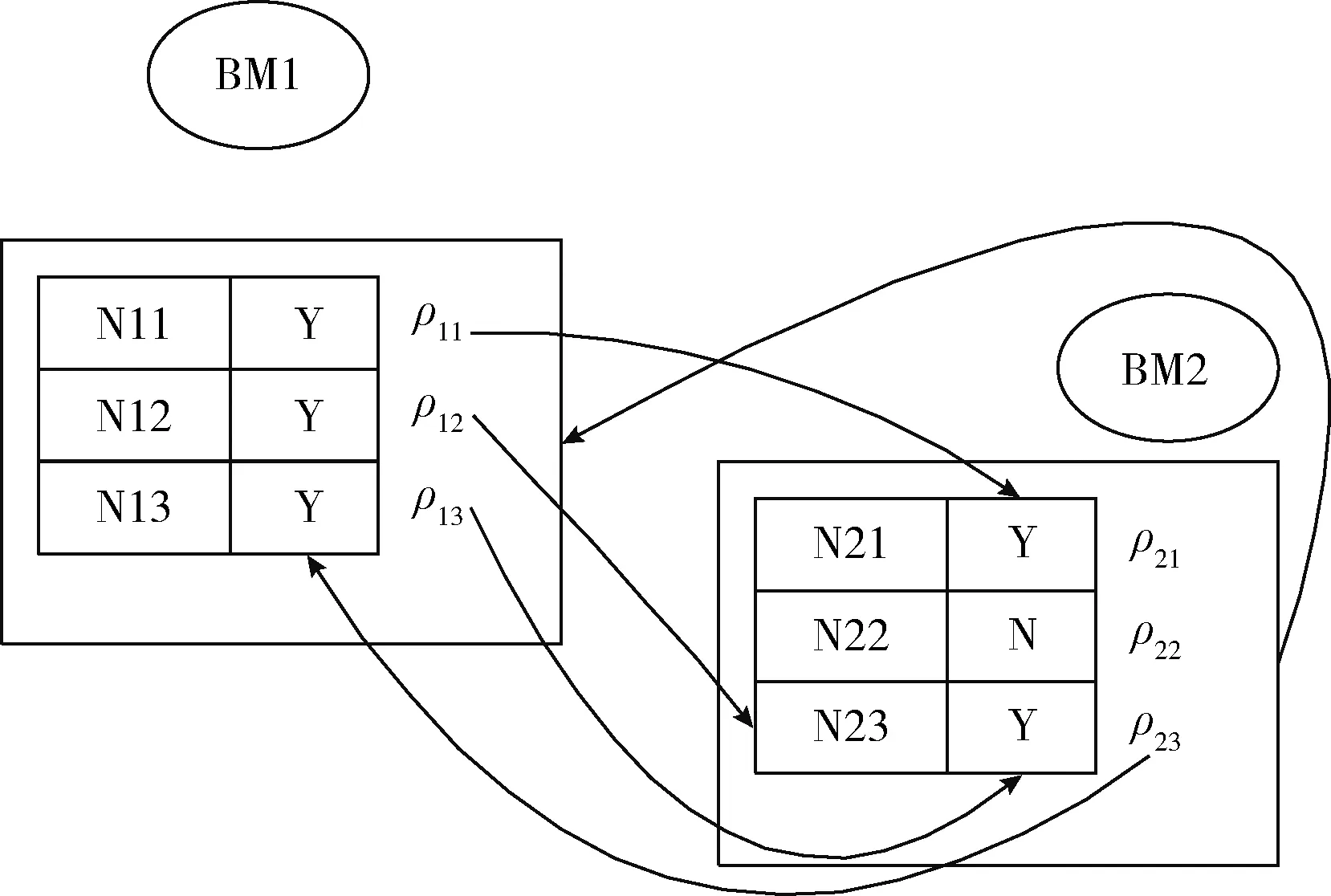
图2 数据依赖及其驱动关系
每个多维网向外有多个驱动方向和多个驱动权重。根据式(1)和式(2)判断数据依赖关系及其依赖程度H,按照式(3)和式(4)进行多维网的融合与分割
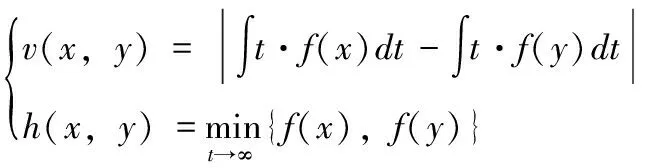
(1)
其中,函数f( )用于获取网络的数据信号。x表示节点接收的信号。y表示节点转发后的信号。t表示信号在网络中的传输时间。v(x,y)表示同一个多维网内节点转发数据的依赖关系。h(x,y)表示不同多维网的节点转发数据的依赖关系
(2)
其中,ρ表示机会驱动权重,M表示活跃节点数
(3)
式(3)将来自不同多维网的信号fi(x)与fj(y)进行融合,得到基于依赖关系H的网络大数据函数关系
(4)
式(4)通过机会多维网的信号转换,实现多维网的自适应分割,并得到分割后的信号。
基于图2所示的数据依赖关系,按照下述算法描述弱化网络大数据的依赖强度。
输入:大数据集合BM,节点数M,数据序列N
算法描述:
初始化BM向量;
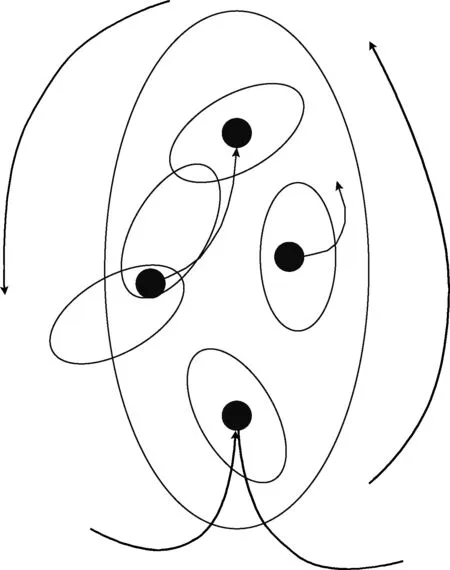
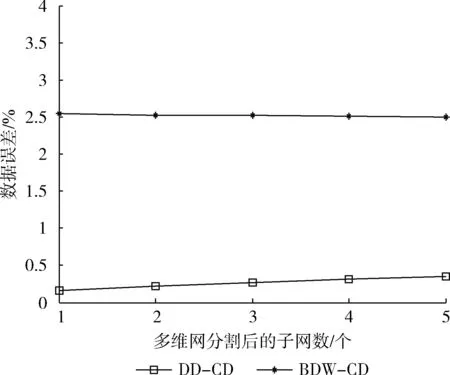
While(1 计算ρi; 求解M个节点之间的依赖强度; } While(1 根据节点属性和依赖关系分析BMj的机会趋势; 根据机会趋势确定数据依赖网; 基于ρ获得子网分割规模X; 分割BMj为X个子网; for(k=1,k 获得第k个子网的起始点坐标(x,y); 求得f(x)和f(y); 求得融合点f(x,y); 融合X个多维网; } } 网络大数据依赖弱化后,数据冲突的检测不能只考虑数据密度及数据间距。而是,将密度、间距与数据属性、数据误差和网络扩散方式相结合,基于多参数协作结合网络数据扩散区域及其拓扑结构,实现数据冲突协作检测。 采用协作检测方法获取网络大数据的多维网络拓扑及其机会依赖趋势,结合数据误差和属性,分析网络大数据的冲突区域及其数据集合。具体过程描述如下: (1)捕捉发生冲突的数据集合。 对来自多维网的大数据集合,检测大数据流与原始数据流的一致性,并记录出现不一致的数据流,同时捕捉这些数据及其冲突,详见式(5) (5) 其中,向量CN表示不一致数据集即发生冲突的数据集。向量CN表示可靠数据集即保持一致性的数据集。向量C表示捕捉了冲突的数据集。 (2)计算多维网发生冲突的数据间距及其依赖弱化。 对数据集向量C的任意元素Cd,设定该元素与向量中心元素的距离为(p-Lo(Cd)),函数L()表示数据元素的长度,参数p表示向量的数据距离均值,则Cd的数据冲突距离详见式(6),结合式(4)得到冲突检测后的数据依赖关系,如式(7)所示 (6) 其中,函数L(C)用于获取向量C中的任意元素 (7) (3)计算数据冲突的密度 (8) 式(8)可以求解数据冲突密度dc。其中Np-dd表示数据冲突的距离域。 (4)建立网络大数据冲突扩散模型 (9) 其中,NS表示数据冲突扩散的距离域,可以准确地获取数据冲突扩散范围。数据冲突扩散如图3所示,其中有4个不一致性数据点,分别处于不同的数据流。整个网络大数据依赖形成一个闭合的椭圆区域。其中,每个数据点按照依赖关系和强度,结合机会多维网拓扑,进行扩散,有助于协作冲突检测。 图3 数据冲突扩散的距离域演化 (10) 优化后得到的改进后数据向量BMI如下 采用实验统计与仿真实验相结合的方法,对所提出的数据质量改进算法在网络开销、算法执行效率和数据质量等方面进行对比。因为,所提算法采用了数据依赖弱化过程,在算法执行复杂度方面重点分析该过程所增加的空间复杂度和时间复杂度。所提算法在进行冲突检测时采用了基于数据密度、距离和属性等多参数相结合的协作算法,在算法网络开销性能分析中重点分析该过程是否增加了网络开销。网络环境参数详见表1。 表1 网络环境参数 为了更好地验证所提算法的性能,图4~图7分别给出了所提算法记为BDW-CD与基于数据依赖驱动的冲突检测算法记为DD-CD基于数据冲突发生概率、子网复杂度和数据发生规模的变化下的算法执行效率、网络开销和数据质量等方面的表现。 图4 算法执行效率 图5 网络开销 图6 基于数据发生规模的数据误差 图7 基于子网规模的数据误差 图4给出了两种算法的执行效率表现,综合了算法的时间复杂度和空间复杂度。横坐标是数据冲突发生概率。虽然,所提算法采用了数据依赖弱化机制,但该算法的空间复杂度增加很小,可以忽略不计,时间复杂度有所增加,但综合表现还是优于DD-CD。这是因为,DD-CD算法是以数据依赖关系进行驱动,这种驱动属于被动驱动,以增加时间复杂度为代价,实现冲突检测。而且,所提算法能够准确感知数据冲突发生概率,调度数据依赖关系弱化进度,在不增加算法复杂度的同时,准确捕捉发生冲突的数据,具有较高的执行效率。 网络开销的表现如图5所示,横坐标是多维网分割后的子网数,从1增加到5,步长为1。多维网分割后的子网数的变大,将会导致网络大数据传输复杂度的增加,路由控制难度有所增加,可以更好地验证算法的性能表现。对比发现,所提算法通过优化于数据密度、距离和属性等多参数相结合的协作算法执行流程,根据图3所示的数据冲突扩散的距离域进行实时演化,为不同的冲突数据点选择最佳的扩散趋势和执行方式。因此,网络开销不仅没有增加,反而有所降低。相比DD-CD算法,具有明显的优势。 图6和图7对比了两种算法的数据质量与实际数据之间的误差。其中,图6的横坐标是数据发生规模的变化即数据发生节点的变化从10到100,步长为10,逐步增加。图7的横坐标是多维网分割后的子网数,从1增加到5,步长为1。数据规模的增加,将增加网络控制难度,使得数据冲突发生概率线性增加,可以有效地验证算法的数据质量保证能力。从图6中可以看出,所提算法采用的协作检测方法,不仅可以实时获取网络大数据的多维网络拓扑及其机会依赖趋势,还具有结合数据误差和属性,分析网络大数据的冲突区域及其数据集合的能力。 网络数据通信过程中,因受到数据依赖性的干扰和数据冲突的制约,导致数据质量严重下降。针对上述数据依赖和冲突问题,提出了一种网络大数据依赖弱化与冲突协作检测的数据质量保证算法。一方面,设计了一种动态机会多维网,准确阐明了网络大数据的依赖关系,采用置换机会多维网的映射出入,实现网络大数据依赖的弱化。另一方面,采用包括密度、间距与数据属性、数据误差和网络扩散方式等多参数,基于协作控制捕捉数据冲突扩散区域,检测数据冲突及其趋势。仿真实验对比了所提算法与基于数据依赖驱动的冲突检测算法,结果表明在算法执行效率、网络开销和数据质量等方面,所提算法具有明显优势。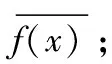
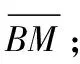
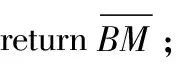
2 冲突协作检测的数据质量改进
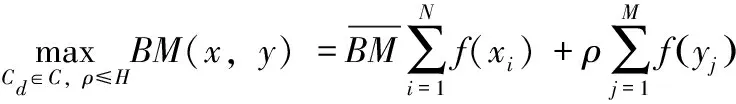
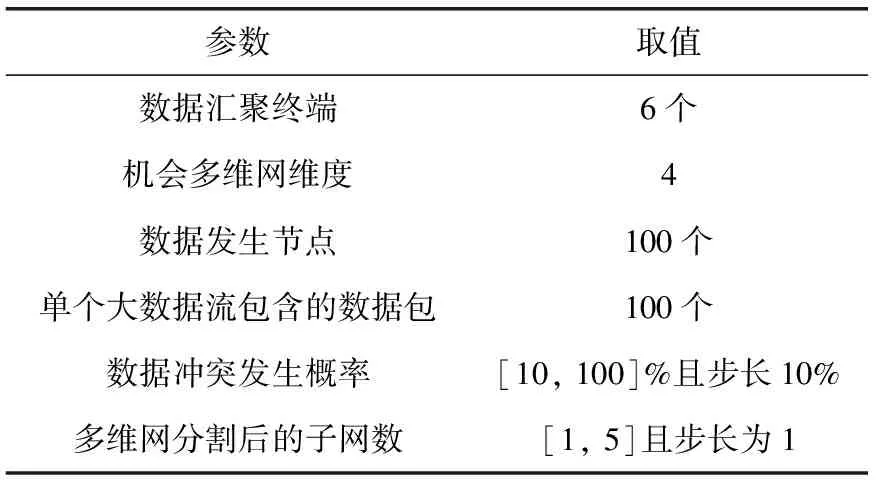
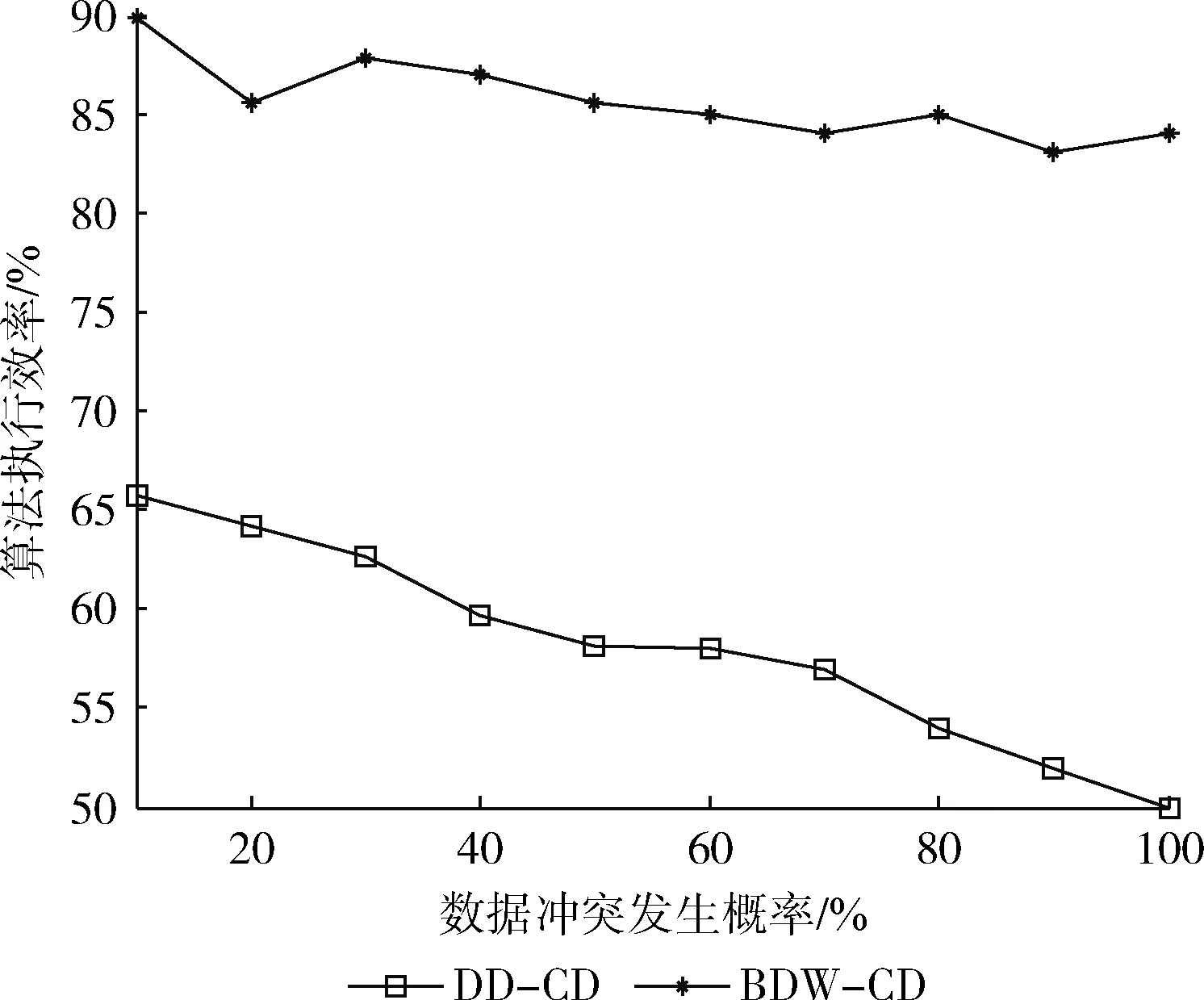
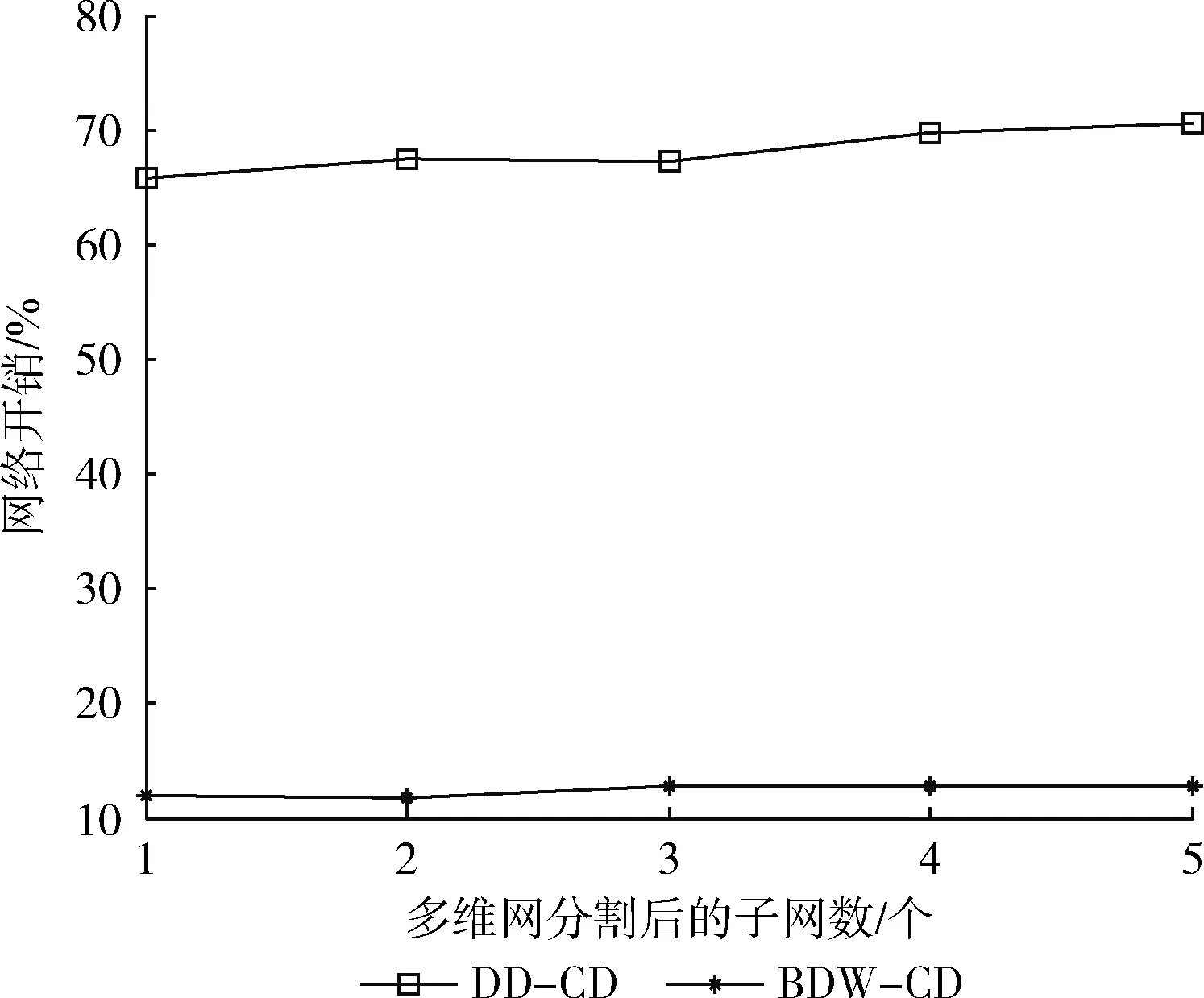
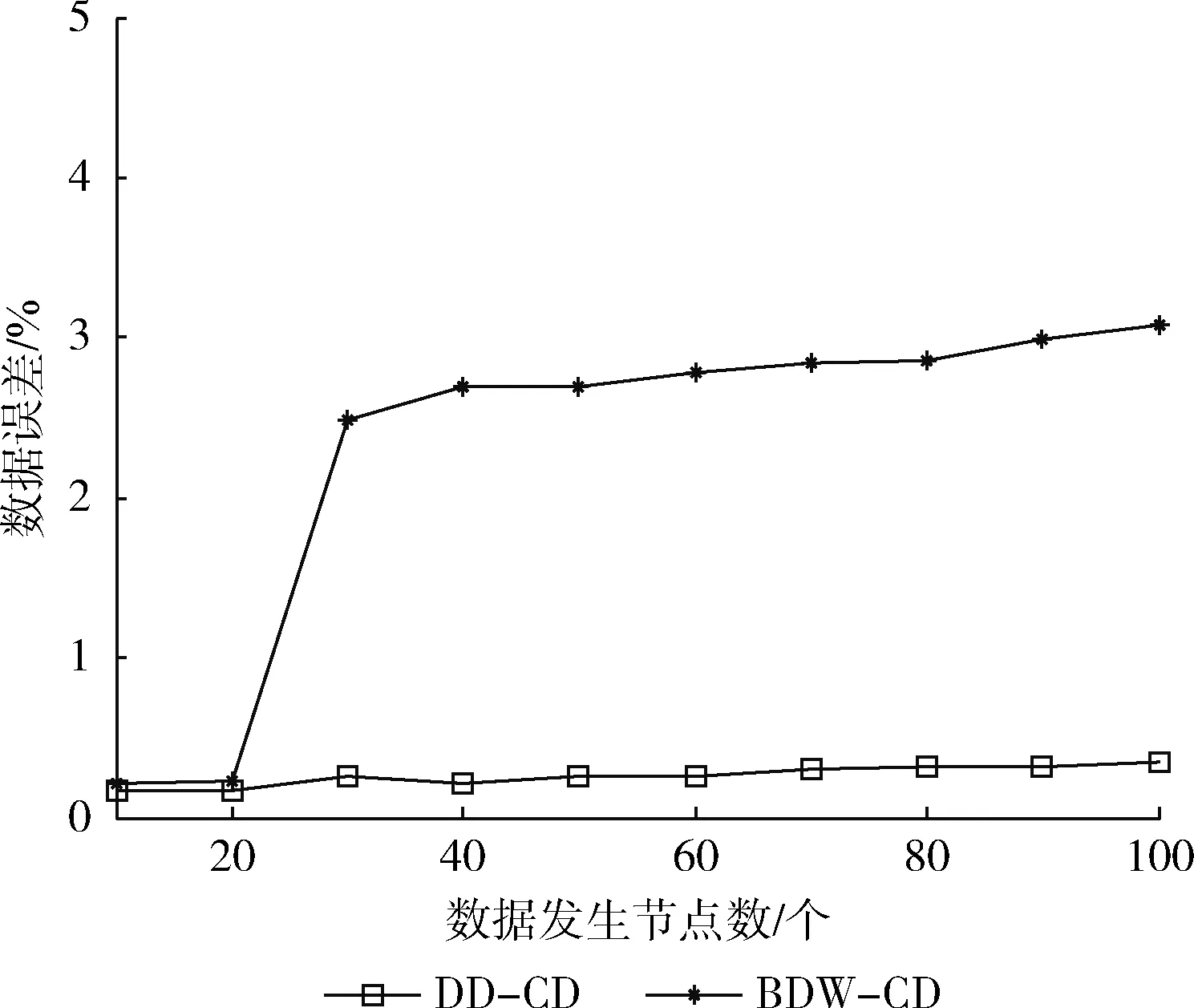
3 实验结果分析
4 结束语
猜你喜欢
环球时报(2022-04-16)2022-04-16井冈教育(2020年6期)2020-12-14中国惯性技术学报(2019年6期)2019-03-04现代园艺(2017年23期)2018-01-18中央民族大学学报(自然科学版)(2017年2期)2017-06-11中国塑料(2017年2期)2017-05-17哲学评论(2016年2期)2016-03-01火控雷达技术(2016年3期)2016-02-06浙江理工大学学报(自然科学版)(2015年10期)2015-03-01浙江人大(2014年6期)2014-03-20
