
基于时空双流卷积与LSTM的人体动作识别
2018-10-19 03:49毛志强马翠红崔金龙
软件 2018年9期
毛志强,马翠红*,崔金龙,王 毅
基于时空双流卷积与LSTM的人体动作识别
毛志强1,马翠红1*,崔金龙2,王 毅1
(1. 华北理工大学 电气工程学院,河北 唐山 063210;2. 北京交通大学海滨学院,河北 沧州 061100)
针对公共区域等特定场合下人体动作识别准确率不高,时间维度信息不能充分利用等问题,提出了一种基于时空双流卷积与长短时记忆(LSTM)网络的人体动作识别模型。该模型首先采用时空双流卷积神经网络分别提取动作视频序列中的时间和空间特征;然后融合双流卷积结构提取到的全连接层的时空特征;最后将时空融合特征输入到LSTM网络递归学习时间维度长时运动特征并结合线性SVM分类器实现人体动作的分类与识别。在动作视频数据集KTH上的实验结果表明,该模型能够充分利用时间维度信息,且识别准确率可达97.5%,优于其他行为识别算法。
人体动作识别;时空模型;卷积神经网络(CNN);长短时记忆(LSTM)
0 引言
人体动作识别(Human action recognition,HAR)已经成为计算机视觉领域的研究热点和难点[1-3]。基于视频的人体动作识别可以看作是随时间变化的图片分类问题,因此在图片识别领域的深度学习方法也被大量应用在视频序列中人体动作识别的研究中[4]。深度卷积神经网络(Convolutional Neural Network,CNN)在动作识别领域得到广泛的应用,Alexnet[5],GoogLeNet[6],VGGnet[7]等经典CNN架构不仅在图像处理任务上取得突破性进展,在视频处理任务也取得显著成效[8]。2014年,Karpathy等[9]第一次将深度卷积神经网络用于视频中的行为识别,以连续的RGB视频帧为直接输入进行识别;2015年,Cheron等[10]利用3D卷积神经网络提取时间维度信息,是人体行为识别领域经典的模型;Simonyan等[11]构建双流CNN模型用于行为识别,分别以单帧RGB图像和堆叠光流图作为空域网络和时域网络的输入,提取视频的表观和运动信息,在一定程度上利用了视频的时间信息,但是识别准确率并不是很高。Jeff等[12]提出融合卷积层和长时递归层的长时递归卷积网络(Long-term Recurrent Convolutional,LRCN),LRCN 利用CNN网络提取特征,然后送入LSTM网络获得识别结果。
基于以上分析,本文结合各个网络模型优点,构建了一种基于时空双流卷积网络与LSTM网络的人体动作识别模型。该模型针对公共区域等特定场所下的动作识别,首先利用时空双流卷积网络提取动作视频中的外观特征和动作特征,并融合双流结构提取的全连接层特征作为长短时记忆(Long Short- Term Memory,LSTM)网络的输入;然后递归学习时间维度运动信息结合线性SVM,从而实现人体动作识别。
1 模型结构设计
本文提出的Spatiotemporal-LSTM网络结构如图1所示。该网络主要包含四个模块:时空特征的提取、时空特征融合、基于LSTM网络递归学习长时运动特征、线性SVM实现动作识别。首先,分别训练两个2D卷积神经网络,用来分别提取空间特征和时间特征;然后将时空特征进行融合,作为LSTM网络结构的输入特征递归学习时间维度长时运动特征;最后利用线性SVM实现人体动作识别。
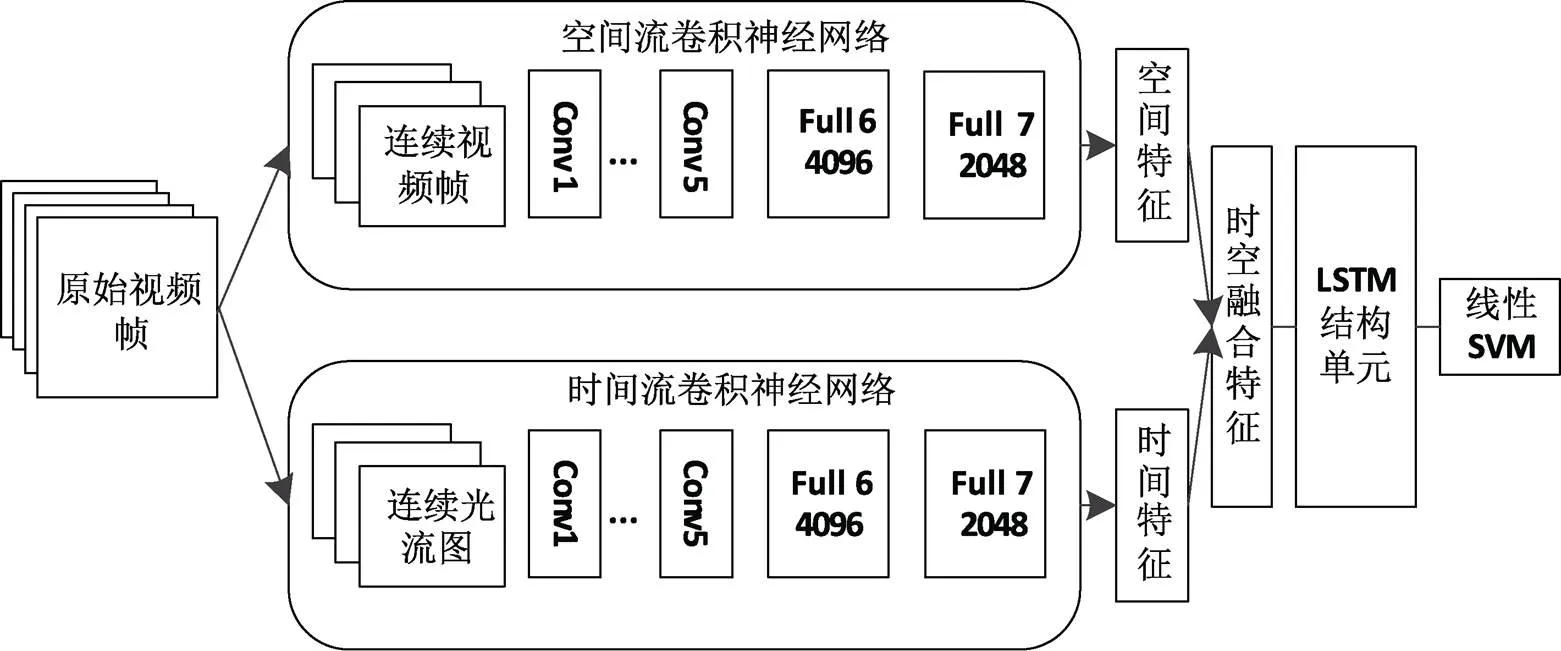
图1 Spatiotemporal-LSTM总体结构
1.1 空间流卷积神经网络
视频序列中的表观特征对于某些人体动作识别具有重要的作用,本文通过构建空间流卷积神经网络来提取表观特征。空间流卷积神经网络实质上是一种图片分类结构,以连续的单个视频帧作为输入,提取静态图片中外观信息来完成人体动作表征。本文构建的空间流卷积网络采用的是牛津大学视觉几何组(Visual Geometry Group,VGG)开发的VGG-M- 2048模型,如图2所示。

图2 空间流卷积神经网络结构
1.2 时间流卷积神经网络
本时间流卷积神经网络结构如图3所示,同样采用的是VCC-M-2048模型。与空间流的输入不同,时间流卷积神经网络输入是连续的光流图。光流图可以理解为空间运动物体在连续视频帧之间的像素点运动的“瞬时速度”,能够更加直观清晰的表征人体运动信息,有效地提取了视频序列的时间特征,提高了视频人体动作的识别准确率。

图3 时间流卷积神经网络
对于光流帧的提取采用的是OpenCV视觉库中提供的稠密光流帧提取方法,分别获取视频中水平方向和垂直方向的光流帧,然后将20个光流图构成一个光流组(flow_x和flow_y)作为时间流卷积神经网络的输入。
1.3 时空特征融合
时空网络的融合在于使用视频的空间特征与时间特征的关联性判断人体的动作。比如对于挥拳和散步两个动作,空间流卷积神经网络识别出静态图片中手和脚的位置,时间流卷积神经网络识别出了在一定的空间位置手部和脚部的周期性动作,结合这两个网络可以识别出挥拳和散步这两个动作。

图4 时空特征融合
相比于卷积层特征,全连接层特征具有更高层次的抽象和更好地语义信息,更适合作为LSTM网络的输入,在实验部分,本文设计了几种不同的卷积层特征融合和全连接层特征融合方案,证明了空间流卷积神经网络的full6层和时间流卷积神经网络的full7层进行特征融合具有更好的识别效果。如图4所示。
1.4 LSTM网络
长短时记忆(LSTM)网络是由递归神经网络(RNN)演变而来,对复杂的时间维度信息更加敏感,能够有效地解决RNN在训练过程中出现的梯度爆炸或梯度弥散的问题,从而有利于学习到长时动态信息。其LSTM网络结构单元如图5所示。
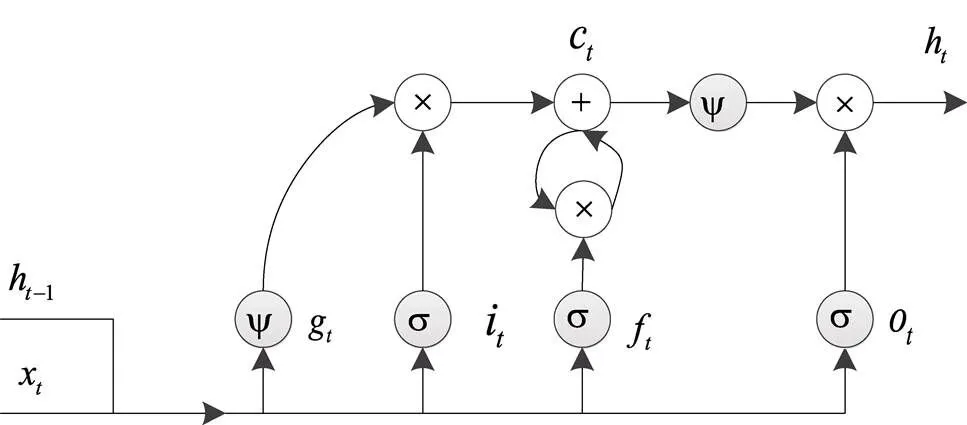
图5 LSTM网络单元
该结构单元在隐层中加入了先验知识——输入门、遗忘门、输出门和输入调制门,通过以上门结构能够将各层间信号和某一时刻的输入信号处理的更加透明。如下式(1)所示:

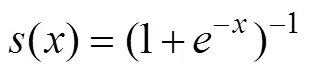
记忆单元c是LSTM的核心部分,其作用是选择有用信息去除无用信息,如式(2)所示:

式中c包括两部分,一部分是由上一时刻记忆单元c1和遗忘门f相乘而得,另一部分由输入门i和输入调制门g相乘而得。
The comparative studies were assessed by the Newcastle-Ottawa Quality Assessment Scale (NOS)[21].Twelve of 14 studies had 6 or more star points on the NOS scale.
LSTM的输出h是由输出门o控制是否激活记忆单元c。如下式(3)所示:

2 实验结果与分析
2.1 实验环境
本文实验环境选择深度学习框架Caffe平台实现,网络训练采用小批量随机梯度下降法。时空双流卷积神经网络采用VGG-M-2048模型提取时空特征,以16帧为一组的连续RGB视频帧为空间流输入,输入大小为224*224,时间流卷积神经网络输入大小为224*224*2在原光流图像上随机位置裁剪的连续光流帧。根据文献[10]的结论,将光流在时间域上的长度设置为=10效果会更好。在训练过程中,批次大小设置为96,将权值衰减率设置为0.85,初始学习率为0.01,在第30000次迭代后每20000次迭代学习率缩小为原来的1/10,直至迭代80000次后停止训练。
本次实验数据集采用KTH数据集,该数据集包括了4种场景下25个不同行人的6中行为视频:正常行走(Walk)、慢跑(Jog)、跑(Run)、挥拳(Box)、双手挥手(Wave)、鼓掌(Clap)。如图(6)所示。实验过程中,为了增加识别准确率可信度,本文将KTH数据集随机划分成3组,取其3组测试平均准确率作为评估模型效果的指标。

图6 KTH样本数据集
2.2 实验结果分析
通过时空双流VGG-M-2048模型提取连续RGB视频帧与连续光流图的时空特征,对于在不同位置融合时空网络层特征的识别准确率如表1所示。
表1 时空特征不同融合位置的识别准确率比较(%)

Tab.1 Comparison of recognition accuracy of different fusion locations of space-time features (%)
从表1中可以发现,随着融合位置层次的加深,识别准确率也在不断提高,而且全连接层特征融合明显高于卷积层特征融合,说明全连接层比卷积层具有更好的语义信息。但是当采用空间流的fc7层和时间流的fc6层进行融合时,识别准确率有所下降,而采用空间流的fc6层与时间流的fc7层识别效果是最好的。
表2 本文算法与其他方法识别准确率的比较(%)

Tab.2 Comparison of the accuracy of the algorithm and other methods in this paper (%)
3 结论
本文提出了一种基于时空双流卷积网络与LSTM的人体动作识别方法。该方法首先利用时空双流网络提取视频序列中的时空特征,再将全连接层的输出特征进行融合作为LSTM模型的输入递归学习长时运动特征。在KTH数据集上的结果表明:选择S-fc6和T-fc7层进行特征融合会有更好的识别效果;LSTM网络递归学习的长时运动特征有利于人体动作识别;本文提出的算法优于其他方法,识别效果更好。
[1] Herath S, Harandi M, Porikli F. Going deeper into action recognition: A survey[J]. Image & Vision Computing, 2017, 60(4): 4-21.
[2] 马淼, 李贻斌. 基于多级图像序列和卷积神经网络的人体行为识别[J]. 吉林大学学报(工), 2017, 47(4): 1244-1252.
[3] 张震, 张雷. 基于CCN的CDN视频内容分发技术研究[J]. 软件, 2015, 36(1): 67-71.
[4] 周枫, 薛荧荧, 李千目. 视频监控与编码技术的研究综述[J]. 软件, 2015, 36(4): 84-92.
[5] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012: 1097-1105.
[6] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2015: 1-9.
[7] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
[8] 张明军, 俞文静, 袁志, 等. 视频中目标检测算法研究[J]. 软件, 2016, 37(4): 40-45.
[9] Karpathy A, Toderici G, Shetty S, et al. Large-Scale Video Classification with Convolutional Neural Networks[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014: 1725-1732.
[10] Chéron G, Laptev I, Schmid C. P-CNN: Pose-Based CNN Features for Action Recognition[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2015: 3218-3226.
[11] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[J]. 2014, 1(4): 568-576.
[12] Donahue J, Hendricks L A, Rohrbach M, et al. Long-term Recurrent Convolutional Networks for Visual Recognition and Description[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(4): 677-691.
Human Action Recognition Model Based on Spatio-temporal Two-stream Convolution and LSTM
MAO Zhi-qiang1, MA Cui-hong1*, CUI Jin-long2, WANG Yi1
(1. College of Electrical Engineering, North China University of Science and Technology, Tangshan 063210, China;2. Beijing Jiaotong University Haibin College, Cangzhou 061100, China)
Aiming at the problem that the accuracy of human action recognition is not high and the time dimension information cannot be fully utilized in specific occasions such as public areas, a human action recognition model based on spatio-temporal two-stream convolution and Long Short-Term Memory (LSTM) network is proposed. The model first uses spatio-temporal two-stream convolutional neural networks to extract temporal and spatial features in action video sequences. Then merging the spatiotemporal features of the fully connected layer extracted by the two stream convolution structure; Finally, the spatio-temporal fusion feature is input into the recursive learning time dimension long-term motion feature of the LSTM network and combined with the linear SVM classifier to realize the classification and recognition of human motion. The experimental results on the action video dataset KTH show that the model can make full use of the time dimension information, and the recognition accuracy is up to 97.5%, which is superior to other behavior recognition algorithms.
Human action recognition; Spatio-temporal model; Convolutional neural network (CNN); Long Short-Term Memory (LSTM)
TP391
A
10.3969/j.issn.1003-6970.2018.09.002
国家自然科学基金项目(61171058)
毛志强(1991-),男,硕士研究生,研究方向:计算机视觉、目标检测与人体行为识别;崔金龙(1989-),男,硕士,助教,研究方向:钢成分测量;王毅(1994-),男,硕士研究生,研究方向:计算机视觉、目标检测与视频分析。
马翠红(1960-),女,教授,研究方向:复杂工业系统的建模与控制。
本文著录格式:毛志强,马翠红,崔金龙,等. 基于时空双流卷积与LSTM的人体动作识别[J]. 软件,2018,39(9):09-12
猜你喜欢
中小学校长(2022年7期)2022-08-19
北京航空航天大学学报(2021年9期)2021-11-02
冶金设备(2020年2期)2020-12-28
小学生学习指导(低年级)(2020年11期)2020-12-14
高原山地气象研究(2020年3期)2020-07-16
中小学校长(2019年10期)2019-11-07
电子制作(2019年11期)2019-07-04
作文大王·低年级(2018年10期)2018-12-06
北京航空航天大学学报(2018年1期)2018-04-20
电视技术(2014年19期)2014-03-11
