
基于Faster R-CNN的车辆多属性识别
2018-10-15 05:58阮航,孙涵
计算机技术与发展 2018年10期
阮 航,孙 涵
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211100)
1 概 述
车辆的自动识别系统对于交通监控、停车管理和公安系统有着重要的意义,其中基于计算机视觉的车辆自动识别研究受到了广泛关注。在这些研究中,车辆检测和车辆识别是自动识别系统中的重要组成部分,而由于自然道路场景下的光照变化,不同天气条件影响和拍摄图像畸变等问题,使得车辆检测和识别具有很大的挑战性。传统的图像处理方法首先提取图像特征,如文献[1]采用Harris特征与SIFT特征结合的方式实现车型识别,文献[2]采用空间金字塔结合Adaboost分类器的方式对车辆进行检测。这些方法提取的特征为纹理、边缘、轮廓等浅层特征,无法准确区分车辆外观,而且提取到的特征易受光照、车辆姿态的影响,在车辆识别中,无法应用浅层特征进行车辆的细粒度分类。
在传统的目标检测中,DPM[3](可变形模型部分)组件检测算法应用广泛。DPM首先计算梯度方向直方图,然后使用SVM训练得到物体的梯度模型来完成分类。DPM具有良好的鲁棒性,但由于使用滑动窗口进行特征提取和分类,使得计算量大、效率低,无法广泛应用。随着深度学习在计算机视觉领域的突出表现,深度学习算法被广泛应用于图像检测和图像分类中,其中在物体检测领域提出了基于候选框的R-CNN[4]方法。该方法采用选择搜索方法(selective search)或边缘框方法(edge box)得到物体的候选框,然后送入卷积神经网络提取特征,最后通过SVM分类器获得最终的检测结果。R-CNN方法将提取到的几千个候选框依次送入CNN网络提取特征,上千次的卷积操作带来了巨大的计算量,使得该方法效率低,计算复杂。为改进R-CNN方法,Fast R-CNN[5]采用兴趣区域(ROI)池化层得到候选框,并采用多任务损失函数预测物体类别和位置信息,只需要一次卷积操作即可完成提取特征操作。与采用滑动窗口的DMP方法相比,上述两种基于候选框的深度学习方法,大大提升了检测效率,然而,这两种方法需要时间来提取候选框,降低了整体的检测效率。因此,在R-CNN和Fast R-CNN的基础上提出了Faster R-CNN[6]。Faster R-CNN算法采用RPN网络(区域建议网络)提取候选框,该方法采用共享卷积层特性来提高速度和性能,真正实现了端到端网络,是一个完整的卷积神经网络结构。Faster R-CNN方法大大提升了物体检测精度,也大大加快了物体检测的效率。
另一个重要的和具有挑战性的研究领域是车辆属性识别,包括车辆姿态、颜色、速度、门的数量、类型和其他细粒度属性。Li等[7]采用矢量匹配的模板来识别车辆颜色,该方法对于图像的质量要求较高,而且只能识别车辆的颜色信息。张军等[8]提出改进的深度学习网络实现车型的分类,该方法只对车辆大小进行分类。文献[9]通过粒子群编码,采用粒子群与云模型结合的方法实现车型识别。文献[10]采用改进的LeNet-5网络结构进行车牌识别,该方法对车牌图像质量要求高。上述方法只针对特定的车辆属性进行分析,然而在许多情况下多个车辆属性需要同时采集,如车辆自动驾驶领域,而且这些属性的学习存在很强的相关性。因此,在车辆自动识别系统中,车辆的多属性识别是十分重要的。
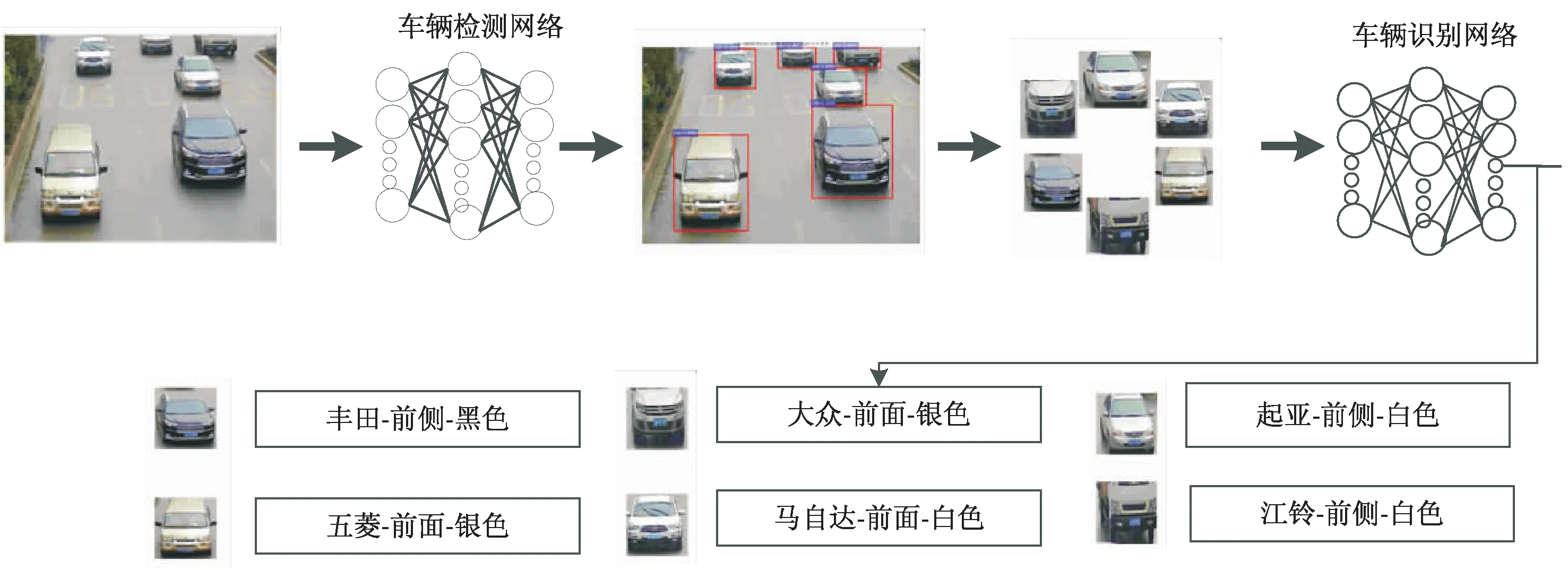
图1 基于Faster R-CNN的车辆多属性识别模型
2 基于Faster R-CNN的车辆检测与多属性识别框架
文中提出了基于Faster R-CNN的车辆检测以及车辆多属性识别,其中车辆多属性识别包括车辆估计、品牌、姿态、颜色等,如图1所示。该检测识别模型包括两个卷积神经网络:车辆检测网络和车辆识别网络。在公路场景中,车辆检测网络旨在预测车辆的位置,然后将检测到的车辆图像输入车辆识别网络中识别车辆的多种属性。
2.1 车辆检测模型
传统的检测方法如DPM使用滑动窗口方法,有很多重复的候选框,严重降低了效率,增大了计算量。基于深度学习的R-CNN和Fast R-CNN的方法结合候选框与分类网络,也会产生很多冗余的候选框,从而降低了网络效率。因此,文中选择Faster R-CNN物体检测算法来实现车辆检测。该算法设计RPN层来提取精确的候选框,大大减少了候选框的数量,并采用多任务损失函数来回归候选框位置信息,同时将RPN网络与多任务分类网络相结合,真正实现端到端的网络结构,在保证速度的同时,大大提升了检测精度。Faster R-CNN框架分为卷积层、RPN层和坐标回归层,网络结构如图2所示。有5层卷积层用于车辆特征图提取,第1层卷积层(conv_1)有96个大小为7*7的卷积核;第1层卷积层(conv_2)的输入是从上一层获得的特征图,该层有256个大小为5*5的卷积核;conv_3、conv_4、conv_5将上一层获得的特征图作为输入,其卷积核的个数分别为384、384、256,大小均为3*3。5个卷积层,其卷积核大小逐层减小,这样可以保留更多有用的浅层特性并提高网络性能。
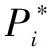
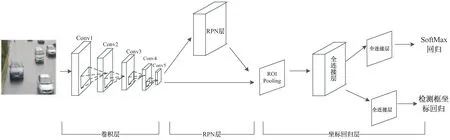
图2 车辆检测网络结构
(1)
(2)
第二种损失是位置回归层,用以修正候选框位置,坐标首先归一化到0~1之间,如式3和式4所示。
(3)
(4)
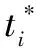
该损失采用Smooth L1函数,如式5所示,作为坐标回归的损失函数。位置回归层的损失函数如式6所示。
1)农村出生人口性别比高于城市。据“五普”、“六普”人口普查资料显示,安康市农村、镇出生人口性别比远远高于城市(表2)。从人口普查数据断定,20世纪80年代以来安康市出生人口性别失衡主要表现在农村出生人口性别的失衡,即农村男性人口数量远远超过女性。而当年出生的人口到现今都已到了婚配时期,由于出生人口性别比严重失调而导致的农村男青年婚恋困难问题也日渐凸显。
(5)
(6)
RPN在训练阶段的多任务损失函数由2分类损失函数和位置回归损失函数构成,如式7所示。
(7)
其中,Ncls为训练批处理数据的图片个数;Nreg为RPN层预测的候选框的数量。这两个参数是将损失值做了归一化处理。
2.2 车辆属性识别模型
在车辆识别领域有很多研究,如车辆类型识别和车辆颜色分类,然而大多都是将车辆属性进行独立研究的,由于未考虑多个属性间的特征关系导致识别准确率下降。因此,文中提出车辆识别网络实现车辆多属性分类。车辆识别网络选择GoogLeNet[11]作为基本的网络模型,该网络有22层,相比于5层的Alexnet[12]和16层的VGG,文中选择深层网络结构的原因是由于车辆识别属于细粒度的分类问题,深层结构可以获得更具代表性的深层语义特征。修改了GoogLeNet网络结构获得车辆识别网络,在GoogLeNet网络的基础上,将全连接层改为多个,每个全连接层对应一个损失层,从而实现多属性分类。修改后的网络结构如图3所示。

图3 车辆属性识别网络结构
车辆识别网络的网络稀疏结构大大减小了计算量,提升了网络性能,其多个损失层又能够更好地利用车辆属性特征之间的关联,提高分类的准确率。在车辆识别阶段,图像具有4个属性标签:E、M、V、C,分别代表估计、品牌、姿态、颜色。如果E为0,表示目标不是车辆,则其他四个属性设置为0,表示这些属性在训练阶段无贡献。属性E的损失函数如式8所示。
(8)
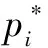
(9)
其他四个属性M、T、V、C的损失函数为Softmax损失,表示预测为某一类别的概率大小。以属性M的损失函数为例,如式10所示。
(10)
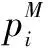
(11)
车辆多属性识别网络的损失函数如式12所示,由估计、品牌、颜色、姿态这四个损失构成。
LVRN(PE,PM,PC,PV)=L(PE)+λL(PM)+
(12)
其中,L(PE)表示车辆估计的损失值,表示预测图像为目标或背景,如果预测为目标,则λ固定为1,否则λ为0。
2.3 训练网络
由于要实现车辆的多目标检测和细粒度的分类问题,因此需要数据集有充足训练数据和丰富的种类,因此选用大规模数据集“Compars”[13]作为训练数据。
该数据集有130 000幅车辆图像,标定了坐标信息和车辆属性,包括品牌、车辆类型、车辆姿态等,具有163种品牌,12种类型,如MPV、SUV、掀背车、轿车、面包车等,5种姿态:前面(F)、后面(R)、侧面(S)、前侧(FS)和后侧(RS)。
对于训练数据,选用所有163种汽车品牌,5种车辆姿态。此外,标注了50 000张常见车辆类型的图像,标注了4种车辆颜色属性,包括黑色、白色、银色、红色,作为训练数据集。
对于训练数据集首先缩放图片到224*224,采用镜像数据和裁剪的方式扩增数据集,对数据集图像进行去均值处理,使得图像的均值为零。对于车辆检测网络,采用车辆的坐标信息作为回归参数,以0.001为初始学习率,权重衰减系数0.9,全部训练数据迭代训练30次,得到车辆检测网络;对于车辆分类网络,采用ImageNet[14]预训练好的GoogLeNet模型来初始化权值参数,修改网络的损失层为车辆品牌损失层、车辆姿态损失层和车辆颜色损失层,学习率调整为0.001来训练网络,采用随机梯度下降的方式更新权重,全部训练数据迭代30次,得到车辆识别网络。
3 实验结果与分析
采集了真实道路场景下不同时间、不同分辨率的5 000幅图像作为测试集Test1来评估车辆检测网络和车辆识别网络。为比较图像对框架的影响,又从测试集Test1中选取2 000幅光照正常,图像内车辆目标个数在3~4个的图像作为测试集Test2,以对比图像对框架的影响。该实验基于Caffe[15]平台,在GeForce1080上测试完成。
3.1 评估车辆检测网络
首先用数据集“Compars”作为训练集来训练车辆检测网络,然后分别将测试集Test1和Test2送入车辆检测网络进行测试,在车辆检测网络中测试图片经过RPN层给出候选框,然后通过损失层计算输出最终的车辆位置。为了评估检测精度,采用相同的训练集“Compars”训练不同的模型,包括R-CNN和Fast R-CNN,并对比了VGG网络结构的Faster R-CNN模型,在测试集Test1和Test2上对比了这几种模型的检测精度。对于检测准确性的判别,采用IoU(交并比)方法来验证候选框是否为车辆位置,计算结果如下:
(13)
其中,A为候选框;B为真实矩形框;IoU为矩形A和矩形B的交集占矩形A和矩形B的并集的比率;SI为矩形A和矩形B的交集面积;SA+SB-SI为矩形A和矩形B的并集面积。
选取准确率与召回率作为评估算法的检测精度指标。准确率和召回率的定义如下:
(14)
(15)
其中,P表示准确率;R表示召回率。
分类结果的混淆矩阵见表1。车辆检测网络的车辆检测结果见表2。

表1 分类结果混淆矩阵
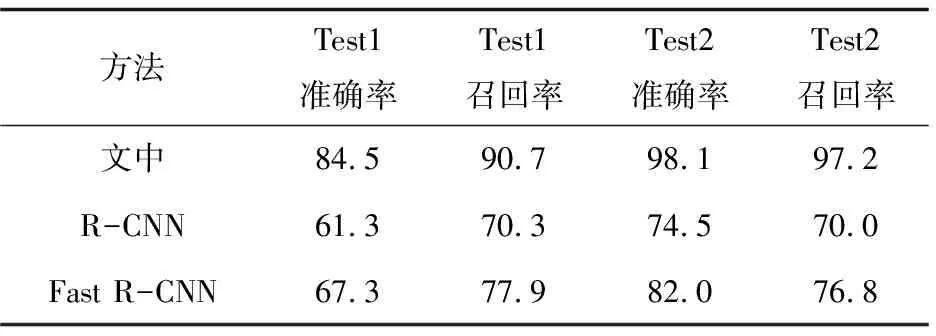
表2 测试集Test1和Test2的检测精度对比 %
由表2可知,测试集Test1的准确率达85%,测试集Test2的准确率达98%。在测试集Test1上,召回率较高而准确率相对下降,说明在测试集Test1上检测错误情况较多,主要原因是Test1的图像车辆目标多,可达5~6个,图像内部有树木、行人、摩托车等干扰对准确率也有影响。而测试集Test2的图像比较清晰,车辆目标为1~2个,车辆目标明显,图像内部干扰较少,因此准确率高,说明车辆检测网络对车辆检测的效果较好,具有良好的有效性。
3.2 评估车辆识别网络模型
为评估车辆识别网络模型,实验中测试车辆的4个属性包括:车辆估计、车辆品牌、车辆颜色和车辆姿态,进行以下几组实验,包括单属性和多属性、不同图像分辨率、不同网络深度等对分类结果的影响。
基于GoogLeNet网络结构,对比了多属性和单属性的分类结果,可以看出在多属性的分类结果一直优于单属性分类,说明多属性联合训练可以充分利用各个属性特征之间的联系,有较好的分类效果。由于真实道路场景下摄像头拍摄的图像信息通常是不同分辨率的,距离摄像头不同远近其捕捉到的图像细节也不同,尽管在车辆识别网络中图像被归一化到224*224,但是不同分辨率的图像归一化到相同大小其细节信息是不同的,故对比了不同分辨率图像对分类的影响。由于不同网络深度提取到的特征的细节程度不同,浅层提取到边缘、纹理等特征,深层提取到轮廓、语义等特征,因此分别对比了不同深度的网络结果对分类结果的影响,包括:AlexNet,VGG16,车辆识别网络。
分类结果如图4所示。
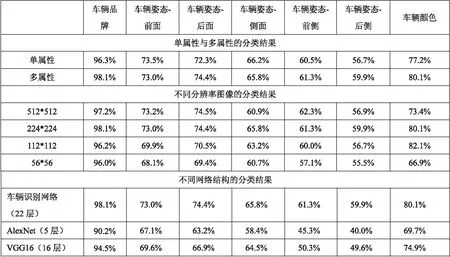
图4 单属性和多属性、不同分辨率、不同网络结构的分类结果
由图4可以看出,多属性联合训练,车辆识别网络在车辆品牌、车辆姿态和车辆颜色方面的分类效果优于单属性训练,虽然单属性分类结果在车辆姿态上有一定的优势,但是多属性联合训练的效率和准确率都相对优于单属性分类。而不同分辨率的图像对于分类结果的影响,从总体表现来说是分辨率越高分类效果越好,但是由于512*512大小的图像在训练时的效率低,耗时长,其准确率也与224*224大小的图像相差不大,因此选择224*224大小的图像效果更好。从网络深度来看,22层的车辆识别网络多属性分类结果明显优于其他深度的网络,由于多属性分类属于细粒度的分类问题,网络结构越深,其提取的特征越丰富,分类准确率就越高。
4 结束语
提出了一种基于Faster R-CNN的车辆多属性识别方法。首先针对真实道路场景下的图像,采用车辆数据库训练Faster R-CNN网络得到车辆检测网络,该检测网络检测精度较高,检测效果好,适用于真实道路场景图像。然后,对GoogLeNet网络结构进行改进,将全连接层连接多个损失层实现车辆的多属性识别,包括车辆的品牌、姿态、颜色等,利用车辆属性识别网络将多个属性之间的特征联合训练,有效提升了属性分类的准确率。采集了两种不同的数据集对基于Faster R-CNN的车辆多属性识别方法进行了测试,实验结果表明,该方法在不同道路场景下均具有较高的检测精度,满足了使用要求,而且可以识别出车辆的品牌、姿态、颜色等信息,具有较高的分类准确率和良好的适用性和鲁棒性。同时,该方法需要完善的方面还有很多,如车辆的其他重要属性(车辆类型、车内人数等)更加细粒度的属性分类问题的研究和建立更加全面丰富的车辆数据集以提升车辆检测精度等。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
