
基于流计算的高铁牵引变电器多工况机理模型研究
2018-10-19 05:34彭清畅姜喜民刘光俊
软件 2018年9期
赵 珂,彭清畅,姜喜民,刘光俊
基于流计算的高铁牵引变电器多工况机理模型研究
赵 珂1,彭清畅2*,姜喜民2,刘光俊2
(1. 昆明理工大学 城市学院,云南 昆明 650051;2. 中车青岛四方机车车辆股份有限公司,山东 青岛 266111)
随着高铁线路的增多,高铁运行故障监控和预警尤为重要。其中高铁牵引变电器的故障预测因受多工况、运行交路状况、检修记录等因素影响,难以实现单一机理模型准确预测。本文提出了一种基于流计算的高铁牵引变电器多工况机理模型,在高速运行的高铁中可以实时实现牵引变电器故障监控和预测。实际运用表明,该方法有效提高了监控故障准确率和预测故障的成功率。
流计算;牵引变电器;多工况;机理模型
0 引言
高铁的牵引变电器装载于中国标准动车组3、6车车下设备舱内,功能是把受电弓从接触电网上取得的25 kV高电压降至供低压电器使用的1900 V低电压[1],这个过程会导致牵引变电器发热,需要冷却系统进行降温。目前牵引变电器冷却系统监控主要通过监控入口风温度、冷却出口油温、风机电流、风机电压等传感器实现[2],车载监控系统只能监控冷却系统高温故障,误报率较大,也无法实现故障预测。为提高牵引变电器的冷却系统的故障监控准确度和实现故障预测,需结合高铁其它子系统的工况传感器,组合多工况进行大数据联合监控。
高铁牵引变电器的散热系统进行多工况监控,需从风机电流、牵引负荷、列车速度、加速度、牵引变电器油温、外温、PM2.5、进风口温度等机理模型组合监控,并在车载监控平台和线下大数据平台进行流计算监控。理想的多工况机理模型需各种算法算子对比训练才能得到,同时模型的精准度也需要反复迭代训练大数据和实时调整流计算才能实现。
高铁动车组每日需采集138亿左右传感器数据,要求监控系统平均每秒需处理16万工况数据,从中筛选出各种机理模型数据,还需对历史数据进行聚合计算,因此流计算需大量资源才能保证牵引变电器多工况机理模型的计算效率。
1 牵引变电器降温机理
牵引变电器冷却系统是牵引外部空气通过空气过滤器后由牵引送风机吸入并吹出冷却风,然后通过冷却系统由排气管道排出。冷却介质由循环水泵泵入牵引变电器内部的逆变模块、整流模块、整流单元和辅变模块,通过内循环单元吸收热量后经出水口蝶阀进入散热器,再通过水冷却器与外界空气进行热交换,内循环单元中被冷却后的冷却剂再由水泵泵入牵引变电器,如此循环实现变电器降温。降温流程如图1所示。

图1 牵引变电器降温流程示意图
牵引变电器冷却机的散热器安装在高铁底部,散热器的冷却效果取决于通过油冷却器的进风量大小。但进气中含有细微粉尘、羽毛、树叶等杂物,一旦吸附杂物堵塞进风口,会减少散热器的通风量,降低散热性能,容易导致牵引变电器发生高温故障。同时附着在散热器翅片表面的灰尘会增加翅片的热阻,导致散热器冷却性能大幅下降。粉尘中的微小金属长时间附着会造成散热器铝材隔板腐蚀穿孔,造成散热器泄漏失效。
基于牵引变电器运行机理,分别测量牵引变电器散热器相关技术指标参数作为冷却机理监控的基本要素,使用方差斜率算法进行拟合出口油温温升监控模型计算方程式:
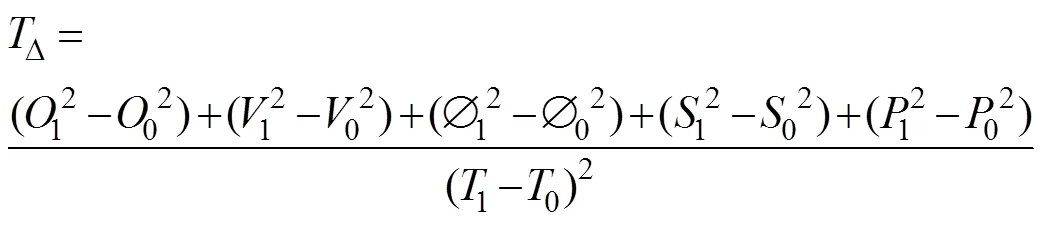
2 高铁传感器数据处理
高铁动车组的传感器数据最大难点是高速运动的设备数据采集和传输。现有动车组数据通过2 G/ 3 G/4 G网络进行实时传输,约3~10 s进行一次网络基站切换[4]。当列车进入信号较弱或无网络覆盖的地方会导致数据传输的延迟,引起大数据流计算高吞吐量的异常变化。并且不同时期建造的高铁其数据包大小和内容都不同,数据包解析的灵活配置是数据实时预处理的关键。因此在多工况数据提取时需要灵活配置和调整才能减少流计算的程序开发工作量。
2.1 数据拟合与过滤
由于高铁牵引变电器的数据存在噪音、突变、传感器故障、干扰、调试等情况,导致很多机理模型难以准确定位,因此需要将数据包进行数据与函数拟合,并通过传感器数据和检修记录等对比分析后,梳理过滤规则提升数据质量。此外,为减少牵引变电器的多工况干扰项和流计算机理模型推导和验证,需对历史数据和当前数据包需要采用方差、均值、小波等聚合类算法进行拟合,还需使用多工况各种比值进行分析和数据拟合处理后才能提高故障预测精度。
2.2 历史数据加工
高铁牵引变电器机理模型设计需要相关工况的历史数据,同时多工况机理模型变化时需要反复处理加工历史数据,因此历史数据只能保存最基本的单位转换数据。牵引变电器故障预测受限于每列高铁的工况变化,如果流计算使用单一数据包只能做阀值监控,用故障预测误差较大,因此需要将历史数据累积成各种工况标签和拟合值,以降低实时流计算处理难度并提升运行效率。
因历史数据面临数据体量过大,运行效率低下,资源开销大的情况,数据加工时间从高铁日常检修和运行交路起止时间段来切分,通常采用集群资源比较闲置的凌晨2点至5点进行历史数据的加工和处理,这样机理模型训练与模型推导既能保障流计算数据处理效率又能提升故障预测效果。
3 机理模型构建方法
牵引变电器传感器采集数据庞大,但每个传感器都有一定的关联机理,在牵引变电器上部署部分监控算法,利用实时采集的数据包,基于大数据流计算进行模型构建。
3.1 模型算法设计
滤网堵塞程度预测模型设计,采用牵引变电器油温温升与滤网堵塞面积百分比建立拟合函数方程式:
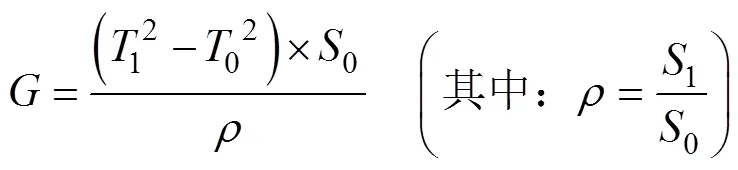
式中G为油温方差温升与进风口堵塞面占比的拟合值,为进风口堵塞面占比,为进风口当前堵塞面积,为进风口面积。画出油温温升数据拟合曲线见图3,由图可见拟合曲线的拐点是温升上升速率最大点。
同时采用牵引变电器油温和外温差之差与滤网堵塞面积百分比建立拟合函数方程:
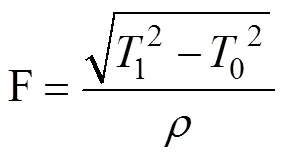

3.2 算法算子动态生效
在流计算中实时调整算法算子,需设置一个规则同步时间开关,流计算运行到该时间点时从配置数据库中同步算法算子规则。按照统一的流式数据格式将测试无误的算法算子封装成jar包,在同步时进行动态装载,可保障动态更新算法算子,也可以在流计算调试时通过降低同步时间开关间隔进行规则同步。
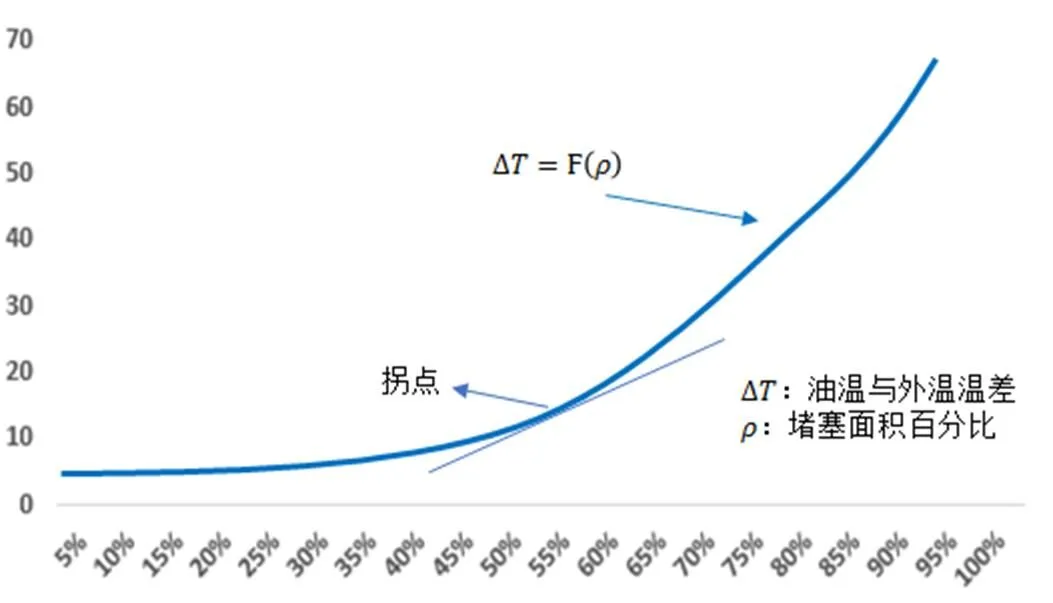
图3 油温差与滤网堵塞面积拟合效果图
3.3 实时流计算
用分布式流计算引擎spark streaming进行封装实现实时流计算[5-9],程序业务流程如图4所示。

图4 Spark streaming程序业务逻辑图
数据流进入spark streaming流计算程序中的关键业务逻辑之前完成数据筛选,减少无关数据量,提升程序运行效率。每种机理模型规则采用线程实现,提升机理模型的并发计算效率,按照spark流计算的批次处理原理,循环执行计算输出机理模型结果。
spark streaming程序需要使用spark-submit进行启动,需以3~5秒/批进行调整执行器数、执行内存和执行CPU核数。
使用on-yarn模式,采用后台nohup无控制台日志运行格式如下:
./spark-submit
--class:入口主类
--master yarn:on-yarn模式
--deploy-mode cluster:集群方式
--num-executors:执行器数
--executor-memory:执行内存
--total-executor-cores:执行CPU核数
--driver-memory:驱动内存
--jars:引用jar包
[程序参数]
3.4 数据链路
流计算程序考虑程序复杂度和数据分层共享等原因,将流计算数据流程链路设计为三层:第1层为原始数据流,第2层为解析后非结构数据流,第3层为机理模型标签数据流。编写三个流程序进行传递处理。每一层都进行写入到hbase进行归档,在保障流计算不同层级的运算效率的同时又能保证流计算的稳定性和完整性。
4 模型推导验证
全国两千多列高铁因建造时间不同,车上传感器种类不同、敏感性不同,采集的数据会存在差异。故每列车的机理模型还需根据具体列车特点推导、训练和验证。选择京广线上1列标动为例,根据交路工况特点在流计算中动态调整机理模型,进行数据和算法拟合验证故障预测效果。
多工况机理模型需要采用高铁运行速度 ≥330 km/s的相同情况下,在固定的运行交路进行推导和验证。
4.1 外温与油温对照验证
在速度匀速时,对不同时间段分析列车外温对牵引变电器油温的影响。数据分析采用该高铁4月16日至22日运行数据,通过函数拟合得到温升与新风温度对比情况,见图5。

图5 新风温度与温升对比图
图中x轴为牵引变电器温升发生频次,y轴为温度,数据对比分析新风温度(进风口温度)上升,而油温没有明显上升,新风温度主要在20℃至35℃之间,从业务上了解到这列高铁期间一直在北方初夏运行,所以新风温度不高。同时对比分析温升拟合值在25℃附近±10℃波动。
进一步分析该列车在四季运行的新风温度机理,采用这列高铁四季运行数据统计分析得到牵引变电器四季水温拟合图6。

图6 进出口四季水温图
由图可见不同季节牵引变电器进口新风温度分布明显不同。由此可见列车季节性外温对进出口水温影响较大。在流计算中,需结合列车四季区间值进行数据过滤,减少单一阀值导致的故障误报,提高故障预测准确率,得到清理牵引变电器清洁周期方程为:
T=0´´(4)
式中T为季节清理周期,0为季节滤网清理周期,为季节影响因子,为相同温度堵塞面积比。将(4)部署到流计算中,根据季节筛选出新风温度最大值,并将值作为故障预测的推导算法条件之一。
4.2 加速度与油温增量验证
在5月17日至27日,分别查看高铁启动阶段的3分钟、5分钟与10分钟阶段的加速度与牵引变电器油温温升的关系,如图7、8所示。

图7 3 min与5 min油温温升散点分布图

图8 10 min油温温升散点分布图
由图可见时间窗口的加速度与牵引变电器温升增量没有线性关系,但从3、5、10 min图中温升逐步散开可以看出温升与加速度的持续时间有一定关联。利用这个关系在流计算中,过滤掉首次发车的冷车阶段前10分钟数据,重点关注之后温升在4℃以上的数据,可以减少在加速度阶段的实时数据误报率。
4.3 模型误差检验
使用一元线性分析方法[6],对这列高铁在5月7日至13日这一段时间内数据,采用线性回归算法对油温与外温的拟合值进行线性回归统计分析得到表1和表2。
在线性回归分析中,得到预测误差值趋近于0。将一元线性回归误差值趋近为0的出现次数进行直方图分析得到图9。
由图可见误差值在±5之间,其误差在较小的合理范围内。结合验证结果,将误差值按照参考值的+5在流计算中进行过滤,剔除误差过大的拟 合值。
表1 线性回归统计表

Tab.1 Statistical table of linear regression
表2 线性回归分析结果表
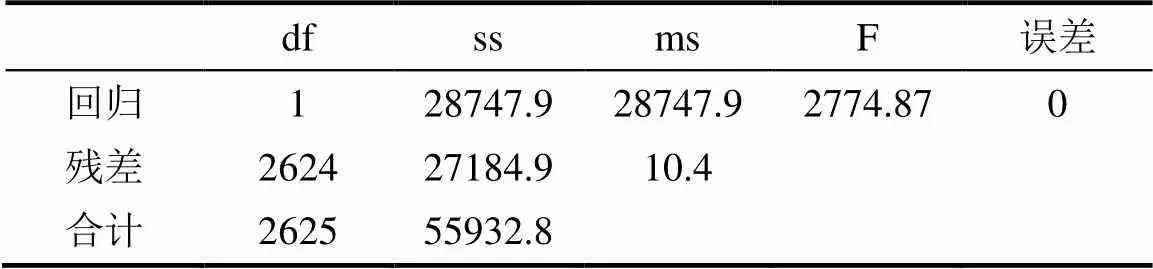
Tab.2 Table of results of linear regression analysis
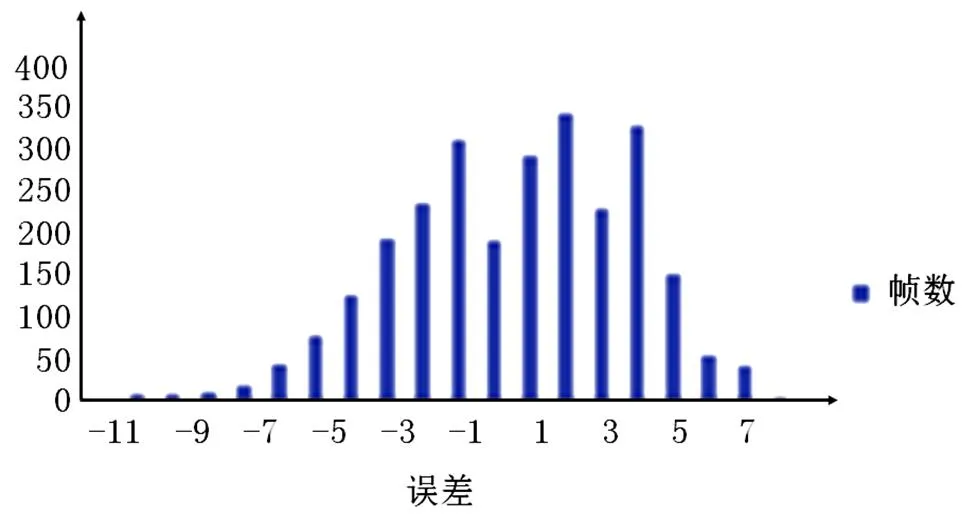
图9 一元线性回归误差直方图
5 迭代训练
机理模型训练需根据已发生故障的数据进行反复迭代训练和修正,大量算法与工况数据之间关联关系也需要业务验证和机理完善。选择在4月22日发生了牵引变电器故障的高铁,调取该高铁上一次检修牵引变电器的时间到该故障发生时间即3月8日到4月22日45天里该列车实际运行数据,进行进风口温度与进风口温差日均值趋势分析得到图10。
由图可见在3月8日牵引变电器风机滤网进行了一次日常周期性清理后,进风口温度和温差都持续升高;到4月2日监控系统预警报高温故障,列车牵引变电器风机滤网故障检查发现进风口堵塞严重,散热器表面有灰尘,进行清理后故障排除。进风口温度回落。到4月22日牵引变电器报高温故障,入库检查发现牵引变电器进风口滤网脏堵,当日进行清理后故障排除。调用多次类似数据后反复分析后推断高温故障出现概率在20日左右会发生进风口滤网堵塞,因此建议将原来不定期清理的检修规程调整为每间隔20日对牵引变电器进风口进行一次定期清理,有效提高了检修效率也避免了一定故障发生率。
此外,每日运行离线大数据程序生成牵引变电器的前60日温差值、均值、最大值、最小值等聚合标签。流计算中的多工况机理模型直接采用每日离线计算的聚合标签进行计算的方法以降低实时流计算的计算资源。
6 结论
本文通过提取高铁牵引变电器传感器多工况数据进行了高温故障机理模型迭代训练和推导,反复修正机理模型和参数,采用在流计算中动态部署机理模型的方式,并根据需要训练和调整模型,解决了流计算中的历史数据实时聚合耗资源问题,也解决了流计算机理模型部署难的问题。基于流计算的高铁牵引变电器多工况机理模型通过实际运行也取得了较好的故障及时监控和故障准确预测效果,在持续1年时间跟踪分析1列高铁在京广线交路上运行情况,前期故障监控和预测准确率分别为88%和85%,后期经过不断迭代训练、优化机理模型,故障监控和预测准确率都提升了近8个百分点。
图10 进风口温度/温差与故障关系图
Fig.10 Relationship between fault and inlet air temperature/temperature difference
[1] 姜斌, 吴云凯, 陆宁云等. 高速列车牵引系统故障诊断与预测技术综述[J]. 控制与决策, 2018, 33(5): 841-955.
[2] 曾云峰, 姚磊, 何凯等. 基于计算流体力学的电力电子牵引变压器热分析[J]. 大功率变流技术, 2017, 4(1): 92-95.
[3] 王斌, 金福才, 谢玉霞. 一种基于流计算的铁路车流推算架构模型研究[J]. 铁道运输与经济, 2018, 7(40): 86-89.
[4] 王忠峰, 王富章, 孙华龙. 高铁动车组WiFi运营服务系统服务质量的测量与分析[J]. 电子技术应用, 2018, 44(5): 77-81.
[5] 夏俊鸾, 刘旭晖, 邵赛赛等. Spark大数据处理技术[M]. 北京: 电子工业出版社, 2015.
[6] 李心愉, 袁诚. 应用经济统计学[M]. 北京: 北京大学出版社, 2008.
[7] Xiaohui Jiang, Peng Hu, Yanchao Li et al. A survey of real-time approximate nearest neighbor query over streaming data for fog computing[J]. Journal of Parallel and Distributed Computing. 116(2018): 50-62.
[8] Jianfeng Xu, Duoqian Miao, Yuanjian Zhang et al. A three-way decisions model with probabilistic rough sets for stream computing[J]. International Journal of Approximate Reasoning 88(2017): 1–22.
[9] 赵永斌, 陈硕, 刘明等.流计算与内存计算架构下的运营状态监测分析[J]. 计算机应用, 2017, 37(10): 3029-3033.
[10] 李斌, 李蓉, 周蕾. 分布式 K-means 聚类算法研究与实现[J]. 软件, 2018, 39(01): 35-38.
Research on Multi Working Mode Mechanism of High Speed Traction Transformer based on Stream Computing
ZHAO Ke1, PENG Qing-chang2*, JIANG Xi-min2, LIU Guang-jun2
(1. City College, Kunming University of Science and Technology, Kunming 650051, China; 2. China Railway Rolling Stock Corporation Qingdao Sifang Co. LTD, Qingdao 266111, China)
With the increase of high-speed rail lines, monitoring and early warning of high-speed rail operation is particularly important. The fault prediction of high-speed railway traction transformer is affected by many factors, such as multi-working conditions, operation routing conditions, maintenance records, etc. It is difficult to achieve accurate prediction of a single mechanism model. In this paper, a multi-condition mechanism model of high-speed railway traction transformer based on stream computing is proposed, which can realize real-time fault monitoring and prediction of traction transformer in high-speed railway. The practical application shows that the method can effectively improve the accuracy of monitoring faults and predict the success rate of failure.
Stream computing; Traction transformer; Multi working mode; Mechanism model
TP273.5
A
10.3969/j.issn.1003-6970.2018.09.027
赵珂(1978-),女,硕士,讲师,主要研究方向:信号与信息处理、大数据挖掘;姜喜民(1979-),男,本科,大数据主管,主要研究方向:信息化规划、大数据架构;刘光俊(1993-),男,本科,助理工程师,主要研究方向:数据统计分析,大数据挖掘。
彭清畅(1985-),男,本科,信息工程师,主要研究方向:软件工程、大数据架构。
本文著录格式:赵珂,彭庆畅,姜喜民,等. 基于流计算的高铁牵引变电器多工况机理模型研究[J]. 软件,2018,39(9):133-138
猜你喜欢
工业炉(2021年2期)2021-05-24
中国煤层气(2019年2期)2019-08-27
小学生学习指导(低年级)(2019年6期)2019-07-22
时代汽车(2018年8期)2018-06-18
环境与可持续发展(2017年2期)2017-04-06
学与玩(2017年12期)2017-02-16
肥料与健康(2016年4期)2016-10-11
小学生·多元智能大王(2014年9期)2014-08-28
火炸药学报(2014年1期)2014-03-20
湖南畜牧兽医(2010年1期)2010-08-15
