
基于分布式架构的铁路企业社会保障管理信息系统设计
2018-10-09 03:32朱韦桥靳源源
铁路计算机应用 2018年9期
洪 铂,朱韦桥, 靳源源
(1. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2. 中国铁路总公司 审计和考核局,北京 100844)
铁路企业社会保障管理主要涵盖企业社会保险(五险)、企业年金、补充医疗保险等方面业务。随着社会保障体系深入推广,铁路各级企事业单位对员工的福利保障内容逐渐从单一趋向复合;然而社会保障日常业务管理存在政策差异大、内容琐碎、量大、复杂等问题,铁路企业又具有点多、线长、面广的行业特征,为实现社保的“记录一生、保障一生、服务一生”的服务宗旨,建设统一规划的铁路企业社会保障管理信息系统(简称:社保系统)已势在必行[1-2]。
社保系统具有政策性强、需求变化频繁等特点,集中式的架构在可扩展性、可维护性、灵活性和维护成本等方面很难满足业务快速变化的需要。在实践中,我们采用了分布式架构,它是一套构建系统的准则,可以把一个复杂的系统划分为一套简单系统的计划,各自系统之间应该保持相互独立,但要与整个系统架构保持一致,分布式架构对大量数据的快速处理和响应也具有极大的优势[3-4],采用分布式架构搭建的系统具有更加经济、更易扩展、数据共享性更好、系统运行效率更高等特点。
1 铁路社保系统建设需求
1.1 管理需求
依据国发〔1998〕28号文的规定,铁路企业的基本养老保险行业统筹移交地方管理[5],自中国铁路总公司成立以来,包括铁路总公司在内,更多的铁路企业将医疗保险、生育保险、工伤保险向地方移交。经过十几年的改革探索,铁路企事业单位逐步建立了社会保险、企业年金和补充医疗保险相结合的社会保障体系,铁路企业的社会保障工作已由“粗放”转向“精深”。同时随着时间的推移,铁路职工对与自身利益相关的账户信息、办理情况等基本情况了解的需求也越来越强烈。
1.2 系统需求
社保系统是在管理要求的基础上建立一套符合管理需求的体系,应包含适应不同企业、不同体系、不同地方的管理要求,在统一规划的体系架构下,搭建不同适应性的组件和硬件平台,从而满足建立统一信息化系统的需求。另外社保系统需要对全路人员的基本信息进行存储,建立人员变动情况追溯机制,系统需要支持业务办理人员可快速查询变动情况,一般职工(在职职工和退休职工)可以在铁路内部网络和互联网上方便快捷的查询自身权益信息。
2017年,铁路总公司在铁路大数据应用中,将社保数据作为资源管理领域的一部分,从企业管理的角度对人员的参保情况、资金使用情况等进行分析和风险控制[6-7],这就对社保业务数据的存储提出了更高的要求。随着铁路企业改革的深化,其社保管理需求也在不断的发展和变化,因此,系统的可持续性和扩展性也是系统在建立过程中必须考虑的问题。
2 系统架构
2.1 逻辑架构
社保系统在规划时,将职工查询、业务办理和统计分析进行了分离,依据3种业务的不同特点采用不同的理念和技术。
(1)职工查询业务主要是为了适应在铁路内部网络和互联网上均可查询,除了支持一般的PC外还应支持当前的各种移动设备。因此,为了适应这种需要,应采用多级缓存技术,并将部分页面进行静态化处理,同时依据各自查询的业务需求创建目录,在提高查询和展现效率的同时,对各自异构网络进行适应。
(2)业务办理功能集中在铁路内部网上,应重点考虑各单位、各地方,以及企业未来业务发展方向,在这部分功能的规划中应重点对业务和数据库进行拆分,在降低系统耦合度的情况下,尽量做到模块的舞台化。
(3)统计分析业务主要是为管理人员和相关领导提供决策支持,分为定时统计和实时统计两部分,其中,实时统计应限定数据范围,定时统计利用系统闲时进行运算,形成计算结果,并提供较为丰富的展现方式。
铁路企业社保系统逻辑架构,如图1所示。
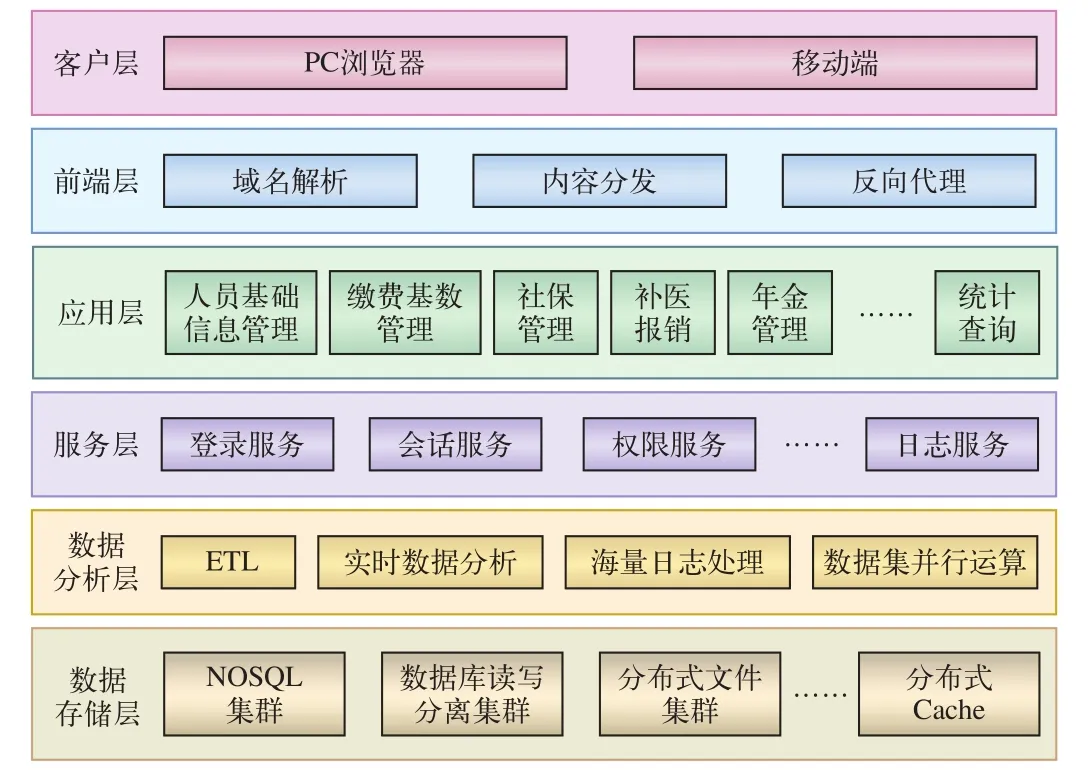
图1 铁路企业社保系统逻辑架构
(1)客户层:支持PC浏览器和手机APP。手机APP主要提供业务查询功能,PC浏览器支持业务办理和职工查询。手机APP可以通过反向代理,访问服务器。
(2)前端层:使用域名解析实现查询和日常业务办理的负载均衡,内容分发主要为查询功能提供本地加速以及反向代理服务。
(3)应用层:在应用集群上分别部署相关业务应用,主要分为社会保险、补充医疗、年金管理、统计查询等业务模块。
(4)服务层:将业务使用的公共模块搭建在服务集群上,主要提供登录服务、基本查询服务、权限管理服务、会话管理服务、报表服务等。
(5)数据处理层:这一层作为较为特殊的一层,一方面对数据存储层中的数据进行抽取和处理,同时依据实际情况可以直接对应用层提供数据分析服务。提供离线数据分析和实时数据分析两种方式,如将月报、季报、年报等具有明显时间任务的统计报表设置定时任务,利用系统闲时进行运算后进行存储,另一方面为一定范围内的数据提供实时数据分析。
(6)数据存储层:含使用关系型数据库集群(支持读写分离)、NOSQL集群、分布式文件系统集群、分布式Cache等技术,支持应用层和服务层的日志数据收集,以及关系数据库、NOSQL数据库的结构化和半结构化数据收集,同时为相关业务数据提供存储支持。
2.2 网络架构
铁路企业社保系统应横跨铁路企业内网和Internet网络:(1)为铁路职工和退休职工提供相关的权益查询功能;(2)面需要与外部相关机构进行数据沟通。
外部相关机构的沟通主要包括地方社保中心以及年金管理机构,通过构建统一的数据交互平台,在确保交互安全的情况下,直接与铁路企业内部网络进行数据交互。因此依据实际情况,可以采用ETL工具对数据进行清洗后导入系统,如图2所示。

图2 铁路企业社保系统网络架构
服务器和集群可以采用云服务器进行弹性控制,在系统实际运行过程中依据实际访问情况,随时对硬件资源进行调整,从而实现资源更加合理的分配和使用。
2.3 数据规划
社保系统不但要对全路的职工进行管理,而且还要对职工的变动情况、权益情况等进行存储维护,由于数据量大的特点,引入了分布式存储系统,达到构建成本低、高性能、可扩展和易用的目的[8]。
大集中式的系统架构已应用多年,业务和技术的发展受限于数据层,业务的连续性也依赖于底层数据的处理,因此,社保系统架构基于对数据一致性和可用性原则进行设计[9],使用数据库代理路由实现对数据的分区分域存储,对客户端屏蔽后端数据库拆分细节,增强了拆分规则的可维护性,同时,也为程序的适应性和扩展性提供很大的帮助。
在社保系统进行部署时,部署架构基于广义的3层架构模型,并参照CSLA.NET框架提出的部分思想进行优化。在CSLA.NET框架中提出,将一般意义上的业务层和数据访问层放到同一台机器上可以提高性能和容错性,因此在社保系统的部署时将这两层进行合并,统称为业务层。CSLA.NET框架中的数据存储和管理层未纳入3层机构,在社保系统中将其作为第3层的数据存储层进行统一管理。综上所述,社保系统从部署角度考虑分为3层:界面层、业务层(包含数据访问层的业务层)、数据存储层。
结合社保系统的数据特点及存储规划,社保系统部署和数据库存储结构,如图3所示。
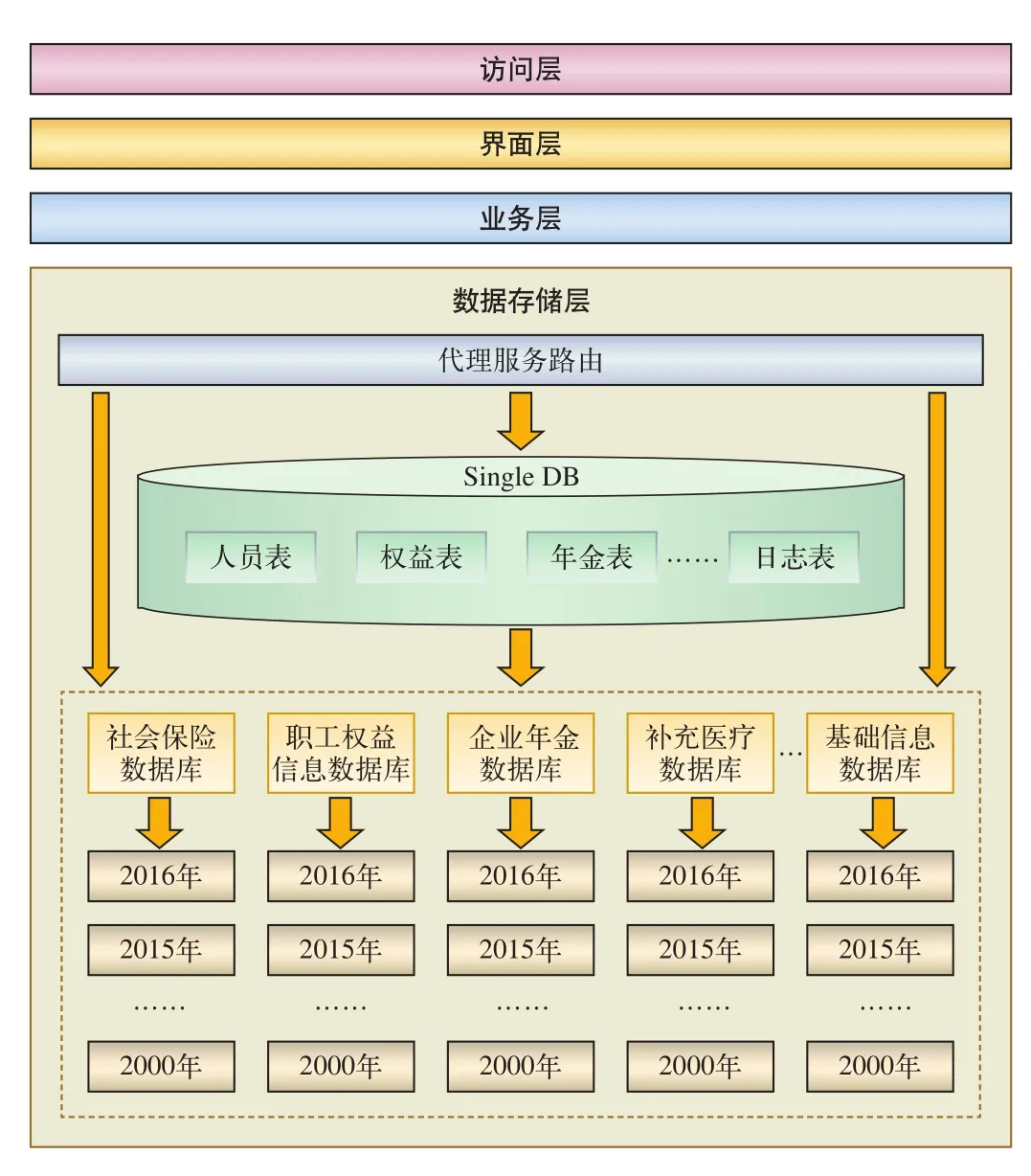
图3 铁路企业社保系统数据规划
按年进行时间切分的方式。在实际应用中纵向切分方式可以依据实际需要进行改进。
3 关键技术
采用分布式架构对社保系统进行搭建,主要是为了解决社保系统面临大量明细数据的快速、高效查询问题,解决由于系统过于复杂而带来的扩展性问题,全面提高系统的稳定性。因此社保系统架构主要基于以下3种技术规划和建设。
3.1 NoSQL数据库
在社保系统中NoSQL数据库集群提供了高效可靠的缓存服务。数据先写入NoSQL数据库,再由NoSQL数据库写入关系型数据库;检索时,系统会对NoSQL数据库进行检索,NoSQL数据库定时与关系型数据库进行同步。另外,社保系统也利用NoSQL数据库集群搭建了Session共享服务器,用于解决分布式系统中的Session统一管理问题。
3.2 DNS和CDN
域名解析服务(DNS)和内容分发网络(CDN)为社保系统在互联网中运行提供高效、安全、稳定的访问机制。社保系统中职工个人的社保数据提供互联网查询功能,而个人的查询操作多针对明细数据,智能线路判断和高效的缓存机制会在很大程度上提高系统的响应速度。由于CDN的存在,网络直接攻击源IP的可能性降低,对提高系统的整体安全性也有极大的帮助。
3.3 数据库层代理路由服务
社保系统的数据库层代理服务采用基于代理模式的分库分表中间件进行实现。分库分表中间件的应用,屏蔽了关系型数据库的物理存储位置,对用户和开发人员来说面对的只是一个关系型数据库。执行查询时分库分表中间件可以对结果进行过滤和屏蔽,有效的解决由于网络传输延迟和服务器性能差异带来的数据无法同一时间返回的问题,同时分库分表中间件一般以关系型数据库的原生SQL作为开发语言,支持数据存储规则的统一的配置管理,降低了项目组的学习和管理成本,提高了开发效率。
4 应用效果
基于分布式架构的社保系统已经上线运行。NOSQL集群和数据库层代理服务技术的全面应用,以及内容分发网络与域名解析的结合应用,令系统在互联网上运行的个人查询功能具有较高的安全性和较好的用户体验。
例如:在年金模块的建设过程中,不仅仅要满足当前业务办理的需要,也要对历年的缴费数据和各类报表进行支持。500万条个人历史缴费信息在进行分布式存储后,在4 h内完成了近10年的各类月报、季报和年报的生成。通过专线的方式,实现了与外部机构的数据交互,规范和提高了年金业务的办理效率。在系统的推广过程中,为了适应铁路企业不同的内部管理要求,必须对部分程序进行修改,同时由于模块相对独立,系统的改建范围较小,极大地降低了改造难度和测试工作量,提高了系统部署的效率。
5 结束语
社保系统不仅仅是一个业务办理系统,在为领导提供决策支持的同时,更是与铁路职工利益息息相关,社保系统的建设,能够做到社保数据对职工公开和透明,在一定程度上增加了职工与社保部门的沟通,降低了总体沟通成本,将会对铁路企业整体提高社保业务的服务水平起到积极的推动作用,也为其他业务复杂、数据量较大的系统架构规划提供了可行的参考方案。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
湖南电力(2022年3期)2022-07-07
汽车工程(2021年12期)2021-03-08
云南画报(2021年12期)2021-03-08
云南画报(2021年12期)2021-03-08
时代人物(2019年27期)2019-10-23
铁道通信信号(2018年7期)2018-08-29
制导与引信(2017年3期)2017-11-02
互联网天地(2016年1期)2016-05-04
雷达与对抗(2015年3期)2015-12-09
