
深度学习方法在业务流程进度预测中的应用
2018-10-18 10:33郑婷婷
现代计算机 2018年26期
郑婷婷
(广东开放大学信息工程学院,广州 510091)
深度学习;事件日志;流程管理;预测分析
0 引言
业务流程的执行进度预测可以为业务流程的管理提供有价值的决策信息,例如当前进度、剩余时间、资源分配,等等,这些信息能让流程管理员识别可能出现异常的案例,并提早采取相应的预防异常措施。流程数据分析和预测的来源主要是流程执行时产生的历史日志信息[1]。预测结果的可以是实时产生的[2][5],也可以是基于经验库的。预测的范畴包括:后续活动、剩余时间、数据流、资源调度等方面[2-5]。
关于业务流程性能预测已有的成果所使用的方法包括:状态转换模型[2]、随机过程[3]、时序分析[4]、遗传进化算法[5]等。随着近年机器学习成为一个研究热点,机器学习在数据分析和预测中的应用也逐渐受到重视。机器学习是一门涉及概率论、统计学、算法复杂度理论等多领域的交叉学科,研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,其构建算法可从数据中进行学习和预测[6]。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,是机器学习中一种基于对数据进行表征学习的方法[7,8]。深度学习可以用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
1 业务流程相关定义
为了让业务流程运行中产生的数据用于深度学习的模型,下面先给出业务流程分析及预测中涉及到的一些定义。
定义1(事件):业务流程中的一个事件定义为元祖e=(caseID,task,timeStart,timeEnd,prop1,…,propm),其中属性caseID是案例的ID,task是该事件所完成的对应的任务,timeStart和timeEnd分别是事件开始和结束的时间戳,prop1,…,propm是该事件对应的其他属性。令所有事件的集合为ε。
对于任意事件ei,设ei(attribute)为其对应的属性值,例如ei(timeStart)和ei(timeEnd)分别为该事件开始和结束的时间戳,则事件ei的持续时间为ei(timeEnd)-ei(timeStart)。
定义2(事件轨迹):一个事件轨迹定义为一个非空的事件序列。一个长度为n的事件序列为σn=<e1,e2,…,en>,其中ei∈σn是事件轨迹中的第 i个事件。
定义3(事件日志):一个事件日志定义为一系列事件轨迹的集合,一个包含了n个时间轨迹的事件日志为Ln=<σ1,σ2,…,σn,>,其中σj∈Ln是事件日志中的第j个事件轨迹。
定义 4(事件轨迹及其预测的映射):函数f∈X→Y表示事件轨迹到其预测函数的映射。其中X表示所有事件轨迹的集合,Y表示预测的值域。
2 深度学习算法的应用
2.1 递归神经网络RRNNNN
递归神经网络(Recurrent Neural Networks,RNN)主要用于处理序列数据[9]。RNN是包含循环的网络,允许信息的持久化。在RNN中,一个序列输出与前面的输出相关。RNN按时间节点的展开如图1所示,每个xi是不同时间节点的输入。显然,RNN中每次的输出都会受到当前和之前的输入xt-2,xt-1,xt等的影响。RNN的输入长度可以是任意的,st是在时间点t的一个隐藏状态,且st受到时间点t之前所有输入的影响[7,8]。而当获取了当前输入xt后,s根据st和xt更新,其中st为:st=f(Uxt+Wst-1),U和W分别是当前输入xt和隐藏状态st-1的权重向量。函数f是激活函数,通常定义为sigmoid函数:

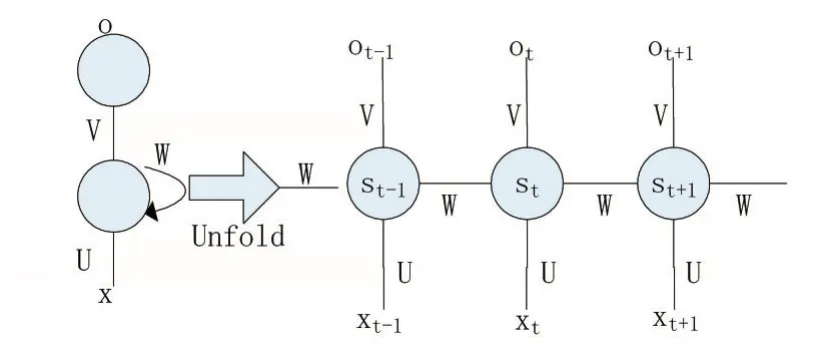
图1 RNN节点展开示例
2.2 长短期记忆单元LLSSTTMM
长短期记忆单元(Long Short-Term Memory,LSTM)是循环网络的一种变体,带有所谓长短期记忆单元,可以解决RNN中梯度消失或梯度爆炸等问题[7-9]。LSTM将误差保持在更为恒定的水平,让循环网络能够进行许多个时间步的学习(超过1000个时间步),从而打开了建立远距离因果联系的通道。RNN与LSTM最大的区别在于LSTM使用了一个更加复杂的记忆单元Ct来取代st。Ct可以存储、写入或读取信息,Ct通过门的开关,即不同的权重集,对输入信息进行筛选,决定是否输入、输出或遗忘,判定哪些信息需要存储,以及何时读取、写入或清除信息。LSTM记忆单元的工作原理如图2所示。
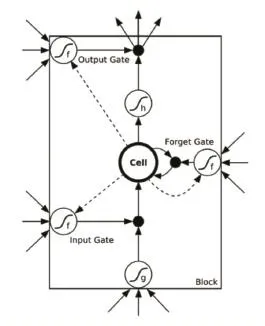
图2 LSTM工作原理
若ft表示“遗忘门”,即表示哪些信息可以遗忘,it表示“输入门”,即当前获取的输入,ot表示“输出门”,即当前节点的输出信息,则LSTM的工作原理可以用以下公式描述:
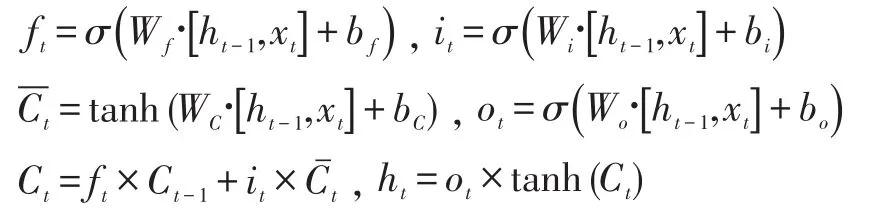
其中,Cˉt是可以对当前状态Ct产生影响的状态参数,Ct-1是前序状态,当前节点的输出信息还可以通过tanh(Ct)进行筛选,最终输出为ht。
2.3 业务流程到深度学习算法的映射
可以把一个事件e=(caseID,task,timeStart,timeEnd,prop1,…,propm)作为深度学习中的一种状态,则事件轨迹σn=<e1,e2,…,en>就是一系列的状态变化。在表示事件的属性时,非数值型的属性可以使用所谓的onehot编码,即所谓的“独热”编码来处理。one-hot编码的方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,只有其中一位有效。这样,所有的非数值型属性都可以在深度学习网络中表示。对于每一个特征,如果它有m个可能值,那么经过“独热”编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据集就会变成稀疏的。“独热”编码的好处主要包括解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。如果要把包含若干轨迹的事件日志映射到LSTM网络中,并利用其属性实现预测,可令每个LSTM记忆单元描述一个事件,其中每组的第一个LSTM单元分别描述事件轨迹的第一个事件,即初始状态,并按轨迹的顺序依次引入其他LSTM记忆单元。事件的属性都可映射到LSTM记忆单元中,这样经过多次的学习,即可得到业务流程的进度预测,如图3所示。
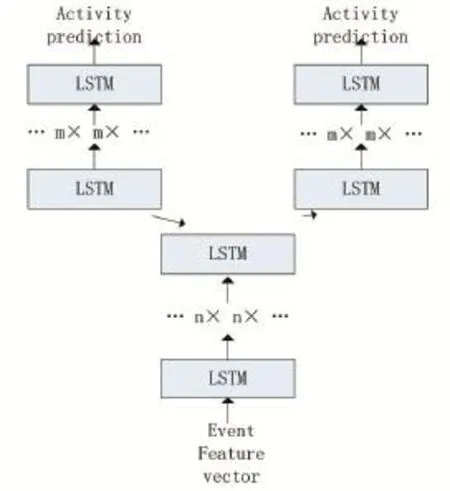
图3 使用事件及其属性预测流程执行情况示例
3 实验分析
使用RNN及LSTM算法预测一个关于借贷的金融服务的业务流程[10]。这个流程的概要如图4所示。
实验中采用平均绝对误差(MAE)作为误差分析的标准。其公式如下:
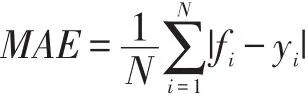
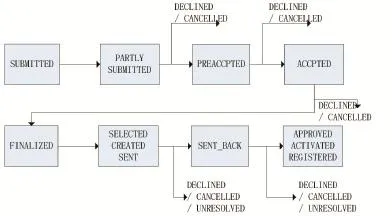
图4 实验业务流程
其中fi和yi分别表示样本的预测值和真实值。平均绝对误差由于离差被绝对值化,不会出现正负相抵消的情况,因而,平均绝对误差能更好地反映预测值误差的实际情况。经多次实验,使用RNN及LSTM算法预测案例执行时间的MAE如表1所示。实验表明这两种算法的使用可以达到较高的准确率。
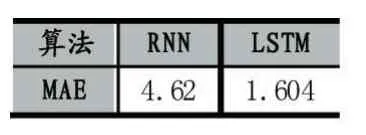
表1 RNN及LSTM算法应用于流程预测的误差对比
4 结语
本文介绍了深度学习算法RNN和LSTM,并把这两种算法用于流程执行预测,实验数据表明深度学习算法用于流程预测具有较高准确率,具有一定的实际意义。我们下一步将研究如何把深度学习算法用于执行序列、资源管理等方面的预测。
猜你喜欢
军民两用技术与产品(2022年4期)2022-06-28
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
华人时刊(2021年13期)2021-11-27
财会学习(2021年14期)2021-11-21
心声歌刊(2020年4期)2020-09-07
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
科学与财富(2018年23期)2018-08-19
