
基于KNN的合成孔径雷达目标识别*
2018-10-16 08:26:42白艳萍张校非
火力与指挥控制 2018年9期
郝 岩,白艳萍,张校非
(中北大学理学院,太原 030051)
0 引言
合成孔径雷达(SAR)是一种高分辨率成像雷达,成像具有全天时、全天候的特点。在信息高速发展的时代,信息的高效处理成为必然。快速高效的SAR目标识别方法也必不可少。目前,SAR目标识别研究主要分为目标特征提取和识别两大部分。传统的特征提取方法有主成分分析(PCA)[1]、非负矩阵分解[2]、灰度共生矩阵法[3]等;而识别方法主要有支持向量机(SVM)[4],自适应集成分类器(AdaBoost)[5]以及深度学习方法[6-8]。
KNN(K 近邻算法)最早是由 Cover和 Hart[9]提出的,现已成为一种非常有效的非参数分类算法。它是一种惰性学习,学习过程只是简单地存储已知的训练数据;当遇到新的测试样本时,一系列相似的样本被取出,并用来分类新的测试样本。它在模式识别、统计分类、计算机视觉、DNA测序以及剽窃侦查等方面应用广泛。
本文主要研究将KNN算法应用于SAR目标识别,并将其效果与经典的SVM算法进行比较。采用剪裁和去噪方法,包括高斯去噪、中值滤波、小波加噪去噪的方法对图像的冗余信息进行“剔除”,并将不同去噪方法与剪裁后的图像结合,达到了比单独剪裁或去噪实验更好的识别效果,进一步证明了本文所提方法的有效性。
1 KNN算法原理简介
KNN算法[10]是一种统计分类器,属于惰性学习,对包容型数据的特征变量筛选尤其有效,是最简单的机器学习算法之一。它的基本思想是:输入没有标签及未经分类的新数据,首先提取新数据的特征并与测试集中每一个数据特征进行比较;然后从样本中提取k个最邻近数据特征的分类标签,统计这k个最邻近数据中出现次数最多的分类,将其作为新数据的类别[11-13]。
KNN的算法步骤如下:
1)计算待分类数据特征与训练数据特征之间的距离并排序;
2)取出距离最近的k个训练数据特征;
3)根据k个相近训练数据特征所属的类别来判定新样本的类别:如果它们都属于同一类,那么新样本也属于这个类;否则,对每个候选类别进行评分,按照某种规则确定新样本的类别。
wi类的判决函数为:
1)欧氏距离
2)马氏距离
3)曼哈顿距离
4)切比雪夫距离
判决规则为:
2 实验及结果分析
本文针对MSTAR的公开数据集BMP2(装甲车),BTR70(装甲车)以及 T72(主战坦克)进行实验,图1是3类目标的SAR图像和光学图像示例。数据库中的SAR图像分辨率为0.3 m×0.3 m,目标图像大小为128×128像素。实验选取SN_C21,SN_C71和SN_132 17°俯仰角下的图像作为训练样本,15°俯仰角下的图像作为测试样本。训练样本个数为698,各类分别为233,233,232。测试样本个数为588,各类分别有196个样本。
2.1 数据预处理
本文将实验分为两组,第1组分别对数据进行了单一的剪裁,高斯去噪,中值滤波,小波加噪再去噪,然后分别用KNN和SVM分类,下面简称实验1;第2组实验数据为在剪裁好的图像基础上再分别进行高斯去噪,中值滤波,小波加噪再去噪,再用KNN和SVM分类,下面简称实验2。
本文将未处理的图像作为实验1的第1组数据。其次,根据MSTAR中SAR图像目标集中于图像中间的特点,将图像剪裁成大小为64×64的新图像,作为实验1的第2组数据,然后对图像分别进行高斯去噪,中值滤波,小波加噪再去噪,把处理后的图像读为特征向量,作为实验1的3、4、5组数据,以待分类。
为了实验更好地识别效果,将实验1中处理好的数据第2组数据分别与3、4、5组数据结合,分别作为实验2的第1、2、3组数据,以待分类。
2.2 实验
2.2.1 实验1结果
针对实验1的数据,分别用KNN和SVM分类的结果如表1,由于KNN的初始聚类中心为[0,1]之间的随机值,因此,本文取10次实验结果的平均值作为最终结果。
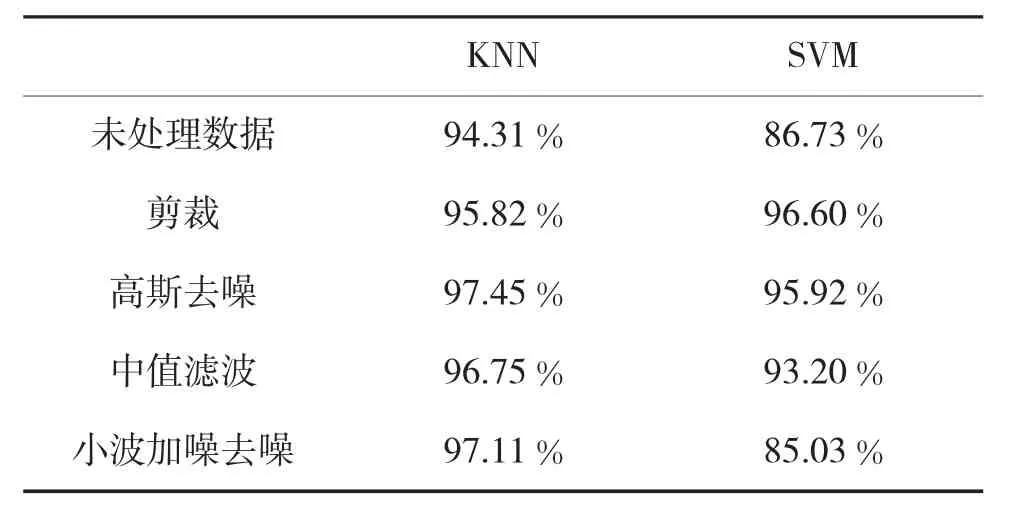
表1 实验1结果比较
从表1可以明显看出,除了经剪裁处理的数据SVM方法比KNN精确度高0.78%之外,其他方法KNN的分类效果都明显优于SVM。而且对于未处理数据而言,SVM的识别效果较差,正确率只达到86.73%,而KNN的识别效果可以达到94.31%。
2.2.2 实验2结果
实验2中除了实验数据与实验1的处理方法不同之外,其他设置均相同,实验结果如表2。
从表2可以看出,第1组数据SVM方法比KNN精确度高0.75%,后两组数据的KNN方法均比SVM精度高。另外。前两组数据相比于实验1的精度都有所提高,而第3组数据的实验结果比未经剪裁的小波加噪去噪方法的精确度略低,说明图片大小的变化对此方法产生了负面影响,但其识别效果依然很可观。
图2是上述8组数据以0作为初始聚类中心的分类误差图,图2(a)~图2(h)分别对应上述8组数据的误差图。从图中可以看出,识别错误率最大的均在第1类中。
3 结论
本文采用逆向思维,通过剪裁和去噪方法提取图像特征,并用KNN和SVM进行识别。通过两组实验发现,KNN的识别准确率均达到94%以上,且在多组数据上识别精确度高于SVM,充分证明了所提方法的有效性。但KNN也存在一些不足,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的各“邻居”中大容量类的样本占多数,这也将成为日后继续研究的一个方面。
猜你喜欢
科学大众(2022年17期)2022-09-22 01:37:30
科技风(2021年19期)2021-09-07 14:04:29
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
电子制作(2019年13期)2020-01-14 03:15:32
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
小学生优秀作文(高年级)(2018年4期)2018-09-11 01:23:30
新闻传播(2018年10期)2018-08-16 02:10:08
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
制造技术与机床(2017年10期)2017-11-28 05:20:43
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
