
基于深度卷积稀疏自编码分层网络的人脸识别技术
2018-09-21 11:39王金平
太原理工大学学报 2018年5期
王金平
(太原理工大学 科学技术研究院,太原 030024)
人脸识别作为计算机视觉中的重要领域一直是学术界与工业界的研究热点。人脸识别往往通过辨别面部器官(眼睛、鼻子、嘴等)形状、大小、分布的不同而进行判断。但光照、姿态、遮挡、表情、老化等变化因素为人脸识别带来了困难。同时,海量人脸图像处理过程中所遇到的“维度灾难”问题,同样是人脸识别领域的挑战之一。
20世纪90年代以来,研究者们相继提出了不同的人脸识别方法。BRUNELLI et al[1]提出了两种算法,分别基于几何特征与灰度特征进行模板匹配。WISKOTT et al[2]提出了一种基于弹性图匹配的人脸识别系统,该系统对人脸图像通过弹性图匹配操作进行特征提取,并通过相似函数进行比较。CHEUNG et al[3]针对基于整体外观的脸部识别方法需要高维度特征空间来获得优秀表现这一问题,提出了一种较低维的特征尺寸与模板匹配方案,使用聚合Gabor滤波器响应来表示脸部图像,在识别面部表情有变化的重复图像上比主成分分析方法更具有鲁棒性。WRIGHT et al[4]将识别问题看作多元线性回归模型中的一种分类模型,并使用了稀疏重构表示主成分特征,提出了处理由遮挡和破坏引起的错误识别的新框架。针对维度灾难问题,不少研究者利用主成分分析(PCA)[5]方法来对人脸识别进行研究,但这种方法只考虑图像的低层统计信息而忽略图像的高层信息。一些研究者进一步提出利用稀疏编码方法对人脸进行识别以获得海量人脸图像更高阶的信息[6-7]。但利用稀疏编码进行人脸识别的方法存在的问题是,由于其基函数依赖于人脸数据库基函数,当数据库不同时需要对相应数据库进行重新学习。
以上方法均是利用传统方法提取人脸图像特征;尽管将不同形式的特征(纹理特征、形状特征等)用于人脸识别系统中,但是研究人员仍无法确定最适合于人脸识别的特征子集。而且,由于人脸图像和其他因素紧密相关,这些人为定义的传统特征能否充分有效地表征人脸图像也无法确定。因此,利用深度学习方法实现检测和无限制的面部识别应运而生。近年来,运用深度学习方法进行人脸识别已经取得一定的成果。WANG et al[8]提出了通过逐层训练深度卷积神经网络对网络进行收敛,通过样本转换方法,避免过拟合的情况,有效提高了人脸识别的准确率。HU et al[9]利用三种卷积神经网络对公共人脸数据库LFW进行人脸识别,并定量比较了CNN的体系结构,评估了不同选择的实现效果。ZHU et al[10]提出了一种深层神经网络多视觉感知器(MVP),用以识别身份以及视图特征,模拟人脑推测出全景图像并给出单张2D脸部图像。
目前,研究人员更倾向于使用深度网络进行识别,然而仍存在调整参数多、计算成本高、特征提取能力弱的问题。针对这一问题,本文提出一种基于深度卷积稀疏自编码分层网络(hierarchical deep convolution sparse autoencoder,HDCSAE)的人脸识别方法。该方法将基于Same模式的卷积操作融入自编码网络中,同时加入稀疏化思想,从而形成深度卷积稀疏自编码网络;用该网络可自动提取海量人脸图像的鲁棒高层特征,避免了繁琐的手工提取特征过程。为了进一步提高分类效果,将卷积神经网络的Softmax层替换为SVM分类器形成分层网络,即将提取的高层特征输入至SVM中进行分类。
1 网络模型构建
1.1 自编码网络
自编码网络是一种用于学习一组数据表示的神经网络[11],旨在学习输入的紧凑表示,同时保留最重要的信息。自编码网络由编码器和解码器两部分构成,如图1所示。其中,编码器是指输入层与中间层组成的子网,目的在于减少输入数据的维度以学习输入数据的简化表示;解码器是指中间层与输出层组成的子网,目的在于在低维空间重建输入。自编码网络的特点是,通过无监督的学习使得输出值尽可能地接近输入值。
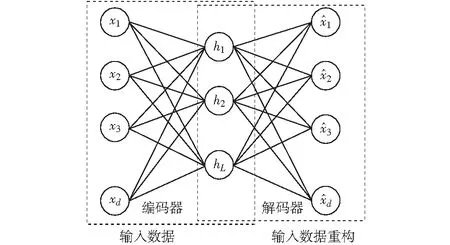
图1 自编码网络模型Fig.1 Autoencoder network model
给定样本,X=[x1,x2,…,xd].自编码的训练目标是最小化重建误差,如式(1):
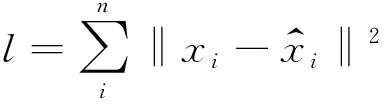
(1)
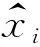
(2)
式中:hi表示中间隐含层;W1和W2分别代表编码器和解码器的权重矩阵;b1和b2表示网络偏置;g(·)表示激活函数。
1.2 基于Same模式的卷积自编码网络
卷积自编码[12]包括卷积编码与卷积解码,其核心思想是在自编码网络的无监督学习方式基础上结合卷积神经网络的卷积与池化操作,来实现特征不变性提取。为了更好地实现无损特征提取以及特征图重构,本文采用Same模式卷积操作下的卷积自编码网络CAE-S,如图2所示。
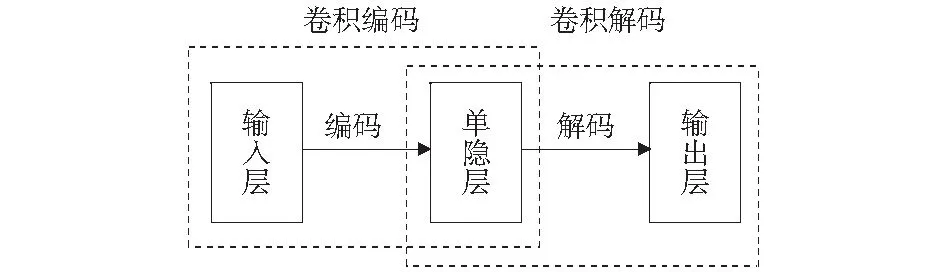
图2 CAE-S结构图Fig.2 CAE-S structure
对特征图执行基于Same模式卷积操作的CAE-S卷积编码,具体公式如下:
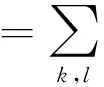
(3)
式中:g为输出图像;f为输入的人脸图像;f'为对矩阵f上下左右各填充(m-1)/2维数据;h为卷积核;m为输入图像的宽。采用基于Same模式的卷积自编码网络,计算CAE-S的输出与输入的均方误差并由此更新网络权值,进而实现特征提取。
1.3 稀疏自编码网络
将稀疏自编码网络的输入设为{x(1),x(2),…},并将目标值设为输入值y(i)=x(i).稀疏自编码网络结构如图3所示。前向传播的公式如下:
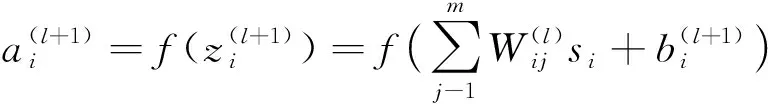
(4)
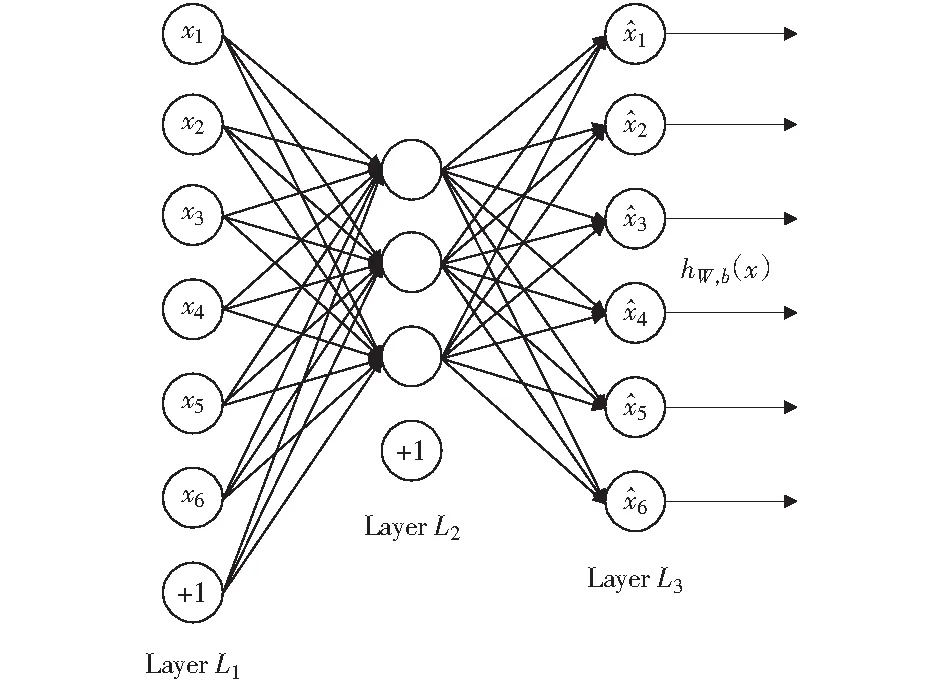
图3 稀疏自编码网络结构Fig.3 Sparse autoencoder network structure
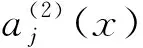
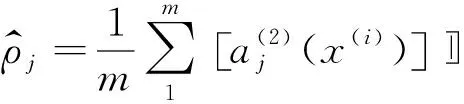
(5)
用最少的隐藏单元来表示输入层的特征以达到稀疏性,因此应采用KL(Kullback-Leibler divergence)距离,具体表达式如下:
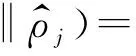
(6)
稀疏自编码网络[13]整体代价函数如下:
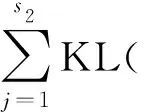
(7)
式中,
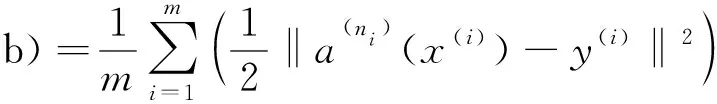
(8)
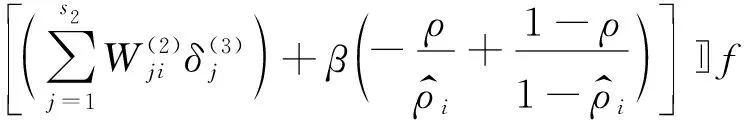
(9)
这样,一个稀疏自编码器就完成了。稀疏自编网络同样可用于降维,其稀疏性具体表现为用较少的隐含层来表示原始数据。
1.4 基于Same模式的深度卷积稀疏自编码分层网络
本文在自编码网络的基础上引入Same模式下卷积操作与稀疏化思想,同时用SVM分类器代替传统的Softmax分类器作为本文所提出网络的分类器,提出了HDCSAE。该网络结合了无监督稀疏自编码(sparse autoencoder,SAE)的特征提取能力和有效的卷积特征表示能力,实现了人脸图像特征的自动提取。在卷积之后,由SAE提取的代表特征是对原始输入图像的特定方向和结构信息的响应,并且卷积特征图包含用于后一层特征表示的重要且期望的信息。该网络由3部分组成:第1部分由CSAE-S层与Pooling层的组合CSAE作为深度网络的基本模块堆叠而成;第2部分为全连接层;第3部分为分类器部分,即将全连接层后提取的高层抽象特征输入SVM分类器,得到分类结果。最终形成基于Same模式的深度卷积稀疏自编码分层网络(HDCSAE),如图4所示。

图4 基于Same模式的深度卷积稀疏自编码分层网络(HDCSAE)
Fig.4 Hierarchical deep convolution sparse autoencoder
(HDCSAE) network based on Same mode
整个网络采用LeakyReLU作为激活函数。在网络的每个Pooling层后加入Dropout层,可抑制网络陷入过拟合的状态,增强其泛化性。最后使用多类别SVM分类器(multiclass support vector machine)代替传统的Softmax分类器,从而形成分层网络,进一步提高了识别准确率。
2 实验结果与分析
2.1 实验数据
本文使用FERET人脸数据库对本文提出的HDCSAE的性能进行测试。FERET人脸数据库作为目前常用的人脸识别数据库之一,包含1 196人14 051幅多姿态和光照的人脸灰度图像。图5为部分人脸图像。
2.2 参数设置
选取数据集中的80%图像进行训练,20%进行测试。为了验证系统的稳定性和鲁棒性,采用5折交叉验证法对网络性能进行评估。HDCSAE比传统CNN要多n×m次卷积操作;其中,n表示HDCSAE的卷积层数,m表示该网络中自编码训练迭代次数。

图5 FERET人脸数据库部分图像Fig.5 Part of the images in FERET face database
为了使CNN在训练过程中可以更快地收敛,目前常用的方法是通过无监督预训练的方式来代替随机初始化权重[14]。而本文中DCAE/DCSAE的本质就是利用自编码初始化CNN权重,即通过控制输出近似等于输入的自编码训练思想完成CNN参数初始化设置。
为了证明将基于Same的卷积操作融入自编码网络中同时加入稀疏化思想所形成的深度卷积稀疏自编码网络在特征提取方面的有效性,本文将传统CNN、基于Same的卷积操作融入自编码网络所形成的的DCAE以及在DCAE的基础上加入稀疏化思想所形成的DCSAE进行对比。网络设计如表1所示。

表1 DCSAE及对比网络结构Table 1 Structure of DCSAE and contrast network
表1为所设计的3种网络模型,其中(64,5×5)表示该卷积层包含64个5×5卷积核。在实验条件允许且不增加训练时间的情况下,将训练块大小设置为32,每层自编码迭代5次,整个网络迭代13次。
2.3 实验分析
实验1通过比较CNN, DCAE,DCSAE等3种识别方法在测试集以及训练集上的准确性来评价本文提出的网络的性能,具体结果如表2所示。
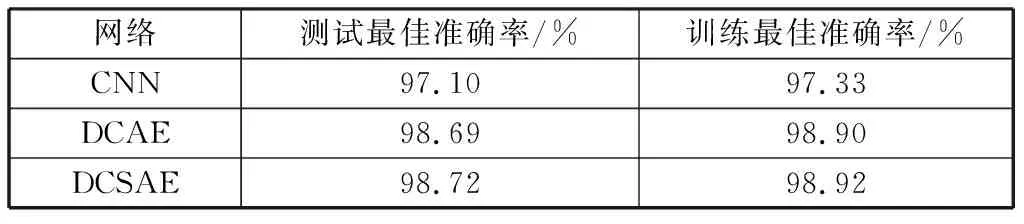
表2 DCSAE及对比网络实验结果Table 2 DCSAE and contrast network experiment result
分析图6以及表2可以得出,相较于传统CNN,DCAE和DCSAE在训练准确率以及测试准确率上均有提高。其中,DCSAE在测试准确率以及训练准确率上均取得最高值。由此说明,将基于Same模式卷积操作融入自编码网络以及在此基础上加入稀疏化操作在提取人脸图像鲁棒的高层特征上的有效性,从而使得网络的泛化性能更好。
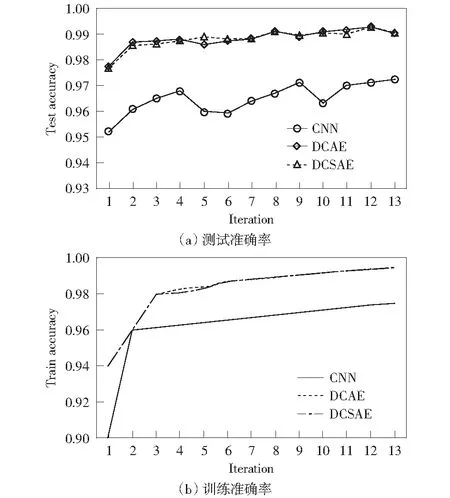
图6 FERET数据集下不同方法的测试准确率与训练准确率Fig.6 Test accuracy rate (a) and train accuracy rate (b) of different methods under FERET dataset
为了说明分层结构可以有效提高深度卷积稀疏自编码网络的识别性能,并且说明本文提出的人脸识别方法相对于其他人脸识别方法的优越性,实验2在FERET数据集下将本文提出的HDCSAE与传统的PCA+SVM结合方法[15]、SDAE(栈式降噪
自编码,stacked denoising autoencoders)[16]方法以及F-NNSC方法[17]进行比较,实验对比结果如表3所示。

表3 FERET数据集下不同算法的识别率Table 3 Recognition rate of different algorithms under FERET dataset
分析对比表3中HDCSAE与表2中DCAE、DCSAE的实验结果后得出,HDCSAE的识别率更高。由此说明了将传统Softmax层替换为SVM分类器对人脸识别的有效性,即说明了分层框架的有效性。
由表3还可以看出:相较于PCA+SVM算法、F-NNSC算法这些基于人为定义特征的人脸识别方法,本文方法(HDCSAE)的识别率有所提高;相较于基于SDAE的人脸识别算法,本方法的识别率有明显的提高。由此证明,本文提出的人脸识别方法可以提取更加鲁棒的人脸图像特征,在深度网络结构设计上更加合理。
3 结论
本文在自编码网络的基础上融入基于Same模式的卷积操作并引入稀疏化思想,形成深度卷积稀疏自编码网络,再将网络中Softmax分类器替换为SVM分类器,从而提出深度卷积稀疏自编码分层网络(HDCSAE),并将其运用于人脸识别。实验证明,该网络能提取人脸图像更加有效鲁棒的高层特征并得到较好的识别结果。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机系统应用(2021年2期)2021-02-23
学生天地(2020年31期)2020-06-01
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
电子技术与软件工程(2017年14期)2017-09-08
电子制作(2017年1期)2017-05-17
