
协同过滤推荐算法的改进与研究
2018-10-15 06:03孙华艳李业丽字云飞
计算机技术与发展 2018年10期
孙华艳,李业丽,字云飞,韩 旭
(北京印刷学院 信息工程学院,北京 102600)
0 引 言
伴随着互联网的迅速发展,智能化、个性化的服务成为电商产业极大的需求,如何通过存储有海量数据的自媒体为用户提供个性化的推荐成为了智能网络研究的热点。研究人员提出了以协同过滤推荐算法为主流的多种推荐算法,相比其他算法,协同过滤推荐算法的易实现性和可扩展性使其在电商和自媒体等领域应用广泛。但随着互联网数据呈几何级数增长、数据内容复杂度不断提高,协同过滤技术也面临着两个瓶颈问题[1-5]:数据的稀疏性和可扩展性。
数据稀疏性问题是推荐系统面临的主要问题,也是导致系统推荐质量下降的主要原因[6]。目前,对该问题的解决分为两类,一类为矩阵填充技术,另一类为矩阵降维技术[6-8]。矩阵填充技术比较理想的方法有BP神经网络、Naive Bayesian分类方法、基于内容的预测[9-10]。矩阵降维技术比较典型的方法是奇异值分解(singular value decomposition,SVD)技术[11-12]。针对个性化推荐过程中最近邻准确性的不足,文中提出了基于因果聚类分析的协同过滤推荐算法和基于模糊相似关系的协同过滤推荐算法。前者利用因果聚类对收集的信息进行分析研究,找出其内在联系,实现个性化的精准推荐。后者通过最大树法及确定最佳阈值λ以更加合理、精准地计算最近邻[13-14]。最后将算法应用于美食推荐系统中进行验证[15]。
1 传统的协同过滤推荐算法
协同过滤(collaborative filtering,CF)推荐算法[16-18]是通过对用户—项目之间的评价、分享、转存等数据的分析,找出基于用户或项目的相似度,实现精准化推荐。协同过滤推荐算法分为:(1)基于用户的协同过滤推荐算法(user-based collaborative filtering),通过用户搜索,对喜欢产品的评价、收藏等数据信息度量有相同行为的用户之间的关系来实现产品的推荐。(2)基于项目的协同过滤推荐算法(item-based collaborative filtering),通过不同用户对于不同产品的评价及喜好程度来度量产品之间的紧密程度,从而实现产品的推荐。
1.1 协同过滤推荐算法的实现
(1)收集用户—项目数据;
(2)计算用户—项目的相似度,找出最近邻或相似度最高的N个用户或项目;
(3)把N个相似度最高的用户或项目推荐给对应的项目或用户。
1.2 相关度评价计算
计算相似度之后寻找最近邻,令Zum为最近邻,对项目的s预测评分的计算为:
(2)
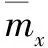
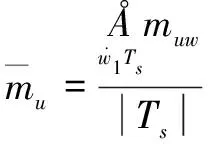
(3)
其中,Ts为项目总和;muw为u对产品w的评价值。
(2)余弦相似度(cosine similarity):通过两个或以上用户对不低于两个产品的评分来计算两用户之间的兴趣相似度。设用户x和y对产品的评价数组数据为x和y,相似度计算如下:
(4)
2 基于因果聚类的协同过滤推荐算法
事物本身的因果关系就存在着相似性,也就是可以通过对以往的经验和数据寻找事物存在的规律。例如:用户a因为喜欢《python数据挖掘》,所以他也可能喜欢《数据挖掘算法》,它们之间存在着这种因果关系。同理对于a和b两个用户,因为他们之间有共同喜爱的一门课程,那么他们之间也有可能存在共同喜爱的另外一门课程。本节基于因果聚类的协同过滤推荐算法,将以更加精细和准确的关联计算来实现项目的精准可靠推荐。引入项目和用户的因果关系计算相似性更进一步提高度量相似度。
2.1 因果模糊聚类
因果模糊聚类[19-20]的核心是择近原则。设对要分析处理的项目集α,每个项目存在的特征值为(x1,x2,…,xn),然后对特征值的因果模糊聚类和模式识别判定、预测它们的归属性,从而实现更好的推荐。
2.2 因果模糊聚类实现过程
(1)特征模糊集的建立。
设所有项目集为α,对于α的聚类通过三元结构(X,Y,φ)处理,所以X=(X1×X2×…×Xn)是n元Descartes累乘,Y为非空幂集,φ为X到Y的映射,如:φ:X1×X2×…×Xn→Y。
同时记zt=(xt,yt),通过模糊等价计算出对应的最佳聚类(z1,z2,…,zm)=(T1,T2,…,Tm),特征模糊集Vi={xt1,xt2,…,xtki}(i=1,2,…,m),其中(xts,yts)为项目Ti的最佳聚类,Vi是Ti的特征轴投影。计算:
(5)
(6)
对于x=(x1,x2,…,xn)属于项目的特征值,令
(7)
其中,i,j=1,2,…,m为特征取值的范围;(ω1,ω2,…,ωn)为一组确定的权重。
令Wi={yt1,yt2,…,ytki},其中i=1,2,…,m,(xts,yts)=zts属于项目最佳聚类Ti,Wi是Ti的预测相似轴投影,计算:
(8)


建立因果模糊聚类A∈X,对应项目的分类(T1,T2,…,Tm)为:
(2)进行因果聚类的判定。
若s期特征的状态为确定特征值xs∈X,则xs与{P1,P2,…,Pm}为最大隶属度原则,Aj=max(A1(u0),A2(u0),…,An(u0))。
若s期特征的状态为模糊集Bs∈X,则Bs与{P1,P2,…,Pm}通过择近原则。
最后,选取Pi0,同时对应的Ii0为项目集α与s期的因果聚类的模糊判定值(i0∈{1,2,…,m})。
该方法通过计算某项目影响推荐效果的n个因素,计算并构造相应的三角模糊数,最后根据最大隶属度原则或择近原则进行模糊预测,从而找出影响最终推荐的可能性最大的因素及特征值,再根据这一影响因素实现精准、个性化的推荐。
步骤1:对于项目的原始特征及数据,进行标注化处理,标定值的大小表示两个特征之间的相似度;
步骤2:通过计算将项目原始特征数据转化成模糊矩阵R;
步骤3:将模糊矩阵R进行模糊聚类分析,并且计算出最佳聚类;
步骤4:根据各聚类的特征函数及权值,构建三角模糊数,从而选取最佳特征值,实现精准、个性化推荐。
2.3 最近邻的取值
算法最后通过对项目的评价、分享、收藏等原始数据值最高的特征进行计算及分析处理,最佳特征为一个取值空间的中间值,所以以中间值为中心的不超过两端取值范围为最佳特征数。
3 基于模糊相似关系的协同过滤推荐算法
用户在网上有目标的搜索是一种显性需求,然而显性需求的信息数据背后隐藏着隐性需求,这就是个性化推荐的核心。起初,网站极少的用户共同评价数据,很难准确地获得最近邻。例如,两个非常喜欢计算机科学的用户由于不存在共同评价数据,其相似度计算结果为零。而与他们不是同一类的书籍爱好者由于存在评价数据,相似度反而高于零。这就是网站对于新用户评价项目的第一评价以及数据稀疏性问题,仅以共同评价数据判断相似级别显然不精准。文中通过结合项目所属分类来计算用户的相似程度,这是由于用户对于统一属性的项目会有相似的喜好程度。
用户喜欢的项目类可能拥有多个特征,而它们之间又可能存在着特征重叠或相通性,所以可以通过模糊相似关系的直接聚类法求其项目之间的紧密程度,也就是相似度。基于模糊相似关系的协同过滤推荐算法就是通过求其最大树法寻找最近邻,从而实现个性化精准推荐。
基于模糊相似关系的协同过滤推荐算法[21]是通过对项目的标定得到模糊矩阵R,然后根据相似矩阵R得到一棵权重树,通过最佳阈值λ确定法对相似矩阵进行截集,应用直接聚类求出相似性,获得最佳聚类,最后对用户进行精准的个性化产品推荐。
3.1 相似关系的协同过滤推荐算法的实现过程
(1)项目特征值的标定。
从项目ui和uj中选取最具有特征性的m个特征值,分别为ui=(xi1,xi2,…,xim)、uj=(xj1,xj2,…,xjm),然后计算得到项目模糊相似矩阵。
(9)


(2)构造最大树。
首先,根据第1步对项目特征值的标定得到模糊相似矩阵R,画出被分类因素为节点,以相似矩阵R的因素rij为权重的一棵最大树;其次,选取最佳阈值λ;最后,砍断权重低于λ的枝,得到一幅连通图,相联的分支就构成了λ水平上的分类,这就是获得相似度较高的最佳聚类。
(3)计算最佳阈值λ。
要实现精准、个性化推荐,阈值λ的选取是核心。通过模糊相似矩阵依次取λ的最大树,再利用最大树法得到的截集来实现精准、个性化推荐。
聚类图可以给出各λ对应的分类,形成一种动态聚类。对于阈值λ的选取,由于人为的分类总是带有主观性,所以可用F-统计量来选取。

(10)

通过最佳阈值λ确定法计算模糊相似矩阵的方法,可以更精准地把相似度高的特征属性项目聚为同一种推荐项目,然后运用这一方法对用户进行精准、个性化的产品推荐。
3.2 最近邻的取值
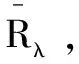
4 实验结果及分析
4.1 数据集合
实验数据是在合法范围内,基于Python语言的数据挖掘技术在美团网上抓取的。美团网拥有中国最多的美食信息资源,也是国内最活跃、最权威的外卖网之一。抓取数据中包含对美食的评分(值为1~5,值越大表明用户喜好度越高)、特征和网络社交关系等。在美团网上用户可以对美食进行等级评分、收藏以及给朋友分享推荐,所以美团网的数据对于美食推荐具有很高的参考价值。其中抓取了10万条评分数据,含有947个用户对1 678个美食的评判分数,每个用户不少于对27个美食进行评分。
4.2 数据密度计算
利用用户对美食的评分值来表达对美食的喜爱程度。
数据密度=100 000/(947×1 678)=0.062 9
(11)
表明数据的稀疏性非常高。
4.3 测试原则
通过对抓取数据随机抽取70 000条作为实验训练集,抽取30 000条作为测试集,分别对传统过滤推荐算法和基于因果聚类和模糊相似关系的协同过滤推荐算法进行实验。
4.4 度量标准
文中应用的统计精度测量中的绝对误差(MAE)是度量推荐结果好坏的最有效方法之一。MAE值越小表明推荐效果越佳。
(12)
其中,m为项目集中评分项的量;pi为对算法预估的评判分数;qi为测试数据的实际分数。
4.5 实验结果
实验基于抓取的数据对传统的协同过滤推荐算法与因果聚类及模糊相似关系的协同过滤推荐算法进行了平均绝对误差值的比较分析,如图1所示。最近邻的数量也将影响推荐的效果,过少将会降低推荐的精准性,过多将极大增加算法的复杂度,实验中选取最近邻的数量为10~40。
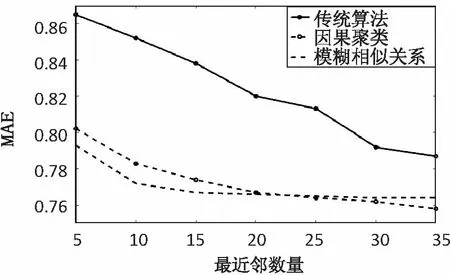
图1 3种算法的MAE比较
通过图1可知,无论选取多大最近邻数,提出的基于因果聚类及模糊相似关系的协同过滤推荐算法的平均MAE都低于传统推荐算法,表明该算法具有较高的精准度,对推荐系统精准度的提高有明显帮助。其中基于因果聚类的协同过滤推荐算法在最近邻数量低于23左右时,精准度略高于基于模糊相似关系的协同过滤推荐算法。这是因为因果聚类是基于模糊相似关系法中的模糊矩阵加各项目的权重来进行聚类分析推荐,所以它的平均绝对误差略小。当最近邻高于23以后,因果聚类法的最终预测值在最大隶属度或择近范围中会扩大,所以精准度趋于不变,而基于模糊相似关系的协同过滤推荐算法的精准度则继续提高。
5 结束语
各推荐算法中相似度度量法的好坏直接影响了推荐项目或用户的精准度和个性化。文中提出的基于因果聚类与模糊相似关系的协同过滤推荐算法主要通过增加项目权重的三角模糊数法和计算最大树及最佳阈值λ确定法来提高相似度的度量。同时,该算法通过对项目或用户特征值的内外距离计算或加权计算特征模糊集,都能减小稀疏性带来的负面影响。下一步将结合聚类技术解决协同过滤推荐技术的可扩展性问题。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
成都信息工程大学学报(2021年3期)2021-11-22
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
文苑(2020年4期)2020-05-30
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
软件导刊(2018年11期)2018-11-19
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
课程教育研究·新教师教学(2016年18期)2017-04-12
汽车与新动力(2016年6期)2017-01-04
